说明1、本文是对特定样本ollvm的分析,提供一种反混淆的方法思路,包含详细的分析过程和针对该样本的反混淆脚本,不包含通用的ollvm反混淆脚本。2、本文仅分析init_array中的第一个函数sub 2023-6-14 18:3:15 Author: 看雪学苑(查看原文) 阅读量:33 收藏
说明
1、本文是对特定样本ollvm的分析,提供一种反混淆的方法思路,包含详细的分析过程和针对该样本的反混淆脚本,不包含通用的ollvm反混淆脚本。
2、本文仅分析init_array中的第一个函数sub_88060 ,其余函数的反混淆可按照本文的思路自行处理。
对bcf和fla进行还原
原始代码
去除bcf的效果
去除fla的效果
bcf分析
ida查看函数的伪代码,包含大量的 ((dword_C0118 * (dword_C0118 - 1)) & 1) == 0 || dword_C0120 < 10判断。
通过简单计算可知,该判断条件的结果永远为false。
所以我们要想办法把该判断识别出来,并把无效跳转给 nop 掉。
转到汇编窗口,找到该条件的汇编指令,
通过分析可知,最后的B.EQ 永远不会跳转,所以把该指令 nop 即可。
先简单写个脚本尝试一下,按顺序匹配指令。
import idc
nop = 0xD503201F
def find_bcf(start, end):
ea = start
# 01
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
val_1 = idc.get_operand_value(ea, 1)
if mnem != 'ADRP' or val_1 != 0xC0000:
return start + 4# 02
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
val_1 = idc.get_operand_value(ea, 1)
if mnem != 'ADRP' or val_1 != 0xC0000:
return start + 4# 03
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
val_1 = idc.get_operand_value(ea, 1)
if mnem != 'MOV' or val_1 != 1:
return start + 4# 04
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
val_2 = idc.get_operand_value(ea, 2)
if mnem != 'ADD' or val_2 != 0x118:
return start + 4# 05
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
if mnem != 'LDR':
return start + 4# 06
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
if mnem != 'SUBS':
return start + 4# 07
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
if mnem != 'MUL':
return start + 4# 08
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
val_1 = idc.get_operand_value(ea, 1)
if mnem != 'MOV' or val_1 != 1:
return start + 4# 09
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
val_2 = idc.get_operand_value(ea, 2)
if mnem != 'ADD' or val_2 != 0x120:
return start + 4# 10
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
if mnem != 'LDR':
return start + 4# 11
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
if mnem != 'AND':
return start + 4# 12
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
val_1 = idc.get_operand_value(ea, 1)
if mnem != 'CMP' or val_1 != 0:
return start + 4# 13
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
op_1 = idc.print_operand(ea, 1)
if mnem != 'CSET' or op_1 != 'EQ':
return start + 4# 14
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
val_1 = idc.get_operand_value(ea, 1)
if mnem != 'CMP' or val_1 != 10:
return start + 4# 15
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
op_1 = idc.print_operand(ea, 1)
if mnem != 'CSET' or op_1 != 'LT':
return start + 4# 16
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
if mnem != 'ORR':
return start + 4# 17
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
val_1 = idc.get_operand_value(ea, 1)
if mnem != 'CMP' or val_1 != 0:
return start + 4# 18
ea += 4
if ea >= end:
return ea
mnem = idc.print_insn_mnem(ea)
if mnem != 'B.EQ':
return start + 4print(hex(ea))
idc.patch_dword(ea, nop)return ea + 4
def patch_bcf_func(func_start):
func_end = idc.find_func_end(func_start)
if func_end == idc.BADADDR:
returnea = func_start
while ea < func_end:
ea = find_bcf(ea, func_end)patch_bcf_func(0x88060)
脚本执行后,发现只处理了一部分,
找到未识别的地方,查看汇编指令,发现这些指令并不全在一起,中间可能插入其他指令。
然后发现,未识别的这个地方最后8条指令是和前面分析的一致,而且前面的指令是取值,核心的判断逻辑是后面这8条指令,
于是直接把脚本中多余的指令判断全删除,只保留 AND 开始的指令。
ida重新加载so(上一次脚本把部分跳转指令nop掉了,直接执行会导致本次nop掉正常的跳转)
删除部分指令判断后,重新执行脚本,发现任然有部分未被处理。
分析后发现,最后几条指令之间也可能插入有其他指令。
再次修改脚本,在每两条指令中间,都加上判断。
import idc
nop = 0xD503201F
def find_bcf(start, end):
ea = start# # 11
while ea < end:
mnem = idc.print_insn_mnem(ea)
if mnem and mnem[0] == 'B':
return start + 4
ea += 4
if mnem == 'AND':
break# 12
while ea < end:
mnem = idc.print_insn_mnem(ea)
if mnem and mnem[0] == 'B':
return start + 4
val_1 = idc.get_operand_value(ea, 1)
ea += 4
if mnem == 'CMP' and val_1 == 0:
break# 13
while ea < end:
mnem = idc.print_insn_mnem(ea)
if mnem and mnem[0] == 'B':
return start + 4
op_1 = idc.print_operand(ea, 1)
ea += 4
if mnem == 'CSET' and op_1 == 'EQ':
break# 14
while ea < end:
mnem = idc.print_insn_mnem(ea)
if mnem and mnem[0] == 'B':
return start + 4
val_1 = idc.get_operand_value(ea, 1)
ea += 4
if mnem == 'CMP' and val_1 == 10:
break# 15
while ea < end:
mnem = idc.print_insn_mnem(ea)
if mnem and mnem[0] == 'B':
return start + 4
op_1 = idc.print_operand(ea, 1)
ea += 4
if mnem == 'CSET' and op_1 == 'LT':
break# 16
while ea < end:
mnem = idc.print_insn_mnem(ea)
if mnem and mnem[0] == 'B':
return start + 4
ea += 4
if mnem == 'ORR':
break# 17
while ea < end:
mnem = idc.print_insn_mnem(ea)
if mnem and mnem[0] == 'B':
return start + 4
val_1 = idc.get_operand_value(ea, 1)
ea += 4
if mnem == 'CMP' and val_1 == 0:
breakwhile ea < end:
mnem = idc.print_insn_mnem(ea)
if mnem and mnem[0] == 'B':
if mnem == 'B.EQ':
print(hex(ea))
idc.patch_dword(ea, nop)
break
ea += 4return ea
def patch_bcf_func(func_start):
func_end = idc.find_func_end(func_start)
if func_end == idc.BADADDR:
returnea = func_start
while ea < func_end:
ea = find_bcf(ea, func_end)patch_bcf_func(0x88060)
ida重新加载so(上一次脚本把部分跳转指令nop掉了,直接执行会导致本次nop掉正常的跳转)
执行修改后的脚本,查看伪代码,判断条件全都被清除了。
另一种bcf处理方法
此处再提供一种简单的处理方法,ida生成的伪代码之所以这么多垃圾代码,是因为bcf所引用的内存属性包含可写属性,所以我们可以通过将其引用的内存地址变为不可写,这样ida就会自动进行优化。
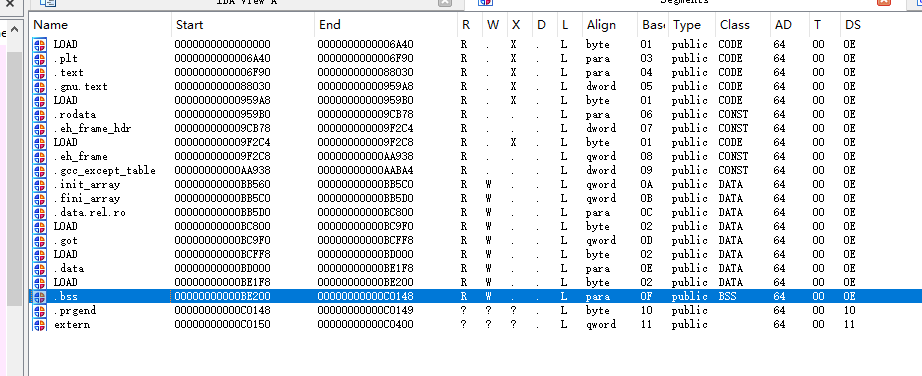
通过查看代码可知,bcf所引用的地址为dword_C0118 和 dword_C0118 ,这两个地址都属于.bss段。
.bss段的内存属性为可读可写,为了不影响ida对.bss中其他变量的分析,把这两个地址单独放在一个段。
发现这两个变量在.bss段的末尾,而.prgend段在.bss后面,并且.prgend没有内容,因此可直接修改这两个段的大小,然后把.prgend段属性改为不可写。
手动设置比较麻烦,直接通过脚本设置一下。
import idc
def modify_segment():
idc.set_segment_bounds(0xC0118, idc.get_segm_start(0xC0118), 0xC0118, idc.SEGMOD_SILENT)
idc.set_segment_bounds(0xC0148, 0xC0118, 0xC0149, idc.SEGMOD_SILENT)
idc.set_segm_attr(0xC0148, idc.SEGATTR_PERM, 4)
idc.patch_dword(0xC0118, 0)
idc.patch_dword(0xC0120, 0)modify_segment()
执行脚本修改段属性后,效果和直接nop跳转一样。
fla分析
查看上文处理后的伪代码,包含while和switch组合,将原本连续的代码分割成了多块,我们的目标是去除该结构,将所有代码连接起来。
通过分析可知,每个代码块会指定下一个代码块的索引,所以我们要想办法,把每个代码块设置的索引识别出来,并直接跳转到下一代码块。
通过查看流程图可知,所有分支执行完后都会跳转到def_88A9C(0x90ED8)再次进行分发。
由流程图可知,下一个代码块的索引存在X28指向的地址。
先简单写个脚本,看能否将索引和跳转地址识别出来。
先查找所有跳转到默认地址的指令,
然后倒回去查找str和mov指令,
mov指令的参数即为下一个代码块的索引。
import idc
def find_fla(ea, end, jpt_addr, def_addr):
# 01
addr = ea
while addr < end:
mnem = idc.print_insn_mnem(addr)
val_0 = idc.get_operand_value(addr, 0)
if mnem == 'B' and val_0 == def_addr:
B_addr = addr
break
addr += 4
else:
return addr# STR W10, [X28]
while ea <= addr:
mnem = idc.print_insn_mnem(addr)
STR_R = idc.print_operand(addr, 0)
op_1 = idc.print_operand(addr, 1)
if mnem == 'STR' and op_1 == '[X28]':
break
addr -= 4# MOV W10, #0x12
while ea <= addr:
mnem = idc.print_insn_mnem(addr)
op_0 = idc.print_operand(addr, 0)
val_1 = idc.get_operand_value(addr, 1)
if mnem == 'MOV' and op_0 == STR_R:
to_addr = hex((jpt_addr + idc.get_wide_dword(jpt_addr + (val_1 - 1) * 4)) & 0xffffffff)
print(hex(B_addr), val_1, to_addr)
break
addr -= 4return B_addr
def patch_fla_func(func_start, jpt_addr, def_addr):
func_end = idc.find_func_end(func_start)
if func_end == idc.BADADDR:
returnea = func_start
while ea < func_end:
ea = find_fla(ea, func_end, jpt_addr, def_addr) + 4patch_fla_func(0x88060, 0x958F4, 0x90ed8)
执行脚本后,识别到29个代码块,但是该函数实际有31个块。
通过对比后发现,索引为8和0x18的块未识别。
分析汇编指令后,发现是未通过X28直接赋值导致的。
在str指令之后又通过mov进行赋值。
修改脚本,查找str指令的时候,不再固定为X28。
再次执行脚本,31个代码块全部识别。
r_28 = 28
while ea <= addr:
mnem = idc.print_insn_mnem(addr)
STR_R = idc.print_operand(addr, 0)
op_1 = idc.print_operand(addr, 1)
if mnem == 'STR' and op_1 == f'[X{r_28}]':
break
if mnem == 'MOV' and STR_R == f'X{r_28}':
r_28 = op_1[1:]
addr -= 4
向脚本添加patch指令,每个代码块结束的时候,直接跳到下一代码块。
def patch_fla(jpt_addr, index, B_addr):
to_addr = hex((jpt_addr + idc.get_wide_dword(jpt_addr + (index - 1) * 4)) & 0xffffffff)
print(hex(B_addr), index, to_addr)encoding, count = ks.asm(f'b {to_addr}', B_addr)
if not count:
print('ks.asm err')
else:
for i in range(4):
idc.patch_byte(B_addr + i, encoding[i])
执行脚本后,查看伪代码,发现修复不完全。
分析后发现是因为指向第一个代码块的索引,在while和switch组合之前初始化,并且没有跳转到默认地址,而是直接跳到分发器。
修复初始化的时候直接跳转到第一个代码块。
再次执行脚本,发现已经没有while和switch结构了,但是发现最后有一个死循环。
分析后发现是因为索引为6的代码块,有两个分支,脚本修复的时候,只识别出17这一个。
于是这两个分支,在if判断后直接跳转到对应的代码块。
修复所有异常的fla处理代码。
import keystone
import idc
ks = keystone.Ks(keystone.KS_ARCH_ARM64, keystone.KS_MODE_LITTLE_ENDIAN)
def patch_fla(jpt_addr, index, B_addr):
to_addr = hex((jpt_addr + idc.get_wide_dword(jpt_addr + (index - 1) * 4)) & 0xffffffff)
print(hex(B_addr), index, to_addr)encoding, count = ks.asm(f'b {to_addr}', B_addr)
if not count:
print('ks.asm err')
else:
for i in range(4):
idc.patch_byte(B_addr + i, encoding[i])def find_fla(ea, end, jpt_addr, def_addr):
# 01
addr = ea
while addr < end:
mnem = idc.print_insn_mnem(addr)
val_0 = idc.get_operand_value(addr, 0)
if mnem == 'B' and val_0 == def_addr:
B_addr = addr
break
addr += 4
else:
return addr# STR W10, [X28]
# MOV X28, X12
r_28 = 28
while ea <= addr:
mnem = idc.print_insn_mnem(addr)
STR_R = idc.print_operand(addr, 0)
op_1 = idc.print_operand(addr, 1)
if mnem == 'STR' and op_1 == f'[X{r_28}]':
break
if mnem == 'MOV' and STR_R == f'X{r_28}':
r_28 = op_1[1:]
addr -= 4# MOV W10, #0x12
while ea <= addr:
mnem = idc.print_insn_mnem(addr)
op_0 = idc.print_operand(addr, 0)
val_1 = idc.get_operand_value(addr, 1)
if mnem == 'MOV' and op_0 == STR_R:
patch_fla(jpt_addr, val_1, B_addr)
break
addr -= 4return B_addr
def patch_fla_func(func_start, jpt_addr, def_addr):
func_end = idc.find_func_end(func_start)
if func_end == idc.BADADDR:
returnea = func_start
while ea < func_end:
ea = find_fla(ea, func_end, jpt_addr, def_addr) + 4jpt_addr = 0x958F4
def_addr = 0x90ed8
patch_fla_func(0x88060, jpt_addr, def_addr)
patch_fla(jpt_addr, 13, 0x88838)
patch_fla(jpt_addr, 29, 0x89D80)
patch_fla(jpt_addr, 17, 0x89FCC)
执行脚本后,查看伪代码,所有的分支都成功处理。
看雪ID:卧勒个槽
https://bbs.kanxue.com/user-home-745332.htm
# 往期推荐
3、安卓加固脱壳分享
球分享
球点赞
球在看
如有侵权请联系:admin#unsafe.sh