原文标题:VulCNN: An Image-inspired Scalable Vulnerability Detection System原文作者:Yueming Wu, Deqing Zou, S 2023-6-21 22:27:19 Author: 安全学术圈(查看原文) 阅读量:50 收藏
原文标题:VulCNN: An Image-inspired Scalable Vulnerability Detection System
原文作者:Yueming Wu, Deqing Zou, Shihan Dou, Wei Yang, Duo Xu, Hai Jin
原文链接:https://wu-yueming.github.io/Files/ICSE2022_VulCNN.pdf
发表会议:ICSE'22
笔记作者:陈彦志@安全学术圈
笔记小编:小编@安全学术圈
基于深度学习进行源代码漏洞检测一般有两种方法,一种方法是将源代码看作文本信息,然后利用NLP方法来检测漏洞;还有一种方法是将程序语义看作图来表示,利用图神经网络的方法来检测漏洞。两种方法各有优劣,第一种方法的缺点主要是利用NLP方法缺少程序语义,所以漏洞检测不够精确。第二种方法的缺点是需要分析图,时间成本高。
https://github.com/CGCL-codes/VulCNN
本文作者的主要创新点是在利用图神经网络进行源代码漏洞挖掘的基础上引入了社交网络中心性分析。通过该方法强化图中关键结点(即源代码中具体代码行)特征,弱化非关键结点特征,进而提高泛化性能。
很多情况下,在训练集上表现很好(分类精度几乎100%)的分类器,实际使用中多数情况下表现都不好。因为分类器会把训练样本自身的一些特点当作所有潜在样本都会具有的一般特征。所以,为了训练出一个实际表现良好的分类器,应该让分类器从训练样本中尽可能学到适用于所有潜在样本的“普遍规律”,这样才能在遇到新样本时做出正确判别。
作者根据上述创新点开发出VulCNN项目。
4.1 VulCNN framework
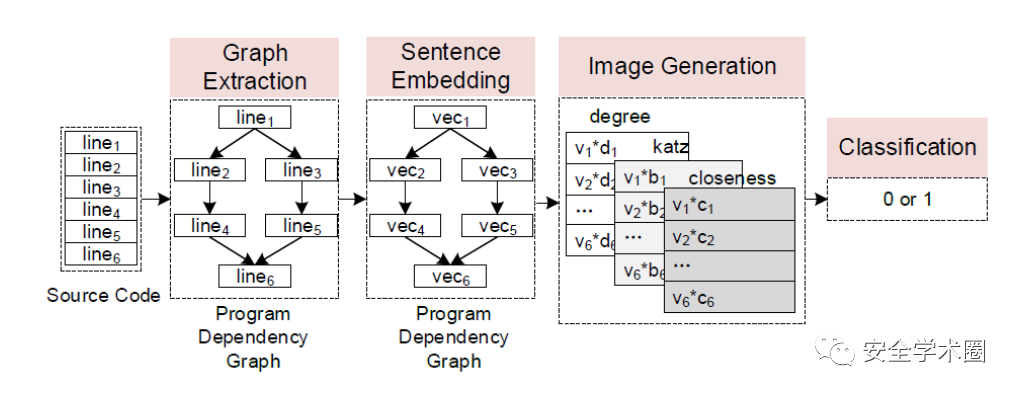
整体框架如下图所示。
整体处理流程主要分为上述四个步骤,即 Graph Extraction,Sentence Embedding, Image Generation 和 Classification。
Graph Extraction: 将给定的函数源代码标准化并生成程序依赖图(PDG)
Sentence Embedding:给定函数的每一行代码即程序依赖图中的每个结点,该步骤将每个节点作为一个语句嵌入一个vector中。
Image Generation:通过centrality analysis 获取每个结点(每行代码)的重要程度,然后乘以向量,最后生成图像。
Classification: 训练CNN模型,然后利用该模型对上一步生成的图像进行漏洞检测。
4.1.1 Graph Extraction
首先将目标函数源代码进行标准化,使得目标程序在维持程序语义的前提下格式更加统一规范。
利用C/C++开源源代码分析平台Joern生成程序依赖图(PDG),目标函数的每一行代码即为PDG中的一个结点。
4.1.2 Sentence Embedding
利用sent2vec实现Sentence Embedding,即将PDG中的每个结点作为一个语句转换为一个固定长度的向量。
Sentence embedding(句子嵌入)是将文本句子转化为连续向量表示的技术。它的主要作用是将自然语言文本转换为计算机可以理解和处理的形式。以下是一些 Sentence embedding 的作用:
文本相似度计算:通过将句子转换为向量表示,可以计算句子之间的相似度或距离。这对于文本分类、信息检索和聚类等任务非常有用。 文本分类:通过将句子嵌入为向量,可以将其输入到机器学习或深度学习模型中进行文本分类。句子嵌入可以捕捉句子的语义信息,帮助模型理解文本的含义。 文本生成:在生成文本的任务中,可以使用句子嵌入来帮助模型生成连贯、语义正确的句子。通过将句子嵌入映射到生成模型的隐空间,可以生成与输入文本相关的输出。 信息检索:在信息检索系统中,可以使用句子嵌入来表示查询和文档,从而提高搜索的准确性和效率。将查询与文档进行嵌入表示后,可以计算它们之间的相似度,并返回最相关的文档。 句子聚类:通过将句子嵌入为向量表示,可以进行句子聚类,将语义上相似的句子分组在一起。这对于组织大规模文本数据、主题提取和摘要生成等任务很有帮助。 总的来说,句子嵌入可以将自然语言文本转化为向量表示,从而在各种自然语言处理任务中提供语义信息,帮助计算机理解和处理文本数据。
4.1.3 Image Generation
通过上述步骤可以得到一个每个结点都是用vector表示的PDG。在该步骤,原文把这个PDG视为一个社交网络(social network),并利用社交网络中心性分析(Social Network Centrality Analysis)来获取目标函数每行代码的重要程度。
社交网络中心性分析(Social Network Centrality Analysis)是一种用于评估社交网络中节点重要性或影响力的方法。在社交网络中,节点可以表示个人、组织或其他实体,而边表示节点之间的关系或连接。
中心性是用来衡量节点在网络中的重要程度的指标,它可以帮助我们理解社交网络中的节点位置、影响力和角色。中心性分析通常用于揭示社交网络的结构、识别关键节点以及预测信息传播、影响扩散等。
以下是几种常见的社交网络中心性指标:
度中心性(Degree Centrality):度中心性衡量节点的直接连接数量,即节点的度数。度中心性高的节点在网络中有更多的连接,因此可以被认为是更为重要或有更大的影响力。 接近度中心性(Closeness Centrality):接近度中心性测量节点与其他节点之间的距离,即节点到其他节点的平均最短路径长度。接近度中心性高的节点在网络中更接近其他节点,具有更高的信息传播速度和影响力。 介数中心性(Betweenness Centrality):介数中心性衡量节点在网络中连接其他节点之间的重要性。具有高介数中心性的节点在网络中充当信息传播的桥梁或关键中介者。 特征向量中心性(Eigenvector Centrality):特征向量中心性考虑节点的邻居节点的中心性,将其权重考虑在内。具有高特征向量中心性的节点与其他高中心性节点相连,具有更大的影响力。 通过进行社交网络中心性分析,可以识别出网络中的关键节点、社区结构、信息传播路径等重要信息,为社交网络分析、社交推荐、病毒传播预测等任务提供支持和洞察。
原文主要使用了以下三个中心性指标进行评估:Degree centrality,Katz centrality,Closeness centrality。
由于色彩可以通过RGB三原色来产生,相应地,本文作者通过将这三个中心性指标来对应RGB三原色进而生成图片,也就是最终的训练样本。
4.1.4 Classification
这一步骤是训练卷积神经网络(CNN)分类器。由于CNN需要大小相等的图片作为输入,所以在训练之前还需要设置一个合适的阈值来生成固定大小的图片。本文作者通过实验发现,超过99%的函数少于200行代码。基于时间成本以及准确度的考量,本文选择100作为阈值。当少于100行时,使用0来对向量进行补充;当多于100行时,则删掉多余的部分。图片大小本文给定的是3*100*128。分别表示三个中心性指标、代码行数阈值、向量的维度。
CNN的参数设置如下所示:
4.2 训练样本预处理的算法表示
这篇论文的整体思想还是很自然的,另外,原文说可以通过生成热力图来指出存在漏洞的具体代码行数,这点也是很锦上添花。唯一的不足就是提供的开源项目存在很多问题,提供的代码CNN模型全连接层特征图维度为1*320,无法生成热力图。但通过本文理论来改进优化提供的代码,生成热力图应该也还是可以实现的。
论文团队信息
通信作者团队:邹德清,博士,华中科技大学教授、博士生导师,网络空间安全学院执行院长。长期在网络空间安全领域开展研究,代表性工作有:(1)在软件安全领域,开展软件漏洞智能检测研究,首次把人工智能方法用于源代码漏洞特征的自动生成,显著降低了现有方法中由于安全专家人工定义漏洞规则导致的漏洞检测高漏报率和高误报率;(2)在云计算安全领域,在虚拟化安全、云可信监控、云数据安全、云计算动态软件升级等积累大量成果。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh