2023-10-10 00:31:15 Author: securityboulevard.com(查看原文) 阅读量:7 收藏
Data lakes, or centralized repositories for large-scale data, are a popular solution for data storage, and there are good reasons for that. Data lakes are flexible and cost-effective, as they allow many object formats and multiple query engines, and there is no need to manage or pay for resources like disks, CPUs, and memory. In a data lake, data is simply stored in an object store, and you can use a managed query engine for a complete pay-per-usage solution.
Unfortunately, with the increase in usage comes an increase in targeted attacks. A data lake is not just another database. Access control and monitoring are much more complex because the data lake includes both an object store’s access control and multiple query engines. It contains both structured and unstructured data, with rapidly increasing size and number of operations.

In this post, we will explain how data lake query engine capabilities in the wrong hands can be exploited to steal sensitive information, and how to mitigate this threat.
To demonstrate how attackers can explore a data lake using a query engine, we will use an example with an AWS cloud data lake, Amazon S3 as an object store, and Amazon Athena (based on prestoDB) as a query engine. This concept is similar in other cloud and on-premises data lakes, and also other query engines. As an example, you can perform similar operations if you use min.io as an object store and Trino as a query engine, and Hive as a metastore.
Assuming we, as an attacker, have acquired credentials to a cloud account, we can first check if we can access the query engine, and then learn about the data lake. Here is the Python code we used to pull initial data lake information:

This code iterates cloud regions, to narrow down the regions our stolen credentials can access. To run a query in Athena, both a workgroup and a writable output location are needed, so the code then tries to find workgroup names and the output locations of past queries. In SQL, we could use the start_query_exeution method. We will use the information the script returns to run SQL queries on different regions using different workgroups.
Once we confirm our SQL access to the data lake, we will use it to list databases, schemas, tables, and columns. We will also look at table and column comments to learn about the data. Additionally, we will look at table locations, to find additional locations to the ones we found on the first step.
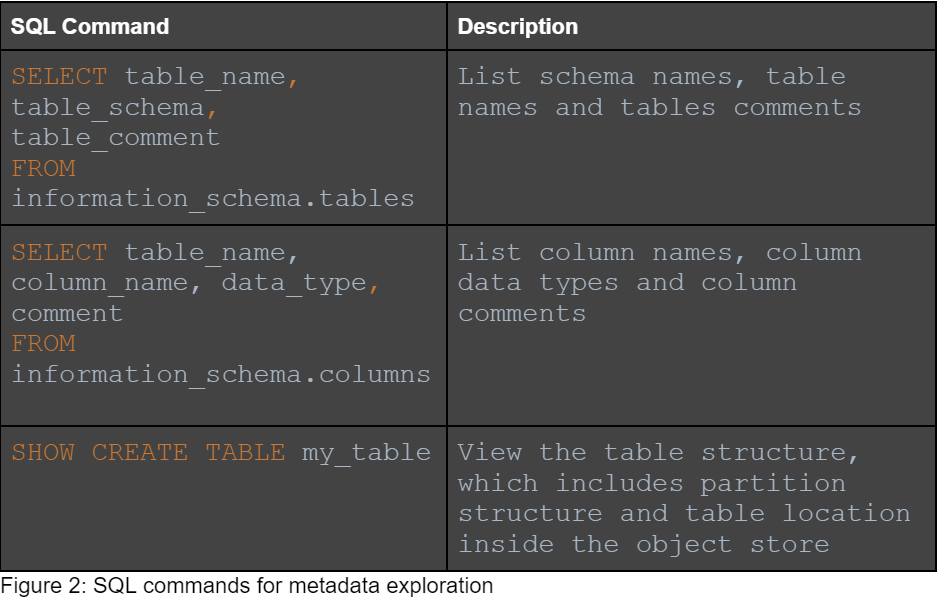
Information returned by the listed queries can be used to explore the data lake. As a smart attacker, we’re looking for table and column names that indicate sensitive data: keywords like “user”,“payment”, “ssn”, “credit_card” or “email”.
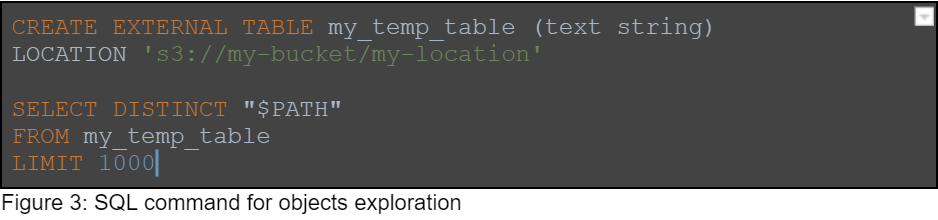
Using the metadata we found above, we are able to find different locations in the data lake. We can use these locations to perform path traversal using the query engine.
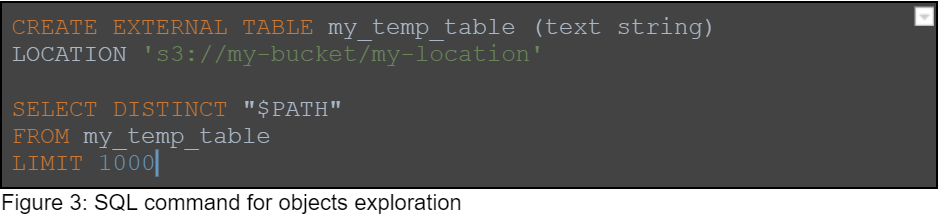
We also use the query engine’s regular expression capabilities to explore the data inside the objects. Here is a query example which finds SSN numbers and emails:

In this example, the query engine goes over all the lines in each of the objects and runs the RegEx, which is a combination of two patterns: email and SSN. The matches are returned per line, and aggregated per object. The query engine saves us the trouble of downloading the information, and we use its capabilities to explore the data and find the sensitive data efficiently. It is possible to go over billions of records in just a few seconds.
Another example is JSON schema detection. In this query, we go over JSON files, parse them, and extract the field names from the data:

The field names can indicate sensitive data, and we can choose which objects we want to download or explore. We can use similar methods to detect CSV objects, schema and other formats.
Another option we will explore is sensitive data detection using S3 SELECT, which is an object store capability. Here is an example for querying data from a CSV file. In the example we try to find SSN numbers in the first column of the CSV object, without downloading the whole object:

We can use this method to iterate CSV files inside a bucket and efficiently find data patterns within objects. From here, we can choose which objects we would like to download or update.
We’ve learned how attackers can exploit data lakes to steal sensitive information, but how can we defend ourselves against this threat? There are three main ways we can protect our data.
Use roles instead of keys. To minimize the risk of data leakage, you should avoid using keys. When possible, assign roles to individual users, so there is no potential for leaked credentials. When you cannot use roles, avoid using long-lasting keys. Use temporary keys or rotate keys frequently.
Narrow the attack surface as much as possible. Even when you are using roles, attackers can gain access to your services and exploit access through roles. To reduce the attack surface:
- Narrow object store permissions to the minimal ones. Use prefixes and split to read only and read/write. Do not give permissions to unused operations, for example, to run S3 SELECT.
- Do not share credentials between services. Each service should have a dedicated user or role, to improve monitoring capabilities.
- In the query engine avoid granting operations like listing schemas or groups, or SQL operations like CREATE TABLE and SHOW CREATE TABLE.
Monitor your object store and query engine usage. Monitoring capabilities change from one object store to another, and from one query engine to another. In S3, for example, you can choose which sensitive prefixes from which you’d like detailed monitoring info. Query engines can monitor queries, this link shows how it can be done in Athena. Based on the monitoring info you can:
- Use anomaly detection to detect suspicious activity.
- Narrow the attack surface by comparing given VS used permissions.
- Remove unused data and unused tables. It will increase security and decrease costs.
As data lake usage continues to grow – their security becomes more and more critical and should be given the right attention. Managing data lake permissions is a complex and ongoing process, which should start before the first byte gets to the object store. To minimize data leakage risk, we recommend a continued review of permissions and monitoring of all access to your query engines, and to your object store when possible.
The post How to Protect Against Data Lake Hacking appeared first on Blog.
*** This is a Security Bloggers Network syndicated blog from Blog authored by Ori Nakar. Read the original post at: https://www.imperva.com/blog/data-lake-hacking/
如有侵权请联系:admin#unsafe.sh