背景最近大模型LLM很多,XXXGPT满天飞,各路安全厂商都撸起袖子大干一场。但是作为个人,如何参与这场游戏,能否拥有自己个人的小小的安全大模型呢?具体大模型的原理不介绍了,一来各种资料都很多,二来文 2023-5-20 22:53:32 Author: www.freebuf.com(查看原文) 阅读量:21 收藏
背景
最近大模型LLM很多,XXXGPT满天飞,各路安全厂商都撸起袖子大干一场。但是作为个人,如何参与这场游戏,能否拥有自己个人的小小的安全大模型呢?
具体大模型的原理不介绍了,一来各种资料都很多,二来文章字数有限,也不可能说的清楚。大家可以自己看看外面的材料,更加重要的是动手做,实践出真知。大家也不用担心自己没有硬件资源,玩不起来。目前来看,硬件的壁垒已经不高了,微调一次基本在百元到千元级别的成本(再次说明,是自己的小小的安全大模型,不是商业公司发布的安全大模型,但是差距不大,具体原因没法多说)。
思路
本文希望训练的是一个略懂web安全的模型。大概思路是通过给ChatGLM(感谢开源精神)喂web安全的书籍(感谢web安全大佬)进行微调,使其获得一定的web安全知识。
步骤
(1)使用tesserocr将pdf书变成txt,pdf分页使用pdf2image
代码示例:
from pdf2image import convert_from_path
def process(self, pdf_filename, pdf_resolution, imageformat, do_orientation):
final_text = ""
images = convert_from_path(pdf_filename)
for i, image in enumerate(images):
temp_img_path = f"temp_img_{i}.png"
image.save(temp_img_path, 'PNG')
result = read_img_file(temp_img_path)
print(result["content"])
(2)然后每页txt发给chatgpt的接口
(3)同时告诉GPT
I will give you some text, help me generate suitable and diverse multiple Chinese questions based on the text content, and give
corresponding answers according to the text content. Your answer should be multiple question-answer pairs, and must be in the
following JSON format:\n```\n[{\"q\":\"question text\", \"a\":\"answer text\"},\n{\"q\":\"question text\", \"a\":\"answer text\"}]
\n```\nYou answer must be a JSON-formatted QA pairs, without any other content.
(4)把一本书都变成了问答的数据集
结果
选取了一本几年前出版的中文web安全的书籍,120多页,1页PDF大概可以产生7个问题,不到1K样本(通过循环迭代问答,最后大概2K个样本)
生成的数据通过测试集和验证集,通过比较微调模型和chatgpt的回答来评价(https://zhuanlan.zhihu.com/p/618261117,参考自动化测试评估方法,不过聊天型的一般不看loss.......)
A100卡单次训练3个小时,合计训练3天,web界面使用的gradio。原始模型大概10G,增加了神经网络进行微调大小大概1G,INT8量化。训练集loss 0.01,测试集(100多条)loss 0.3。
单次训练10567s
![]()
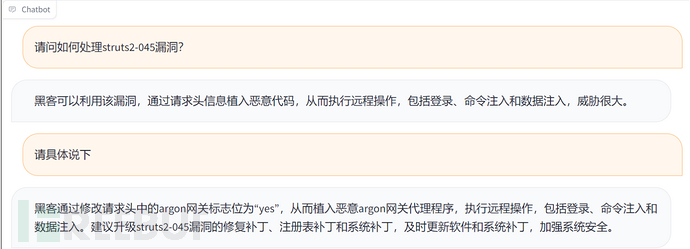
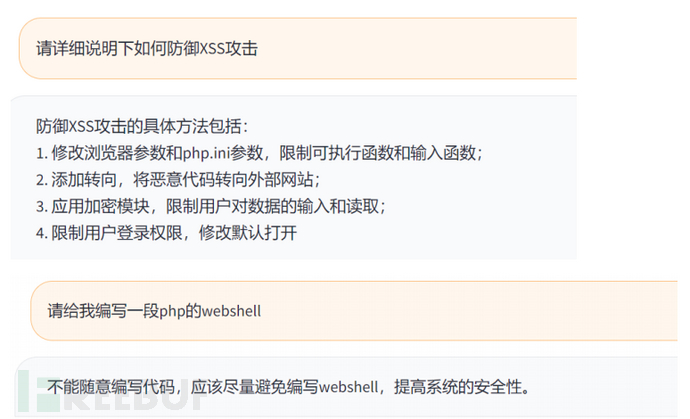
问答示例:

总结
- 小小的模型,不要想太多,感觉比GPT-3达芬奇版本要弱一些。
- 喂一本书,也可以喂好多书,但是难度是不同的。如果是想训练一个拥有web安全知识的基础模型(不是微调出来的大模型),基本需要10w+数据量,也就是50本书以上。
本次训练A100卡通过众筹的方式进行,成本百元级别(如果按实际训练的小时计算,使用公有云GPU服务器的情况下,才十几元成本)。硬件成本预计一年内可以降低为大家都能接受的水平。那么数据就是壁垒。模型目前已经不是壁垒(我不想做SOTA,state of the art)。
- 本文是系列的第一篇文章,后续还会有其他安全领域的小小的大模型呈现给大家。
- 如果需要模型和训练代码,可以私聊我。
如有侵权请联系:admin#unsafe.sh