Loading...



8 min read

Today, Cloudflare’s Workers platform is the place over a million developers come to build sophisticated full-stack applications that previously wouldn’t have been possible.
Of course, Workers didn’t start out that way. It started, on a day like today, as a Birthday Week announcement. It may not have had all the bells and whistles that exist today, but if you got to try Workers when it launched, it conjured this feeling: “this is different, and it’s going to change things”. All of a sudden, going from nothing to a fully scalable, global application took seconds, not hours, days, weeks or even months. It was the beginning of a different way to build applications.
If you’ve played with generative AI over the past few months, you may have had a similar feeling. Surveying a few friends and colleagues, our “aha” moments were all a bit different, but the overarching sentiment across the industry at this moment is unanimous — this is different, and it’s going to change things.
Today, we’re excited to make a series of announcements that we believe will make a similar impact as Workers did in the future of computing. Without burying the lede any further, here they are:
- Workers AI (formerly known as Constellation), running on NVIDIA GPUs on Cloudflare’s global network, bringing the serverless model to AI — pay only for what you use, spend less time on infrastructure, and more on your application.
- Vectorize, our vector Database, making it easy, fast and affordable to index and store vectors to support use cases that require access not just to running models, but customized data too.
- AI Gateway, giving organizations the tools to cache, rate limit and observe their AI deployments regardless of where they’re running.
But that’s not all.
Doing big things is a team sport, and we don’t want to do it alone. Like in so much of what we do, we stand on the shoulders of giants. We’re thrilled to partner with some of the biggest players in the space: NVIDIA, Microsoft, Hugging Face, Databricks, and Meta.
Our announcements today mark just the beginning of Cloudflare’s journey into the AI space, like Workers did six years ago. While we encourage you to dive into each of our announcements (you won’t be disappointed!), we also wanted to take the chance to step back and provide you with a bit of our broader vision for AI, and how these announcements fit into it.
Inference: The future of AI workloads
There are two main processes involved in AI: training and inference.
Training a generative AI model is a long-running (sometimes months-long) compute intensive process, which results in a model. Training workloads are therefore best suited for running in traditional centralized cloud locations. Given the recent challenges in being able to obtain long-running access to GPUs, resulting in companies going multi-cloud, we’ve talked about the ways in which R2 can provide an essential service that eliminates egress fees for the training data to be accessed from any compute cloud. But that’s not what we’re here to talk about today.
While training requires many resources upfront, the much more ubiquitous AI-related compute task is inference. If you’ve recently asked ChatGPT a question, generated an image, translated some text, then you’ve performed an inference task. Since inference is required upon every single invocation (rather than just once), we expect that inference will become the dominant AI-related workload.
If training is best suited for a centralized cloud, then what is the best place for inference?
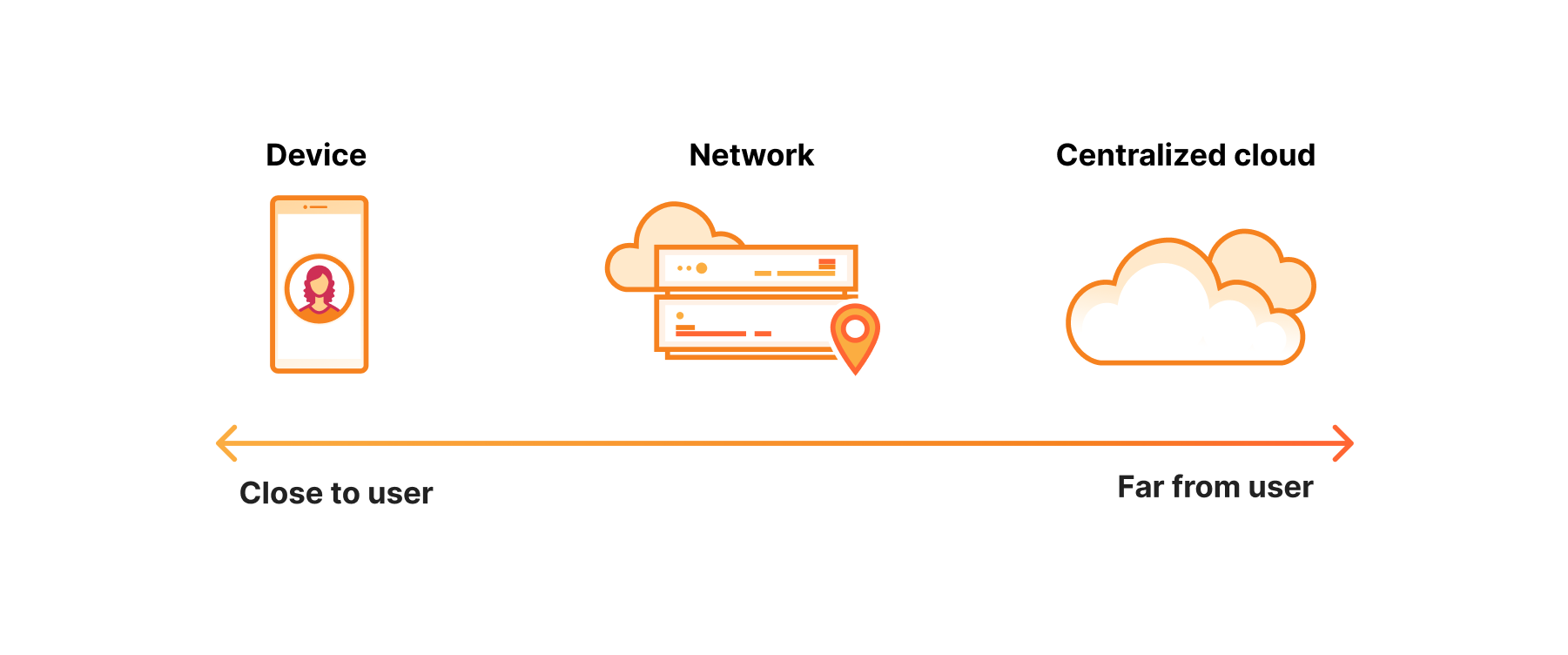
The network — “just right” for inference
The defining characteristic of inference is that there’s usually a user waiting on the other end of it. That is, it’s a latency sensitive task.
The best place, you might think, for a latency sensitive task is on the device. And it might be in some cases, but there are a few problems. First, hardware on devices is not nearly as powerful. Battery life.
On the other hand, you have centralized cloud compute. Unlike devices, the hardware running in centralized cloud locations has nothing if not horsepower. The problem, of course, is that it’s hundreds of milliseconds away from the user. And sometimes, they’re even across borders, which presents its own set of challenges.
So devices are not yet powerful enough, and centralized cloud is too far away. This makes the network the goldilocks of inference. Not too far, with sufficient compute power — just right.
The first inference cloud, running on Region Earth
One lesson we learned building our developer platform is that running applications at network scale not only helps optimize performance and scale (though obviously that’s a nice benefit!), but even more importantly, creates the right level of abstraction for developers to move fast.
Workers AI for serverless inference
Kicking things off with our announcement of Workers AI, we’re bringing the first truly serverless GPU cloud, to its perfect match — Region Earth. No machine learning expertise, no rummaging for GPUs. Just pick one of our provided models, and go.
We’ve put a lot of thought into designing Workers AI to make the experience of deploying a model as smooth as possible.
And if you’re deploying any models in the year 2023, chances are, one of them is an LLM.
Vectorize for… storing vectors!
To build an end-to-end AI-operated chat bot, you also need a way to present the user with a UI, parse the corpus of information you want to pass it (for example your product catalog), use the model to convert it into embeddings — and store them somewhere. Up until today, we offered the products you needed for the first two, but the latter — storing embeddings — requires a unique solution: a vector database.
Just as when we announced Workers, we soon after announced Workers KV — there’s little you can do with compute, without access to state. The same is true of AI — to build meaningful AI use cases, you need to give AI access to state. This is where a vector database comes into play, and why today we’re also excited to announce Vectorize, our own vector database.
AI Gateway for caching, rate limiting and visibility into your AI deployments
At Cloudflare, when we set out to improve something, the first step is always to measure it — if you can’t measure it, how can you improve it? When we heard about customers struggling to reign in AI deployment costs, we thought about how we would approach it — measure it, then improve it.
Our AI Gateway helps you do both!
Real-time observation capabilities empower proactive management, making it easier to monitor, debug, and fine-tune AI deployments. Leveraging it to cache, rate limit, and monitor AI deployments is essential for optimizing performance and managing costs effectively. By caching frequently used AI responses, it reduces latency and bolsters system reliability, while rate limiting ensures efficient resource allocation, mitigating the challenges of spiraling AI costs.
Collaborating with Meta to bring Llama 2 to our global network
Until recently, the only way to have access to an LLM was through calls to proprietary models. Training LLMs is a serious investment — in time, computing, and financial resources, and thus not something that’s accessible to most developers. Meta’s release of Llama 2, an open-source LLM, has presented an exciting shift, allowing developers to run and deploy their own LLMs. Except of course, one small detail — you still have to have access to a GPU to do so.
By making Llama 2 available as a part of the Workers AI catalog, we look forward to giving every developer access to an LLM — no configuration required.
Having a running model is, of course, just one component of an AI application.
Leveraging the ONNX runtime to make moving between cloud to edge to device seamless for developers
While the edge may be the optimal location for solving many of these problems, we do expect that applications will continue to be deployed at other locations along the spectrum of device, edge and centralized cloud.
Take for example, self-driving cars — when you’re making decisions where every millisecond matters, you need to make these decisions on the device. Inversely, if you’re looking to run hundred-billion parameter versions of models, the centralized cloud is going to be better suited for your workload.
The question then becomes: how do you navigate between these locations smoothly?
Since our initial release of Constellation (now called Workers AI), one technology we were particularly excited by was the ONNX runtime. The ONNX runtime creates a standardized environment for running models, which makes it possible to run various models across different locations.
We already talked about the edge as a great place for running inference itself, but it’s also great as a routing layer to help guide workloads smoothly across all three locations, based on the use case, and what you’re looking to optimize for — be it latency, accuracy, cost, compliance, or privacy.
Partnering with Hugging Face to provide optimized models at your fingertips
There’s nothing of course that can help developers go faster than meeting them where they are, so we are partnering with Hugging Face to bring serverless inference to available models, right where developers explore them.
Partnering with Databricks to make AI models
Together with Databricks, we will be bringing the power of MLflow to data scientists and engineers. MLflow is an open-source platform for managing the end-to-end machine learning lifecycle, and this partnership will make it easier for users to deploy and manage ML models at scale. With this partnership, developers building on Cloudflare Workers AI will be able to leverage MLFlow compatible models for easy deployment into Cloudflare’s global network. Developers can use MLflow to efficiently package, implement, deploy and track a model directly into Cloudflare’s serverless developer platform.
AI that doesn’t keep your CIO or CFO or General Counsel up at night
Things are moving quickly in AI, and it’s important to give developers the tools they need to get moving, but it’s hard to move fast when there are important considerations to worry about. What about compliance, costs, privacy?
Compliance-friendly AI
Much as most of us would prefer not to think about it, AI and data residency are becoming increasingly regulated by governments. With governments requiring that data be processed locally or that their residents’ data be stored in-country, businesses have to think about that in the context of where inference workloads run as well. While with regard to latency, the network edge provides the ability to go as wide as possible. When it comes to compliance, the power of a network that spans 300 cities, and an offering like our Data Localization Suite, we enable the granularity required to keep AI deployments local.
Budget-friendly AI
Talking to many of our friends and colleagues experimenting with AI, one sentiment seems to resonate — AI is expensive. It’s easy to let costs get away before even getting anything into production or realizing value from it. Our intent with our AI platform is to make costs affordable, but perhaps more importantly, only charge you for what you use. Whether you’re using Workers AI directly, or our AI gateway, we want to provide the visibility and tools necessary to prevent AI spend from running away from you.
Privacy-friendly AI
If you’re putting AI front and center of your customer experiences and business operations, you want to be reassured that any data that runs through it is in safe hands. As has always been the case with Cloudflare, we’re taking a privacy-first approach. We can assure our customers that we will not use any customer data passing through Cloudflare for inference to train large language models.
No, but really — we’re just getting started
We're just getting started with AI, folks, and boy, are we in for a wild ride! As we continue to unlock the benefits of this technology, we can't help but feel a sense of awe and wonder at the endless possibilities that lie ahead. From revolutionizing healthcare to transforming the way we work, AI is poised to change the game in ways we never thought possible. So buckle up, folks, because the future of AI is looking brighter than ever – and we can't wait to see what's next!
This wrap up message may have been generated by AI, but the sentiment is genuine — this is just the beginning, and we can’t wait to see what you build.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.