前言本文根据英文原文 LOGICMEM: Automatic Profile Generation for Binary-Only Memory Forensics via Logic Inferen 2023-4-10 18:16:40 Author: 网安国际(查看原文) 阅读量:37 收藏
前言
本文根据英文原文 LOGICMEM: Automatic Profile Generation for Binary-Only Memory Forensics via Logic Inference整理撰写,原文发表在Network an Distributed system Security symposium,2022。作者在完成原文工作时,为加州大学河滨分校在读博士生。
内存分析与取证是计算机取证科学的重要分支。通过对内存数据的分析,可以重构出原系统中运行程序状态,进程信息,网络连接,系统状态等等敏感数字证据。此类信息传统取证方法难以获取,只有通过分析物理内存镜像与页面交换文件的二进制数据才能获得。
内存分析与取证工具利用内核符号(函数地址,数据结构地址)和内核数据结构的内部结构(layout)实现从内存快照中直接读取信息进行取证。在内存分析与取证中, 内核符号和数据结构的layout又被称为内核profile。通常来讲,内核profile可以通过编译可加载内核模块时产生的调试符号表获得。然而,此种方法生成的profile虽然准确,但其可行性取决于是否有内核源码,内核编译环境, 以及当前内核编译配置 (configuration)。然而,在实际内存分析与取证过程中,往往只提供内存快照(memory dump/snapshot)。例如,在犯罪现场调查中,为确保证据完整性,调查者会对电子设备进行内存快照并基于快照展开分析。又比如,对于IoT设备,或者服务器生产环境,由于权限,编译工具不存在, 内核头文件是否存在等原因,通过编译内核模块的方法来生成profile往往是不可行的。因此,不依赖源码编译(binary-only)的profile生成方法尤为重要。
生成内核profile最主要的步骤是生成内核数据结构的内部layout, 即结构体成员的偏移位置(offset)。现有的方法基本上都通过分析内核函数的二进制代码来获得偏移位置(offset)。在内核函数访问结构体成员时,会通过结构体基址加偏移的指令来访问,此时偏移位置可在函数的二进制码中获得。现有方法通过静态分析内核函数二进制指令或者动态模拟执行内核函数来获得结构体成员的偏移位置。然而,实验结果表明,此类方法难以实现很高的准确率和召回率。
01
介绍
内存取证的进展表明在许多重要领域的实际应用,例如犯罪调查、rootkit 和恶意软件检测等。
内存取证能够揭示大量内存驻留信息,例如加密密钥,网络流量、正在运行的进程和内存中的恶意软件,并分析来自各种设备的易失性存储器,包括台式机、智能手机、嵌入式设备等。
为了揭示捕获的证据和文物物理内存,全面理解内核符号和内核数据结构是必需的,在内存取证领域,称为内核配置文件。对于针对内存的取证,目标系统的配置文件必须在分析之前生成。
对于 Windows操作系统,生成配置文件的挑战性较小,因为内核对象的布局可以从微软获取符号服务器,其中包含预构建的内核调试符号。此外,Windows 内核的版本有限,这样用户就可以重复使用来自符号服务器的配置文件,而无需需要知道产品名称、版本或内部版本号。然而,对于像 Linux 这样的基于 Unix 的操作系统,内核版本经常升级,内核是高度可配置的。发行商和个人用户可以通过启用或禁用各种内核配置来定制自己的内核。图 1 显示了 task_struct 中的一些配置 (#ifdef)。尽管取证所需字段通常不受配置控制,它们的偏移量会受配置影响,因为启用或禁用配置会导致添加或删除字段并将取证所需的字段推送到不同的偏移量。尽管官方发行版可能会提供内核符号以及新版本发布时的调试信息,但这不适用于用户定制的 Linux 内核、Android 系统和嵌入式设备,在这种情况下供应商不会发布调试符号, 并且内核数据结构的布局由于特定偏好(例如 tmpfs)而极其多样化支持、控制组和安全选项(例如 SELinux、AppArmor)。总之,预建是不可能的适用于所有 Linux 内核的配置文件。
研究人员已经提出了解决Linux配置文件生成问题的解决方案。内存取证和虚拟机内省工具(如Volatility 、LibVMI 和DECAF)采用的最流行的方法是从内核调试符号中提取配置文件。然而,这种方法并不是为仅限于二进制的内存取证而设计的。首先,它需要访问实时系统,并需要安装内核头文件和工具链。其次,必须构建或插入一个测试内核模块来收集调试符号,这通常在生产环境中是不可行的。此外,需要人为干预来随着内核升级更新测试内核模块,这对开发人员和用户来说都很不方便。
另一种方法尝试通过分析内核函数的汇编代码,重建内核对象,以进行仅限于二进制的内存取证。当访问对象成员时,将执行内存解引用指令,并在该指令中透露该对象成员的偏移量。然而,这种方法很难被推广,因为内核函数可以通过不同架构上的不同编译器编译成各种指令格式。此外,从大量内核代码中精确定位这些透露偏移量的内存解引用指令是很困难的。
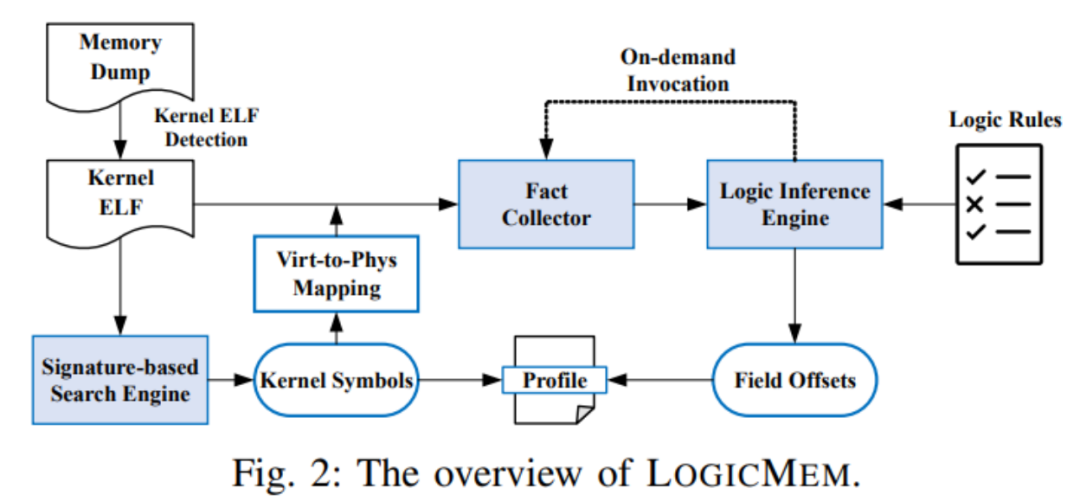
在本文中,我们提出了一种逻辑规则推理的方法,在不知道内核版本和配置时准确地定位内核中取证所需字段偏移量。我们观察到内存取证只需要少数内核对象(取证所需的字段)并且这些字段在不同内核版本中始终存在并且保持不变。为了支持这一观察,我们对 47 个主要 Linux 版本进行了内核演化分析。请注意,取证所需字段的偏移量可能会因到不同的内核配置和版本。我们的方法考虑了这种不确定性,允许推理引擎有效地定位它们内核对象中的偏移量。
我们已经实现了一个原型LOGICMEM,以证明我们提出的方法的有效性。我们在来自主流Linux发行版(例如CentOS、Debian和Ubuntu)的16个内存转储、具有随机配置的自定义Linux内核的30个内存转储、最近的6个长期支持(LTS)或稳定版本的Android内核以及设计用于嵌入式设备的2个内核映像上评估了LOGICMEM。评估结果显示,对于主流Linux内核,LOGICMEM可以推断出完美准确的取证所需字段,并对具有随机配置的自定义Linux内核具有100%的精确度和95%的召回率。在对逻辑规则进行微调后,假阴性可以进一步消除。在案例研究中,我们展示了,尽管由于缺乏内核符号,现有的内存取证工具无法分析Android和嵌入式系统,但LOGICMEM仍然可以支持八个Volatility插件。此外,我们还展示了,LOGICMEM可以启用Volatility中的rootkit检测插件来分析一个受rootkit感染的内存转储。
我们将我们的贡献总结如下:
■ 我们提出了一种逻辑推理方法来定位内核数据结构中取证所需字段的偏移量,无需了解内核版本和配置。
■ 我们设计和实现了LOGICMEM来展示我们提出的方法的有效性,并在来自主流Linux发行版的16个内存转储和30个使用随机配置构建的内核上进行了评估。评估结果表明,LOGICMEM可以以合理的效率实现100%的精确度和至少95%的召回率。
■ 我们展示了LOGICMEM支持从Android系统和嵌入式设备中收集的内存转储的一些内存取证任务的能力,这对于现有的方法如Volatility来说是困难的(如果不是不可能的)。
02
背景和动机
1. 一个运行的例子
配置文件包含内核符号的地址和内核结构总体布局,它们指导内存取证工具找到感兴趣的内核对象并从所需字段中检索值。图 1 展示了使用配置文件从 task_struct 检索流程信息的示例。首先,内存取证工具从 init_task 符号中获取第一个进程的虚拟地址。然后将其翻译成对应的物理地址,并在内存转储中定位 task_struct 对象。接下来,从配置文件中获取 task_struct 中所需字段的偏移量(在图 1 中突出显示)。如图 1 所示,最大的挑战是 Linux 内核配置文件是特定于配置和版本的:Linux 项目经常升级并包含各种编译配置,为特定版本和配置生成的配置文件不太可能被另一个内核重用。现有方法从用于构建此内核的内核头文件和配置构建配置文件。但是,它需要访问实时系统并安装内核头文件和编译器工具链,这对于犯罪现场调查、云服务和生产环境等纯二进制取证是不可能的。其他方法提出了仅二进制方法来解决这个问题,但根据他们的论文,未能实现高精度和召回率。在本文中,我们提出了一种具有高通用性和准确性且效率合理的逻辑推理方法。
2. 现有技术
(1)基于编译器的方法
基于编译器的配置文件生成是内存取证和虚拟机自省工具最常用的方法。它通过从实时系统中的 System.map 文件中收集内核符号并编译内核模块以产生调试信息来生成配置文件。因此,它能够以 100% 的准确度生成配置文件。但是,这种方法本质上对于仅二进制取证是不切实际的。
首先,它需要访问实时系统以收集 System.map 文件并编译测试内核模块。此外,它需要在目标系统中安装编译器工具链和内核头文件,这对于服务器、物联网设备和智能手机来说几乎是不可能的。
(2)基于二进制代码的方法
基于二进制代码的方法直接从内存中生成配置文件。当访问对象成员时,会执行基于偏移的内存引用,并且此偏移可从汇编指令中观察到,汇编指令被定义为偏移显示指令 (ORI) 。因此,基于二进制代码的方法利用二进制的 ORI 来推断对象成员的偏移量。RAMPARSER基于 ORI 重构内核对象。RAMPARSER 首先识别访问取证必需字段的多个内核函数。然后它从 System.map 文件中获取已识别函数的地址,并从内存转储中反汇编内核函数。为了定位访问取证所需字段的 ORI,它会比较访问同一字段的多个函数的ORI,并执行交集以发现使用相同的偏移量的 ORI。最终,取证所需字段的偏移量从识别的 ORI 中提取并用于内存取证分析。ORIGEN是另一个以类似方式恢复对象字段偏移量的工作。ORIGEN 可以为跨版本的内存取证生成配置文件。更具体地说,它首先从配置文件可用的一个软件版本中识别 ORI。然后它执行基于控制流图 (CFG) 的代码搜索,以在同一软件的未见过版本中找到等效的 ORI。然后,它从定位的 ORI 中检索对象字段的偏移量并生成新的配置文件。Pagani提出的另一项工作通过监控运行时内存访问模式来识别 ORI。类似地,它首先找到对内核对象中取证所需字段进行操作的内核函数,并从内存转储中提取它们。然后它使用 Unicorn 模拟器重新执行内核函数。在执行过程中,它会监控内存访问以观察取证所需字段的偏移量。然而,这项工作的一个主要缺点是执行开销很大:为一个内存转储生成配置文件需要数小时。
这几种基于装配的方法面临几个基本挑战。首先,相同的源代码级语句可以通过不同的编译器和编译器选项编译成各种格式的指令。因此,要支持不同编译器在不同架构上构建的内核,就需要穷尽指令格式的所有可能性。其次,很难从内核函数代码中精确定位 ORI,尤其是对于内存访问指令较多的大型函数。
(3)设计目标
我们希望以高精度和合理的效率支持纯二进制内存取证。更具体地说,我们的设计目标如下:
■ 仅二进制方法。我们假设取证分析的唯一输入是内存转储。一个好的解决方案应该直接从给定的内存转储生成配置文件并支持现有的内存取证任务。
■ 高通用性。所提出的技术对于不同的内核版本、配置、CPU 架构和编译器应该足够通用。
■ 高精度。显然,生成的配置文件应该是准确的,以确保正确的分析结果。
■ 合理的效率。提出的技术应在合理的时间范围内生成配置文件,并且可以处理大量内存文件。
(本文只选取原文中部分章节,更多精彩内容敬请期待后续出版的《网络安全研究进展》)
作者简介
亓震霄 加州大学河滨分校 (UC Riverside) 计算机学院博士生。其研究专注于利用程序分析,虚拟化,逻辑推理等技术解决计算机安全相关问题,包括漏洞挖掘,内核安全分析等等,并多次将研究成果发表在NDSS,RAID等国际安全顶级会议。
主页:https://enlighten5.github.io/
相关阅读
如有侵权请联系:admin#unsafe.sh