
整体设计思路对于人工检测病毒来说,不管是静态分析,还是动态分析,直接分析是十分消耗精力的,需要大量专家信息作为辅助。而对于机器学习,特别是深度学习来说,端到端的神经 2023-6-5 23:46:12 Author: xz.aliyun.com(查看原文) 阅读量:49 收藏
整体设计思路
对于人工检测病毒来说,不管是静态分析,还是动态分析,直接分析是十分消耗精力的,需要大量专家信息作为辅助。而对于机器学习,特别是深度学习来说,端到端的神经网络雨后春笋般的出现。能够把深度学习引入到病毒检测将大大减轻人工的负担,我们需要做的就是优化网络结构并挑选出更有代表性的特征。
对于静态分析来说,可以将代码当成nlp中的语句,或者是将文件抽象成 CNN 中的图像,来更好的识别一个文件的静态特征。对于动态分析而言,把 api 调用链当成特征也是十分自然。当然还有很多选择的方式。本次选择的方案 CNN 。
这个 CNN 处理思路是看一篇论文得到的,用的数据集是微软的微软恶意软件分类挑战的。这个数据集一百多个G,转成灰度图更是能跑好久好久,差不多跑了4个小时。下边开始介绍,主要分成三个点:
- 图像预处理
- VGG神经网络
- 搭建部署上线
前言:理论支撑
如何抽取特征以及特征为什么有效?
关于如何将一个病毒的二进制文件格式转变成一张图,论文有很详细的说明,下面我把代码处理逻辑具体说下:
对于逆向工作人员来说,将病毒拖进ida或者各种十六进制查看器是兵家常事。以一个真实的病毒举例:

对于第一个字节来说,M 不是它唯一能表示的东西,事实上,一个灰度图的像素点也是呈 0-255 分布的,所以我们完全可以把 M 也就是 0x4D,也就是 77,当成一个像素点的灰度。


那为什么提取的特征是有效的呢?能够工作的原因就是病毒家族之间有着十分相似的布局和纹理。这就和CNN网络特点不谋而合了,所以能够直接借鉴过来。
图像预处理
这个数据集文件格式很常规:
malware-classification/
├── sampleSubmission.csv
├── trainLabels.csv
├── test/
│ ├── aa.asm
│ ├── aa.bytes
│ └── ...
├── train/
│ ├── bb.asm
│ ├── bb.bytes
│ └── ...
└── dataSample/
├── a.asm
├── a.bytes
├── b.asm
└── b.bytesdataSample 一个实例文件夹、而 test 是测试数据集,sampleSubmission 是提交格式的说明,因为是个比赛的数据集。我们搭建需要用到就是两个:trainLabels.csv 和 train 文件夹,如名字所说:trainLabels.csv 放的是 train 文件夹下训练数据的标签,可以当成使用文件名索引出 class,如图:

而对于asm文件来说我们这次是用不到的,它是通过ida得出来的,是ida反编译出来的结果:
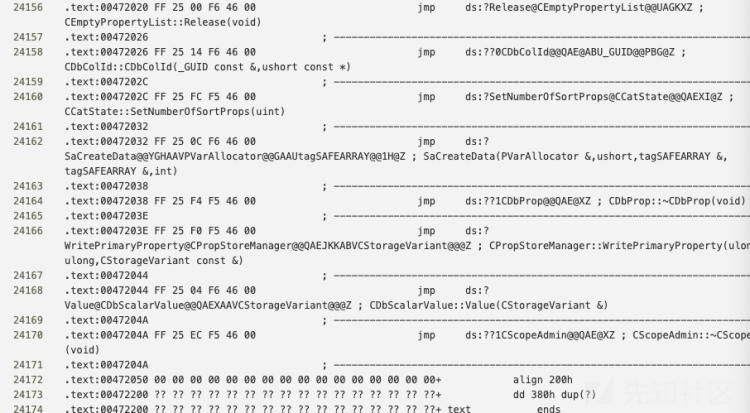
好的,下面看下主角文件格式:

我们其实要做的核心步骤就是把一个文件如a.bytes,转成a.png(文件名前缀一定不能变,因为要靠文件名去csv中当索引找对应的类别)
文件统一从0x401000开始,且长度不定有几百k的也有几m的,但处理不难,就是用空格把文件所有字符分割开,然后append到一个一维数组中。如何将一维数组升到二维,论文提到了一种宽度的设计:小于10kb的宽设成32,10kb到30kb之间的宽度设为64,中间还有一段区间(详细见代码),最后是大于1000kb的话设置为1024。使用这种方式来将数据进行升维,代码如下:
import os
# 定义一个函数,将 bytes 文件转换成图片
def bytes_to_image(file_path, output_folder):
# 读取文件内容
with open(file_path, 'r') as f:
content = f.read()
# 将文件内容转换成像素点的亮度
pixels = []
for line in content.split('\n'):
for byte in line.split()[1:]:
if byte=='??':continue
pixels.append(int(byte, 16))
# 计算图片高度
print(len(pixels)//1024)
width = next(w for s, w in widths if len(pixels) < s)
height = len(pixels) // width
if len(pixels) % width != 0:
height += 1
# 创建图片
from PIL import Image
img = Image.new('L', (width, height), 0)
img.putdata(pixels)
# 保存图片
file_name = os.path.splitext(os.path.basename(file_path))[0] + '.png'
output_path = os.path.join(output_folder, file_name)
img.save(output_path)
# 定义一个列表,用于存储不同文件大小对应的图片宽度
widths = [(10 * 1024, 32), (30 * 1024, 64), (60 * 1024, 128),(100 * 1024, 256),(200 * 1024, 384),(500 * 1024, 512),(1000 * 1024, 768),(float('inf'), 1024)]
# 遍历文件夹,将所有 .bytes 文件转换成图片
input_folder = 'train'
output_folder = 'rtrainpng'
for file_name in os.listdir(input_folder):
if file_name.endswith('.bytes'):
file_path = os.path.join(input_folder, file_name)
# 读取文件内容,计算像素点数量
with open(file_path, 'r') as f:
content = f.read()
pixels_count = sum(1 for line in content.split('\n') if line.startswith('004010'))
# 将文件转换成图片
bytes_to_image(file_path, output_folder)跑代码,坐等结果:


这是一小部分中的一小部分,最后所有图片跑出来6个多 g ,图片处理完毕,最费时间233(鬼见条)

VGG神经网络搭建
这是安全社区,不是人工智能社区,233,搭建过程见代码。就是个 CNN 神经网络的搭建,代码如下
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import models, transforms
from PIL import Image
import os
import pandas as pd
import os
import pandas as pd
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import os
import pandas as pd
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
class MyDataset(Dataset):
def __init__(self, csv_file, root_dir, transform=None, train=True, test_ratio=0.2):
self.df = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
self.train = train
self.test_ratio = test_ratio
# 获取文件夹中的文件名
self.filenames = os.listdir(self.root_dir)
self.filenames = [f for f in self.filenames if f.endswith('.png')]
# 将数据集分成训练集和测试集
if self.train:
self.df = self.df[self.df['Id'].isin([f[:-4] for f in self.filenames])]
self.df = self.df.sample(frac=1).reset_index(drop=True)
self.test_size = int(len(self.df) * self.test_ratio)
self.train_df = self.df.iloc[self.test_size:]
# self.test_df = self.df.iloc[:self.test_size]
else:
self.df = self.df[self.df['Id'].isin([f[:-4] for f in self.filenames])]
self.df = self.df.sample(frac=1).reset_index(drop=True)
self.test_size = int(len(self.df) * self.test_ratio)
# self.train_df = self.df.iloc[self.test_size:]
self.train_df = self.df.iloc[:self.test_size]
# self.train_df = self.df[self.df['Id'].isin([f[:-4] for f in self.filenames])]
def __len__(self):
return len(self.train_df)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
# 读取图片和标签
img_name = self.train_df.iloc[idx, 0] + '.png'
img_path = os.path.join(self.root_dir, img_name)
image = Image.open(img_path)
label = self.train_df.iloc[idx, 1]
# 数据增强
if self.transform:
image = self.transform(image)
return image, label
# 定义数据增强
transform = transforms.Compose([
transforms.Grayscale(num_output_channels=3),
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5),
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 创建训练集和测试集
train_dataset = MyDataset('trainLabels.csv', 'rtrainpng', transform=transform, train=True)
test_dataset = MyDataset('trainLabels.csv', 'rtrainpng', transform=transform, train=False)
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 定义 VGG16 模型
class VGG16(nn.Module):
def __init__(self, num_classes=9):
super(VGG16, self).__init__()
self.features = models.vgg16(pretrained=True).features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# 创建 VGG16 模型
model = VGG16(num_classes=9)
device = torch.device('mps')#nvidia的话写成cuda
model = model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 训练模型
for epoch in range(30):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
ima, labels = data
ima=ima.to(device)
labels=labels.to(device)
optimizer.zero_grad()
outputs = model(ima)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# if i % 100 == 99:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
# 保存 PyTorch 模型到文件中
torch.save(model.state_dict(), 'model.pth')
# 测试模型
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images=images.to(device)
labels=labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the test images: %d %%' % (100 * correct / total))ok,ai部分结束,开始上部署上线代码
部署上线
当然得强调一下,最终的效果是和你的数据集和模型有关的,使用这个数据集得到的结果肯定出不了标签那几个。
我这里选择搭建在局域网中,想要搭建到公网或者内网穿透有很多选择,这里记录个坑点:关于使用 python 的 ngrok,有可能穿透不出去,需要在配置文件 ngrok.yml(unix端在家目录下的.ngrok2文件夹下边)中将 region 改成 auto(我尝试过用 jupyter 强行走代理,但失败,企业功能才可以)

这个部署就简单了,整体如下:

逻辑很简单,用户访问把病毒传上去,服务器先在数据库里找文件的md5,找到后直接把结果返回给用户,找不到后充当队列中的生产者向队列中生产数据,两个ai服务器部署一样的代码,秉持吃多少饭用多大碗的原则,每次消费完数据后确认,之后再拿数据,保证两台服务器能够并行工作。同时ai服务器处理完也要向数据库写如刚才的md5和结果。核心代码和效果图如下:
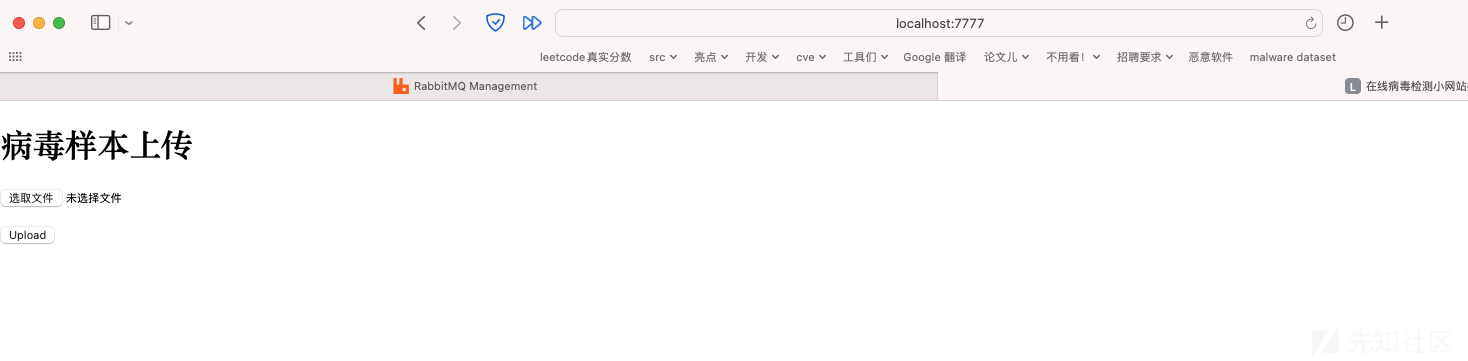
选择文件后直接上传,两种情况,一种是mysql中有文件处理结果:

这时候就直接把结果返回。

还有一种就是mysql中没有,需要真正让ai去跑的(对不起我写的太丑了):
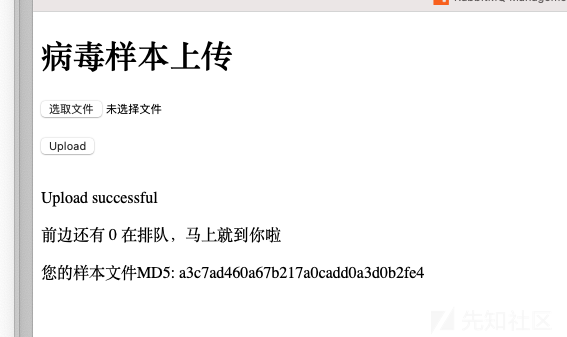
少写个字,前边还有0人在排队,233,这个0就是返回的队列中消息的个数。让用户知道还有多少人排队。
然后我在这页面加了个ajax,ajax每10秒轮训一次,把自己的md5当参数发给/getresult路由。这块的html和ajax代码如下:

<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>在线病毒检测小网站捏</title>
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.6.0/jquery.min.js"></script>
<script>
$(document).ready(function() {
setInterval(function() {
$.get("/getresult?md5={{.MD5}}", function(data) {
$("#result").html(data);
});
}, 10000);
});
</script>
</head>
<body>
<h1>病毒样本上传</h1>
<form action="/upload" method="post" enctype="multipart/form-data">
<input type="file" name="file">
<br>
<br>
<input type="submit" value="Upload">
</form>
<br>
{{if .Message}}
<div>
<p>{{.Message}}</p>
<p>前边还有 {{.MessageCount}}人在排队,马上就到你啦</p>
<p>您的样本文件MD5: {{.MD5}}</p>
</div>
{{end}}
<br>
<div id="result"></div>
</body>
</html>result.html ,也就是ajax访问后出现的页面,也是用模板写的,代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>病毒检测结果</title>
</head>
<body>
<h1>该病毒检测结果为:</h1>
<p>MD5: {{.MD5}}</p>
<p>Result: {{.Result}}</p>
</body>
</html>当然因为有个getresult接口,所以可以直接采用url传参进行查询:

因为网站是非登陆的,如果想要改成注册登陆型的话可以让用户和传的文件md5进行绑定,就不用记住文件的md5了。
go三个路由如下,那就先说 getresult 路由吧:
// 处理查询请求
func getResultHandler(w http.ResponseWriter, r *http.Request) {
// 检查请求方法是否为GET
if r.Method != "GET" {
http.Error(w, "Method not allowed", http.StatusMethodNotAllowed)
return
}
// 解析查询参数
md5 := r.URL.Query().Get("md5")
// 连接到MySQL数据库
db, err := sql.Open("mysql", "root:[email protected](127.0.0.1:3306)/mydatabase")
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
defer db.Close()
// 查询文件处理结果
var result int
err = db.QueryRow("SELECT result FROM files WHERE md5 = ?", md5).Scan(&result)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
// 返回查询结果
w.Header().Set("Content-Type", "text/html")
w.WriteHeader(http.StatusOK)
tpl := template.Must(template.ParseFiles("result.html"))
tpl.Execute(w, map[string]interface{}{
"MD5": md5,
"Result": result,
})
}文件上传路由:
// 处理文件上传请求
func uploadHandler(w http.ResponseWriter, r *http.Request) {
// 检查请求方法是否为POST
if r.Method != "POST" {
http.Error(w, "Method not allowed", http.StatusMethodNotAllowed)
return
}
// 解析表单数据
err := r.ParseMultipartForm(32 << 20) // 限制上传文件大小为32MB
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
file, handler, err := r.FormFile("file")
if err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
defer file.Close()
// 将文件保存到本地
fileDir := "./uploads"
if _, err := os.Stat(fileDir); os.IsNotExist(err) {
os.Mkdir(fileDir, 0755)
}
filePath := filepath.Join(fileDir, handler.Filename)
f, err := os.OpenFile(filePath, os.O_WRONLY|os.O_CREATE, 0644)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
defer f.Close()
// 计算文件的MD5值
hash := md5.New()
if _, err := io.Copy(f, io.TeeReader(file, hash)); err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
md5Hash := fmt.Sprintf("%x", hash.Sum(nil))
db, err := sql.Open("mysql", "root:[email protected](127.0.0.1:3306)/mydatabase")
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
defer db.Close()
// 查询文件处理结果
var result int
err = db.QueryRow("SELECT result FROM files WHERE md5 = ?", md5Hash).Scan(&result)
if err == nil {
w.Header().Set("Content-Type", "text/html")
w.WriteHeader(http.StatusOK)
tpl := template.Must(template.ParseFiles("result.html"))
tpl.Execute(w, map[string]interface{}{
"MD5": md5Hash,
"Result": result,
})
return
}
// 将文件名和MD5值发送到RabbitMQ队列中
conn, err := amqp.Dial("amqp://guest:[email protected]:5672/")
if err != nil {
log.Fatalf("Failed to connect to RabbitMQ: %v", err)
}
defer conn.Close()
ch, err := conn.Channel()
if err != nil {
log.Fatalf("Failed to open a channel: %v", err)
}
defer ch.Close()
q, err := ch.QueueDeclare(
"file_queue", // 队列名称
true, // 是否持久化
false, // 是否自动删除
false, // 是否具有排他性
false, // 是否阻塞
nil, // 额外参数
)
if err != nil {
log.Fatalf("Failed to declare a queue: %v", err)
}
body := []byte(fmt.Sprintf("%s|%s", handler.Filename, md5Hash))
err = ch.Publish(
"", // 交换机名称
q.Name, // 队列名称
false, // 是否强制
false, // 是否立即
amqp.Publishing{
ContentType: "text/plain",
Body: body,
},
)
if err != nil {
log.Fatalf("Failed to publish a message: %v", err)
}
// 获取队列中的消息数量
queue, err := ch.QueueInspect(q.Name)
if err != nil {
log.Fatalf("Failed to inspect queue: %v", err)
}
messageCount := queue.Messages
// 返回上传成功的响应
w.Header().Set("Content-Type", "text/html")
w.WriteHeader(http.StatusOK)
tpl := template.Must(template.ParseFiles("index.html"))
tpl.Execute(w, map[string]interface{}{
"Message": "Upload successful",
"MessageCount": messageCount,
"MD5": md5Hash,
})
}还有个根路由:
func indexHandler(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "text/html")
w.WriteHeader(http.StatusOK)
tpl := template.Must(template.ParseFiles("index.html"))
tpl.Execute(w, nil)
}主程序进行注册:
func main() {
// 注册文件上传处理函数
http.HandleFunc("/getresult", getResultHandler)
http.HandleFunc("/upload", uploadHandler)
// 注册根路由处理函数
http.HandleFunc("/", indexHandler)
// 启动HTTP服务器
log.Fatal(http.ListenAndServe(":7777", nil))
}完整go见附件。消费者代码,也就是ai服务器的代码很简单,就是上边说的逻辑,篇幅所限不展开了,完整版见附件,sql建表语句也在。
整体文件目录长这样:

最后真正上线的话把这段代码加进去(在服务器的uploadHandler函数里),把 exe 转成一维数组传给 ai:
def chu(fillname):
with open(fillname, "rb") as f:
content = f.read()
# print(content)
# 将每两个字符组成一个十六进制数,并用空格分隔
hex = " ".join("{:02x}".format(c) for c in content)
# 将空格分隔的十六进制数合并成一行
hex = hex.replace(" ", "")
# 将每8个字符分隔成一组,并用逗号分隔
hex = ",".join(hex[i:i+2] for i in range(0, len(hex), 2))
# 将结果存储到一个数组中
arr = hex.split(",")
ans=[]
for i in arr:
ans.append(int(i,16))
return ans
chu('Ransom.WannaCryptor.exe')如有侵权请联系:admin#unsafe.sh