2023-11-2 04:32:7 Author: blogs.sap.com(查看原文) 阅读量:1 收藏
This blog post outlines the creation of a real-time pipeline in SAP Data Intelligence (DI) for continuous file replication from one storage location to another. For example, when a file is uploaded or generated in your source storage location, such as S3 or Azure Data Lake, the DI pipeline will automatically detect, retrieve, and transfer the data to the target storage location. The pipeline operates 24/7 and seamlessly repeats the process as soon as a new file arrives at the source storage location. There is no need to manually stop and restart the pipeline or set a specific schedule; it is designed to run continuously. The pipeline will only halt in the event of an error while writing the file.
Steps to create Real-Time Pipeline :

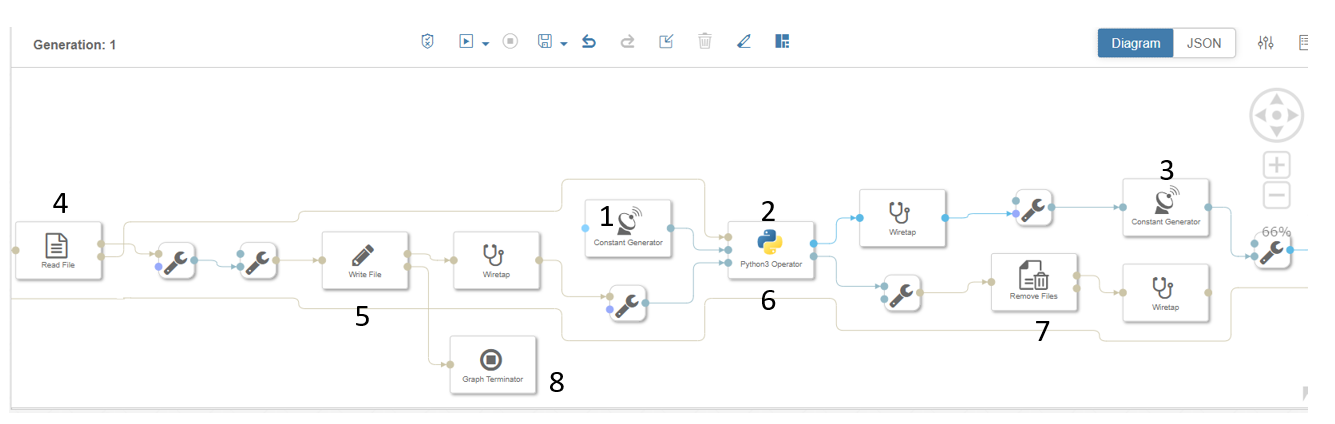
SAP DI Pipeline for continuous file replication
Based on above snapshot , follow the numbering to design the pipeline and connecting operators.
- Use Constant generator to start the process of executing python operator (2).Set Mode as “Once” in configuration.
- Python operator consist of scripts to send the output to operator (3 and 7).
import pandas as pd import io from io import StringIO import csv import json def on_input(inData): df = (inData.body) api.send("output",str(df)) def on_input2(inData2): df1 = (inData2) api.send("output",str(df1)) def on_input3(inData3): df1 = ("/shared/task_instances.csv") api.send("output2",str(df1)) api.send("output",str(df1)) api.set_port_callback("input3", on_input3) api.set_port_callback("input2", on_input2) api.set_port_callback("input1", on_input) - Constant generator (3) consist of file source path for example – “/shared/xyz.csv” and mode is set to trigger.
- Read file ( 4) will read the data from file based on input file path and Write operator(5) will generate the file at target location.
- Remove file operator (7) will delete the file from source location once target file is generated.
- Graph terminate operator (8) to stop the pipeline if there is any error while writing data in target file.
This blog post has covered basic functionality to read and write data into files , however It can be further enhanced based on customers requirement.
Hope this blog post helps.
Please share your feedback or thoughts in a comment.
For more information on SAP Data Intelligence, you can refer and follow the below pages:
如有侵权请联系:admin#unsafe.sh