Loading...




11 min read

If you're anywhere near the developer community, it's almost impossible to avoid the impact that AI’s recent advancements have had on the ecosystem. Whether you're using AI in your workflow to improve productivity, or you’re shipping AI based features to your users, it’s everywhere. The focus on AI improvements are extraordinary, and we’re super excited about the opportunities that lay ahead, but it's not enough.
Not too long ago, if you wanted to leverage the power of AI, you needed to know the ins and outs of machine learning, and be able to manage the infrastructure to power it.
As a developer platform with over one million active developers, we believe there is so much potential yet to be unlocked, so we’re changing the way AI is delivered to developers. Many of the current solutions, while powerful, are based on closed, proprietary models and don't address privacy needs that developers and users demand. Alternatively, the open source scene is exploding with powerful models, but they’re simply not accessible enough to every developer. Imagine being able to run a model, from your code, wherever it’s hosted, and never needing to find GPUs or deal with setting up the infrastructure to support it.
That's why we are excited to launch Workers AI - an AI inference as a service platform, empowering developers to run AI models with just a few lines of code, all powered by our global network of GPUs. It's open and accessible, serverless, privacy-focused, runs near your users, pay-as-you-go, and it's built from the ground up for a best in class developer experience.
Workers AI - making inference just work
We’re launching Workers AI to put AI inference in the hands of every developer, and to actually deliver on that goal, it should just work out of the box. How do we achieve that?
- At the core of everything, it runs on the right infrastructure - our world-class network of GPUs
- We provide off-the-shelf models that run seamlessly on our infrastructure
- Finally, deliver it to the end developer, in a way that’s delightful. A developer should be able to build their first Workers AI app in minutes, and say “Wow, that’s kinda magical!”.
So what exactly is Workers AI? It’s another building block that we’re adding to our developer platform - one that helps developers run well-known AI models on serverless GPUs, all on Cloudflare’s trusted global network. As one of the latest additions to our developer platform, it works seamlessly with Workers + Pages, but to make it truly accessible, we’ve made it platform-agnostic, so it also works everywhere else, made available via a REST API.
Models you know and love
We’re launching with a curated set of popular, open source models, that cover a wide range of inference tasks:
- Text generation (large language model): meta/llama-2-7b-chat-int8
- Automatic speech recognition (ASR): openai/whisper
- Translation: meta/m2m100-1.2
- Text classification: huggingface/distilbert-sst-2-int8
- Image classification: microsoft/resnet-50
- Embeddings: baai/bge-base-en-v1.5
You can browse all available models in your Cloudflare dashboard, and soon you’ll be able to dive into logs and analytics on a per model basis!
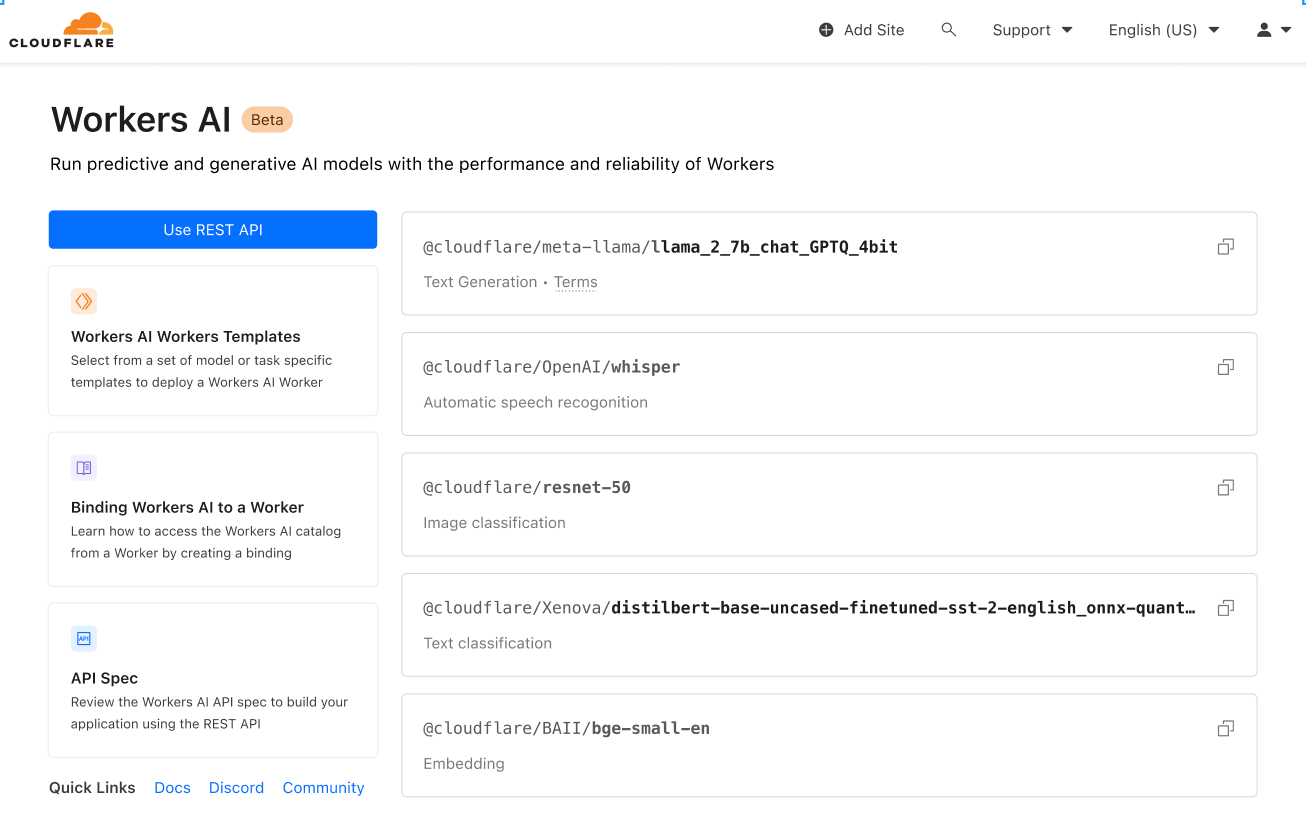
This is just the start, and we’ve got big plans. After launch, we’ll continue to expand based on community feedback. Even more exciting - in an effort to take our catalog from zero to sixty, we’re announcing a partnership with Hugging Face, a leading AI community + hub. The partnership is multifaceted, and you can read more about it here, but soon you’ll be able to browse and run a subset of the Hugging Face catalog directly in Workers AI.
Accessible to everyone
Part of the mission of our developer platform is to provide all the building blocks that developers need to build the applications of their dreams. Having access to the right blocks is just one part of it — as a developer your job is to put them together into an application. Our goal is to make that as easy as possible.
To make sure you could use Workers AI easily regardless of entry point, we wanted to provide access via: Workers or Pages to make it easy to use within the Cloudflare ecosystem, and via REST API if you want to use Workers AI with your current stack.
Here’s a quick CURL example that translates some text from English to French:
curl https://api.cloudflare.com/client/v4/accounts/{ACCOUNT_ID}/ai/run/@cf/meta/m2m100-1.2b \
-H "Authorization: Bearer {API_TOKEN}" \
-d '{ "text": "I'll have an order of the moule frites", "target_lang": "french" }'
And here are what the response looks like:
{
"result": {
"answer": "Je vais commander des moules frites"
},
"success": true,
"errors":[],
"messages":[]
}
Use it with any stack, anywhere - your favorite Jamstack framework, Python + Django/Flask, Node.js, Ruby on Rails, the possibilities are endless. And deploy.
Designed for developers
Developer experience is really important to us. In fact, most of this post has been about just that. Making sure it works out of the box. Providing popular models that just work. Being accessible to all developers whether you build and deploy with Cloudflare or elsewhere. But it’s more than that - the experience should be frictionless, zero to production should be fast, and it should feel good along the way.
Let’s walk through another example to show just how easy it is to use! We’ll run Llama 2, a popular large language model open sourced by Meta, in a worker.
We’ll assume you have some of the basics already complete (Cloudflare account, Node, NPM, etc.), but if you don’t this guide will get you properly set up!
1. Create a Workers project
Create a new project named workers-ai by running:
$ npm create cloudflare@latest
When setting up your workers-ai worker, answer the setup questions as follows:
- Enter workers-ai for the app name
- Choose Hello World script for the type of application
- Select yes to using TypeScript
- Select yes to using Git
- Select no to deploying
Lastly navigate to your new app directory:
cd workers-ai
2. Connect Workers AI to your worker
Create a Workers AI binding, which allows your worker to access the Workers AI service without having to manage an API key yourself.
To bind Workers AI to your worker, add the following to the end of your wrangler.toml file:
[ai]
binding = "AI" #available in your worker via env.AI
You can also bind Workers AI to a Pages Function. For more information, refer to Functions Bindings.
3. Install the Workers AI client library
npm install @cloudflare/ai
4. Run an inference task in your worker
Update the source/index.ts with the following code:
import { Ai } from '@cloudflare/ai'
export default {
async fetch(request, env) {
const ai = new Ai(env.AI);
const input = { prompt: "What's the origin of the phrase 'Hello, World'" };
const output = await ai.run('@cf/meta/llama-2-7b-chat-int8', input );
return new Response(JSON.stringify(output));
},
};
5. Develop locally with Wrangler
While in your project directory, test Workers AI locally by running:
$ npx wrangler dev --remote
Note - These models currently only run on Cloudflare’s network of GPUs (and not locally), so setting --remote above is a must, and you’ll be prompted to log in at this point.
Wrangler will give you a URL (most likely localhost:8787). Visit that URL, and you’ll see a response like this
{
"response": "Hello, World is a common phrase used to test the output of a computer program, particularly in the early stages of programming. The phrase "Hello, World!" is often the first program that a beginner learns to write, and it is included in many programming language tutorials and textbooks as a way to introduce basic programming concepts. The origin of the phrase "Hello, World!" as a programming test is unclear, but it is believed to have originated in the 1970s. One of the earliest known references to the phrase is in a 1976 book called "The C Programming Language" by Brian Kernighan and Dennis Ritchie, which is considered one of the most influential books on the development of the C programming language.
}
6. Deploy your worker
Finally, deploy your worker to make your project accessible on the Internet:
$ npx wrangler deploy
# Outputs: https://workers-ai.<YOUR_SUBDOMAIN>.workers.dev
And that’s it. You can literally go from zero to deployed AI in minutes. This is obviously a simple example, but shows how easy it is to run Workers AI from any project.
Privacy by default
When Cloudflare was founded, our value proposition had three pillars: more secure, more reliable, and more performant. Over time, we’ve realized that a better Internet is also a more private Internet, and we want to play a role in building it.
That’s why Workers AI is private by default - we don’t train our models, LLM or otherwise, on your data or conversations, and our models don’t learn from your usage. You can feel confident using Workers AI in both personal and business settings, without having to worry about leaking your data. Other providers only offer this fundamental feature with their enterprise version. With us, it’s built in for everyone.
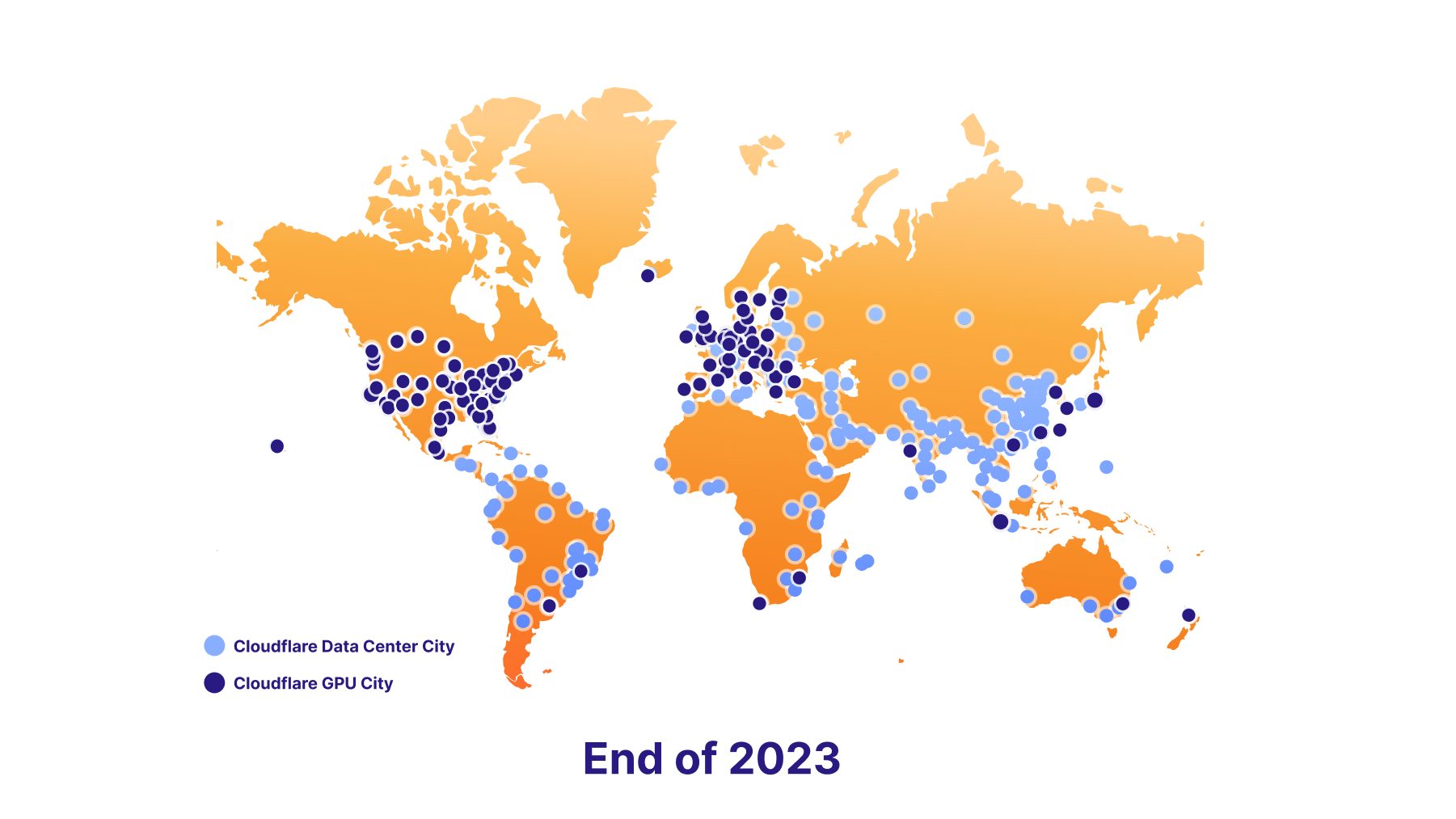
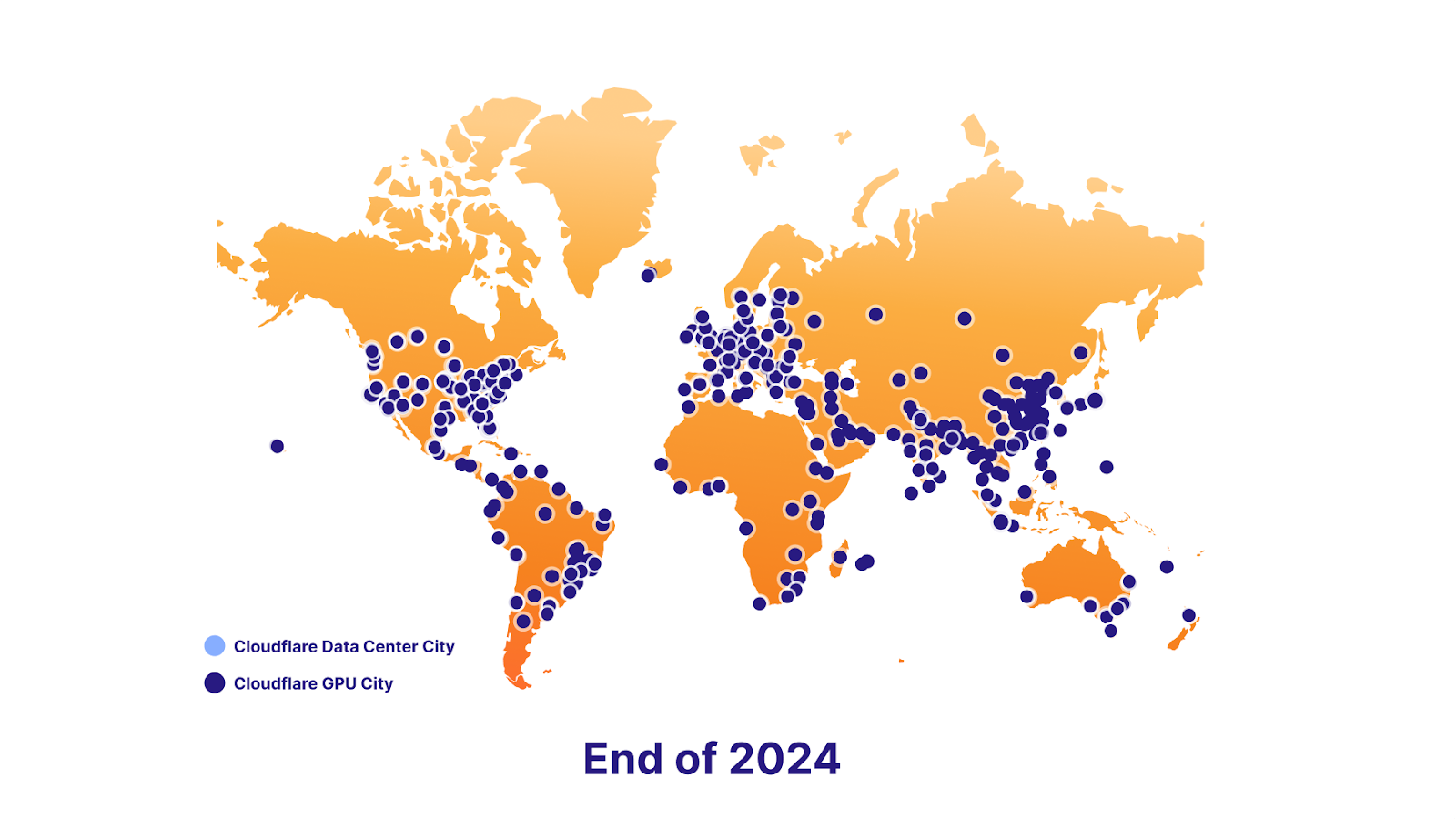
We’re also excited to support data localization in the future. To make this happen, we have an ambitious GPU rollout plan - we’re launching with seven sites today, roughly 100 by the end of 2023, and nearly everywhere by the end of 2024. Ultimately, this will empower developers to keep delivering killer AI features to their users, while staying compliant with their end users’ data localization requirements.
The power of the platform
Vector database - Vectorize
Workers AI is all about running Inference, and making it really easy to do so, but sometimes inference is only part of the equation. Large language models are trained on a fixed set of data, based on a snapshot at a specific point in the past, and have no context on your business or use case. When you submit a prompt, information specific to you can increase the quality of results, making it more useful and relevant. That’s why we’re also launching Vectorize, our vector database that’s designed to work seamlessly with Workers AI. Here’s a quick overview of how you might use Workers AI + Vectorize together.
Example: Use your data (knowledge base) to provide additional context to an LLM when a user is chatting with it.
- Generate initial embeddings: run your data through Workers AI using an embedding model. The output will be embeddings, which are numerical representations of those words.
- Insert those embeddings into Vectorize: this essentially seeds the vector database with your data, so we can later use it to retrieve embeddings that are similar to your users’ query
- Generate embedding from user question: when a user submits a question to your AI app, first, take that question, and run it through Workers AI using an embedding model.
- Get context from Vectorize: use that embedding to query Vectorize. This should output embeddings that are similar to your user’s question.
- Create context aware prompt: Now take the original text associated with those embeddings, and create a new prompt combining the text from the vector search, along with the original question
- Run prompt: run this prompt through Workers AI using an LLM model to get your final result
AI Gateway
That covers a more advanced use case. On the flip side, if you are running models elsewhere, but want to get more out of the experience, you can run those APIs through our AI gateway to get features like caching, rate-limiting, analytics and logging. These features can be used to protect your end point, monitor and optimize costs, and also help with data loss prevention. Learn more about AI gateway here.
Start building today
Try it out for yourself, and let us know what you think. Today we’re launching Workers AI as an open Beta for all Workers plans - free or paid. That said, it’s super early, so…
Warning - It’s an early beta
Usage is not currently recommended for production apps, and limits + access are subject to change.
Limits
We’re initially launching with limits on a per-model basis
- @cf/meta/llama-2-7b-chat-int8: 50 reqs/min globally
Checkout our docs for a full overview of our limits.
Pricing
What we released today is just a small preview to give you a taste of what’s coming (we simply couldn’t hold back), but we’re looking forward to putting the full-throttle version of Workers AI in your hands.
We realize that as you approach building something, you want to understand: how much is this going to cost me? Especially with AI costs being so easy to get out of hand. So we wanted to share the upcoming pricing of Workers AI with you.
While we won’t be billing on day one, we are announcing what we expect our pricing will look like.
Users will be able to choose from two ways to run Workers AI:
- Regular Twitch Neurons (RTN) - running wherever there's capacity at $0.01 / 1k neurons
- Fast Twitch Neurons (FTN) - running at nearest user location at $1.25 / 1k neurons
You may be wondering — what’s a neuron?
Neurons are a way to measure AI output that always scales down to zero (if you get no usage, you will be charged for 0 neurons). To give you a sense of what you can accomplish with a thousand neurons, you can: generate 130 LLM responses, 830 image classifications, or 1,250 embeddings.
Our goal is to help our customers pay only for what they use, and choose the pricing that best matches their use case, whether it’s price or latency that is top of mind.
What’s on the roadmap?
Workers AI is just getting started, and we want your feedback to help us make it great. That said, there are some exciting things on the roadmap.
More models, please
We're launching with a solid set of models that just work, but will continue to roll out new models based on your feedback. If there’s a particular model you'd love to see on Workers AI, pop into our Discord and let us know!
In addition to that, we're also announcing a partnership with Hugging Face, and soon you'll be able to access and run a subset of the Hugging Face catalog directly from Workers AI.
Analytics + observability
Up to this point, we’ve been hyper focussed on one thing - making it really easy for any developer to run powerful AI models in just a few lines of code. But that’s only one part of the story. Up next, we’ll be working on some analytics and observability capabilities to give you insights into your usage + performance + spend on a per-model basis, plus the ability to fig into your logs if you want to do some exploring.
A road to global GPU coverage
Our goal is to be the best place to run inference on Region: Earth, so we're adding GPUs to our data centers as fast as we can.
We plan to be in 100 data centers by the end this year
And nearly everywhere by the end of 2024
We’re really excited to see you build - head over to our docs to get started.
If you need inspiration, want to share something you’re building, or have a question - pop into our Developer Discord.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.