
针对上次写的项目的痛点进行了改进,下面回顾下:python服务器和go相当于是串行的,也就是说waf掉了整个业务就掉了完善业务,加入用户验证waf防护的太简单 2023-5-29 17:58:0 Author: xz.aliyun.com(查看原文) 阅读量:32 收藏
针对上次写的项目的痛点进行了改进,下面回顾下:
- python服务器和go相当于是串行的,也就是说waf掉了整个业务就掉了
- 完善业务,加入用户验证
- waf防护的太简单,需要加模块
暂时想到了以下解决方式:
- go服务器把url信息发到rabbitmq里边,使用队列让waf消费并验证;
- 加入用户验证,如果waf验证到不对劲了就执行封禁用户session的操作,或本身就在黑名单里,直接返回就行了
- waf整体架构严格意义上已经不是墙了,而是一个为了不影响机器学习处理速度拖累用户访问体验所采取的另一种防护模式。设计的整体架构和心路历程如下:
整体架构如图所示:
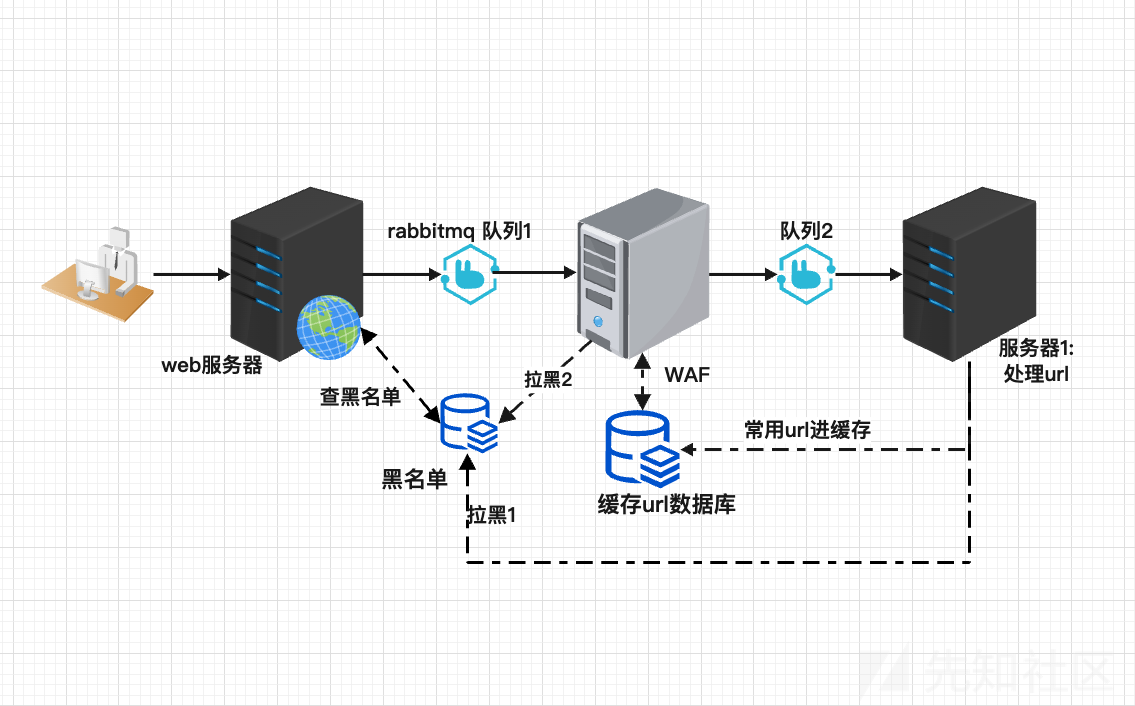
本次完成的是基于token的,倘若用户不登陆直接进行攻击的话,可以采取直接封禁ip的黑名单措施,但原理都类似。
如果把传统WAF比做大楼门禁的话:客人扫脸进来,长得像坏人直接就不让进。这个更像客人来者不拒,但会把脸的信息都记录下来,等查到信息后发现某客人是坏人,就把该客人赶出去,并加入黑名单)。优势就是速度快,但是缺点就是来的客人有可能在被赶走之前就把我们这个大楼的设施毁坏了
web服务器和waf都是用go写的。服务器1(也叫做ai服务器,专门检验url是否是恶意的)是python写的,因为用到机器学习的框架,考虑到最大化发挥语言特点,就选择了go和python。关于消息队列的选择,没用kafka,选择了更能保证数据的rabbitmq(就怕恶意url丢了)。
- go服务器维护一个用户验证登陆系统,每次用户发来url的同时把url和用户session同时发送到队列中(发送前会从redis黑名单中查询是不是黑名单成员,是的话,直接就不让访问),用来验证用户是否存在攻击行为。
- waf充当消费者不断从队列里边拿数据。waf干两件事,从redis中找数据,看看有没有,如果没有的话直接就向下一层消息队列通知,让下层服务器去处理url(考虑到拓展性,可以将第二层消息队列,也就是队列2,修改成交换机或路由器,来专门处理url或者body或等等)
- 服务器1设置了1个,专门用来查url的,如果上步完成了改成交换机或路由器的话就能完成更多操作了。这个服务器消化队列2里的数据并把结果返回给缓存url数据库中,而且如果结果是1,也就是结果是攻击行为的话就直接在黑名单redis里添加数据。事实上,访问网页流量的攻击行为是不多的,而且这个黑名单不是session黑名单,而是用户黑名单,以防止用户重复登陆,拿着新token继续攻击的行为。
web服务器代码
登陆验证用的token,主要是因为不需要在服务器端存储任何状态信息,并轻松地扩展到多个服务器。web服务器连的东西有三个:
- redis(验证黑名单用的)
- mysql(连mysql验证账密的)
- rabbitmq(队列1的生产者)
下面给出代码,完整代码见附件,包和import都不加了,直接上逻辑代码
http.HandleFunc("/login", func(w http.ResponseWriter, r *http.Request) { //login路由,登陆放回token用的 //解析body var user User err := json.NewDecoder(r.Body).Decode(&user) if err != nil { http.Error(w, err.Error(), http.StatusBadRequest) return } var user1 User // 验证 _ = db.QueryRow("SELECT username, password FROM users WHERE username = ?", user.Username).Scan(&user1.Username, &user1.Password) if user != user1 { http.Error(w, "Invalid username or password", http.StatusUnauthorized) return } //无所谓,写不写死不重要 // if (user.Username == "admin" && user.Password == "password") || (user.Username == "test" && user.Password == "test") { // log.Printf("%s login in ", user.Username) // } else { // http.Error(w, "Invalid username or password", http.StatusUnauthorized) // return // } // 创建 JWT token claims := &Claims{ Username: user.Username, StandardClaims: jwt.StandardClaims{ ExpiresAt: jwt.TimeFunc().Add(time.Hour * 24).Unix(), }, } token := jwt.NewWithClaims(jwt.SigningMethodHS256, claims) tokenString, err := token.SignedString([]byte("secret")) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } // 放到返回头里边 w.Header().Set("Authorization", fmt.Sprintf("Bearer %s", tokenString)) // OK w.Write([]byte("Hello World")) })
login路由完成的功能就是从数据库中找用户登陆的账密对不对,对的话的话给个token,用来进行检验登陆状态。
// 处理其他请求 http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) { // 获取token fmt.Println(r.URL) authHeader := r.Header.Get("Authorization") if authHeader == "" { http.Error(w, "Missing authorization header", http.StatusUnauthorized) return } tokenString := authHeader[len("Bearer "):] // 解析 token, err := jwt.ParseWithClaims(tokenString, &Claims{}, func(token *jwt.Token) (interface{}, error) { return []byte("secret"), nil }) if err != nil { http.Error(w, err.Error(), http.StatusUnauthorized) return } // 拿到用户名 claims, ok := token.Claims.(*Claims) if !ok { http.Error(w, "Invalid token claims", http.StatusUnauthorized) return } // 和黑名单的对,如果在的话,直接就返回未授权 if redisClient.SIsMember("blacklist", claims.Username).Val() { http.Error(w, "Sry U R in blacklist", http.StatusUnauthorized) return } // 把session和url都扔到rabbitmq里边 err = ch.Publish( "", // exchange q.Name, // routing key false, // mandatory false, // immediate amqp.Publishing{ ContentType: "text/plain", Body: []byte(fmt.Sprintf("Session: %s, URL: %s", claims.Username, r.URL)), }) if err != nil { log.Printf("Failed to publish message: %v", err) } // OK! w.Write([]byte("Hello World")) })
之后监听到8080端口就好了!验证登陆程序启动,并发送url和session的功能。使用postman验证下:可以看到session和url都进rabbitmq队列里边去了

WAF
这个WAF的功能更像干消息派发的,我引入他的原因挺多的。
- 首先就是机器学习处理是需要时间的,如果取消他的话,直接让AI服务器当WAF的话,python可能消化不过来队列1的东西
- 引入他会省大量的重复url
- 方便后期扩展,扣下题,hh
这个WAF等数据来之后会先在缓存url数据库里边找,找到的话就不麻烦AI服务器了,否则就扔到队列2里边让AI服务器工作。同时他也需要有个拉黑的功能。主要原因就是不同用户发来的恶意请求有可能是一样的话,既然这样的话就要解耦了,url当key,value就是0/1(0表示无害,1表示恶意请求)。用户发来value为1的url直接拉黑该用户就行!
// 处理消息 for msg := range msgs { // 解析Session和URL字段 var Session, URL string fields := strings.Split(string(msg.Body), ",") for _, field := range fields { if strings.HasPrefix(field, "Session:") { Session = strings.TrimSpace(strings.TrimPrefix(field, "Session:")) } } re := regexp.MustCompile(`URL:\s*([^,]+)`) match := re.FindStringSubmatch(string(msg.Body)) if len(match) > 1 { URL = match[1] fmt.Printf("URL: %s\n", URL) } // 打印结果 // fmt.Printf("%s %s\n", Session, URL) // 从cache里看有没有这个url key := "cache" field := URL val, _ := redisClient.HGet(key, field).Result() // 不存在的话发到队列里 if val == "" { // Value does not exist fmt.Println("Value does not exist") err = ch.Publish( "", // 交换机名称 "newurls", // 队列名称 false, // 是否强制发送到队列 false, // 是否等待服务器确认 amqp.Publishing{ ContentType: "text/plain", Body: []byte(fmt.Sprintf("Session: %s, URL: %s", Session, URL)), }, ) if err != nil { log.Fatalf("Failed to publish a message: %v", err) } } else if val == "1" { //加到黑名单,脱离ai服务器也能运行 setKey := "blacklist" err := redisClient.SAdd(setKey, Session).Err() if err != nil { log.Fatal(err) } } }

缓存触发,b也进黑名单了
ai服务器
这块因为是python,所以写起来得心应手,很好写,还是用的之前的逻辑回归代码:
import pika import re from flask import Flask, request import os from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression import urllib.parse import joblib import redis import requests # 连接Redis r = redis.Redis(host='localhost', port=6379, db=0) connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明要消费的队列 channel.queue_declare(queue='newurls', durable=True) def load(name): filepath = os.path.join(str(os.getcwd()), name) with open(filepath,'r') as f: alldata = f.readlines() ans = [] for i in alldata: i = str(urllib.parse.unquote(i)) ans.append(i) return ans badqueries = load('badqueries.txt') goodqueries = load('goodqueries.txt')#导入两类url vectorizer = TfidfVectorizer()#用来将url向量化 X = vectorizer.fit_transform(badqueries+goodqueries)#直接输进去 lgs = LogisticRegression(class_weight='balanced') #简单的逻辑回归二分类 lgs = joblib.load('lgs.model') print('ready!!') def check(url): X_predict = vectorizer.transform([url]) res = lgs.predict(X_predict) print(res) return res
然后消费队列这块是新东西了,因为要定义回调函数,来处理消息。需要注意的是这个check函数的返回值是numpy类型,之后得强转一下。
# 回调函数,处理消息 def callback(ch, method, properties, body): # 解析Session和URL字段 session, url = None, None for field in body.decode().split(", "): if field.startswith("Session:"): session = field.split(":")[1].strip() elif field.startswith("URL:"): url = field.split(":")[1].strip() # 打印结果 print("Session: %s, URL: %s" % (session, url)) tmp= int(check(url))#numpy类型转int # 检查在不在 if r.hexists('cache', url): print('已经有了')#这块不用加的,我蠢了,但没删,留作教训 else: # 加进去 r.hset('cache', url, tmp) print(url+" 已加入cache数据库") if tmp: #本来是想让web服务器留个接口的,通过一个key来请求销毁session,进黑名单,但想了想干脆直接在这里拉进黑名单不就行了,多省事! # url = 'http://127.0.0.1:8080/invalidate'#你服务器地址 # params = {'key': 'qweasd', 'session': session} #requests.get(url, params=params) #拉黑 r.sadd('blacklist',session) print(session+" 已拉黑") # 消费消息 channel.basic_consume(queue='newurls', on_message_callback=callback, auto_ack=True) # 启动消费者 channel.start_consuming()
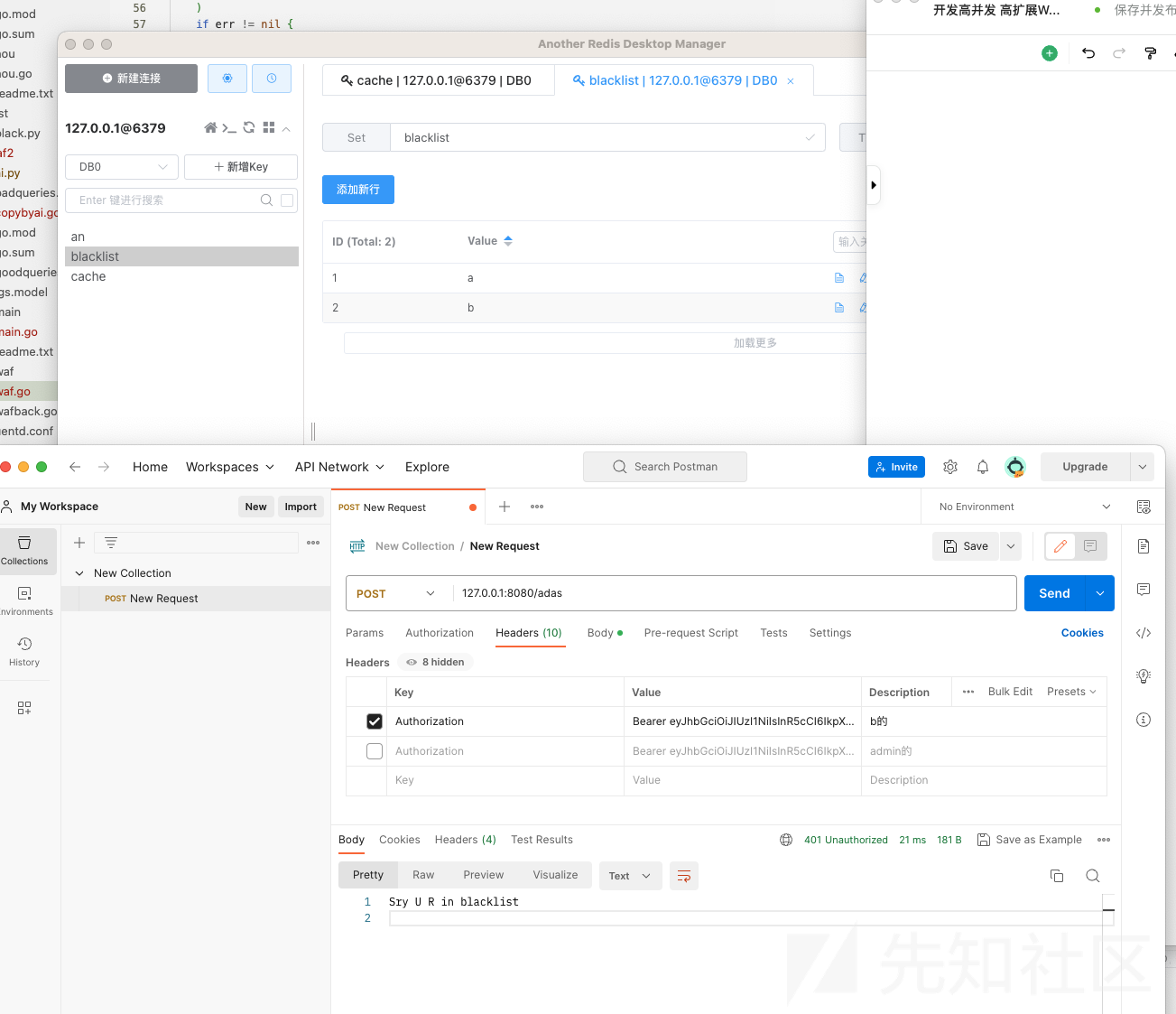
直接在python里拉黑会简单很多
环境部署
本次的实验全在自己机子上完成的,redis、mysql、rabbitmq全是docker里跑的
docker run -d -p 6379:6379 redis
docker run -e MYSQL_ROOT_PASSWORD=123456 -p 3306:3306 -d mysql
docker run -it --rm --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3.11-management
附件里的文件直接跑就行
总结
本次完成了上次既定的两个目标,超量完成目标1,标准完成目标2,目标3看了几篇论文和数据集也逐渐有了头绪。但感觉ai和开发的交互已经完成大概了,所以这项目暂时搁置一下,学ai去了,芜湖
如有侵权请联系:admin#unsafe.sh