
Loading...



Once my holidays had passed, I found myself reluctantly reemerging into the world of the living. I powered on a corporate laptop, scared to check on my email inbox. However, before turning on the browser, obviously, I had to run a ping. Debugging the network is a mandatory first step after a boot, right? As expected, the network was perfectly healthy but what caught me off guard was this message:
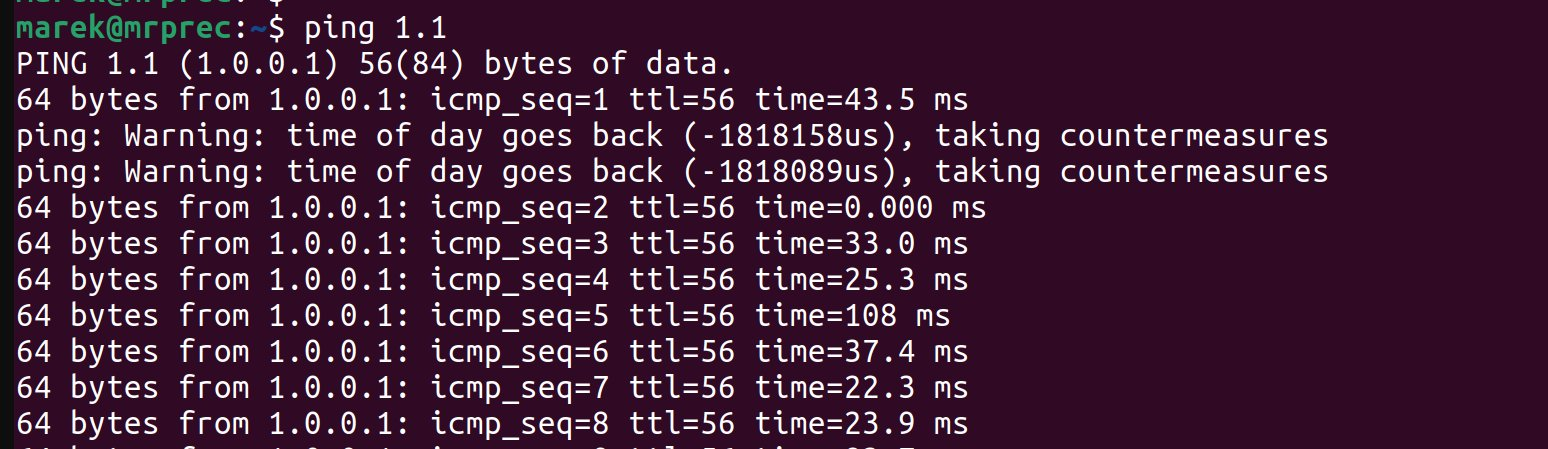
I was not expecting ping to take countermeasures that early on in a day. Gosh, I wasn't expecting any countermeasures that Monday!
Once I got over the initial confusion, I took a deep breath and collected my thoughts. You don't have to be Sherlock Holmes to figure out what has happened. I'm really fast - I started ping before the system NTP daemon synchronized the time. In my case, the computer clock was rolled backward, confusing ping.
While this doesn't happen too often, a computer clock can be freely adjusted either forward or backward. However, it's pretty rare for a regular network utility, like ping, to try to manage a situation like this. It's even less common to call it "taking countermeasures". I would totally expect ping to just print a nonsensical time value and move on without hesitation.
Ping developers clearly put some thought into that. I wondered how far they went. Did they handle clock changes in both directions? Are the bad measurements excluded from the final statistics? How do they test the software?
I can't just walk past ping "taking countermeasures" on me. Now I have to understand what ping did and why.
Understanding ping
An investigation like this starts with a quick glance at the source code:
* P I N G . C
*
* Using the InterNet Control Message Protocol (ICMP) "ECHO" facility,
* measure round-trip-delays and packet loss across network paths.
*
* Author -
* Mike Muuss
* U. S. Army Ballistic Research Laboratory
* December, 1983
Ping goes back a long way. It was originally written by Mike Muuss while at the U. S. Army Ballistic Research Laboratory, in 1983, before I was born. The code we're looking for is under iputils/ping/ping_common.c gather_statistics() function:

The code is straightforward: the message in question is printed when the measured RTT is negative. In this case ping resets the latency measurement to zero. Here you are: "taking countermeasures" is nothing more than just marking an erroneous measurement as if it was 0ms.
But what precisely does ping measure? Is it the wall clock? The man page comes to the rescue. Ping has two modes.
The "old", -U mode, in which it uses the wall clock. This mode is less accurate (has more jitter). It calls gettimeofday before sending and after receiving the packet.
The "new", default, mode in which it uses "network time". It calls gettimeofday before sending, and gets the receive timestamp from a more accurate SO_TIMESTAMP CMSG. More on this later.
Tracing gettimeofday is hard
Let's start with a good old strace:
$ strace -e trace=gettimeofday,time,clock_gettime -f ping -n -c1 1.1 >/dev/null
... nil ...
It doesn't show any calls to gettimeofday. What is going on?
On modern Linux some syscalls are not true syscalls. Instead of jumping to the kernel space, which is slow, they remain in userspace and go to a special code page provided by the host kernel. This code page is called vdso. It's visible as a .so library to the program:
$ ldd `which ping` | grep vds
linux-vdso.so.1 (0x00007ffff47f9000)
Calls to the vdso region are not syscalls, they remain in userspace and are super fast, but classic strace can't see them. For debugging it would be nice to turn off vdso and fall back to classic slow syscalls. It's easier said than done.
There is no way to prevent loading of the vdso. However there are two ways to convince a loaded program not to use it.
The first technique is about fooling glibc into thinking the vdso is not loaded. This case must be handled for compatibility with ancient Linux. When bootstrapping in a freshly run process, glibc inspects the Auxiliary Vector provided by ELF loader. One of the parameters has the location of the vdso pointer, the man page gives this example:
void *vdso = (uintptr_t) getauxval(AT_SYSINFO_EHDR);
A technique proposed on Stack Overflow works like that: let's hook on a program before execve() exits and overwrite the Auxiliary Vector AT_SYSINFO_EHDR parameter. Here's the novdso.c code. However, the linked code doesn't quite work for me (one too many kill(SIGSTOP)), and has one bigger, fundamental flaw. To hook on execve() it uses ptrace() therefore doesn't work under our strace!
$ strace -f ./novdso ping 1.1 -c1 -n
...
[pid 69316] ptrace(PTRACE_TRACEME) = -1 EPERM (Operation not permitted)
While this technique of rewriting AT_SYSINFO_EHDR is pretty cool, it won't work for us. (I wonder if there is another way of doing that, but without ptrace. Maybe with some BPF? But that is another story.)
A second technique is to use LD_PRELOAD and preload a trivial library overloading the functions in question, and forcing them to go to slow real syscalls. This works fine:
$ cat vdso_override.c
#include <sys/syscall.h>
#include <sys/time.h>
#include <time.h>
#include <unistd.h>
int gettimeofday(struct timeval *restrict tv, void *restrict tz) {
return syscall(__NR_gettimeofday, (long)tv, (long)tz, 0, 0, 0, 0);
}
time_t time(time_t *tloc) {
return syscall(__NR_time, (long)tloc, 0, 0, 0, 0, 0);
}
int clock_gettime(clockid_t clockid, struct timespec *tp) {
return syscall(__NR_clock_gettime, (long)clockid, (long)tp, 0, 0, 0, 0);
}
To load it:
$ gcc -Wall -Wextra -fpic -shared -o vdso_override.so vdso_override.c
$ LD_PRELOAD=./vdso_override.so \
strace -e trace=gettimeofday,clock_gettime,time \
date
clock_gettime(CLOCK_REALTIME, {tv_sec=1688656245 ...}) = 0
Thu Jul 6 05:10:45 PM CEST 2023
+++ exited with 0 +++
Hurray! We can see the clock_gettime call in strace output. Surely we'll also see gettimeofday from our ping, right?
Not so fast, it still doesn't quite work:
$ LD_PRELOAD=./vdso_override.so \
strace -c -e trace=gettimeofday,time,clock_gettime -f \
ping -n -c1 1.1 >/dev/null
... nil ...
To suid or not to suid
I forgot that ping might need special permissions to read and write raw packets. Historically it had a suid bit set, which granted the program elevated user identity. However LD_PRELOAD doesn't work with suid. When a program is being loaded a dynamic linker checks if it has suid bit, and if so, it ignores LD_PRELOAD and LD_LIBRARY_PATH settings.
However, does ping need suid? Nowadays it's totally possible to send and receive ICMP Echo messages without any extra privileges, like this:
from socket import *
import struct
sd = socket(AF_INET, SOCK_DGRAM, IPPROTO_ICMP)
sd.connect(('1.1', 0))
sd.send(struct.pack("!BBHHH10s", 8, 0, 0, 0, 1234, b'payload'))
data = sd.recv(1024)
print('type=%d code=%d csum=0x%x id=%d seq=%d payload=%s' % struct.unpack_from("!BBHHH10s", data))
Now you know how to write "ping" in eight lines of Python. This Linux API is known as ping socket. It generally works on modern Linux, however it requires a correct sysctl, which is typically enabled:
$ sysctl net.ipv4.ping_group_range
net.ipv4.ping_group_range = 0 2147483647
The ping socket is not as mature as UDP or TCP sockets. The "ICMP ID" field is used to dispatch an ICMP Echo Response to an appropriate socket, but when using bind() this property is settable by the user without any checks. A malicious user can deliberately cause an "ICMP ID" conflict.
But we're not here to discuss Linux networking API's. We're here to discuss the ping utility and indeed, it's using the ping sockets:
$ strace -e trace=socket -f ping 1.1 -nUc 1
socket(AF_INET, SOCK_DGRAM, IPPROTO_ICMP) = 3
socket(AF_INET6, SOCK_DGRAM, IPPROTO_ICMPV6) = 4
Ping sockets are rootless, and ping, at least on my laptop, is not a suid program:
$ ls -lah `which ping`
-rwxr-xr-x 1 root root 75K Feb 5 2022 /usr/bin/ping
So why doesn't the LD_PRELOAD? It turns out ping binary holds a CAP_NET_RAW capability. Similarly to suid, this is preventing the library preloading machinery from working:
$ getcap `which ping`
/usr/bin/ping cap_net_raw=ep
I think this capability is enabled only to handle the case of a misconfigured net.ipv4.ping_group_range sysctl. For me ping works perfectly fine without this capability.
Rootless is perfectly fine
Let's remove the CAP_NET_RAW and try out LD_PRELOAD hack again:
$ cp `which ping` .
$ LD_PRELOAD=./vdso_override.so strace -f ./ping -n -c1 1.1
...
setsockopt(3, SOL_SOCKET, SO_TIMESTAMP_OLD, [1], 4) = 0
gettimeofday({tv_sec= ... ) = 0
sendto(3, ...)
setitimer(ITIMER_REAL, {it_value={tv_sec=10}}, NULL) = 0
recvmsg(3, { ... cmsg_level=SOL_SOCKET,
cmsg_type=SO_TIMESTAMP_OLD,
cmsg_data={tv_sec=...}}, )
We finally made it! Without -U, in the "network timestamp" mode, ping:
- Sets SO_TIMESTAMP flag on a socket.
- Calls gettimeofday before sending the packet.
- When fetching a packet, gets the timestamp from the CMSG.
Fault injection - fooling ping
With strace up and running we can finally do something interesting. You see, strace has a little known fault injection feature, named "tampering" in the manual:
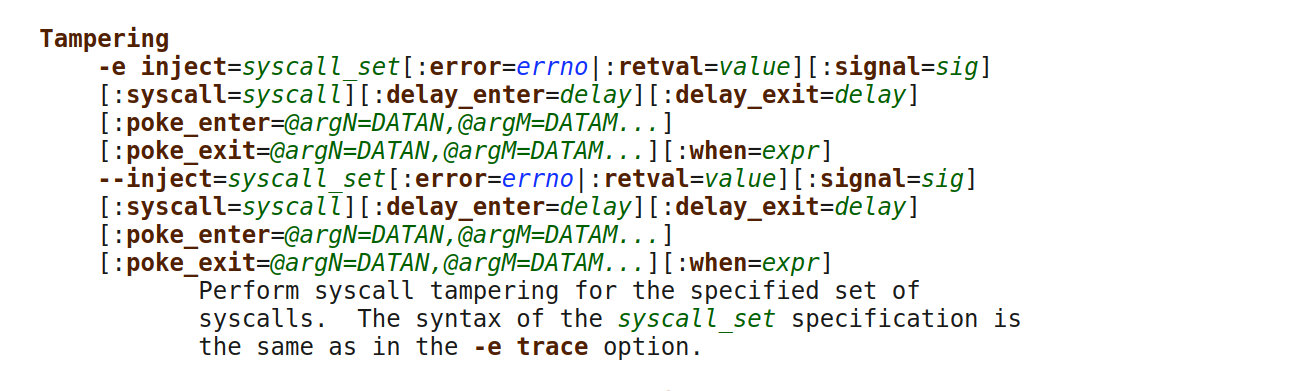
With a couple of command line parameters we can overwrite the result of the gettimeofday call. I want to set it forward to confuse ping into thinking the SO_TIMESTAMP time is in the past:
LD_PRELOAD=./vdso_override.so \
strace -o /dev/null -e trace=gettimeofday \
-e inject=gettimeofday:[email protected]=ff:when=1 -f \
./ping -c 1 -n 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
./ping: Warning: time of day goes back (-59995290us), taking countermeasures
./ping: Warning: time of day goes back (-59995104us), taking countermeasures
64 bytes from 1.1.1.1: icmp_seq=1 ttl=60 time=0.000 ms
--- 1.1.1.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.000/0.000/0.000/0.000 ms
It worked! We can now generate the "taking countermeasures" message reliably!
While we can cheat on the gettimeofday result, with strace it's impossible to overwrite the CMSG timestamp. Perhaps it might be possible to adjust the CMSG timestamp with Linux time namespaces, but I don't think it'll work. As far as I understand, time namespaces are not taken into account by the network stack. A program using SO_TIMESTAMP is deemed to compare it against the system clock, which might be rolled backwards.
Fool me once, fool me twice
At this point we could conclude our investigation. We're now able to reliably trigger the "taking countermeasures" message using strace fault injection.
There is one more thing though. When sending ICMP Echo Request messages, does ping remember the send timestamp in some kind of hash table? That might be wasteful considering a long-running ping sending thousands of packets.
Ping is smart, and instead puts the timestamp in the ICMP Echo Request packet payload!
Here's how the full algorithm works:
- Ping sets the SO_TIMESTAMP_OLD socket option to receive timestamps.
- It looks at the wall clock with gettimeofday.
- It puts the current timestamp in the first bytes of the ICMP payload.
- After receiving the ICMP Echo Reply packet, it inspects the two timestamps: the send timestamp from the payload and the receive timestamp from CMSG.
- It calculates the RTT delta.
This is pretty neat! With this algorithm, ping doesn't need to remember much, and can have an unlimited number of packets in flight! (For completeness, ping maintains a small fixed-size bitmap to account for the DUP! packets).
What if we set a packet length to be less than 16 bytes? Let's see:
$ ping 1.1 -c2 -s0
PING 1.1 (1.0.0.1) 0(28) bytes of data.
8 bytes from 1.0.0.1: icmp_seq=1 ttl=60
8 bytes from 1.0.0.1: icmp_seq=2 ttl=60
--- 1.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1002ms
In such a case ping just skips the RTT from the output. Smart!
Right... this opens two completely new subjects. While ping was written back when everyone was friendly, today’s Internet can have rogue actors. What if we spoofed responses to confuse ping. Can we: cut the payload to prevent ping from producing RTT, and spoof the timestamp and fool the RTT measurements?
Both things work! The truncated case will look like this to the sender:
$ ping 139.162.188.91
PING 139.162.188.91 (139.162.188.91) 56(84) bytes of data.
8 bytes from 139.162.188.91: icmp_seq=1 ttl=53 (truncated)
The second case, of an overwritten timestamp, is even cooler. We can move timestamp forwards causing ping to show our favorite "taking countermeasures" message:
$ ping 139.162.188.91 -c 2 -n
PING 139.162.188.91 (139.162.188.91) 56(84) bytes of data.
./ping: Warning: time of day goes back (-1677721599919015us), taking countermeasures
./ping: Warning: time of day goes back (-1677721599918907us), taking countermeasures
64 bytes from 139.162.188.91: icmp_seq=1 ttl=53 time=0.000 ms
./ping: Warning: time of day goes back (-1677721599905149us), taking countermeasures
64 bytes from 139.162.188.91: icmp_seq=2 ttl=53 time=0.000 ms
--- 139.162.188.91 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.000/0.000/0.000/0.000 ms
Alternatively we can move the time in the packet backwards causing ping to show nonsensical RTT values:
$ ./ping 139.162.188.91 -c 2 -n
PING 139.162.188.91 (139.162.188.91) 56(84) bytes of data.
64 bytes from 139.162.188.91: icmp_seq=1 ttl=53 time=1677721600430 ms
64 bytes from 139.162.188.91: icmp_seq=2 ttl=53 time=1677721600084 ms
--- 139.162.188.91 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1000ms
rtt min/avg/max/mdev = 1677721600084.349/1677721600257.351/1677721600430.354/-9223372036854775.-808 ms
We proved that "countermeasures" work only when time moves in one direction. In another direction ping is just fooled.
Here's a rough scapy snippet that generates an ICMP Echo Response fooling ping:
# iptables -I INPUT -i eth0 -p icmp --icmp-type=8 -j DROP
import scapy.all as scapy
import struct
def custom_action(echo_req):
try:
payload = bytes(echo_req[scapy.ICMP].payload)
if len(payload) >= 8:
ts, tu = struct.unpack_from("<II", payload)
payload = struct.pack("<II", (ts-0x64000000)&0xffffffff, tu) \
+ payload[8:]
echo_reply = scapy.IP(
dst=echo_req[scapy.IP].src,
src=echo_req[scapy.IP].dst,
) / scapy.ICMP(type=0, code=0,
id=echo_req[scapy.ICMP].id,
seq=echo_req.payload.seq,
) / payload
scapy.send(echo_reply,iface=iface)
except Exception as e:
pass
scapy.sniff(filter="icmp and icmp[0] = 8", iface=iface, prn=custom_action)
Leap second
In practice, how often does time change on a computer? The NTP daemon adjusts the clock all the time to account for any drift. However, these are very small changes. Apart from initial clock synchronization after boot or sleep wakeup, big clock shifts shouldn't really happen.
There are exceptions as usual. Systems that operate in virtual environments or have unreliable Internet connections often experience their clocks getting out of sync.
One notable case that affects all computers is a coordinated clock adjustment called a leap second. It causes the clock to move backwards, which is particularly troublesome. An issue with handling leap second caused our engineers a headache in late 2016.
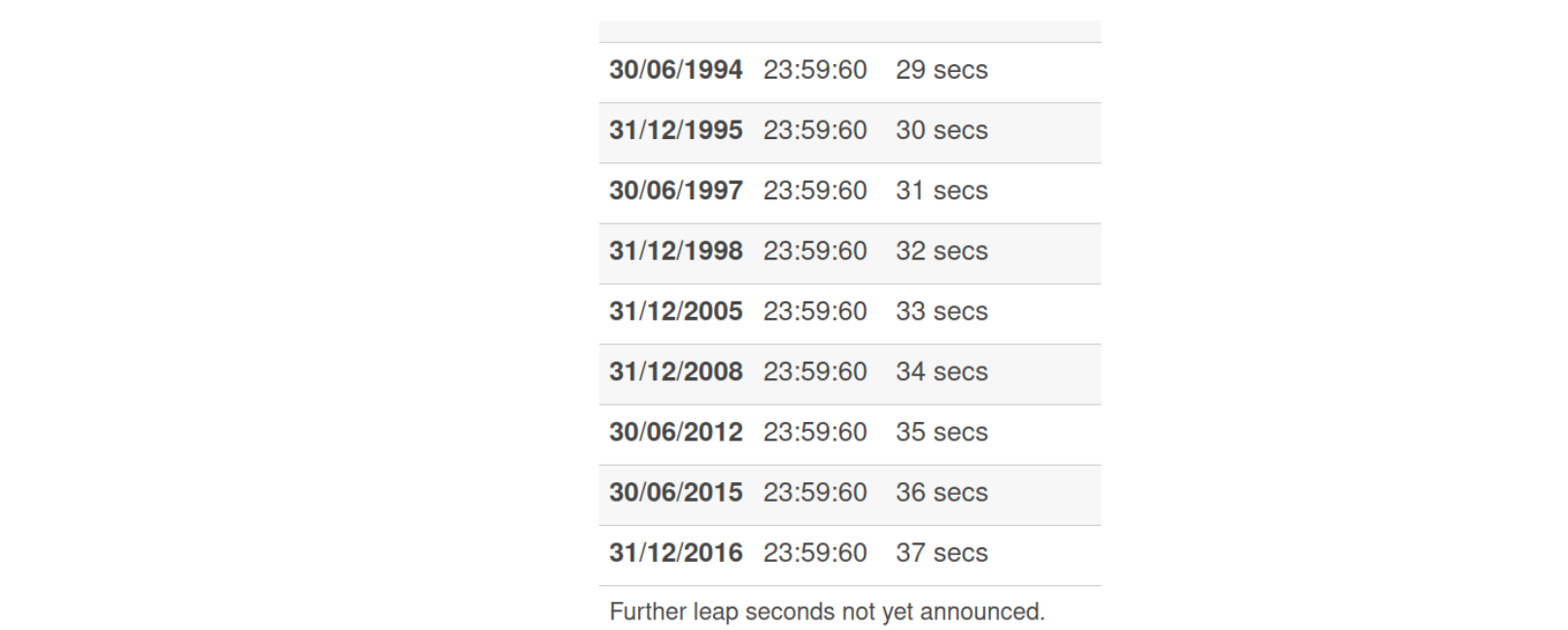
Leap seconds often cause issues, so the current consensus is to deprecate them by 2035. However, according to Wikipedia the solution seem to be to just kick the can down the road:
A suggested possible future measure would be to let the discrepancy increase to a full minute, which would take 50 to 100 years, and then have the last minute of the day taking two minutes in a "kind of smear" with no discontinuity.
In any case, there hasn't been a leap second since 2016, there might be some in the future, but there likely won't be any after 2035. Many environments already use a leap second smear to avoid the problem of clock jumping back.
In most cases, it might be completely fine to ignore the clock changes. When possible, to count time durations use CLOCK_MONOTONIC, which is bulletproof.
We haven't mentioned daylight savings clock adjustments here because, from a computer perspective they are not real clock changes! Most often programmers deal with the operating system clock, which is typically set to the UTC timezone. DST timezone is taken into account only when pretty printing the date on screen. The underlying software operates on integer values. Let's consider an example of two timestamps, which in my Warsaw timezone, appear as two different DST timezones. While it may like the clock rolled back, this is just a user interface illusion. The integer timestamps are sequential:
$ date [email protected]$[1698541199+0]
Sun Oct 29 02:59:59 AM CEST 2023
$ date [email protected]$[1698541199+1]
Sun Oct 29 02:00:00 AM CET 2023
Lessons
Arguably, the clock jumping backwards is a rare occurrence. It's very hard to test for such cases, and I was surprised to find that ping made such an attempt. To avoid the problem, to measure the latency ping might use CLOCK_MONOTONIC, its developers already use this time source in another place.
Unfortunately this won't quite work here. Ping needs to compare send timestamp to receive timestamp from SO_TIMESTAMP CMSG, which uses the non-monotonic system clock. Linux API's are sometimes limited, and dealing with time is hard. For time being, clock adjustments will continue to confuse ping.
In any case, now we know what to do when ping is "taking countermeasures"! Pull down your periscope and check the NTP daemon status!
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.