
Can ChatGPT detect phishing links?Hearing all the buzz about the amazing applications 2023-5-1 18:0:20 Author: securelist.com(查看原文) 阅读量:45 收藏
Can ChatGPT detect phishing links?
Hearing all the buzz about the amazing applications of ChatGPT and other language models, our team could not help but ask this question. We work on applying machine learning technologies to cybersecurity tasks, specifically models that analyze websites to detect threats such as phishing. What if all our complex, multi-layered detection systems are now obsolete, and a single LLM (large language model) to rule them all can fight cybercriminals better than we do?
To answer this question, we conducted an experiment to see how good ChatGPT is at recognizing overtly malicious links. In this article, we provide a practical example of how an LLM can be applied to a real, albeit simplified, cybersecurity task, and describe all the interesting things we learned along the way. Since we didn’t have any illusions that ChatGPT could actually be used as a detection method, our primary goal was to find out how much cybersecurity knowledge ChatGPT has learned from its training data and how it could possibly assist a human analyst in their job.
Why URL classification?
An analyst’s trained eye can spot an obviously malicious link in a split second (and you probably can too):
hxxp://caseld-10xxxx.info/1/Office365/0fflce3.6.5/live/login.php
- This is not the Office365 login link, is it?
(links in the article are partially masked with x)
A rule of thumb for finding tasks to which ML can be applied is that if a person can do it instantly, almost without thinking, it’s probably a good candidate. Still, building a machine-learning system requires a lot of effort, from gathering data and crafting features to preparing the infrastructure. The promise of replacing all that with a single interface configured via natural language sounds too good to be true, but just how far is it from being a reality?
When conducting this experiment, we were well aware of the limitations of large language models, as well as the fact that OpenAI asks that this emerging technology not be applied to any high-risk area, and state the following regarding GPT-4’s cybersecurity applications in the system card:
However, GPT-4 has significant limitations for cybersecurity operations due to its “hallucination” tendency and limited context window.
It is natural to assume that GPT-3.5-turbo will exhibit these limitations to a greater extent.
We chose the URL classification task because:
- Unlike a whole HTML page, a URL fits easily into an LLM, because modern LLMs, such as ChatGPT, can only consume a limited number of symbols (more precisely, tokens) at a time (they have a fixed context window, in LLM-speak).
- Obviously malicious links are easy to detect, but the task is still non-trivial, because it requires world knowledge (for example, knowing the names of popular web services).
- URLs are still text, and LLMs are good at processing text.
So here is what we did.
Let’s talk?
First of all, we opened the ChatGPT web interface and checked if what we wanted was even possible:
Judging by the URL, is this link a phishing attempt? Please explain why. Link: hxxp://caseld-10xxxx.info/1/Office365/0fflce3.6.5/live/login.php
Yes, it is likely a phishing attempt.
The URL appears to be intentionally deceptive, as it contains several red flags:
- The domain name “caseld-10xxxx.info” is not associated with any reputable or recognizable entity, and it looks like a random sequence of letters and numbers.
- The URL uses the term “Office365” which is a popular productivity suite, and it is a common target for phishing attacks. Cybercriminals often use this tactic to lure unsuspecting victims into clicking on a link and disclosing sensitive information.
- The word “live” in the URL could be used to imply that the page is an official Microsoft Office365 login page, as Microsoft has used “live” in the past in some of its services.
- The misspelling of “Office” as “0fflce” is another red flag as it is a common tactic used by phishers to trick users into believing the website is legitimate.
- The “.php” extension at the end of the URL suggests that it is a PHP script running on a server, which is commonly used in phishing attacks to harvest login credentials.
Therefore, it is advisable to avoid clicking on such links and to always check the URL’s legitimacy before entering any personal information or credentials.
This is a pretty reasonable explanation. Aside from the fact that the model shows some distrust of PHP (well, who doesn’t?), it is good at recognizing the target organization, a homographic attack (0ffice), and even points out why “live” might have been used. This is an explanation worthy of a junior analyst.
To gather a corpus of explanations, we used OpenAI API to query the model called gpt-3.5-turbo, which is the backend for ChatGPT. It is fast and cheap (we check a lot of links), but still powerful enough. For the test corpus, we gathered a few thousand links that our detection technologies deemed phishing, and threw in a few thousand safe URLs.
Attempt 1. Is it phishing?
ChatGPT is great at providing the answer in the form that you require – from poems:
And lastly, “0fflce” it doth spell amiss,
A trick oft used by phishers with a hiss.
Beware, dear user, and take great care,
Lest thou fall victim to this cyber snare.
to machine-readable formats. It can also do more than one thing at once. This means that in addition to the yes/no answer to the question about link safety, we could ask ChatGPT to format the response as JSON and also to include a rationale, as well as the possible target. So, after a few iterations, we settled on the following prompt:
{"role": "system", "content": "You are CyberGPT, a guru cyber security assistant AI."}, { "role": "user", "content": 'Does this link lead to a phish website? Answer in the json format {"phish": "yes|no", "reasoning": "detailed explanation why", "target_company": "possible targeted company"}\nLink: ' + url } |
We use a system prompt here (according to practitioners and docs, this is less important than the user input) that portrays ChatGPT as a cybersecurity chatbot and ask for its verdict in the user prompt. Frankly, the fact that it is so easy to get the desired output from ChatGPT is awe-inspiring.
It took us two nights to get about 6,000 verdicts (probably because we ran the experiment at the peak of all the hype), and once we got the data, we proceeded to parse the results.
Unfortunately, while most of the outputs could be parsed as is, some were corrupted: some contained additional text, such as “Note: be careful when opening links…” or just a dot at the end, others had unnecessary escape characters. All in all, less than 0.5% of JSONs were broken beyond automated fixes or contained text such as:
I am sorry, but as an AI language model, I am not able to access the internet or browse the website provided. However, as per the standard industry practices, you can check the legitimacy of the website by running it through a reputable online phishing detection service/provider. Additionally, if there are any official reports of phishing attacks or scams associated with the target company, it further increases the likelihood of the link leading to a phish website.
Which is still a reasonable answer.
All in all, after all the errors and rejections, we were left with a dataset of 2322 phish and 2943 safe URLs. The resulting metrics are:
- Detection rate: 87.2%
- False positive rate: 23.2%
While the detection rate is very high, the false positive rate is unacceptable. Imagine if every fifth website you visit was blocked? Sure, no machine learning technology on its own can have a zero false positive rate, but this number is too high. To put this in perspective, in a well-known paper called URLnet, where Le et al. solved a very similar task, the authors managed to achieve about the same level of detection rate (~85%) with a false positive rate of about 0.4% with a specially crafted convolutional neural network. A more recent URLTran paper by Maneriker et al. uses Transformers (the same architecture that powers ChatGPT) to achieve an even lower FPR.

ROC curve from Le et al., 2018, illustrating achievable TPR (DR)/FPR values
Unfortunately, there are no miracles here. This is also where we met the first limitation – we can’t adjust the threshold to trade FPR for DR. Or can we?
The second experiment: ‘Is it safe?’
Our prompt was probably too specific and cued the language model to view the link with suspicion. Instead of asking if the link is phishing, we could ask if it is safe to visit, and maybe the LLM would behave less suspiciously. This led us to the second prompt:
{"role": "system", "content": "You are a helpful internet security assistant chatbot."}, { "role": "user", "content": 'Is this link safe to visit? ' 'Answer in the json format: {"safe": "yes|no", "yes_confidence": 0.5}' '\nwhere "yes_confidence" is the confidence that the link is safe from 0 to 1. ' 'Only output json.' '\nLink: ' + url }, |
Differences from the previous prompt:
- Gone is the ‘cybersecurity guru’, who by nature should be suspicious of random links
- We don’t ask for the target, so as not to alert the model that this is a phishing detection task
- We do, however, ask for confidence. Though this is very unlikely, confidence may prove useful.
The results were quite discouraging:
- Detection rate: 93.8%
- False positive rate: 64.3%
It turns out that the more general prompt is more likely to prompt a verdict that the link is dangerous. This is how the links from the safe subset of data changed the assigned verdicts, compared to the previous cybersecurity guru prompt:
| Internet security assistant chatbot verdicts (safe data) | safe | unsafe |
| CyberGPT cybersecurity guru verdicts (safe data) | ||
| safe | 1049 | 1210 |
| phish | 2 | 682 |
Interestingly, the confidence choices are more like human-assigned confidence in the sense that round numbers like 90% occur most often:
TOP 5 probabilities that the model chose. Note that they are rounded to 0.1 (download)
At least the ROC curve looks alright, but there is no point at which this prompt would outperform the cybersecurity guru from the previous attempt:

ROC curve based on probabilities provided by ChatGPT
To conclude, it is hard to predict the behavior of the LLM based on human reasoning about the prompt. Probably the “safety” of a link is a vaguer concept than “phish”. Understanding why the first prompt won by a large margin is difficult, and choosing the best prompt at this time, despite the emergence of new prompt engineering techniques, is more art than science.
Verdict stability
An important fact about LLMs is that the generation process is random. While you can coerce an LLM to be almost deterministic by setting its temperature parameter, which actually controls the output randomness, to 0 (there are still numerical sources of non-determinism), it usually leads to poor performance (such as the tendency to repeat the same phrase over and over again). As a result, for each token (a word or its part) that the network generates, it has a few alternatives among the choices (also controllable by parameters).
Non-deterministic verdicts are not the top feature you expect from a detection system. To measure its impact on the results, we conducted another small experiment in which we chose 200 random URLs (100 safe and 100 phish) and gathered verdicts with the same simplified prompt:
{"role": "system", "content": "You are a helpful internet security assistant chatbot."}, { "role": "user", "content": 'Is this link safe to visit? ' 'Answer in the json format: {"safe": "yes|no"}' '\nOnly output json.' '\nLink: ' + url }, |
This is how the results of these two identical runs compare (the responses are not post-processed and answer the question of whether the link is safe):
| Run 2 | no | unknown | yes |
| Run 1 | |||
| no | 145 | 2 | 3 |
| yes | 4 | 0 | 46 |
So, the verdict for 4.5% percent of the URLs changed due to the randomness of the LLM, with the variation in verdicts between runs on safe URLs being 7%. Again, while this can be remedied by tweaking the temperature, it’s an important factor to keep in mind when using LLMs.
The most striking aspect of ChatGPT’s performance was the extraction of the potential phishing target. When attackers craft their samples, they try to trick users into believing that the URL is genuine and belongs to a company, while also obfuscating it enough to fool automated analysis. Extracting the attack target can be useful in many scenarios.
ChatGPT has enough real-world knowledge to know about many internet and financial services and with only a small post-processing step (e.g., merging “Apple” and “iCloud” or removing “LLC” and “Inc”) it does a very good job at extracting them. It was able to identify a target more than half the time. Note that not every URL contains a reference to a target organization. Among the identified companies, there were major tech portals like Facebook, TikTok and Google, marketplaces such as Amazon and Steam, lots of banks from all over the world, from Australia to Russia, cryptocurrency and delivery services.
Some interesting examples include:
URL: hxxps://steancxxxmuunity.com/profiles/765xxxxxxxxxx175
Organization: Steam
Reasoning: The domain name ‘steancxxxmuunity.com’ appears to be a typo-squatting attempt. The correct spelling of the domain should be ‘steamcommunity.com’. The website is trying to impersonate Steam Community, a popular gaming platform…
URL: https://cxxxxxxxxr.com/wp-includes/js/jcrop/cgi/BOfA/Validation/login.php?cmd=login_submit
Organization: Bank of America
Reasoning: The link is suspicious and indicates a phishing attempt because the domain name is not related to the possible targeted company (Bank of America), the URL is also suspicious containing additional characters such as ‘/wp-includes/js/jcrop/cgi’…
URL: http://caseld-10xxxx.info/1/Office365/0fflce3.6.5/live/login.php
Organization: Microsoft
Reasoning: The link’s domain name (caseld-10xx93.info) does not appear to be related to Microsoft’s Office 365 service. The URL path also contains a misspelled version of the word ‘office’ (0fflce) and a suspiciously old version number (3.6.5).
URL: http://adobexxxsignxxxx.duckdns.org/ees/
Organization: Adobe
Reasoning: The domain name ‘duckdns.org’ is a free dynamic DNS provider which is often used by cyber criminals for hosting phishing sites or other malicious content. Additionally, the subdomain adobexxxsignxxxx in the URL appears to imitate the legitimate Adobe service ‘Adobe Sign’, which suggests that the attackers may be targeting Adobe’s customers for information theft or fraud.
Here we see that ChatGPT detects homographic attacks (although it can confuse them with typo-squatting), and correctly states that the domains are not related to the companies. While it fails to untangle that “3.6.5” is an imitation of 365, the explanations are quite reasonable.
Implicit knowledge: reasoning analysis
The examples above are cherry-picked. When cherry-picking with the opposite intention, some funny things happen. The explanations that ChatGPT provides may include:
- References to WHOIS, which the model doesn’t have access to:
- Finally, if we perform a WHOIS lookup for the domain name, it was registered very recently (2020-10-14) and the registrant details are hidden.
- References to content on a website that the model doesn’t have access to either:
- the website is asking for user credentials on a non-Microsoft website. This is a common tactic for phishing attacks.
- Additionally, the webpage’s layout and design are inconsistent with eBay’s official website, indicating that it may be a fake website designed to impersonate eBay.
- There is also no information available on the website’s security and privacy policy. A secure website should provide that information transparently to users.
- References to SSL certificate expiration:
- The domain ‘duckdns.org’ is not owned by Netflix, and the SSL Certificate is invalid.
- Misstatements:
- The domain ‘sxxxxxxp.com’ is not associated with Netflix and the website uses ‘http’ protocol instead of ‘https’ (the website uses https)
- Revelatory nuggets of cybersecurity information:
- The domain name for the URL ‘yxxxx3.com’ appears to be registered in Korea which is a red-flag.
These are funny and highlight the limitations of an LLM: while it can generate reasonable explanations, it is also prone to hallucinations – such as imagining contexts that it does not have access to, or coming up with facts that are just plain wrong.
In general, however, we see that the model demonstrates a non-trivial understanding of the task. Analyzing all the explanations by hand would be laborious, so we do some distant reading here to get a bird’s-eye overview of the reasonings it generates by applying a little bit of old-school NLP.
First of all, we noticed that the model used mostly short, terse sentences with one point per sentence in its explanations. We split the statements into sentences using the NLTK Punkt tokenizer. The resulting sentences were then vectorized using MPNet from the Sentence-Bert package, and then visualized using UMAP. To color the resulting plot, we used DBSCAN clustering. A few iterations of hyperparameter tweaking yield the following result:
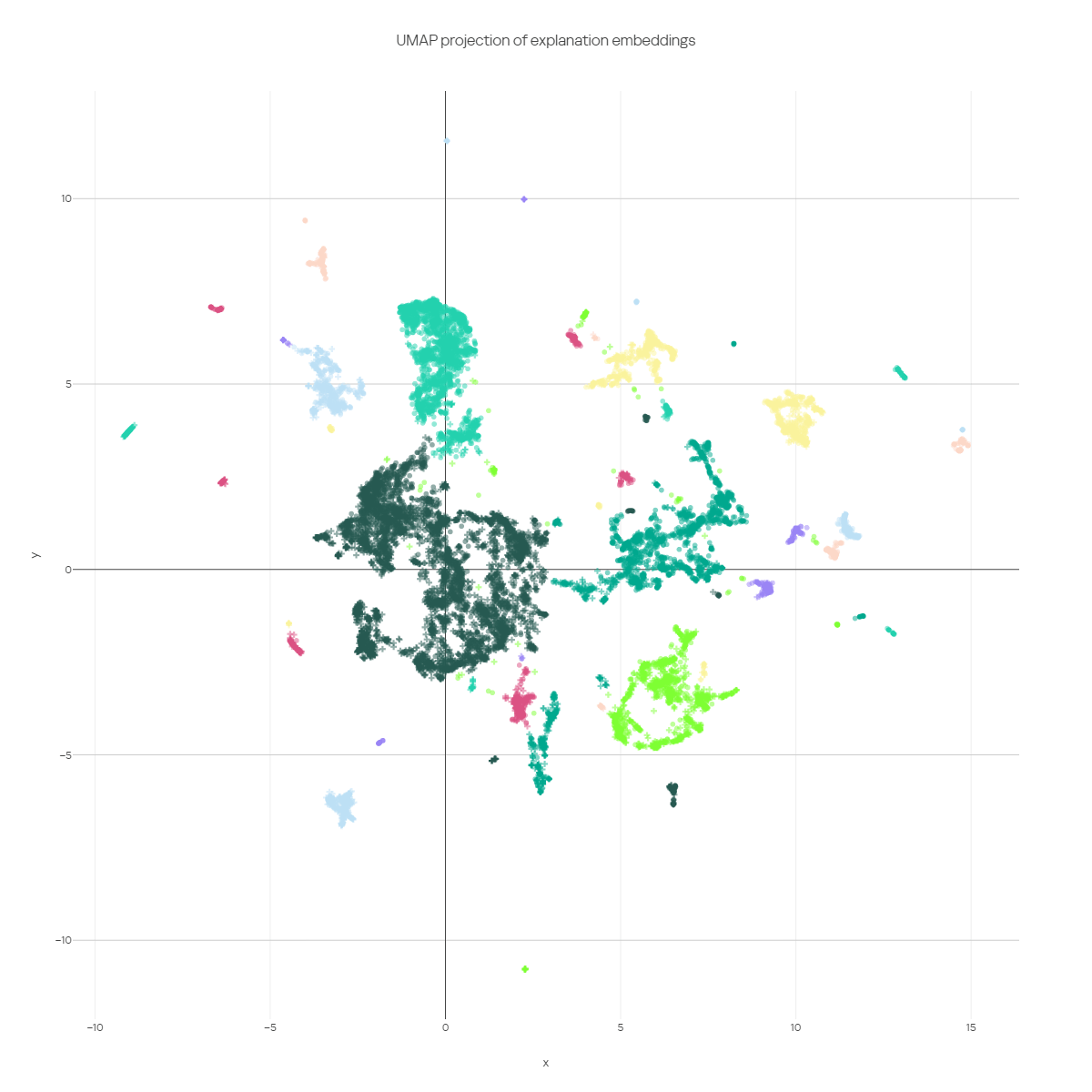
Cluster analysis of explanations provided by ChatGPT. Semantically close reasons form dense clusters.
These dense clusters reveal the most popular phrases that the model provides as explanations. Some of these clusters are:
- Mentions of particular target companies.
- Recommendations not to click the link.
- Certain statements about the website being phish or not.
- Statements of uncertainty.
- References to HTTPS (or lack thereof) or SSL (usually hallucinations)
- Sentences like “This is a common tactic…”
However, some of them reveal “common tactics”:
- Use of IPFS: “The URL looks suspicious and appears to be hosted on IPFS which can be used to host malicious content.”
- Suspicious elements in path, including homographic attacks: “This link is an example of a homograph attack also known as ‘IDN homograph attack’.”
- Elements in path or domain that are related to security and urgency: “Lastly, the URL has a sense of urgency to it, indicating that the user needs to click immediately.”
- Use of dynamic DNS: “The domain name ‘duckdns.org’ is a free dynamic DNS provider that can be used by anyone to create custom subdomains, which makes it easy for attackers to use for phishing emails or websites impersonating legitimate companies”.
- An email in the parameters: “Additionally, the email address used as a query parameter may indicate a potential phishing attempt.”
- Mention of an organization in the path or subdomain while the domain is not related to the organization: “The link appears suspicious as it contains a subdomain that is not related to Amazon.”
- Elements in the domain that look autogenerated: “Also, the path ‘bafyxxxxxxxxxxxxxxxxxx43ky’ suggests that this is an autogenerated link.”
These points make a lot of sense. This means that the training data for ChatGPT contained enough cybersecurity material for the LLM to learn the telltale signs of phishing attempts and use this knowledge to analyze specific cases, which is very impressive.
Conclusion
As we have seen, for a zero-shot system the results are amazing – it is hard to argue with, even for a die-hard sceptic. Anecdotal examples, especially the cherry-picked ones, are also very impressive. This is why, when we talk about real-world performance, a screenshot from Twitter is not a solid basis for decision-making. This is especially true in cybersecurity, where applying automated scenarios to our tasks means going far beyond “good” or even “impressive” performance.
As with many other use cases, the core detection task is only part of the problem. Creating signatures or blocklist records, validating and testing them, delivering them, ensuring quality of service is less glamorous, but just as important, and here we need a lot of hard work done by humans to get things rolling.
Moreover, the use of LLM means applying a whole new set of skills. We could have improved the results, both in detection, target organization extraction and reasoning, by trying various things:
- Using a stronger model, such as GPT-4
- Using special prompt-designing patterns, such as Chain-of-Thought-prompting or Reflect-Critique-Improve
- Feeding parts of the HTML along with the URL
- Adjusting the system prompt and sampling parameters, such as temperature, etc.
However, this means abandoning the hope of a zero-shot AI that “just works”. Also, using LLMs means dealing with their current idiosyncrasies, such as the demonstrated tendency to hallucinate (manifested by coming up with imaginary explanations and referring to page texts it has never seen), randomness of output, as well as possible prompt injection attacks.
On the other hand, if we look at the organization extraction and reasoning, we have to admit that it performs on par with what we would expect from an intern-level phishing analyst: it is good, but never leave it without supervision! Therefore, it is possible to use this type of technology to assist flesh-and-blood analysts by highlighting suspicious parts of the URL and suggesting possible attack targets. It could also be used in weak supervision pipelines to improve classic ML pipelines.
All in all, while impressive, ChatGPT and LLMs are not yet ready to radically change the cybersecurity game, at least as far as phishing detection is concerned. At Kaspersky, we continue to investigate cutting-edge technologies and study their potential impact on both cyberattackers and defenders. Let’s see what happens next.
如有侵权请联系:admin#unsafe.sh