01/7 数据分类分级的难点回顾之前一篇文章内,我们大致讲述了近两年来在各大企业和机构内大热的数据分类分级运动的由来,以及数据分类分级的难点。简单总结起来其困境主要来源于企业内部系统构建的个性化 2023-9-22 13:22:55 Author: www.freebuf.com(查看原文) 阅读量:7 收藏
01/7 数据分类分级的难点回顾
之前一篇文章内,我们大致讲述了近两年来在各大企业和机构内大热的数据分类分级运动的由来,以及数据分类分级的难点。简单总结起来其困境主要来源于企业内部系统构建的个性化程度高,如基于数据字段命名并无法推测出实质数据类型(见下图所示,text1 并不能被自动识别为姓名数据);或者组合类的数据类型和业务关联度高的数据类型,无法抽象为技术可描述的确定规则,如财务数据、金融数据、快递数据这种大类的数据类型;或者一大部分的数据并不具备强规则特征,无法通过对数据内容的识别从而进行类型的分类,如用户姓名、金额数字等等。
回顾上一篇内容:数据分类分级,难成通用且标准化的技术产品
正是由于上述这些困境,让数据分类分级并未带来一场技术上的盛宴,而是上演了一场声势浩大的人工运动,而且是一场针对数据库而不是针对数据的运动,耗时耗力。数据到处都有,除了关系型的数据库里之外,还流动在网络请求里、展示在应用页面中、躺在各类文档上。数据分类分级在数据库层面,人工尚还能上手,到了应用、网络和文档里,那可真是连下手的机会都没有了。这也就解释了本篇文章的标题为何是“数据库分类分级”了。
02/7 数据库分类分级的临时性产出
当前的数据分类分级重在资产盘点,就如同要详细整理出自家有多少资产一样,家里有多少张桌子、几把椅子、存款几何、车几辆、衣服多少件。整理结束,得到的就是不同维度的几张清单,当然这些清单不是打印到 A4 纸上的临时性记录,而是也会以结构化的数据存在,变成描述企业数据资产的数据。那么常见的是哪些清单呢:
1、《数据资产清单》企业内有多少个应用,每个应用对应了多少个数据库,每个数据库对应了多少张数据表,每个数据表的数据量(字段数目、数据行数、数据存储空间大小)等等。2、《数据分类分级清单》与现有数据库一一映射的数据分类分级清单,如下面这样子的表格记录。
| 数据库名 | 数据表名 | 字段名 | 数据类型 | 安全等级 |
|---|---|---|---|---|
| db_customer | cus_details | name | 姓名 | C3 |
| db_customer | cus_details | sex | 性别 | C3 |
| db_customer | cus_details | age | 年龄 | C3 |
| db_customer | cus_details | phone | 电话号码 | C3 |
为什么这些清单叫做临时性的结果呢?因为应用或者业务系统是在不断迭代升级的,其结果就是对应的数据库和表结构会变化,数据库、表格、字段都在不停地增、删、改,对应的资产清单记录由于是人肉加工的结果,缺乏自动化的同步更新机制,势必导致资产清单的过时。对于平台型的企业,如大部分的科技企业,本身都是自研产品为主,那么只需要配合规范的内部开发流程,如应用开发者在涉及到数据库的变动的时候,必须同步更新元数据库(即上述资产清单),否则不予批准代码的推送和应用发布,如此才可保证资产清单的实时性和权威性地位。相反,对于大量依赖第三方服务商提供系统的机构,如政务部门和银行,这个问题将变得非常尖锐,每次系统的更新就意味着对历史资产清单的否定了。
03/7 数据库分类分级的产出能用来做什么
当每一份关于数据安全的国家标准都写明要搞数据分类分级的时候,当每一次安全研讨会议各大专家都在强调要抓紧落实数据分类分级的时候,当每个安全服务商都在宣传自己强大的数据分类分级能力的时候,谁要是唱反调说分类分级不重要,那必定成为众矢之的。但每当我提问,做完了数据分类分级,接下来做什么的时候,换来的通常是尴尬的一阵沉默。沉默的是拿着各类数据资产清单,真的不知道该如何下手去用起来,大家的愿景还是极其朴素和一致的,那就是“基于分类分级的结果,针对不同安全等级的敏感数据,施加不同程度的安全管控策略”。
在安全从业者的构想里,可以落地这样一些安全管控敏感数据的场景:
1、依据不同的数据安全等级,施行不同的数据使用审批流程,如数据表格的使用审批流程(数据库层面),应用内数据下载的审批流程(应用层面)。2、高敏感数据的脱敏使用(应用层面)。3、敏感数据的外发检测,如员工通过各类 IM、邮箱、U 盘等外发文档的时候,提取内部所含的敏感数据,判断外发行为是否有异常(文档层面)。
当我们判断想要实现的安全管控效果能否与分类分级结果相配合时,只需要看作用的对象是不是数据库即可,还是因为如题目揭示的那样现如今的分类分级结果是针对数据库的。因此针对数据库相关的权限审批,脱敏,有效期控制等策略,技术上是非常直观地就能实现,只需将现有的数据管理平台同分类分级查询服务进行集成即可。
反观其它针对应用层面和文档层面的安全控制,几乎难以有效利用数据库分类分级的成果。
04/7 应用层面的数据管控,无法与数据库分类分级结果联动
这是一个令人沮丧的结论,却又似乎有些反直觉,因为在一般的理解上应用的数据也都是在对应的数据库里,如下面这张图如此般清晰的逻辑和数据链路,难道应用自己不知道某个具体的数据(如图中的电话号码 1321333333)来自于哪个数据库的哪张表中的哪个字段,进而去数据分类分级的清单结果里反查出其具体的数据类型和安全等级吗?
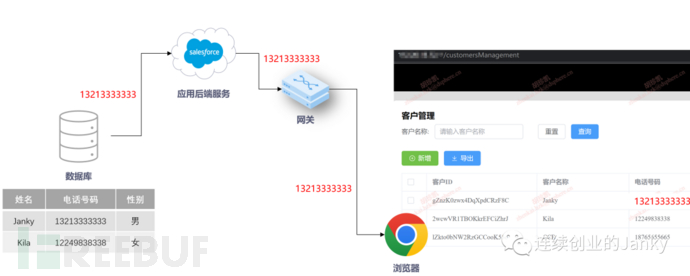
答案是真的做不到,沮丧就沮丧在这里。我们稍做一下解释,应用后端服务一定知道这个电话号码来自于数据库的哪个位置,因为查询数据的 SQL 语句就是应用后端服务自己组装出来的。但是一旦数据通过网络接口传递给了下一层的网关,数据的上下文信息也就丢失了,网关能看到的就是赤裸裸的数据本身。同样当数据被传递到浏览器,浏览器和应用自身的前端页面也只是简单的负责数据的渲染和展示即可,对后端数据库完全没有任何感知。由此就可看出,数据链路只能保持一跳,即数据库到应用后端服务这一跳而已,再往后的环节就完全丧失了数据库的元信息,从而也就无法利用基于数据库分类分级的结果了。
05/7 应用层面的数据管控,只能依靠应用层面的数据分类分级
当我们想要动态的依据应用内的敏感数据类型和等级,进行个性化的数字水印、数据脱敏、数据下载和导出管控、以及数据审批的时候,我们必须以某种特定的方式实现应用层面的数据识别和分类分级的能力,因为我们别无选择,我们无法利用数据库层面的分类分级结果。但我们是否也需要仿照建立数据库的资产清单那样,去建立一个针对应用的分类分级结果集合吗?针对一个常规的应用,并不需要,也不必要,因为相对于数据库有比较稳定的结构(数据量在不断增长,但数据结构变化并不一定很大),应用具有极强的动态性,应用的页面、接口都可能不断变化,那么建立一个相对不变的应用级别的数据清单就如同要去给沙滩上的沙粒画一张位置图谱。应用,需要具备动态的数据识别和分类分级的能力。拆解其技术模型,位于最核心地位的当属应用数据的解析和敏感数据的识别。
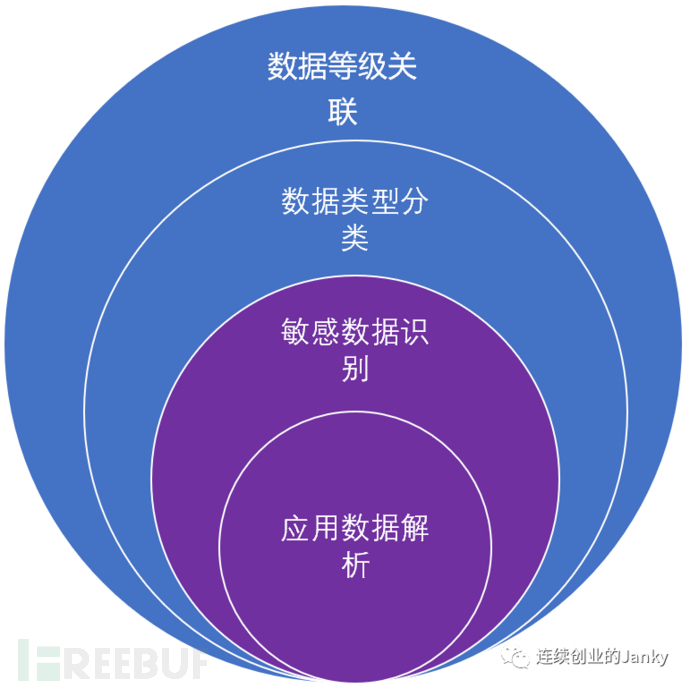 针对应用,需要具备动态的分类分级能力;针对数据库,需要具备预先分类分级的资产清单。两者的本质差异还在于,应用得先获得数据才能处理数据。而针对数据库的操作(如申请数据表权限),总不能先把数据全给你,再基于数据判断回收不能给的数据,而是要先明确给什么数据再把数据给过去。
针对应用,需要具备动态的分类分级能力;针对数据库,需要具备预先分类分级的资产清单。两者的本质差异还在于,应用得先获得数据才能处理数据。而针对数据库的操作(如申请数据表权限),总不能先把数据全给你,再基于数据判断回收不能给的数据,而是要先明确给什么数据再把数据给过去。
06/7 应用层面的数据分类分级可行方案选择
依照数据的流转路径,敏感数据识别的节点在逻辑上可以有如下多种选择,当然有些方案在逻辑上成立,但是却不一定具有很好现实可操作性和落地性。
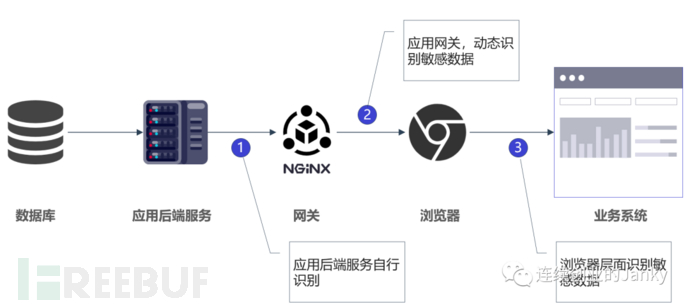
1、应用后端服务
针对自研应用,在后端服务实现数据的识别,主要在于研发成本,不能一蹴而就,随着业务系统的变化要不断添加数据识别代码。后端识别逻辑难以抽象公共模块组件,进行统一的数据识别研发成本大。
2、网关层面数据识别
在应用前端(客户端或者浏览器)与后端服务之间,串联一个网关,在网关内过滤网络流量,进行流量内的数据识别。网关面临着应用性能和稳定性的担忧,常常成为该方案被采用的最大阻碍。
3、浏览器层面数据识别
无论是采用专用浏览器,还是特定浏览器插件的模式,其实现逻辑都是在应用页面被渲染出来之前进行自动的数据识别。当然从其形式来看适用场景也是受限的,仅限于Web系统。浏览器研发成本高,一般企业没有能力去构建这样的解决方案,只能寻找第三方,目前宣称有这样安全能力的在国内只有数影星球一家。
07/7 数据分类分级的终极局面
数据分类分级本身并不是目的,真正的目标还是在于有针对性地去保护真正重要的数据,既保护企业自身的数据资产也保护公民的数据和隐身权益。当前各大企业都在如火如荼的开展数据库层面的分类分级工作,而尚未开始应用层面的数据分类分级,一来由于数据库更容易被拖库从而造成大量的数据泄露,二来也是由于相对于应用来说,数据库的分类分级工作更容易开展。
但是回头再一想,真正的分类分级保护其实最终针对的还是“正常”的用户,如企业自家员工、外包人员、合作机构等展开的不同安全等级的控制,而并非针对以非法入侵手段进行数据窃取和破坏的高级黑客。由此判断,应用层面的数据分类分级工作应该更为重要才是。
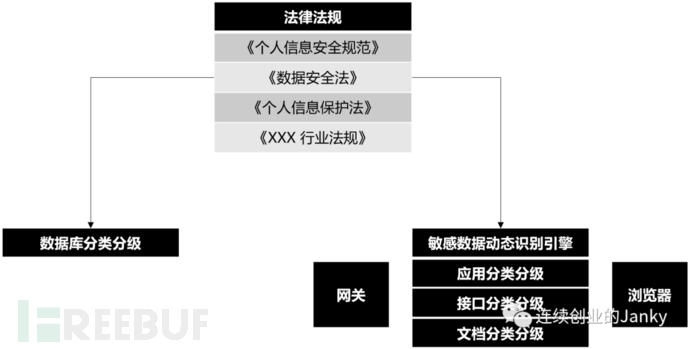
最终针对数据分类分级的落地和实现,作者判断大致会呈现出这样的架构。
如有侵权请联系:admin#unsafe.sh