本篇文章就讨论一个问题扫描器判定 header 方面是不是应该再宽泛一些?大小写问题http 2.0 问题0x00 背景 在最近的一次开发中,使用 nodejs 的 axios 发起 http 请求后 2023-5-5 21:20:16 Author: NOP Team(查看原文) 阅读量:64 收藏
本篇文章就讨论一个问题
扫描器判定 header 方面是不是应该再宽泛一些?
大小写问题 http 2.0 问题
0x00 背景
在最近的一次开发中,使用 nodejs 的 axios 发起 http 请求后,处理结果时发现, axios 返回的结果中 header 都是小写的,例如我们常见的 Content-Type 、 Content-Length、Server 等,我一看,这简单,我写了一个函数,将每条 header 的key取出来,按照 - 进行分割,对分割得到的部分进行首字母大写不就完了
但是转念一想,似乎不靠谱,这样做相当于在对原始报文进行修改。如果目标服务器就是返回了小写的 header,那就改变了原始结果。
诶?
header可以是小写的吗?
服务器可以返回小写的header吗?
burpsuite 看到的好像都是单词首字母大写,是真的都是大写还是burpsuite 帮我们改了?
各个扫描器都是怎么判定的呢?
带着这几个疑问,开启本篇文章
0x01 header 是如何规定的
根据 RFC 9110 - section 5.1 , http/1.1 协议的 header 的 name 字段是大小写不敏感的,也就是大小写都可以
参考文档
https://www.rfc-editor.org/rfc/rfc9110.html#section-5.1
根据 RFC 9113 - section 8.2 http/2.0 协议中,上述RFC 9110 - section 5.1规定的 header 的 name 字段必须转化为小写,也就是说 http/2.0 帧中的 header name 字段传输的都是小写的 (当然,这只是标准,具体实现不见得大家都遵守)
所以综上来说,在 http/1.1 中, Content-Type 、 Content-type、content-type、coNtent-type 都是合法且结果相同的。http/2.0 中应该为 content-type
0x02 服务器可以返回小写的header吗
根据RFC的规定,看来是可以的,但是我们也试一下
1. 使用 curl + nc 进行测试
nc 监听 80 端口
nc -lp 80
curl 发起 http HEAD 请求
curl -I 192.168.1.1
将返回内容粘贴进入 nc ,并发送
可以看到, curl 成功获取到我们输入的小写 header
2. 搭建 apache2 + php 进行验证
环境是 Ubuntu Server 22.04
安装 apache2
sudo apt update
sudo apt install apache2
安装后,apache2 会立即启动
安装 php
sudo apt install php libapache2-mod-php
自定义 header
参考
https://www.php.net/manual/zh/function.header.php
先使用上述网站中提供的案例
可以展示我们自定义的 header
修改 l.php
<?php
header('content-type: application/pdf');?>
这里对比上面的案例我们发现,似乎 php 默认会将我们提供的字符串进行处理,将 Content-type 和 content-type 处理为 Content-Type
是所有的header name 都会这样处理吗?我们修改一些自定义 header 的 name
<?php
header('dontent-type: application/pdf');?>
这回 php 就没有帮我们进行处理,似乎 php 对一些常见且重要的 header 做了自动化处理
0x03 burpsuite 中可以展示小写header 吗
显然,之前 burpsuite 中header 都是大写是我的一种错觉
0x04 各个扫描器是如何判定的呢?
这里选择了 nuclei、xray、goby 来进行测试
因为这几个扫描器都支持自定义 PoC ,所以场景就设置为访问 l.php ,判定条件 header 中包含 dontent-type 这个 header name
1. nuclei
https://nuclei.projectdiscovery.io/
更新 nuclei 和 template
nuclei -un / nuclei -up 从某个版本后, -un 参数变成了 -up
nuclei -ut
检查实验环境
使用 curl 访问 http://192.168.31.187/l.php
按照上面设计的场景,此判定条件为 true ,也就是存在漏洞
生成 PoC 并检测
下面使用 nuclei-burp-plugin 帮助我们快速生成 PoC
nuclei-burp-plugin
https://github.com/projectdiscovery/nuclei-burp-plugin
可以看到,如果服务器返回的 header是小写的, nuclei 默认情况会判断失败
进一步测试 header value
但是如果我们设置的判定字符不是header name,而是 header value 中的字符,则会判定成功
初步结论
这意味着nuclei 或者nuclei 用来发包的模块会改变服务器返回的内容,即 header 的 name 字段的大小写
对结论进一步验证
通过以上测试,验证了我们的结论,同时也探测清楚了 nuclei 是如何修改 header name 的
2. xray
https://xray.cool/
更新 xray
xray upgrade
检查实验环境
按照上面设计的场景,此判定条件为 true ,也就是存在漏洞
生成 PoC 并检测
下面使用 XRAY 规则实验室进行快速生成 PoC
XRAY 规则实验室
https://poc.xray.cool/
成功发现漏洞
进一步测试
修改 PoC 中的条件 dontent-type 为 Dontent-type , 漏洞服务器不变
依旧能检测出漏洞存在
PoC 中判定条件还是设置为 dontent-type,修改漏洞服务器响应为 Dontent-tYpe
依旧可以检测出漏洞
PoC 中判定条件还是设置为 dontent-type,修改漏洞服务器响应为 Dontent-tYpeaaa
这次就检测不到漏洞了,因为我们把漏洞返回给改了嘛
结论
xray 判定 header name 时是将服务器返回的header name 以及 PoC 中指定的字符同时转化为小写或者大写来进行判定的,判定的是字符串相等关系,而不是包含关系或者说判定的是数组中包含某个字符串,而不是字符串包含某个字符串。
这个验证方式我觉得算是相对比较好的了
3. goby
https://gobysec.net/
更新 goby
检查实验环境
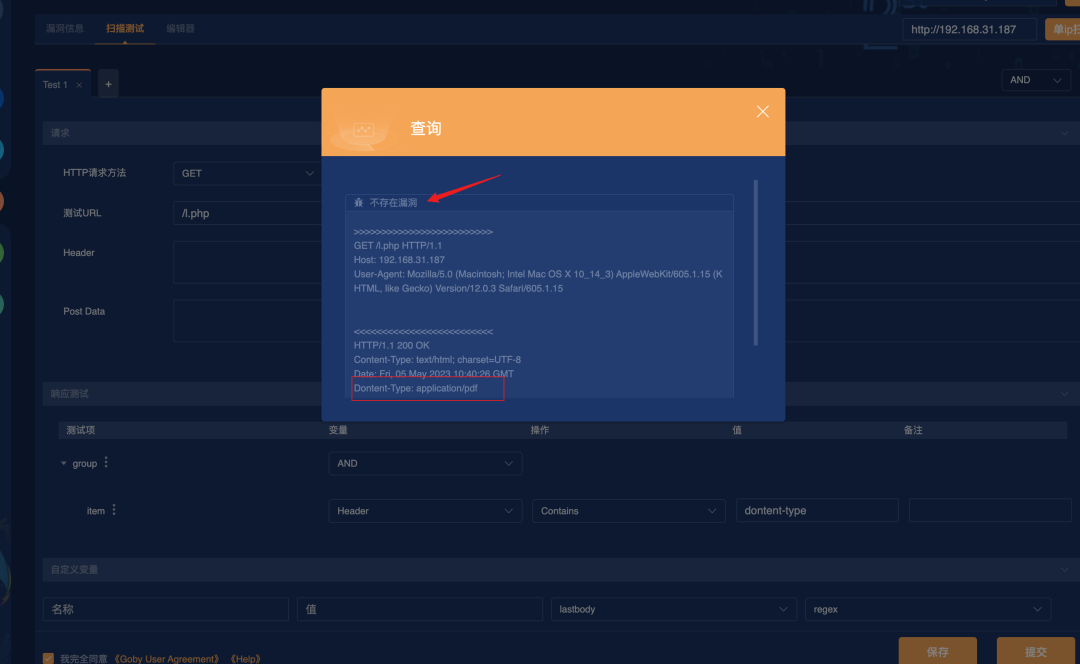
生成 PoC 并检测
保存后进行测试
检测失败,Goby 比较清晰地将返回包的部分内容返回到了页面上,我们可以看到红框内显示的返回内容为 Dontent-Type: application/pdf
初步结论
Goby 也自动进行了一些大小写转换,默认格式为 Dontent-Type
对结论进一步验证
从结果来看,Goby 会将服务器返回的 header name字段自动化做处理,导致小写的header或者说不符合 Goby 规范的 header 会判断失误。Goby 做判定的时候,是字符串包含进行判断的。
0x05 寻找原因
这三款扫描器都使用 Go 进行开发,而且 nuclei 是开源的,因此直接分析 nuclei 的源代码就好,遗憾的是我不了解 go 语言,只能浅浅地分析一下
https://github.com/projectdiscovery/nuclei
1. 寻找发包的部分
https://github.com/projectdiscovery/nuclei/blob/main/v2/pkg/protocols/http/http.go#L359
找到了似乎是发起http请求的部分
接下来找 request 这个对象是哪里来的
github 这个功能挺好,你点击这个对象,右边就会有一些提示,根据提示可以找到定义的地方,点击右边就可以跳转
https://github.com/projectdiscovery/nuclei/blob/main/v2/pkg/protocols/http/request_annotations.go#L51
可以看到,request 是从 retryablehttp 这里来的,继续
通过 Ctrl + f 搜索到,这是一个外部的包 github.com/projectdiscovery/retryablehttp-go
直接放到浏览器进行访问
发现也是他们组织的一个项目,我们想办法使用这项目对漏洞环境发起请求试试
2. 测试 retryablehttp-go
在页面介绍中,给了一个案例,位于 https://github.com/projectdiscovery/retryablehttp-go/blob/main/examples/main.go
package mainimport (
"fmt"
"io"
"github.com/projectdiscovery/retryablehttp-go"
)
func main() {
opts := retryablehttp.DefaultOptionsSpraying
// opts := retryablehttp.DefaultOptionsSingle // use single options for single host
client := retryablehttp.NewClient(opts)
resp, err := client.Get("https://scanme.sh")
if err != nil {
panic(err)
}
defer resp.Body.Close()
data, err := io.ReadAll(resp.Body)
if err != nil {
panic(err)
}
fmt.Printf("Data: %v\n", string(data))
}
go 这语法还挺奇怪的,整个冒号加等号,像表情包一样
想要运行这个文件,单独 go run main.go 似乎还不太行,会报错,需要整个项目下载下来
修改 main.go 的内容,测试代码可能不太符合 go 语言的规范,但是能用就行
package mainimport (
"fmt"
"io"
"github.com/projectdiscovery/retryablehttp-go"
)
func main() {
opts := retryablehttp.DefaultOptionsSpraying
// opts := retryablehttp.DefaultOptionsSingle // use single options for single host
client := retryablehttp.NewClient(opts)
resp, err := client.Get("http://192.168.31.187/l.php")
if err != nil {
panic(err)
}
defer resp.Body.Close()
data, err := io.ReadAll(resp.Body)
if err != nil {
panic(err)
}
fmt.Printf("Data: %v\n", string(data))
fmt.Printf("%+v", resp)
}
可以看到 resp 这个对象似乎有 Header 成员,进而打印 Header
package mainimport (
"fmt"
"io"
"github.com/projectdiscovery/retryablehttp-go"
)
func main() {
opts := retryablehttp.DefaultOptionsSpraying
// opts := retryablehttp.DefaultOptionsSingle // use single options for single host
client := retryablehttp.NewClient(opts)
resp, err := client.Get("http://192.168.31.187/l.php")
if err != nil {
panic(err)
}
defer resp.Body.Close()
data, err := io.ReadAll(resp.Body)
if err != nil {
panic(err)
}
fmt.Printf("Data: %v\n", string(data))
// fmt.Printf("%+v", resp)
fmt.Printf("%+v", resp.Header)
}
我们先将打印结果与 curl 打印的结果放在一起对比
可以看到, curl返回的 header name 为 dontent-tyPeaaa 也就是实际上服务器返回的;retryablehttp-go 返回的 header name 为 Dontent-Typeaaa ,其对 header name 进行了格式化的处理
因此, nuclei 获取的结果也是被格式化后的,但是 goby 也能得到类似的结果,难道 goby 也使用了这个组织的库吗?
带着这个疑问,又对这个库进行了一番分析
https://github.com/projectdiscovery/retryablehttp-go/blob/main/request.go
https://github.com/projectdiscovery/retryablehttp-go/blob/main/http.go
发现这个项目似乎使用了名为 net/http 这个库来发起 http 请求,这名字看起来是个官方库
3. 测试 net/http
参考
https://www.liwenzhou.com/posts/Go/http/
通过参考上面的文章,发现这确实是个官方库,这里直接使用博客里提供的代码,做一些修改
package mainimport (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
resp, err := http.Get("http://192.168.31.187/l.php")
if err != nil {
fmt.Printf("get failed, err:%v\n", err)
return
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Printf("read from resp.Body failed, err:%v\n", err)
return
}
fmt.Print(string(body))
fmt.Printf("%+v", resp.Header)
}
幸运的是这个代码可以直接 go run xxx.go 来执行
可以看到,net/http 获取的结果为 Dontent-Typeaaa, curl 获取的结果为 dontent-tyPeaaa ,所以根源是在这里
4. 猜测原因
Goby 和 Nuclei 都是因为直接或间接使用了
net/http这个库,因此获取到的 Header 都是格式化过的Xray 要么是没使用这个库;要么就是使用的将判断字符和服务器返回的header同时进行了大写或者小写的统一处理
0x06 小小的建议
建议各个扫描器能够对 response header name 忽略大小写后进行判断,如果为了保证准确率不能忽略大小写,至少也要保证从服务器获取到的 response header name 是未经格式化处理的,与服务器保持一致的
对于 http 2.0 协议的服务器,将服务器返回的 header 和 用户提交的判断字符都转化成小写进行判断
0x07 往期文章
如有侵权请联系:admin#unsafe.sh