
前言
本文原文来自Hex-Rays Microcode API vs. Obfuscating Compiler。在IDA 7.1中IDA发布了反编译中使用的中间语言microcode,IDA 7.2和7.3中又新增了相关的C++和python API,这篇文章就是关于Rolf Rolles如何使用这一新功能来处理ollvm混淆的,代码地址:HexRaysDeob。我翻译过程中为了方便理解加入了一些数据结构说明和相关代码对照,并不与原文完全相同。文章较长,分为上下两个部分。
microcode和ctree
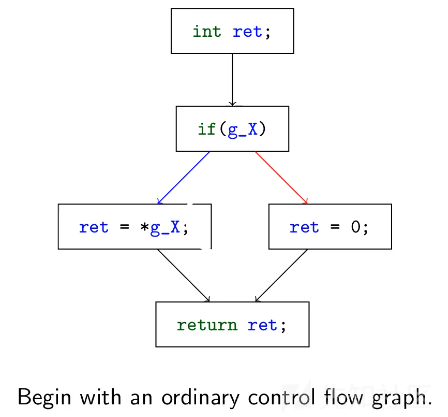
IDA反编译器中二进制代码有两种表示方式:
microcode:处理器指令被翻译成microcode,反编译器对其进行优化和转换。
使用HexRaysDeob插件除了处理ollvm混淆也可以查看microcode。

ctree:由优化的microcode构建而成,用C语句和表达式表示像AST一样的树。
使用HexRaysCodeXplorer插件或者IDApython中的示例vds5.py可以查看ctree。
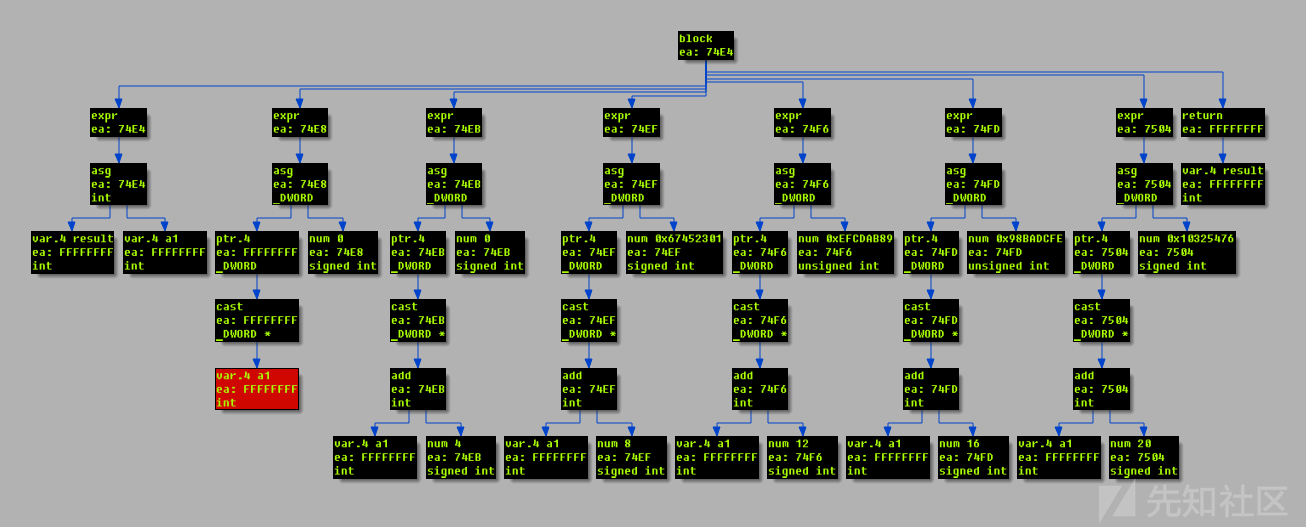
IDA反编译的整体流程如下所示。
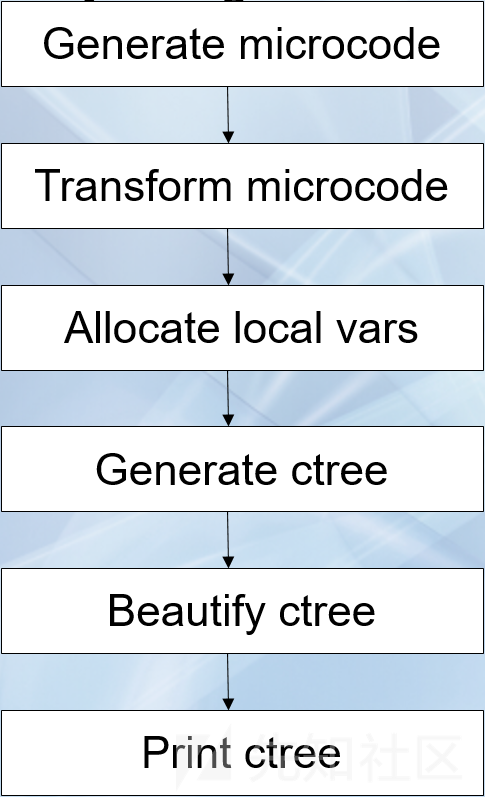
这篇文章重点说microcode。
microcode数据结构
microcode中四个比较重要的数据结构如下。
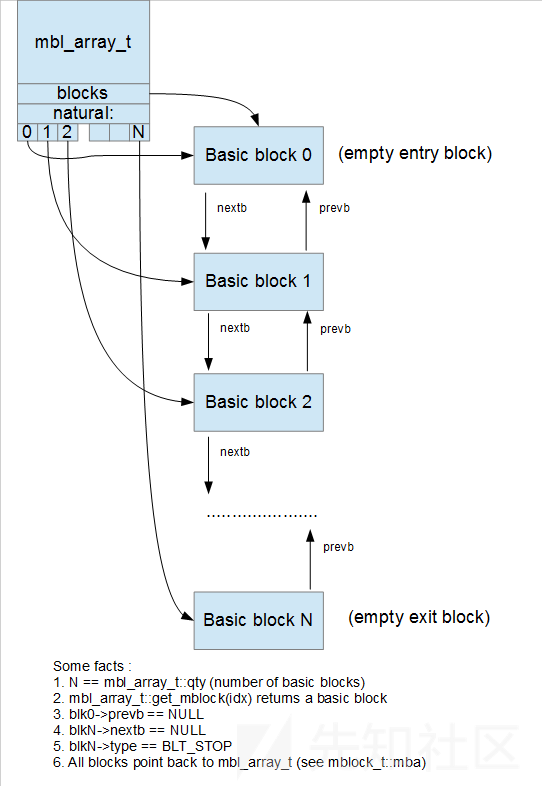
mbl_array_t
保存关于反编译代码和基本块数组的信息。包含的内容比较多,最重要的一个成员是qty,最重要的一个函数是get_mblock。
int qty; // 基本块数组的数量
get_mblock; // 根据序号返回数组中对应的基本块mblock_t
一个包含指令列表的基本块。
minsn_t
表示一条指令,class minsn_t中包含以下成员。指令可以嵌套,也就是说mop_t也可能会包含一个minsn_t。
mcode_t opcode; // 操作码 int iprops; // 一些表示指令性质的位的组合 minsn_t *next; // 双向链表中的下一条指令 minsn_t *prev; // 双向链表中的上一条指令 ea_t ea; // 指令地址 mop_t l; // 左操作数 mop_t r; // 右操作数 mop_t d; // 目标操作数
mop_t
表示一个操作数,根据它的类型可以表示不同的信息(数字,寄存器,堆栈变量等等),class mop_t中包含以下成员。
mopt_t t; // 操作数类型 uint8 oprops; // 操作数属性 uint16 valnum; // 操作数的值,0表示未知,操作数的值相同操作数也相同 int size; // 操作数大小 //下面的联合体中包含有关操作数的其它信息。根据操作数类型,存储不同类型的信息 union { mreg_t r; // mop_r 寄存器数值 mnumber_t *nnn; // mop_n 立即数的值 minsn_t *d; // mop_d 另一条指令 stkvar_ref_t *s; // mop_S 堆栈变量 ea_t g; // mop_v 全局变量 int b; // mop_b 块编号(在jmp\call指令中使用) mcallinfo_t *f; // mop_f 函数调用信息 lvar_ref_t *l; // mop_l 本地变量 mop_addr_t *a; // mop_a 操作数地址(mop_l\mop_v\mop_S\mop_r) char *helper; // mop_h 辅助函数名 char *cstr; // mop_str 字符串常量 mcases_t *c; // mop_c switch的case和target fnumber_t *fpc; // mop_fn 浮点数常量 mop_pair_t *pair; // mop_p 操作数对 scif_t *scif; // mop_sc 分散的操作数信息 };
它们之间的关系由下图所示。简单来说就是操作数(mop_t)组成指令(minsn_t),指令(minsn_t)组成基本块(mblock_t),基本块(mblock_t)组成mbl_array_t。


当HexRays在内部优化和转换microcode时,它将经历不同的成熟阶段(maturity phases),该阶段由类型为mba_maturity_t的枚举元素表示。例如,刚刚生成的microcode成熟度为MMAT_GENERATED,经过了局部优化之后的microcode成熟度为MMAT_LOCOPT,经过了函数调用的分析之后microcode成熟度为MMAT_CALLS。通过gen_microcode() API生成microcode时,用户可以指定需要优化microcode的成熟度级别。
使用IDA microcode去除ollvm混淆
样本中采用的混淆手段
基于模式的混淆
在该样本反编译的结果中可以看到相同的模式。
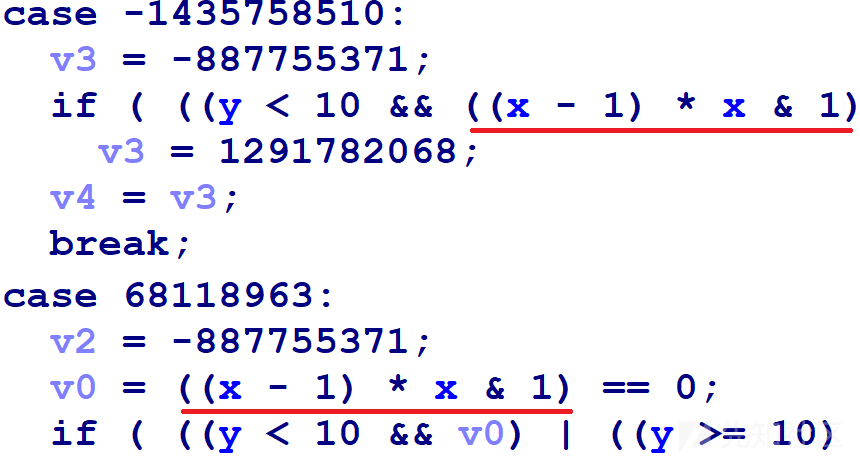
带下划线的部分在运行时始终为0,因为x是偶数或者奇数,并且x-1和x的奇偶性相反,偶数乘以奇数总是偶数,偶数的最低位为0,因此&1结果为0。这种模式还出现在带有AND复合条件的if语句中,AND复合条件结果总是为0,因此if语句永远不会执行。这是一种称为不透明谓词的混淆方式:条件分支运行时永远只会执行其中一条路径。
控制流平坦化
被混淆的函数具有异常的控制流。每个被混淆的函数都包含一个循环中的switch语句,这是一种被称为控制流平坦化(control flow flattening)的混淆方式。简而言之,它的原理如下。
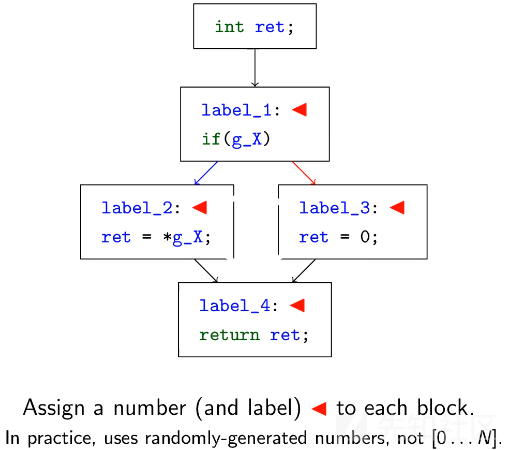
1.为每个基本块分配一个数字。
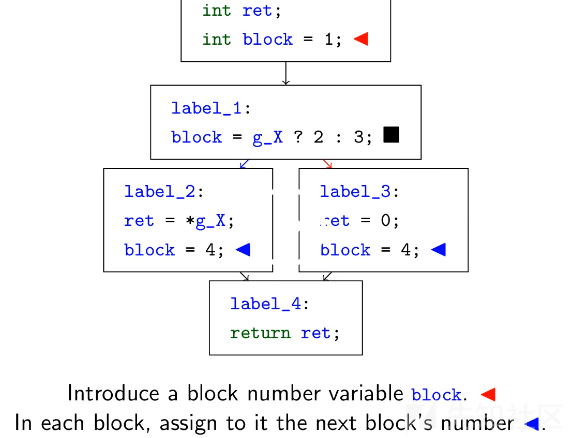
2.混淆器引入了块号变量,指示应执行哪个块。
3.每个块都不会像往常那样通过分支指令将控制权转移给后继者,而是将块号变量更新为其所选的后继者。
4.普通的控制流被循环内的根据块号变量执行的switch语句代替。
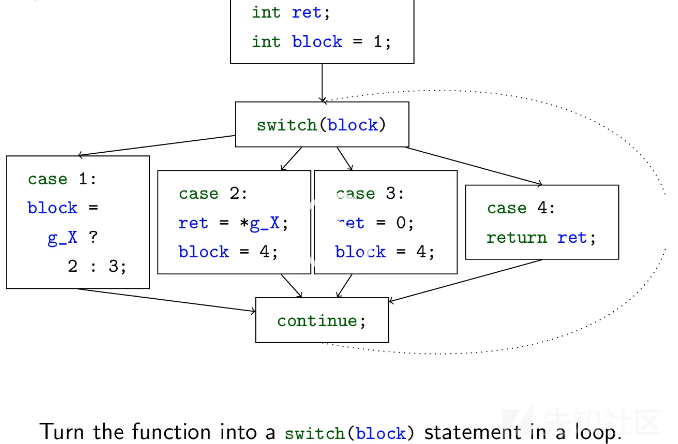
该样本一个被混淆函数的控制流switch的汇编代码如下所示。
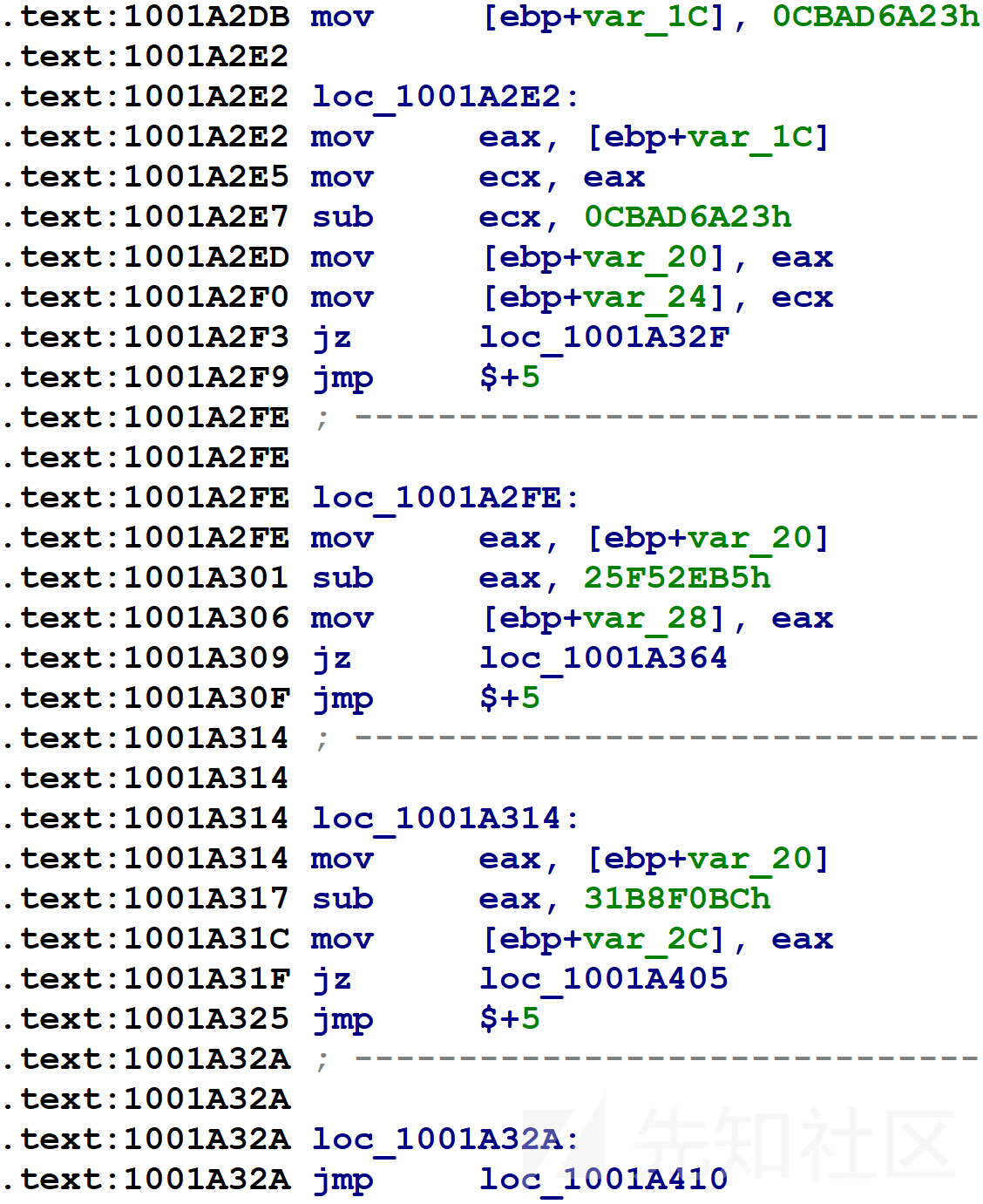
在第一行,var_1C即上面提到的块号变量被初始化为某个看起来很随机的数字。紧随其后的是一系列var_1C与其它随机数字的比较(var_1C复制到var_20中,var_20用于之后的比较)。这些比较的目标是原始函数的基本块。基本块在回到刚才显示的代码之前会更新var_1C指示下一步应执行哪个基本块,然后代码将执行比较并选择要执行的相应块。对于只有一个后继者的块,混淆器给var_1C分配一个常量,如下图所示。

对于具有两个可能的后继者(例如if语句)的块,混淆器引入x86 CMOV指令以将var_1C设置为两个可能的值之一,如下图所示。

整个函数看起来如下所示。
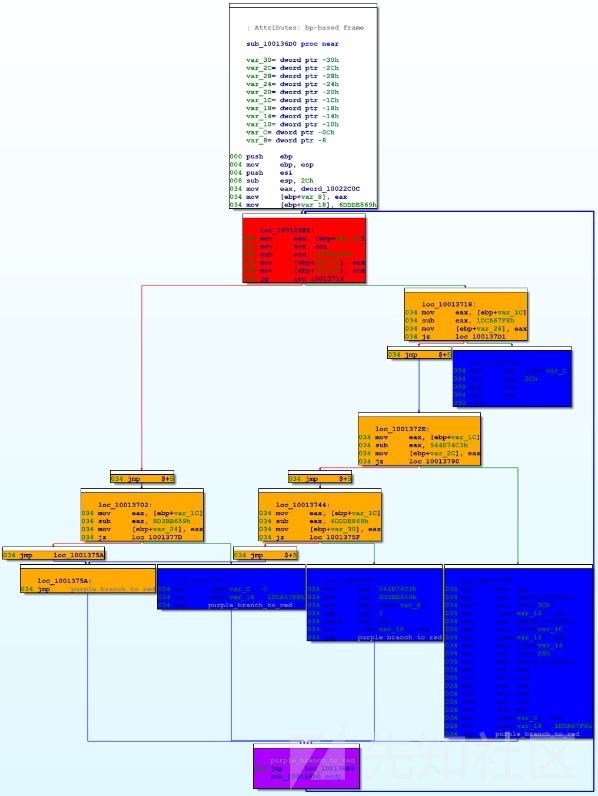
在上图中,红色和橙色节点是控制流switch的实现。蓝色节点是该函数的原始基本块(可能会进一步混淆)。底部的紫色节点返回到开头的控制流switch。
奇怪的栈操作
最后,我们还可以看到混淆器以不同寻常的方式操纵栈指针。它用__alloca_probe为函数参数和局部变量保留栈空间,而普通的编译器会在函数开头用push指令为所有局部变量保留栈空间。

IDA具有内置的启发式方法,可以确定__alloca_probe调用的参数并跟踪这些调用对栈指针的影响。但是混淆器使得IDA无法确定参数,因此IDA无法正确跟踪栈指针。
反混淆器代码结构
HexRaysDeob反混淆器的代码结构如下所示。
AllocaFixer:处理__alloca_probe
CFFlattenInfo:处理控制流平坦化之前的准备工作
main:插件入口
MicrocodeExplorer:显示microcode
PatternDeobfuscate/PatternDeobfuscateUtil:处理基于模式的混淆
Unflattener:处理控制流平坦化
DefUtil/HexRaysUtil/TargetUtil:其它功能
IDA的插件入口一般会有的三个函数是init,term和run,作用分别是初始化,清理和调用插件。init函数中调用了install_optinsn_handler函数和install_optblock_handler函数进行指令级别的优化(PatternDeobfuscate)和块级别的优化(Unflattener),HexRays会自动调用注册的回调对象。

PatternDeobfuscate和AllocaFixer的代码相对比较好理解,接下来会重点讲解关于处理控制流平坦化的代码。
前面说了IDA反编译器中二进制代码有microcode和ctree两种表示方式,那么使用microcode相关API而不是ctree相关API有什么好处呢?从前面的介绍中我们可以了解到ctree是由microcode产生的,microcode比ctree更“底层”。如果在microcode级别操作可以利用HexRays已有的恢复控制流的算法,另外一些模式在microcode级别能更好被匹配。
对抗控制流平坦化
简单来说,控制流平坦化消除了块到块直接的控制流传输。平坦化过程引入了一个块号变量,在函数执行的每一步它决定应该执行的块。每个展平函数的控制流结构都被转换为块号变量上的一个switch,它最终引导执行到正确的块。每个块必须更新块号变量,以指示在当前块号之后应该执行的块。
控制流展开过程在概念上很简单。简单地说,我们的任务是重建块到块直接的控制流传输,在此过程中消除控制流切换机制。在下面的小节中,我们将以图片的方式展示该过程。只需要三个步骤就可以消除控制流平坦化。一旦重新构建了原始的控制流传输,HexRays现有的控制流重组机制将完成剩下的工作。
确定平坦块编号到mblock_t的映射
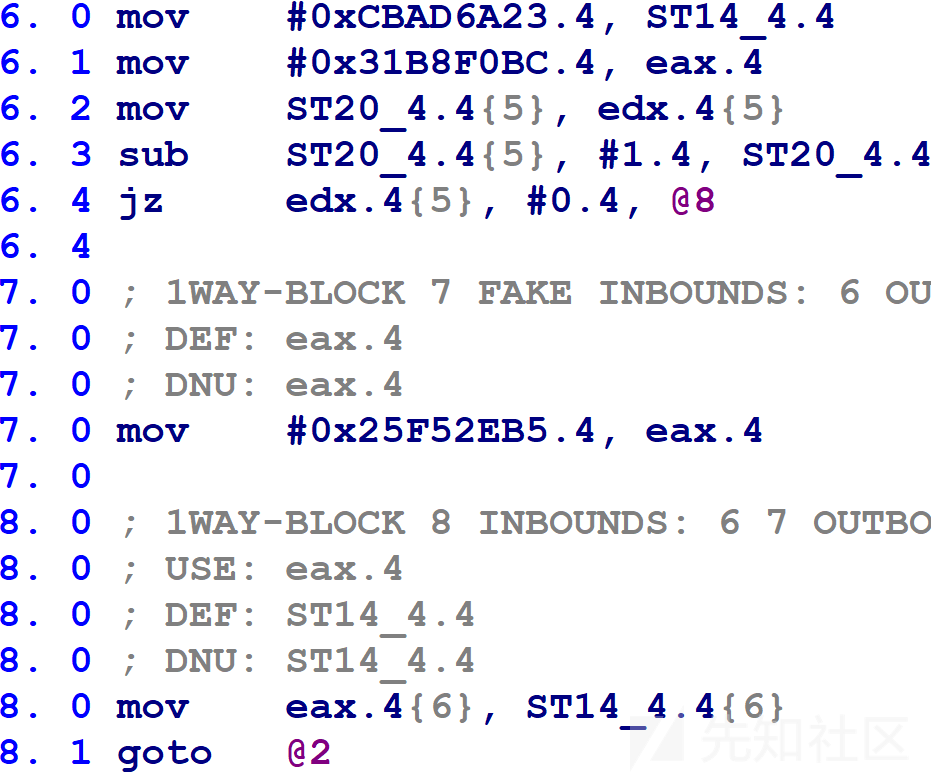
我们的首要任务是确定哪个平坦块编号对应于哪个mblock_t。下图所示是一个函数的控制流switch部分的microcode表示。

HexRays当前正在使用块号变量ST14_4.4。如果等于0xCBAD6A23,则jz指令将控制流转移到@6块。类似的,0x25F52EB5对应于@9块,0x31B8F0BC对应于@10块。
确定每个展平块的后继者
接下来对于每个展平的块,我们需要确定控制流可能转移到的展平的块编号。如果原始控制流是无条件的,则它们可能具有一个后继者;如果其原始控制流是有条件的,则可能具有两个后继者。
@9块中的microcode有一个后继者(第9.3行已被截断,因为它很长并且其细节不重要)。我们可以在9.4行上看到,该块在执行goto返回到控制流switch之前将块号变量更新为0xCBAD6A23,控制流switch会将控制流转移到@6块。

@6块中的microcode有两个后继者。在第8.1行执行goto返回到控制流switch之前,第8.0行用eax的值更新块号变量。如果第6.4行的jz为true,eax值为0x31B8F0BC;如果第6.4行的jz为false,eax值为0x25F52EB5。控制流switch会将控制流转移到@10块或@9块。
直接将控制流从源块转移到目标块
最后我们可以修改microcode中的控制流指令以直接指向其后继,而不是通过控制流switch。如果对所有平坦化的块执行此操作,则控制流switch将不再可用,我们可以将其删除,仅保留函数原始的未平坦化的控制流。
前面我们确定@9块最终将控制流转移到@6块。@9块结尾用goto声明返回到位于@2块的控制流switch。我们只需将现有goto语句的目标修改为指向@6块而不是@2块,如下图所示(同时也删除了对块号变量的分配,因为不再需要)。

有两个后继者的块的情况稍微复杂一些,但是基本思想是相同的:将现有的控制流直接指向目标块而不是控制流switch。
为了解决这个问题,我们将:
1.将@8块的指令复制到@7块的末尾。
2.更改@7块(刚从@8块复制过来)的goto指令,使其指向@9块。
3.更改@8块的goto指令,使其指向@10块。
我们还可以清除8.0行对块号变量的更新以及6.1行和7.0行中对eax的赋值。
下一篇文章将讨论反混淆器的工程实现。
如有侵权请联系:admin#unsafe.sh