xscan是一次自动化漏洞赏金的探索,xscan的设计思想就是希望挂着机,打着游戏,漏洞就能自动上门。为此首先写了一个能自己无限爬行的web爬虫,爬虫能帮我无限深度的获取url,然后还做了一个xss检 2023-4-21 09:27:10 Author: Hacking就是好玩(查看原文) 阅读量:83 收藏
xscan是一次自动化漏洞赏金的探索,xscan的设计思想就是希望挂着机,打着游戏,漏洞就能自动上门。为此首先写了一个能自己无限爬行的web爬虫,爬虫能帮我无限深度的获取url,然后还做了一个xss检测模块(主要是xss比其他漏洞检测起来更多更容易),简单的框架就这么搭建好了。
凭XSS漏洞 刷了腾讯src 3000+分,暂列第一,漏洞赏金大概有15k
XSS扫描器的优化
很多自动化程序是一堆开源工具或扫描器的工作流组合,我基本上会使用开源软件进行改造,不会使用闭源程序,因为掌控代码细节可以进一步优化细节,然后用算法和策略去进一步提升效率。
优化扫描器的过程和机器学习的训练很像,机器学习会将问题转换为一个数学求最优解的过程,赋予不同的系数权重,经过gpu的运算在样本范围内求最优解。
而我就是xscan的gpu,通过爬虫爬取大量数据集,并且学习了大量乌云、hackone的xss报告和手法,用人脑对数据集判断,然后将它们转换为规则。有时候规则紧了漏洞就少,规则松了就有大量误报,有时候规则比较小众,也扫不到。总的来说,这就像是一个加权重的过程。
基于dom相似度的爬虫
获取数据集的一个重要方式就是爬虫,开源爬虫中比较好的有projectdiscovery的katana和 crawlergo。crawlergo基于chromium爬虫,katana分静态爬虫和动态爬虫,但动态爬虫规则不如crawlergo。
因为要进行大范围扫描,考虑效率问题,我先使用的是katana的静态模式,而且后续切换到动态爬虫模式和修改细节也很容易。
在爬虫的时候遇到一个问题,爬虫重复率太高了,有些网站url不一样,但是网站内容基本是模板生成出来的。
之前就有想法写一个基于dom相似度的过滤器来解决这个问题,问了chatgpt大概的实现方式后,真的就实现了。
其实也很简单,将网页转换为dom结构,使用hash算法将每个节点的内容转换为一个数字,乘以节点深度和一个权重,将这个节点求余展开在自己定义的维度内。一个网页就能得出一个类似这样的embeding,eg:[1,2,3,4,5,6 ...]
用cos余弦函数对两个网页的embeding求值即是两个网页的相似度。技术是相同的,最近学习了一点深度学习的知识,没想到转头就能用到爬虫的身上,
扫描策略
xscan使用了html和javascript语义分析技术来检测xss,最早在w13scan中有开源这部分模块。
html语义会把dom结构按照标签解析为Tag,Attribute,Content 这几个属性,Js按照词法分析会把javascript语句解析为StringToken,IdentifyToken等等.
使用语义解析能准确确认回显内容在html/js中的位置,只要再次根据所属位置发送针对性payload,查看这些语义位置是否发生改变,就能知道是否存在xss,全程不会包含敏感payload。
如 https://brutelogic.com.br/xss.php?b1=asdsda
asdsda是我们能控制的内容
它的回显位置用语义分析后,会发现是属于Attribute属性,value为 "asdsda"。
此时在之前payload基础上加一个引号,就能破坏原有结构,
此时asdsda经过语义分析后,属性为 Attribute的name,语义发生了改变,则说明可以XSS了。
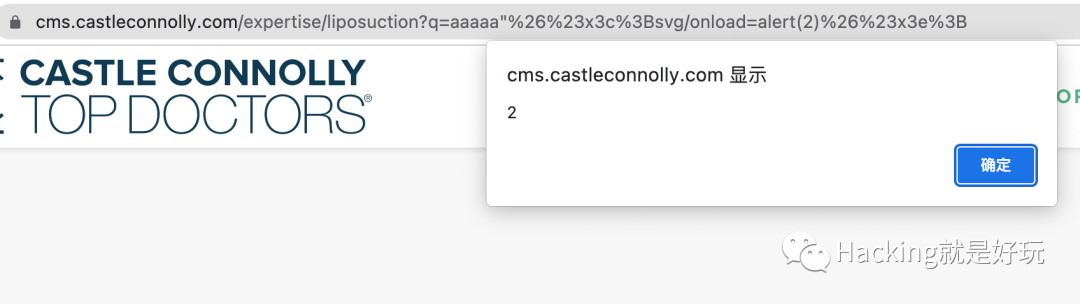
在bugcrowd中就扫到一个例子
如果回显出现在JavaScript中,除了使用构造js造成xss外,还能直接闭合<script>标签造成XSS,如下
还有很多返回头Content-type是html的js部分,callback也能造成xss
扫描位置
用户能接触并自动触发的位置,一般是在GET的query位置和POST的data位置,还有一个位置,就是url部分。对url每层路径也进行一下检测,也能发现很多XSS。
xscan也能扫描cookie,header的参数,但是不好利用,要结合多个漏洞来串联,也发现了很多这种漏洞,但还没有合适的例子串起来。
真实世界有趣的XSS
国外也有个xss扫描器叫knoxss,它的测试用例不错,覆盖了很多场景。https://knoxss.me/?page_id=766
这个靶场有很多姿势学习,xscan也覆盖了这些场景,然后就开动爬虫对一些赏金项目进行了大范围爬虫和扫描,主要是测试扫描规则的命中率,正反馈再优化扫描器。
以下是一些真实世界中有趣的XSS
简单js xss
原内容是
a = 'xxxx'
回显内容可导致js引号逃逸
a= ''-alert()-''
直接造成xss
因为是核心业务范围,获得赏金¥3000
html编码绕过
在一般情况都被过滤的情况下,xscan测得参数可以被html编码,然后构造payload即可,由于可以html编码,waf也是随便绕了。
css 接管
微信的某个地方的登录接口,href参数可以控制css的路径
此时可以做一个远程的css
#js_single_page_container{
display: none;
}
.login_page_standalone:before{
content:"hacked by w14";
}如图,可以将页面文字篡改,并且把登录二维码改为了收款二维码.
漏洞赏金 ¥60
输出在src上
某某云 ,某个参数html编码过滤了内容,但是输出点在 script的src上,可以直接引用外部js。
可以看到还有个小细节,输出的后面会有一堆内容,使用?=就可以无视了
都过滤了就安全了?
多个参数导致的XSS,每个参数都过滤到位了,但是两两组合起来,就会有意想不到的事情。
看以下数据包
authorappEventId,type参数都能在页面中回显,并且引号双引号都会被html编码。但是仔细观察能发现,type参数有反斜杠,能够吃掉引号,而authorappEventId参数可以控制后面的内容,就导致了xss诞生。
最后构造好js结构让js不报错,如下,就能造成xss了,同时还要bypass一下网站的waf(不让弹alert)。
最终弹窗
js编码造成的XSS
出现的原因是returnto参数回显到document.write里了,过滤了引号,但是没有过滤反斜杠,此时可以用js编码,十六进制,八进制,绕过。
编码转换小工具:https://i.hacking8.com/encoding/
用以下
弹窗
双参数绕过变态waf
waf很变态,检测到恶意后有几率封ip。为此还要换代理池去绕。
这个点有两个参数,能回显三个地方。
waf很变态,基本封死了所有可能触发的事件。研究了一阵后,突破点就在那多处回显的情况,我们可以将一个参数设为<img src=1,另一个参数设置为onerror=alert()
waf还会对 alert进行过滤,用console.log测试正常,但是换alert就拦了,但是这块灵活多样,花时间就可以了。最后
缓存中毒导致的存储型XSS
普通访问时发现首页会缓存,并且发现当增加一些参数后,参数会回显到页面上,没有任何的过滤
第一步
请求 https://www.rakuten.com/index.jsp?4jgia=ys828&callback=omico&categoryid=mh2cng1&code=vtb6t&emailto=i007y&id=mymtd&keyword=a9519&keywords=geeva&lang=fx3zt&list_type=adq0s&mod=xqard&monthx=rq2hr"-[1].find(alert)-"
数据包如下
GET /index.jsp?4jgia=ys828&callback=omico&categoryid=mh2cng1&code=vtb6t&emailto=i007y&id=mymtd&keyword=a9519&keywords=geeva&lang=fx3zt&list_type=adq0s&mod=xqard&monthx=rq2hr"-[1].find(alert)-" HTTP/1.1
Accept-Charset: utf-8
Referer: https://us.rakuten.com/
Accept-Encoding: gzip
Pragma: no-cache
Host: www.rakuten.com能看到返回页面已经注入了js
第二步:
去掉payload访问,https://www.rakuten.com/index.jsp?4jgia=ys828&callback=omico&categoryid=mh2cng1&code=vtb6t&emailto=i007y&id=mymtd&keyword=a9519&keywords=geeva&lang=fx3zt&list_type=adq0s&mod=xqard
请求包如下
GET /index.jsp?4jgia=ys828&callback=omico&categoryid=mh2cng1&code=vtb6t&emailto=i007y&id=mymtd&keyword=a9519&keywords=geeva&lang=fx3zt&list_type=adq0s&mod=xqard HTTP/1.1
Accept-Charset: utf-8
Referer: https://us.rakuten.com/
Accept-Encoding: gzip
Pragma: no-cache
Host: www.rakuten.com依然能看到我们的xss payload
网页访问后
绕csp
群友给的一个目标,有csp,把csp贴到 https://csp-evaluator.withgoogle.com/
script过滤的挺严的,标签要有nonce+随机数标记才能执行JavaScript。
但是百密一疏,疏忽了对base的过滤
所以插入一个base标签,设置全局js的加载路径
<base href="">
弹窗~
总结
结论分为 3 个部分:做对了什么,做错了什么,学到了什么。
做对的地方
使用Golang作为开发语言,go很适合写扫描器,并且直接编译为各个平台的二进制,直接可以运行,在不断更新的扫描器中,只用重新上传即可,相比以前使用python的扫描器,环境的依赖,代码的质量,到后面基本不可维护,一跑起来就报错,又得费劲调试。
开发自己的核心引擎
从一开始就决定做自己的扫描器,其他引擎不完全符合自己需求,难以实现一些的创新想法,自己编写核心引擎具有很多优点:
可以更好地适应自己的需求
具有更高的速度和可靠性
可以加入自己的创新想法
并不一味追求可控的代码,
用算法提升扫描器效率
dom相似度算法的爬虫,爬虫深度优先算法,小小的算法能解决大大的问题,爬虫的提升提高了很多效率减少了很多误报
可配置选项
内测版抽离了配置,可以在yaml文件上配置各种参数适配不同的机器。
学习并验证“经验”
twitter上的trick,knoxss的靶场,一些bugbounty的文章和pdf,最终都经过爬虫+扫描模块的验证,当效果比较好时才会正式纳入它们成为xscan的扫描模块。有时候有一些新点子,嗯,有没有网站会有这种情况呢?就拉一批网站来试验。总体来说很多想法在试验中都不尽如人意。也有一些效果特别好的,暂且不表,大家自己实验,哈哈。
开放并交流经验
在星球开放了自己的工具,收到了很多反馈,和很多bughunter碰撞,优化xscan的策略和适配情况。
xscan不会直接发送敏感的payload,而是通过语义的方式发现这里存在问题并报告,由使用者自行判断问题
做错了什么
在xss同时顺手加了clrf和ssti扫描,但基本上没有扫到什么,触发打开爬虫限制,让它漫无目的爬虫,会出现一些ssti漏洞,增加了请求数量但没有什么实际效果,后面就基本关闭它们了。
没有写测试用例,到后面一处代码改动,这个情况能跑成功,之前的情况跑不成功了。
应该针对每个场景的情况都应该写一个测试用例,当修改代码后,一键跑一下测试用例,就能知道代码运行情况和质量了。索性后面慢慢补上了
熬了很多个夜晚写代码,排查bug,排查误报问题。
白天上班,让扫描器跑着,晚上回来根据生成的文档改bug,半个月都在熬夜,业余所有时间都在它上面,有时候会在想值不值得,还好腾讯的奖励够大,可以让我坚持。但是对身体的伤害是不可逆的了。
一个人想完成所有事情
学到了什么
在国内SRC中,xss评级一般都是低微,只有腾讯和阿里对xss的评级是中危,特别的一些核心业务,腾讯对XSS的评分更高,这也是我一直拿腾讯SRC作为练手的原因。针对核心业务,因为范围小,也对xscan做了特别优化,如基于burp的数据包扫描,有时候只会帮我查看哪些参数回显以及过滤情况,不会直接使用策略,可以节省时间。
对于国外的赏金,我只扫了hackerone和bugbounty,它们把XSS定级一般在P3,赏金在200~1200美刀之间,折算成人民币诱惑也很大了。但也不是那么好扫,全世界都盯着这些目标,它们也有自己的自动化扫描程序,简单的xss重复率相当高,主要它们修复周期慢,一个xss几个月不修,交上去全部重复。剩下的就是waf超级变态和一些需要奇淫巧计的了。国外网站的安全做的很好,CSP规则制定的很严,一定程度上预防了这类XSS。不过只针对赏金项目了,没有赏金或赏金低的项目国内国外xss都很多。
XSS的危害没有RCE来的刺激,对于漏洞赏金来说,提交十来份XSS报告的赏金可能还不如一个RCE来的多和有成就感,作为bughunter应该多研究这种类型的漏洞。但是对于刚接触新手来说,xss是很容易获得第一份漏洞赏金的漏洞,xscan则可以帮助你完成。
xscan只是我自动化赏金的其中一环,扫描策略方面已经跑通了,下一步就是扩大范围的扫描,想做的是收集hackerone,bugbounty上赏金项目的资产,持续监控,扫描,毕竟国外的赏金报酬诱人,捡漏还是能一些的。这就是w15scan要做的(还在做)
知识星球
以上的案例xscan已经能全部覆盖了,我的知识星球也会不断更新xscan,w15scan也会在做好后发到星球测试。
我的知识星球主要针对 安全开发方向,分享的都是原创内容,包括思路,包括代码。相关内容可见:https://github.com/boy-hack/zsxq
xss扫描器也是星球的第四期作业,如果你也对安全开发感兴趣可以加入我们。
有一次去武汉昙华林,我看到几个字:"你若慕名而来,定会失望而归"。印象深刻。我不希望读者看了本文就盲目加星球,我设置了星球不可新用户加入,五天后恢复,五天后在公众号回复“知识星球”就可加入了。
不过可以转发文章到朋友圈,抽3个知识星球免费名额(中奖截止后转发则中奖无效)
如有侵权请联系:admin#unsafe.sh