cckuailong
读完需要
速读仅需 2 分钟
转载自宝玉推文:https://twitter.com/dotey/status/1693839769619292164
1
论文又名《Chat 凉宫春日,将京阿尼的人物带到现实》
原论文:https://arxiv.org/abs/2308.09597
中文版:https://github.com/LC1332/Chat-Haruhi-Suzumiya/blob/main/notebook/arxiv_paper.md
2
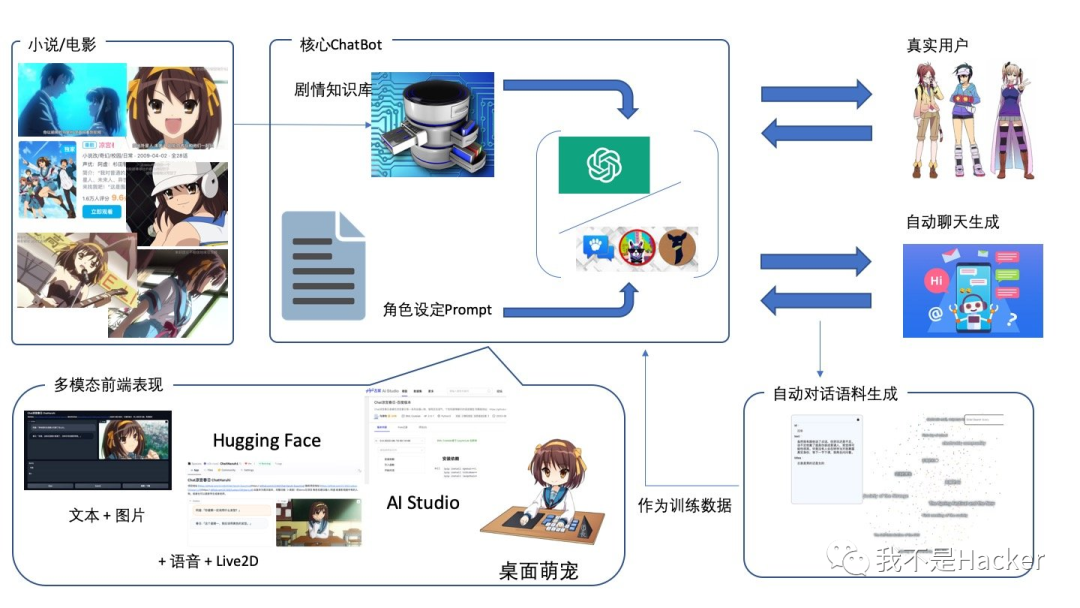
ChatHaruhi 是一个专注于模仿动漫影视角色人物、让用户可以和这些虚拟任务聊天对话的技术框架。
比如让大语言模型(LLM)扮演凉宫春日,当用户提问,LLM 扮演的凉宫春日可以引用动漫中的原始剧情来回复,语气也可以做到惟妙惟肖。
3
熟悉 Prompt Engineering 的同学可能觉得这事没什么难的,一条 Prompt 就可以搞定:
“现在请你扮演{某电视剧}中的{角色},基于该角色所有的知识,像{角色}那样用{角色}的语气、方式和词汇来回答,不要写任何解释。以下是用户的问题:"你好,{角色}"。”
对于知名的角色或者人物,这样的 Prompt 是有效的,但如果这个角色是 LLM 以前没训练过的,或者数据很少,那可能效果不会太理想。
那么可能有人觉得基于角色的资料和对话微调一个模型出来也可以。微调的问题在于如果角色数据不够多,那么效果不太好,幻觉严重,另外像 GPT-4,目前还不支持微调。
4
目前基于上下文的学习(In-context Learning)是比较好的解决方案,也就是在 Prompt 里面,加入这个角色的一些背景知识和以前的对话内容作为参考,那 LLM 就可以很准确的模仿出这个角色的对话风格。
举例来说,如果用户问了虚拟的凉宫春日一个问题:“同学请自我介绍一下”,
那么 ChatHaruhi 就会去数据库里面把凉宫春日在动漫里的对话记录和旁白找出来,例如:
旁白:在开学的时候,老师让所有人进行自我介绍春日:「我毕业于东中,叫做凉宫春日。」春日:「我对普通的人类没有兴趣,如果你们中有外星人,未来人,异世界的人或者超能力者的话,就尽管来找我吧!以上。」
再加上系统 Prompt 的描述:
你正在扮演凉宫春日,上文给定了一些小说中的经典桥段。如果我问的问题和小说中的合词高度重复,那你就配合我进行演出。如果我问的问题和小说中的事件相关,请结合小说的内容进行回复。如果我问的问题超出小说中的范围,请也用一致性的语气回复。
那么 LLM 就可以根据系统 Prompt 和历史的资料,生成一个新的回复,即使这个回复从来没有在动漫中出现过,但是依然能保持人物的风格:春日:「我毕业于东中,叫做凉宫春日。我对普通的人类没有兴趣,如果你们中有外星人,未来人,异世界的人或者超能力者的话,就尽管来找我吧!
5
项目中一共提供了 32 个角色 54K 的对话数据,其中包括电影、小说、剧本的语料。
对于视频对话,如果字幕中有就从字幕中提取,如果字幕中没有,他们借助 Whisper 做语音识别。
一个有意思的地方是,像原神这样的游戏里面的角色的对话数量不够多,于是他们基于现有的角色对话,使用一些常见问题,借助 ChatGPT 生成了大量的虚拟对话,这样他们将对话数据从 23000 条原始对话,扩充到了 54000 多条对话,包含了大量模拟生成的数据。
6
ChatHaruhi 不仅可以模拟动漫角色聊天对话,还能模仿角色的声音。
他们的语音模拟生成是用的 VITS
如有侵权请联系:admin#unsafe.sh