Mips是个啥?MIPS:无互锁流水级的微处理器(Microprocessor without Interlocked Piped Stages)MIPS架构(英 2023-4-10 11:32:0 Author: xz.aliyun.com(查看原文) 阅读量:23 收藏
Mips是个啥?
MIPS:无互锁流水级的微处理器(Microprocessor without Interlocked Piped Stages)
MIPS架构(英语:MIPS architecture,为Microprocessor without Interlocked Pipeline Stages的缩写,亦为Millions of Instructions Per Second的头字语),是一种采取精简指令集(RISC)的处理器架构,1981年出现,由MIPS科技公司开发并授权,广泛被使用在许多电子产品、网络设备、个人娱乐设备与商业设备上。最早的MIPS架构是32位,最新的版本已经变成64位。
机器周期
大多数计算机处理器都会不断地重复三个基本步骤。每个机器周期内会执行一条机器指令。一个现代的计算机处理器每秒钟运行数百万次机器周期。
一条机器指令是由一串对应着处理器基本操作的二进制码组成的,在不同的处理器架构中,机器周期的组成也不相同,但他们的基本行为都包含下面三个主要步骤:
- 从内存中读取指令:指令存放在内存中,PC (Program Counter) 存放了指令在内存中的地址
- PC=PC+4:让PC指向下一条指令所在的地址
- 执行所得到的指令

汇编语言
机器指令是由0,1的二进制码构成的因而人类无法阅读。相对应地,汇编语言允许我们使用相应的代码来编写指令。下面是对应的机器码和汇编语言:
machine instruction
0000 0001 0010 1011 1000 0000 0010 0000
assembly language statement
add $t0,$t1,$t2这条指令的意思是:寄存器$t0,$t1,$t2间
$t0 = $t1 + $t2
寄存器种类
- MIPS下一共有32个通用寄存器
- 在汇编中,寄存器标志由$符开头
寄存器表示可以有两种方式
- 直接使用该寄存器对应的编号,例如:从$0到$31
- 使用对应的寄存器名称,例如:
$t1,$sp
对于乘法和除法分别有对应的两个寄存器
$lo,$hi- 对于以上二者,不存在直接寻址;必须要通过
mfhi(“move from hi”)以及mflo(“move from lo”)分别来进行访问对应的内容 - 乘法:
HI存储32位高位,LO存储32位低位 - 除法:
LO存储结果,HI存储余数
- 对于以上二者,不存在直接寻址;必须要通过
- 栈的走向是从高地址到低地址

$0
即$zero,该寄存器总是返回零,为0这个有用常数提供了一个简洁的编码形式。
move $t0,$t1
#实际为
add $t0,$0,$t1$1
即$at,该寄存器为汇编保留,由于I型指令的立即数字段只有16位,在加载大常数时,编译器或汇编程序需要把大常数拆开,然后重新组合到寄存器里。比如加载一个32位立即数需要 lui(装入高位立即数)和addi两条指令。像MIPS程序拆散和重装大常数由汇编程序来完成,汇编程序必需一个临时寄存器来重组大常数,这也是为汇编保留$at的原因之一。
$2..$3
即$v0-$v1,用于子程序的非浮点结果或返回值,对于子程序如何传递参数及如何返回,MIPS范围有一套约定,堆栈中少数几个位置处的内容装入CPU寄存器,其相应内存位置保留未做定义,当这两个寄存器不够存放返回值时,编译器通过内存来完成。简单来说:一般用于存储表达式或者函数的返回值(value的简写)
$4..$7
即$a0-$a3,用来传递前四个参数给子程序,不够的用堆栈。a0-a3和v0-v1以及ra一起来支持子程序/过程调用,分别用以传递参数,返回结果和存放返回地址。当需要使用更多的寄存器时,就需要堆栈(stack)了,MIPS编译器总是为参数在堆栈中留有空间以防有参数需要存储。参数寄存器(Argument简写)
$8..$15
即$t0-$t7临时寄存器,子程序可以使用它们而不用保留。一般用于存储临时变量(temp简写)
$16..$23
即$s0-$s7,保存寄存器,在过程调用过程中需要保留(被调用者保存和恢复,还包括$fp和$ra),MIPS提供了临时寄存器和保存寄存器,这样就减少了寄存器溢出(spilling,即将不常用的变量放到存储器的过程),编译器在编译一个叶(leaf)过程(不调用其它过程的过程)的时候,总是在临时寄存器分配完了才使用需要保存的寄存器。存放子函数调用过程需要被保留的数据(saved values)
$24..$25
即$t8-$t9,同$t0-$t7,一般用于存储临时变量(temp简写)
$26..$27
即$k0-$k1,为操作系统/异常处理保留,至少要预留一个。 异常(或中断)是一种不需要在程序中显示调用的过程。MIPS有个叫异常程序计数器(exception program counter,EPC)的寄存器,属于CP0寄存器,用于保存造成异常的那条指令的地址。查看控制寄存器的唯一方法是把它复制到通用寄存器里,指令mfc0(move from system control)可以将EPC中的地址复制到某个通用寄存器中,通过跳转语句(jr),程序可以返回到造成异常的那条指令处继续执行。MIPS程序员都必须保留两个寄存器$k0和$k1,供操作系统使用。简单来说就是中断函数返回值,不可做其他用途
$28
即$gp,为了简化静态数据的访问,MIPS软件保留了一个寄存器:全局指针gp(global pointer,$gp),全局指针指向静态数据区中的运行时决定的地址,在存取位于gp值上下32KB范围内的数据时,只需要一条以gp为基指针的指令即可。在编译时,数据须在以gp为基指针的64KB范围内。指向64k(2^16)大小的静态数据块的中间地址(字面上好像就是这个意思,块的中间),GlobalPointer简写。
$29
即$sp,MIPS硬件并不直接支持堆栈,你可以把它用于别的目的,但为了使用别人的程序或让别人使用你的程序,还是要遵守这个约定的,但这和硬件没有关系。栈指针,指向栈顶(Stack Pointer简写)
$30
即$fp,GNU MIPS C编译器使用了帧指针(frame pointer),而SGI的C编译器没有使用,而把这个寄存器当作保存寄存器使用($s8),这节省了调用和返回开销,但增加了代码生成的复杂性。
$31
即$ra,存放返回地址,MIPS有个jal(jump-and-link,跳转并 链接)指令,在跳转到某个地址时,把下一条指令的地址放到$ra中。用于支持子程序,例如调用程序把参数放到$a0~$a3,后jal X跳到X过程,被调过程完成后把结果放到$v0,$v1,然后使用jr $ra返回。栈指针,指向栈顶(Stack Pointer简写)
程序结构(Program Structure)
- 本质其实就只是数据声明+普通文本+程序编码(文件后缀为.s,或者.asm也行)
- 数据声明在代码段之后(其实在其之前也没啥问题,也更符合高级程序设计的习惯)
数据声明(Data Declarations)
- 数据段以.data为开始标志
- 声明变量后,即在主存中分配空间。
代码(Code)
- 代码段以.text为开始标志
- 其实就是各项指令操作
- 程序入口为 main: 标志(这个都一样啦)
- 程序结束标志(详见下文)
注释(Comments)
感觉和c是有点像的
# Comment giving name of program and description of function
# 说明下程序的目的和作用(其实和高级语言都差不多了)
# Template.s
#Bare-bones outline of MIPS assembly language program
.data # variable declarations follow this line
# 数据变量声明
# ...
.text # instructions follow this line
# 代码段部分
main: # indicates start of code (first instruction to execute)
# 主程序
# ...
# End of program, leave a blank line afterwards to make SPIM happy
# 结束数据声明(Data Declarations)
name: storage_type value(s)
变量名:(冒号别少了) 数据类型 变量值- 通常给变量赋一个初始值;对于 .space ,需要指明需要多少大小空间(bytes)
举个例子
var1: .word 3 # create a single integer variable with initial value 3
# 声明一个 word 类型的变量 var1, 同时给其赋值为 3
array1: .byte 'a','b' # create a 2-element character array with elements initialized
# to a and b
# 声明一个存储2个字符的数组 array1,并赋值 'a', 'b'
array2: .space 40 # allocate 40 consecutive bytes, with storage uninitialized
# could be used as a 40-element character array, or a
# 10-element integer array; a comment should indicate which!
# 为变量 array2 分配 40字节(bytes)未使用的连续空间,当然,对于这个变量
# 到底要存放什么类型的值, 最好事先声明注释下!加载/保存(读取/写入) 指令集(Load / Store Instructions)
- 如果要访问内存,不好意思,你只能用load或者store指令
- 其他的只能都一律是寄存器操作
load
lw register_destination, RAM_source
#copy word (4 bytes) at source RAM location to destination register.
从内存中 复制 RAM_source 的内容到 对应的寄存器中
(lw中的'w'意为'word',即该数据大小为4个字节lb register_destination, RAM_source
#copy byte at source RAM location to low-order byte of destination register,
# and sign-e.g.tend to higher-order bytes
从内存中 复制 RAM_source 的内容到 对应的寄存器中
同上, lb 意为 load bytestore word
sw register_source, RAM_destination
#store word in source register into RAM destination
#将指定寄存器中的数据 写入 到指定的内存中sb register_source, RAM_destination
#store byte (low-order) in source register into RAM destination
#将源寄存器中的字节(低位)存储到内存中load immediate:
li register_destination, value
#load immediate value into destination register
顾名思义,这里的 li 意为 load immediate,将立即值加载到目标寄存器综上,举个例子
.data
var1: .word 3 # declare storage for var1; initial value is 3
# 先声明一个 word 型的变量 var1 = 3;
.text
__start:
lw $t0, var1 # load contents of RAM location into register $t0: $t0 = var1
# 令寄存器 $t0 = var1 = 3;
li $t1, 5 # $t1 = 5 ("load immediate")
# 令寄存器 $t1 = 5;
sw $t1, var1 # store contents of register $t1 into RAM: var1 = $t1
# 将var1的值修改为$t1中的值: var1 = $t1 = 5;
done立即与间接寻址(Indirect and Based Addressing)
load address:
直接给了地址
la $t0, var1
#copy RAM address of var1 (presumably a label defined in the program) into register $t0
将 var1 的 RAM 地址(大概是程序中定义的标签)复制到寄存器 $t0indirect addressing:
地址是寄存器的内容(可以理解为指针)
lw $t2, ($t0)
#load word at RAM address contained in $t0 into $t2
将 $t0 中包含的 RAM 地址处的字加载到 $t2sw $t2, ($t0)
#store word in register $t2 into RAM at address contained in $t0
将寄存器 $t2 中的字存储到 $t0 中包含的地址的 RAM 中based or indexed addressing:
+偏移量
lw $t2, 4($t0)
#load word at RAM address ($t0+4) into register $t2
#"4" gives offset from address in register $t0
将 RAM 地址 ($t0+4) 的字加载到寄存器 $t2
“4”给出寄存器 $t0 中地址的偏移量sw $t2, -12($t0)
#store word in register $t2 into RAM at address ($t0 - 12)
#negative offsets are fine
将寄存器 $t2 中的字存储到地址为 ($t0 - 12) 的 RAM 中
负偏移也行Note: based addressing is especially useful for:
arrays; access elements as offset from base address
stacks; easy to access elements at offset from stack pointer or frame pointer
不必多说,要用到偏移量的寻址,基本上使用最多的场景无非两种:数组,栈。
综上举个例子
.data
array1: .space 12 # declare 12 bytes of storage to hold array of 3 integers
# 定义一个 12字节 长度的数组 array1, 容纳 3个整型
.text
__start: la $t0, array1 # load base address of array into register $t0
# 让 $t0 = 数组首地址
li $t1, 5 # $t1 = 5 ("load immediate")
sw $t1, ($t0) # first array element set to 5; indirect addressing
# 对于 数组第一个元素赋值 array[0] = $1 = 5
li $t1, 13 # $t1 = 13
sw $t1, 4($t0) # second array element set to 13
# 对于 数组第二个元素赋值 array[1] = $1 = 13
# (该数组中每个元素地址相距长度就是自身数据类型长度,即4字节, 所以对于array+4就是array[1])
li $t1, -7 # $t1 = -7
sw $t1, 8($t0) # third array element set to -7
# 同上, array+8 = (address[array[0])+4)+ 4 = address(array[1]) + 4 = address(array[2])
done算数指令集(Arithmetic Instructions)
- 最多3个操作数
- 操作数只能是寄存器,绝对不允许出现地址
- 所有指令统一是32位 = 4 * 8 bit = 4bytes = 1 word
add $t0,$t1,$t2 # $t0 = $t1 + $t2; add as signed (2's complement) integers
添加为有符号(2 的补码)整数
sub $t2,$t3,$t4 # $t2 = $t3 - $t4
addi $t2,$t3, 5 # $t2 = $t3 + 5; "add immediate" (no sub immediate)
“添加立即数”(没有子立即数)
addu $t1,$t6,$t7 # $t1 = $t6 + $t7; add as unsigned integers
添加为无符号整数
subu $t1,$t6,$t7 # $t1 = $t6 + $t7; subtract as unsigned integers
减去无符号整数
mult $t3,$t4 # multiply 32-bit quantities in $t3 and $t4, and store 64-bit
# result in special registers Lo and Hi: (Hi,Lo) = $t3 * $t4
将$t3和$t4中的32位数量相乘,并存储 64 位
运算结果在特殊寄存器 Lo 和 Hi: (Hi,Lo) = $t3 * $t4
div $t5,$t6 # Lo = $t5 / $t6 (integer quotient)
# Hi = $t5 mod $t6 (remainder)
整数商存放在 lo, 余数存放在 hi
mfhi $t0 # move quantity in special register Hi to $t0: $t0 = Hi
不能直接获取hi或lo中的值,需要mfhi,mflo指令传值给寄存器
这里将特殊寄存器Hi中的数量移动到$t0:$t0=Hi
mflo $t1 # move quantity in special register Lo to $t1: $t1 = Lo
# used to get at result of product or quotient
将特殊寄存器 Lo 中的数量移动到 $t1: $t1 = Lo
用于获取乘积或商的结果
move $t2,$t3 # $t2 = $t3控制流(Control Structures)
Branches
分支(if else系列),条件分支的比较内置于指令中
b target # unconditional branch to program label target
无条件分支到程序标号
beq $t0,$t1,target # branch to target if $t0 = $t1
如果 $t0 = $t1 则分支到目标
blt $t0,$t1,target # branch to target if $t0 < $t1
如果 $t0 < $t1 则分支到目标
ble $t0,$t1,target # branch to target if $t0 <= $t1
如果 $t0 <= $t1 则分支到目标
bgt $t0,$t1,target # branch to target if $t0 > $t1
如果 $t0 > $t1 则分支到目标
bge $t0,$t1,target # branch to target if $t0 >= $t1
如果 $t0 >= $t1 则分支到目标
bne $t0,$t1,target # branch to target if $t0 <> $t1
如果 $t0不等于$t1 则分支到目标Jumps
跳转(while, for, goto系列)
j target # unconditional jump to program label target
看到就跳, 不用考虑任何条件
jr $t3 # jump to address contained in $t3 ("jump register")
类似相对寻址,跳到该寄存器给出的地址处Subroutine Calls
子程序调用
subroutine call: "jump and link" instruction——子程序调用:“跳转链接”指令
jal sub_label # "jump and link"
“跳转链接”- copy program counter (return address) to register $ra (return address register)
- 将当前的程序计数器保存到 $ra 中
- jump to program statement at sub_label
- 跳转到 sub_label 处的程序语句
subroutine return: "jump register" instruction——子程序返回:“跳转寄存器”指令
jr $ra # "jump register"- jump to return address in $ra (stored by jal instruction)
- 通过上面保存在 $ra 中的计数器返回调用前
如果说调用的子程序中有调用了其他子程序,如此往复, 则返回地址的标记就用 栈(stack) 来存储, 毕竟 $ra 只有一个
系统调用 与 输入/输出(主要针对SPIM模拟器)(System Calls and I/O (SPIM Simulator))
- 通过系统调用实现终端的输入输出,以及声明程序结束
- 学会使用 syscall
- 参数所使用的寄存器:$v0, $a0, $a1
- 返回值使用: $v0
系统服务指令Syscall用法
在C语言中输出文本可以使用printf函数,但是汇编中没有printf这么一说,如果想要输出文本,需要借助syscall指令
如果想要输出一个数字1,那么syscall指令从$a0寄存器中取出需要输出的数据
因此, 你在执行syscall指令之前需要将数据提前放入$a0之中:
li $a0,1
syscall同时,还需要指定输出的数据类型,数据类型的指定保存在$v0寄存器中
# $v0=1, syscall--->print_int
# $v0=4, syscall--->print_stringsyscall指令读写对照表
| Service | Code in $v0 |
Arguments 所需参数 |
Results返回值 |
|---|---|---|---|
| print_int 打印一个整型 |
$v0 = 1 |
a0 = integer to be printed 将要打印的整型赋值给a0 |
|
| print_float 打印一个浮点 |
$v0 = 2 |
f12 = float to be printed 将要打印的浮点赋值给f12 |
|
| print_double 打印双精度 |
$v0 = 3 |
f12 = double to be printed 将要打印的双精度赋值给f12 |
|
| print_string 打印字符串 |
$v0 = 4 |
a0 = address of string in memory 将要打印的字符串的地址赋值给a0 |
|
| read_int 读取整形 |
$v0 = 5 |
integer returned in v0 将读取的整型赋值给v0 |
|
| read_float 读取浮点 |
$v0 = 6 |
float returned in v0 将读取的浮点赋值给v0 |
|
| read_double 读取双精度 |
$v0 = 7 |
double returned in v0 将读取的双精度赋值给v0 |
|
| read_string 读取字符串 |
$v0 = 8 |
a0 = memory address of string input buffer 将读取的字符串地址赋值给a0 a1 = length of string buffer (n) 将读取的字符串长度赋值给a1 |
|
| sbrk 应该同C中的sbrk()函数动态分配内存 |
$v0 = 9 |
a0 = amount 需要分配的空间大小(单位目测是字节 bytes) |
address in v0 将分配好的空间首地址给v0 |
| exit 退出 |
$v0 =10 |
- 大概意思是要打印的字符串应该有一个终止符,估计类似C中的'\0', 在这里我们只要声明字符串为 .asciiz 类型即可。

- .ascii 与 .asciiz唯一区别就是 后者会在字符串最后自动加上一个终止符, 仅此而已
- The read_int, read_float and read_double services read an entire line of input up to and including the newline character.
- 对于读取整型, 浮点型,双精度的数据操作, 系统会读取一整行,(也就是说以换行符为标志 '\n')
The read_string service has the same semantices as the UNIX library routine fgets.
read_string 服务与 UNIX 库例程 fgets 具有相同的语义。
It reads up to n-1 characters into a buffer and terminates the string with a null character.
它将最多 n-1 个字符读入缓冲区并以空字符终止字符串。
If fewer than n-1 characters are in the current line, it reads up to and including the newline and terminates the string with a null character.
如果当前行中的字符少于 n-1 个,它会读取并包括换行符并以空字符终止字符串。
举点例子
打印一个存储在寄存器 $2 里的整型
li $v0, 1 # load appropriate system call code into register $v0;
声明需要调用的操作代码为 1 (print_int) 并赋值给 $v0
# code for printing integer is 1
li $t2, 3 #将t2的值写为3
move $a0, $t2 # move integer to be printed into $a0: $a0 = $t2
将要打印的整型赋值给 $a0
syscall # call operating system to perform operation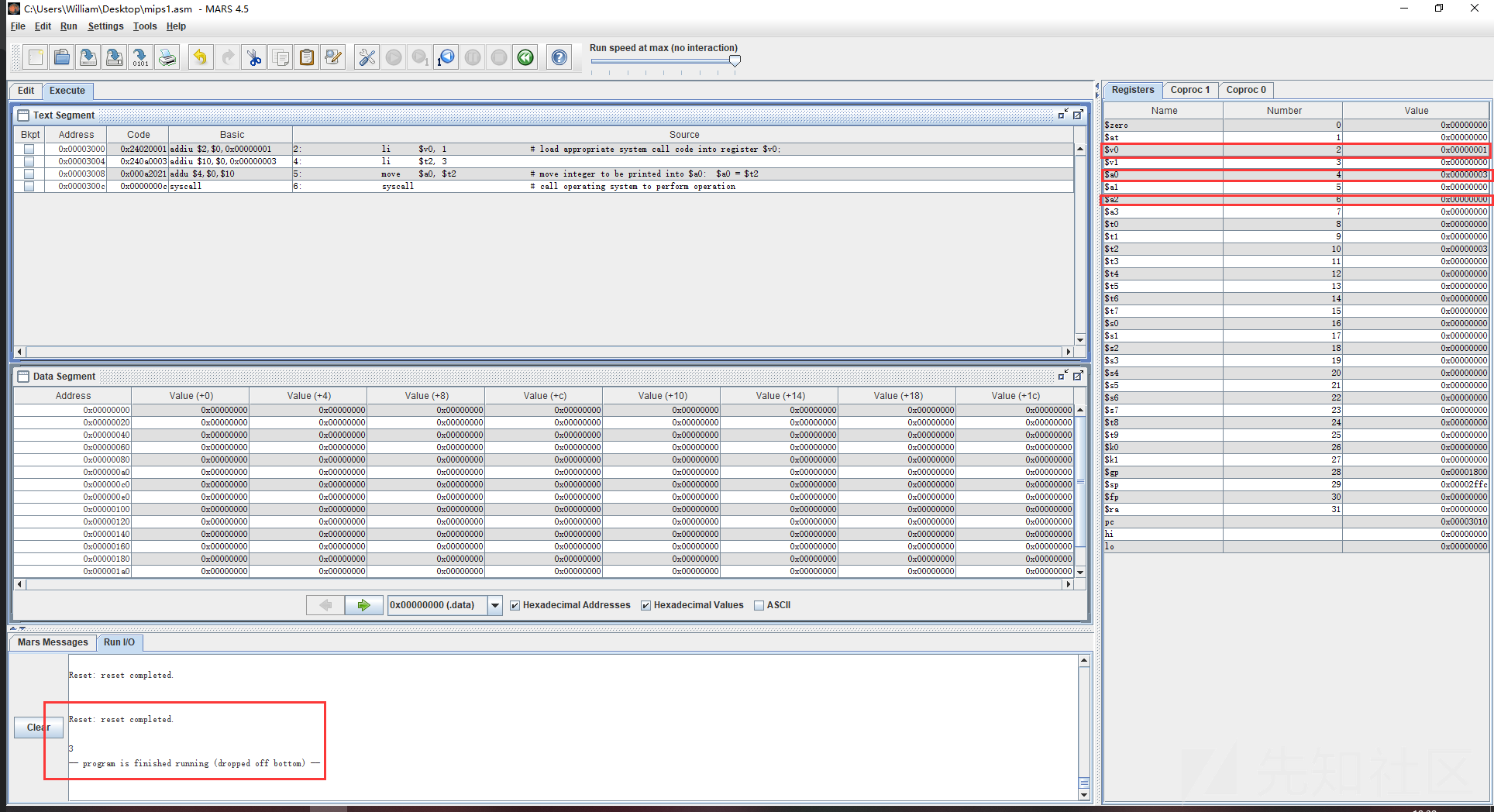
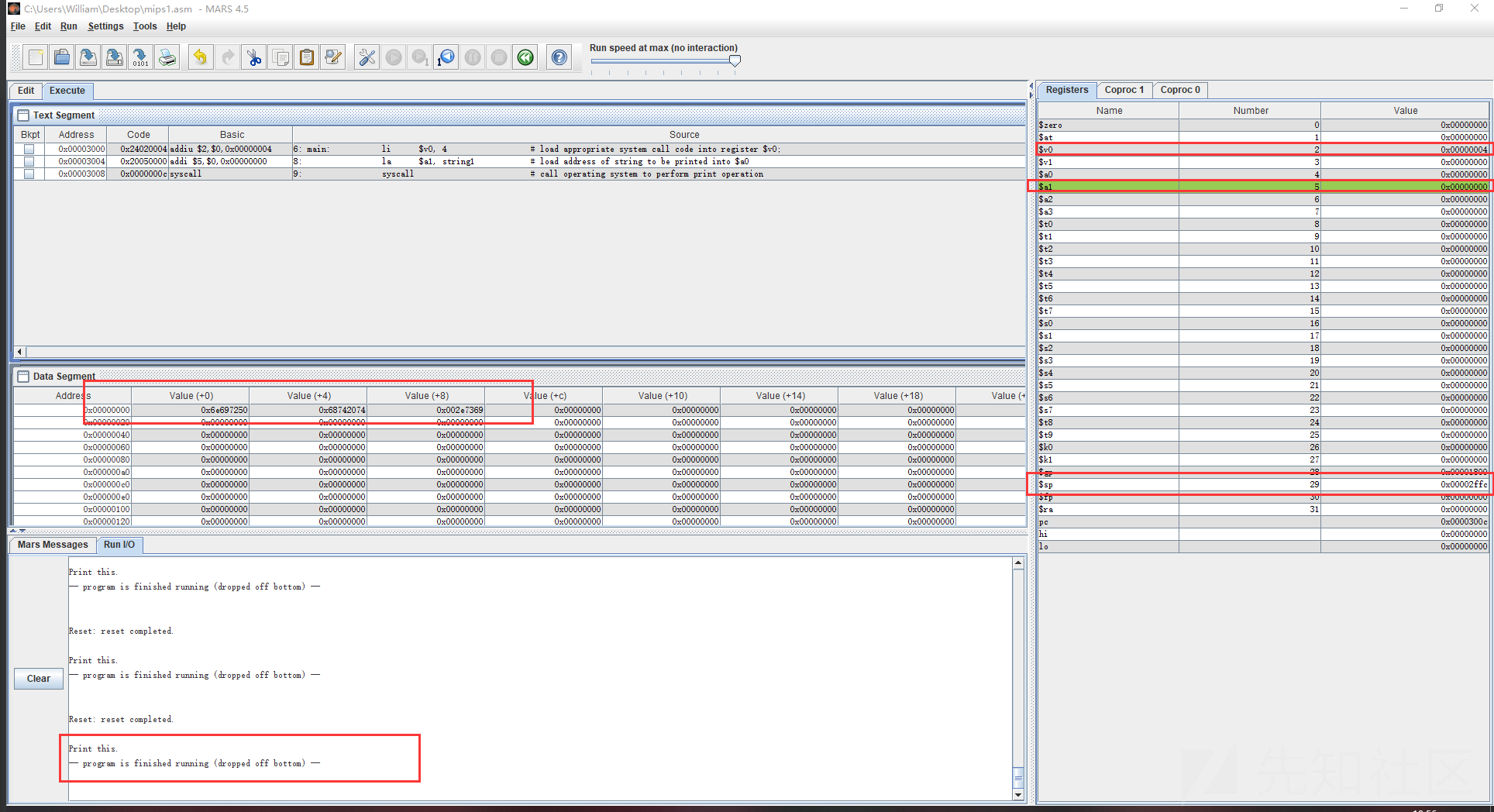
打印一个字符串(这是完整的,其实上面栗子都可以直接替换main: 部分,都能直接运行)
.data
string1: .asciiz "Print this.\n" # declaration for string variable,
# .asciiz directive makes string null terminated
#类似于C语言中 char* msg="hello world"
.text
main: li $v0, 4 # load appropriate system call code into register $v0;
# code for printing string is 4
打印字符串, 赋值对应的操作代码 $v0 = 4
la $a0, string1 # load address of string to be printed into $a0
将要打印的字符串地址赋值 $a0 = address(string1)
syscall # call operating system to perform print operation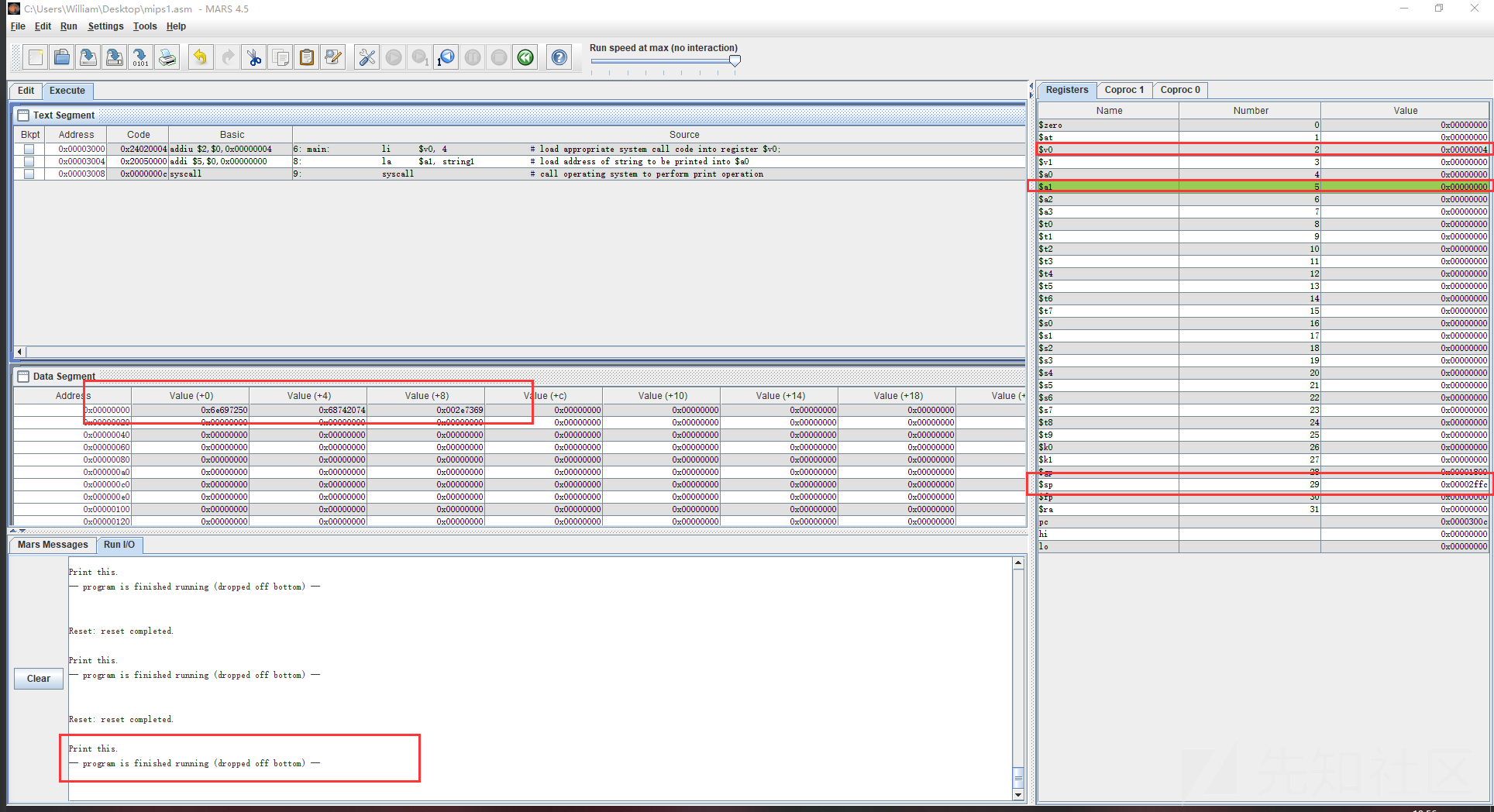
结束例子
li $v0, 10 # system call code for exit = 10
syscall # call operating sys
数据定义
定义整型数据
定义Float数据
定义Double数据
定义字符串数据
用户输入
字符串输入
整型数据输入
浮点型数据输入
单精度和双精度
单精度数(float型)在32位计算机中存储占用4字节,也就是32位,有效位数为7位,小数点后6位。
双精度数(double型)在32位计算机中存储占用8字节,也就是64位,有效位数为16位,小数点后15位。
浮点寄存器
在mips中一共有32个浮点寄存器(其中包含16个双精度浮点寄存器),用于单独处理浮点数
函数声明和调用
函数声明
格式
jr ra #ra寄存器中保存着调用指令下一条代码所在的地址函数调用
格式
jal 函数名举个例子:函数传参和返回值
#需求:定义加法函数 并调用获取返回值int sum(int v,int b)
main:
addi $a1,$zero,50
addi $a2,$zero,100
jal add
li $v0,1
move $a0,$v1
syscall
#结束程序
li $v0,10
syscall
add:
add $v1,$a1,$a2
jr $ra之心前两步之后a1和a2的值进行了改写
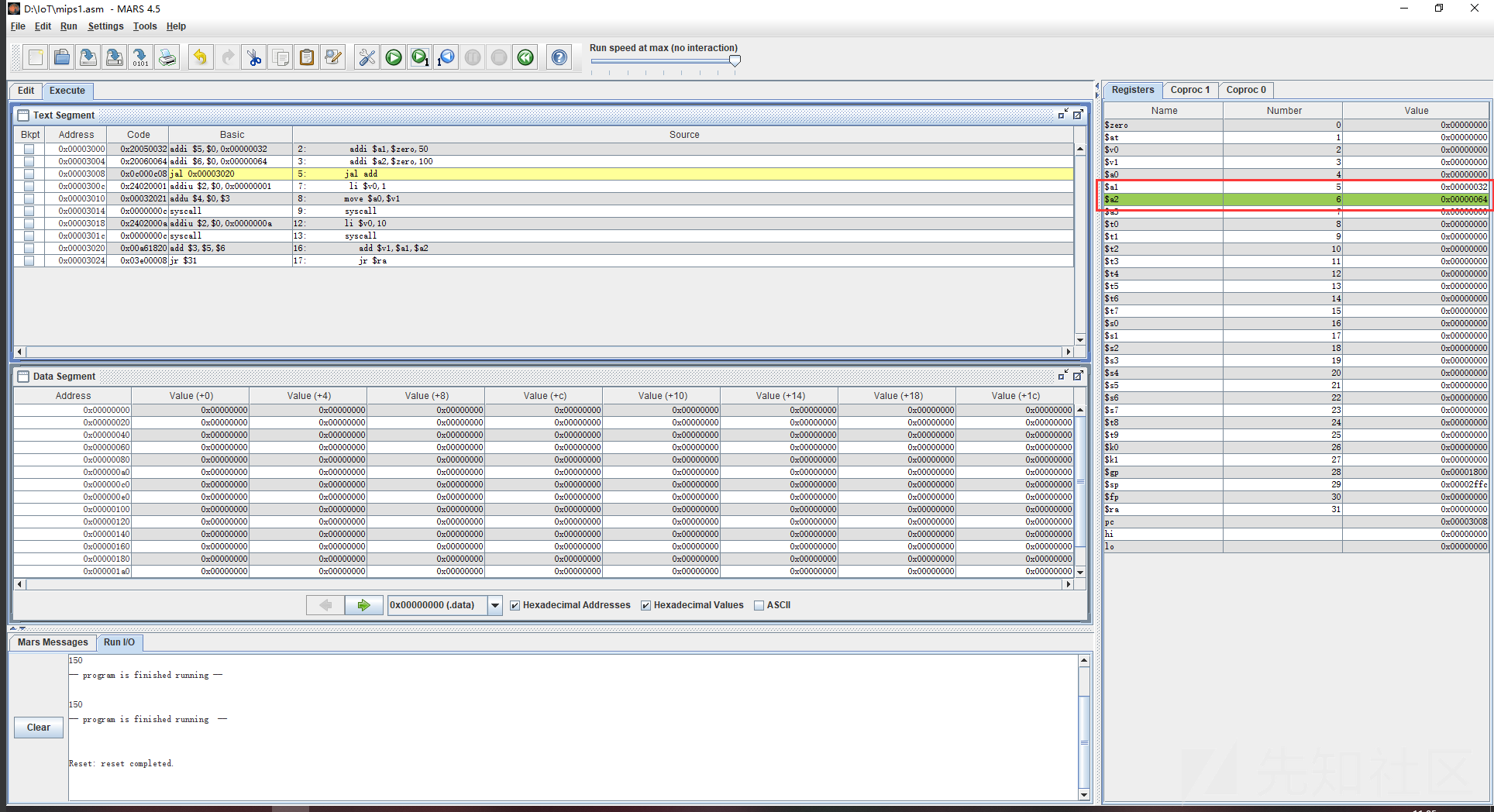
执行完第三步将当前的程序计数器保存到 $ra 中,也就是这里的0x000300c,而后我们直接跳转到了add函数
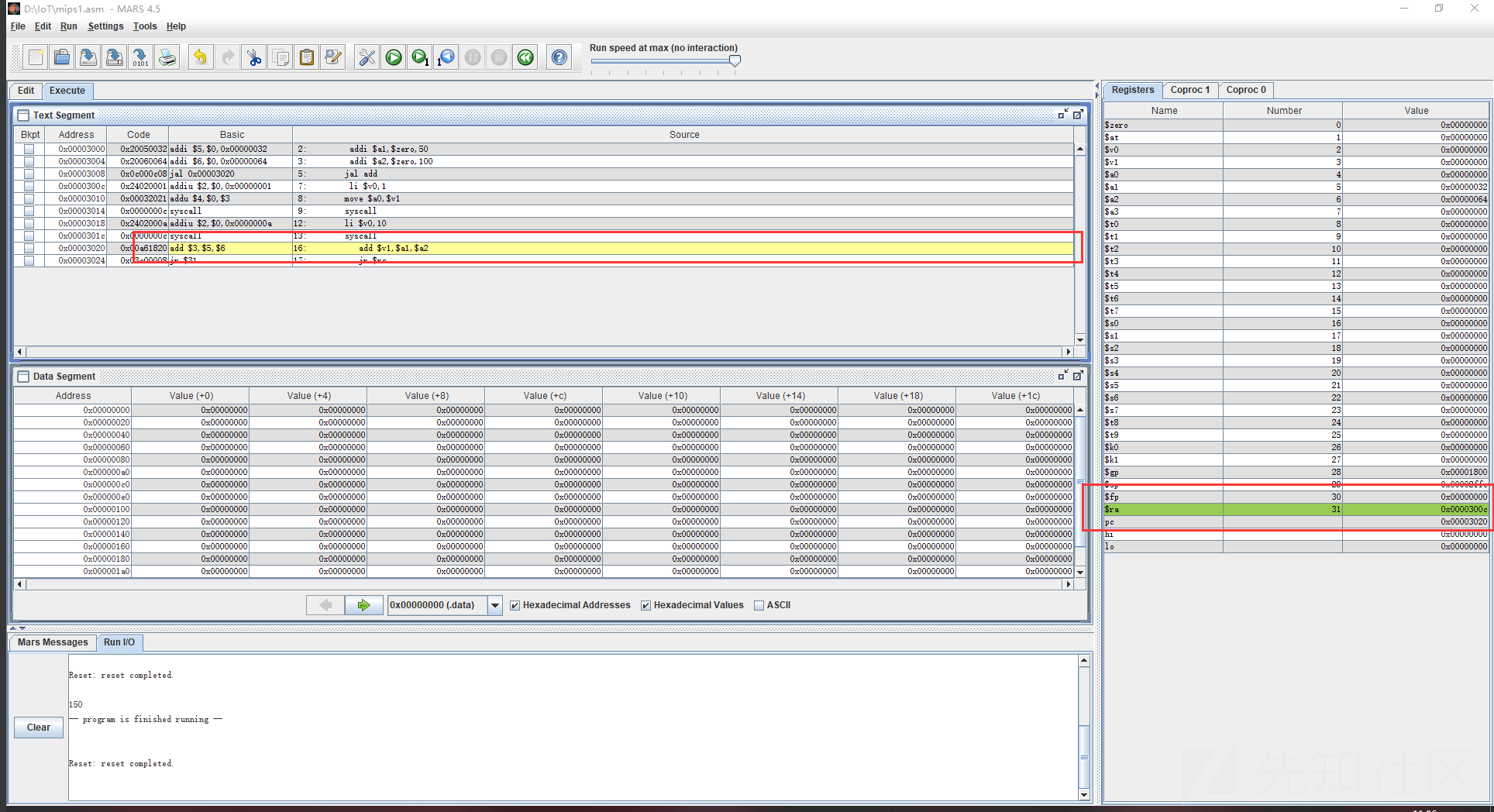
将函数值写入了v1,我们继续看下一步返回的ra,jr是跳转寄存器,通过上面保存在 $ra 中的计数器返回调用前,单步执行看一下

果然,我们跳转到了调用之前,给v0赋值的位置,也就是说这里的jr主要作用是结束一个函数的调用,

执行两步,看下结果,a0已经被成功的赋值了
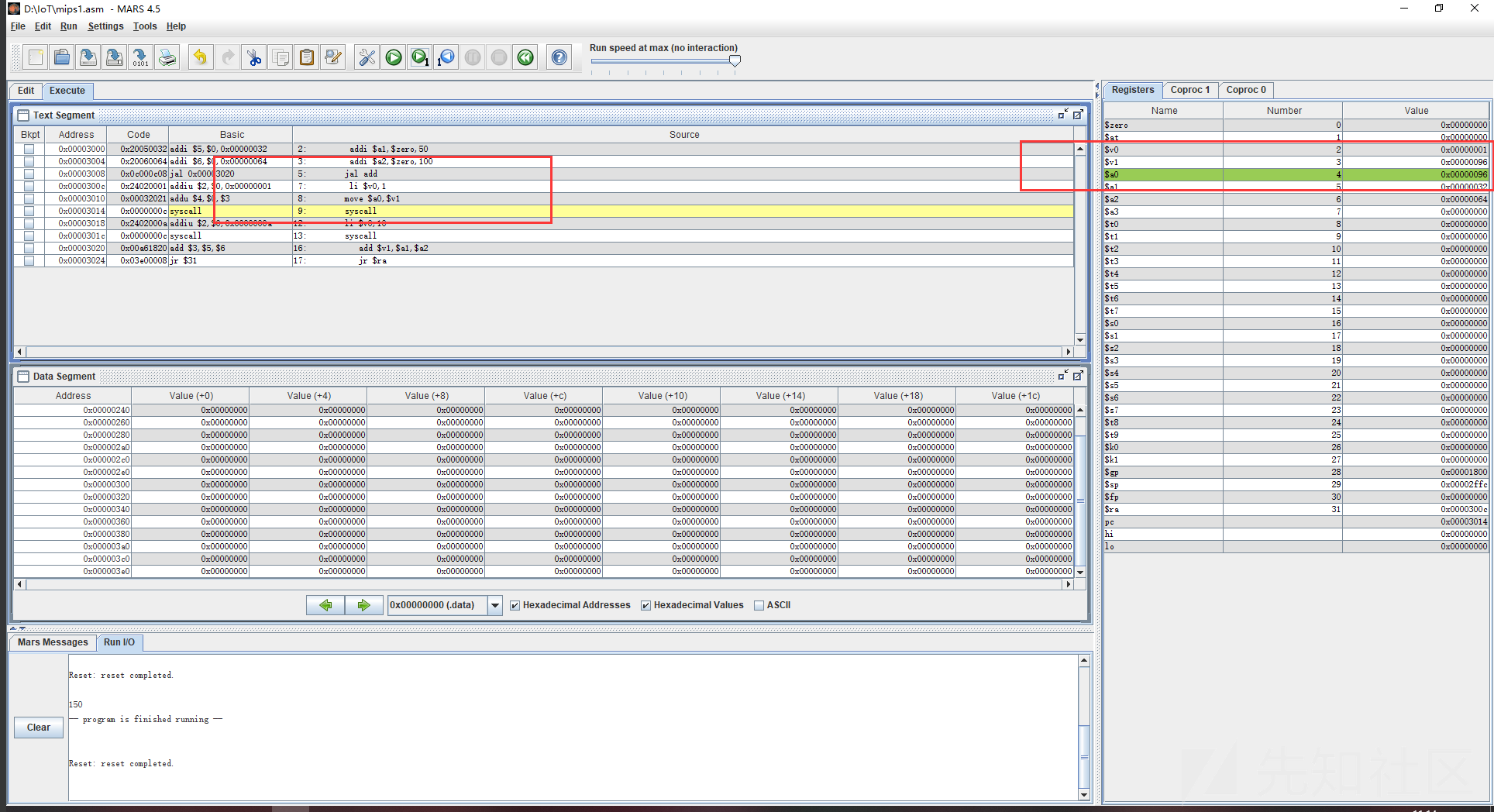
执行到结束,成功输出了内容,同时优雅退出程序

针对栈的操作
主要是栈空间的拉伸和平衡
入栈和出栈
嵌套函数通过栈保护$ra来记录函数的地址,保证函数的调用和返回
内存空间布局
我们在使用Mars的时候其实就已经在进行对内存空间的改写和编辑了,就比如说这里
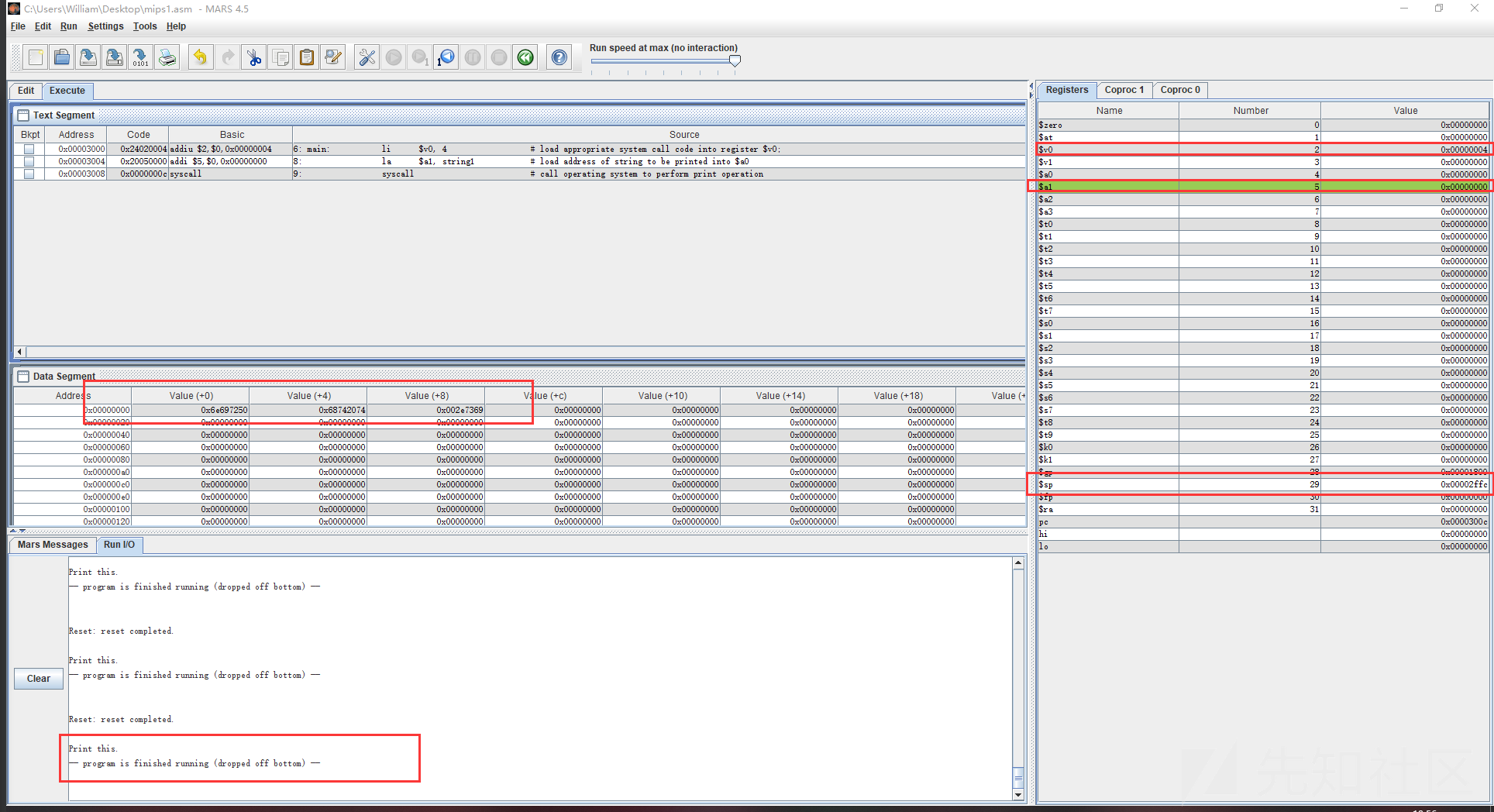
其中栈的结构用途来表示就是这样的


栈的伸缩在mips和x86架构中都是从高地址往低地址进行伸缩,在arm架构中可以升序也可以降序
内存碎片
在内存动态分配(heap区)过程中容易出现一些小且不连续的空闲内存区域,这些未被使用的内存称作内存碎片
我们可以将其分成内部碎片和外部碎片
内部碎片
比如数据在内存中采用4个字节对齐的方式进行存储, 比如我们申请一块3个字节的空间用于存储一个数据,但是系统给我们分配了4个字节空间,这时多出来的一个字节的空间就被称之为内部碎片
外部碎片
在我们进行内存回收和分配的时候容易出现外部碎片,比如我连续申请了三块4个字节的内存空间,当我释放第二块内存空间然后紧接着申请一块8个字节的空间,此时由于之前释放的4个字节空间太小无法使用,这就造成了内存块空闲,这种碎片叫做外部碎片
PC寄存器
程序计数寄存器(Program Counter Register) :用于存储程序即将要执行的指令所对应在内存中的实际物理地址, 如果改变该值可以让指令跳转到我们想要跳转的地方
那么如何修改pc寄存器中的值呢?
我们可以使用转移指令
jr #类似相对寻址,跳到该寄存器给出的地址处
jal #将当前的程序计数器保存到 $ra 中,跳转到 sub_label 处的程序语句
j #看到就跳,不用考虑任何条件内存数据的读写
从指定内存中读取数据
从内存中读取数据的宽度取决于寄存器的大小,由于32位cpu寄存器最大储存32位数据
因此lw $t0表示一次性读取四个细节的数据到$t0寄存器
如果想要连续读取八个字节的数据,那么需要使用$ld这个伪指令
.data LEN: .word 12 .text ld $6, LEN它说基本代码
lui $1, 0x00001001 lw $6, 0x00000000($1) lui $1, 0x00001001 lw $7, 0x00000004($1)lw指令似乎可以完成所需的所有操作:它将32位特定地址0x00000000加载到寄存器$ 6中,并将随后的32位加载到后续寄存器中。
lui指令对我而言似乎毫无用处。 它甚至两次做同一件事,为什么呢?
它用作lw指令的偏移量,但必须具有两倍的相同值,否则我们不会在内存地址获得64位,而是两个"随机" 32位?
解释下
ld是"加载双字"(64b),它将加载指定的寄存器+下一个寄存器,因此$6表示ld中的$6+$7
所以ld $t0,表示一次性读取8个字节的数据到t0
往指定内存中写入数据
第一种
#整型数据
li $s1,4
sw $s1,0x10010000 #将$s1寄存器中的数据存入0x10010000这个物理地址
#单精度浮点数
.data
f1: .float 3.14
.text
lwc1 $f2,f1
swc1 $f2,0x10010000
#双精度浮点数
.data
d1: .double 3.14
.text
ldc1 $f2,d1
sdc1 $f2,0x10010000对于整形数据来说,我们将代码放到mars中跑一下看看,这里对应的值a1也发生了改变,与此同时$at(保留寄存器)位置也发生了偏移,也就是说保留的空间整体都发生了偏移。同时多出了一行原指令,这其实代表了将sw拆分成为了两条指令执行,首先是执行了lui,也就是取了$at中的立即数,也就是获取保留的内容,然后再用sw将$at中保留的内容给$s1存入内存,最终的结果就是将$s1寄存器中的数据存入0x10010000这个物理地址
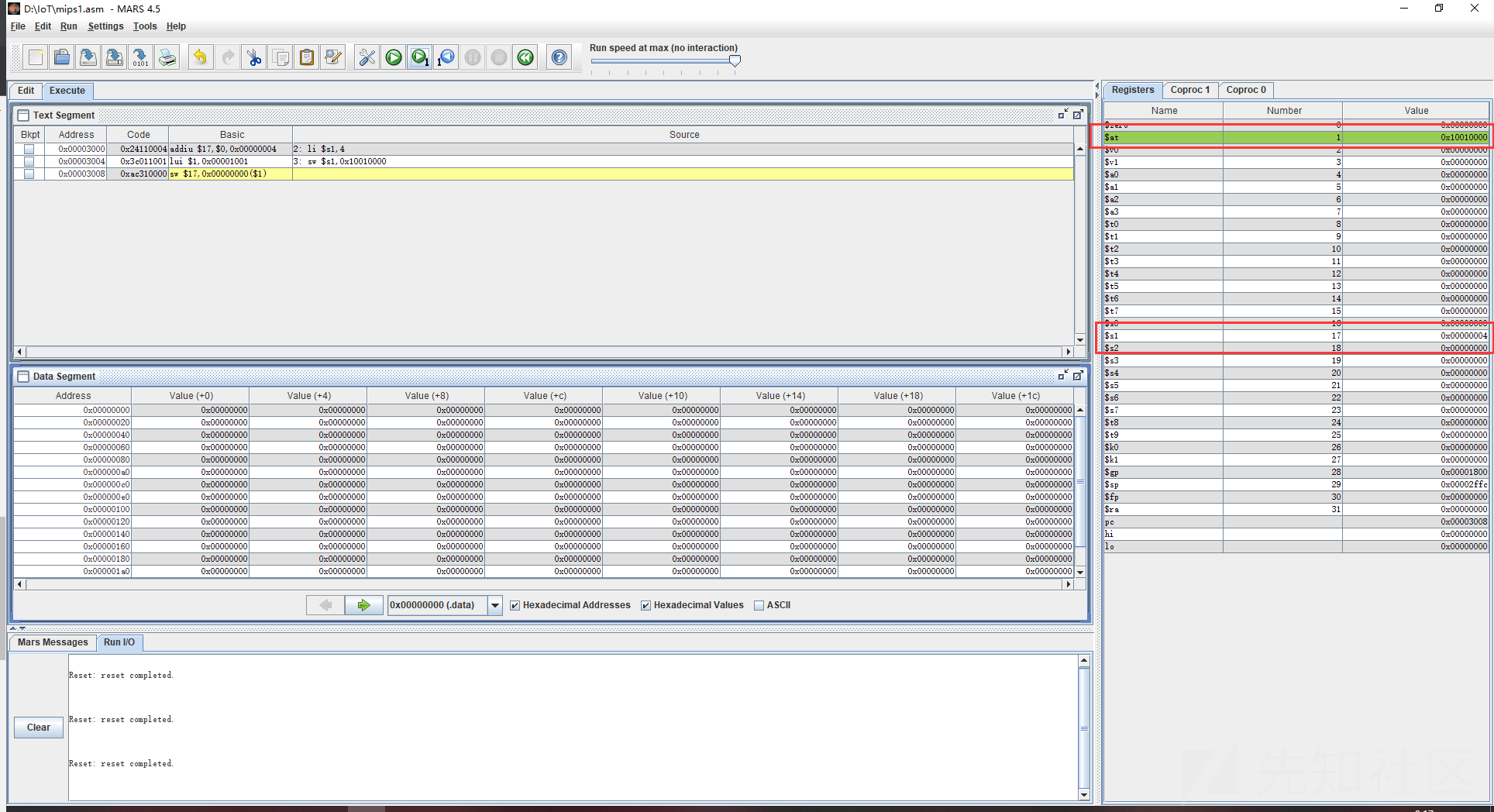
对单精度的浮点数进行测试,因为我们提前再数据段写入了数据,也就是f1的值,这样数据段地址的值就发生了变化。再通过lwc1(lwc1指令是针对FPU(协处理器),也就是针对浮点数专门拎出来的一条指令。功能与lw一样。)把f1的值读到$f2。这里对swc1的处理也是分成了两条来进行,基本和上面的过程一样,首先是执行了lui,也就是取了$at中的立即数,也就是获取保留的内容,然后再用swc1将$at中保留的内容给$f2存入内存,最终的结果就是将$f2寄存器中的数据存入0x10010000这个物理地址
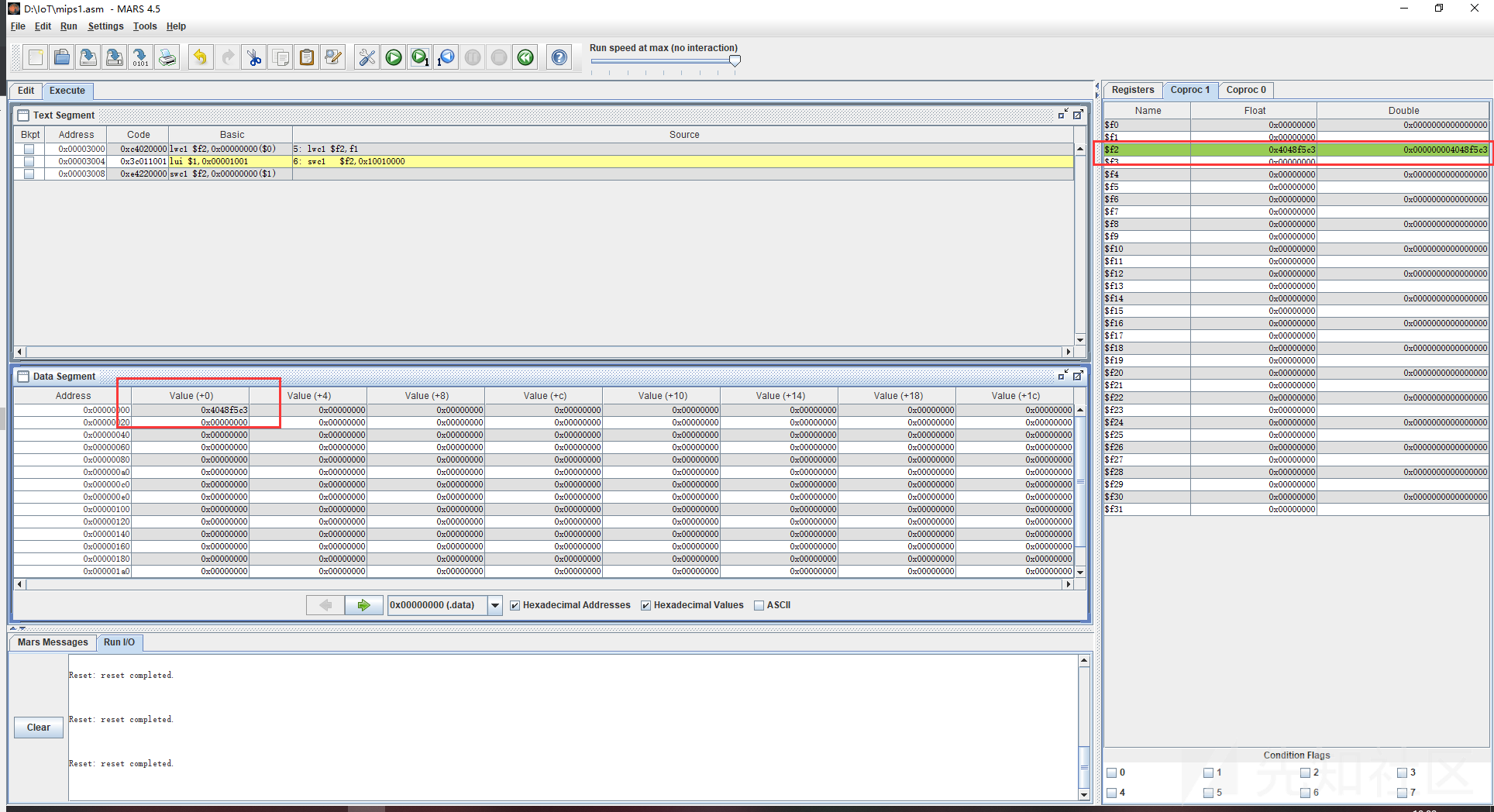
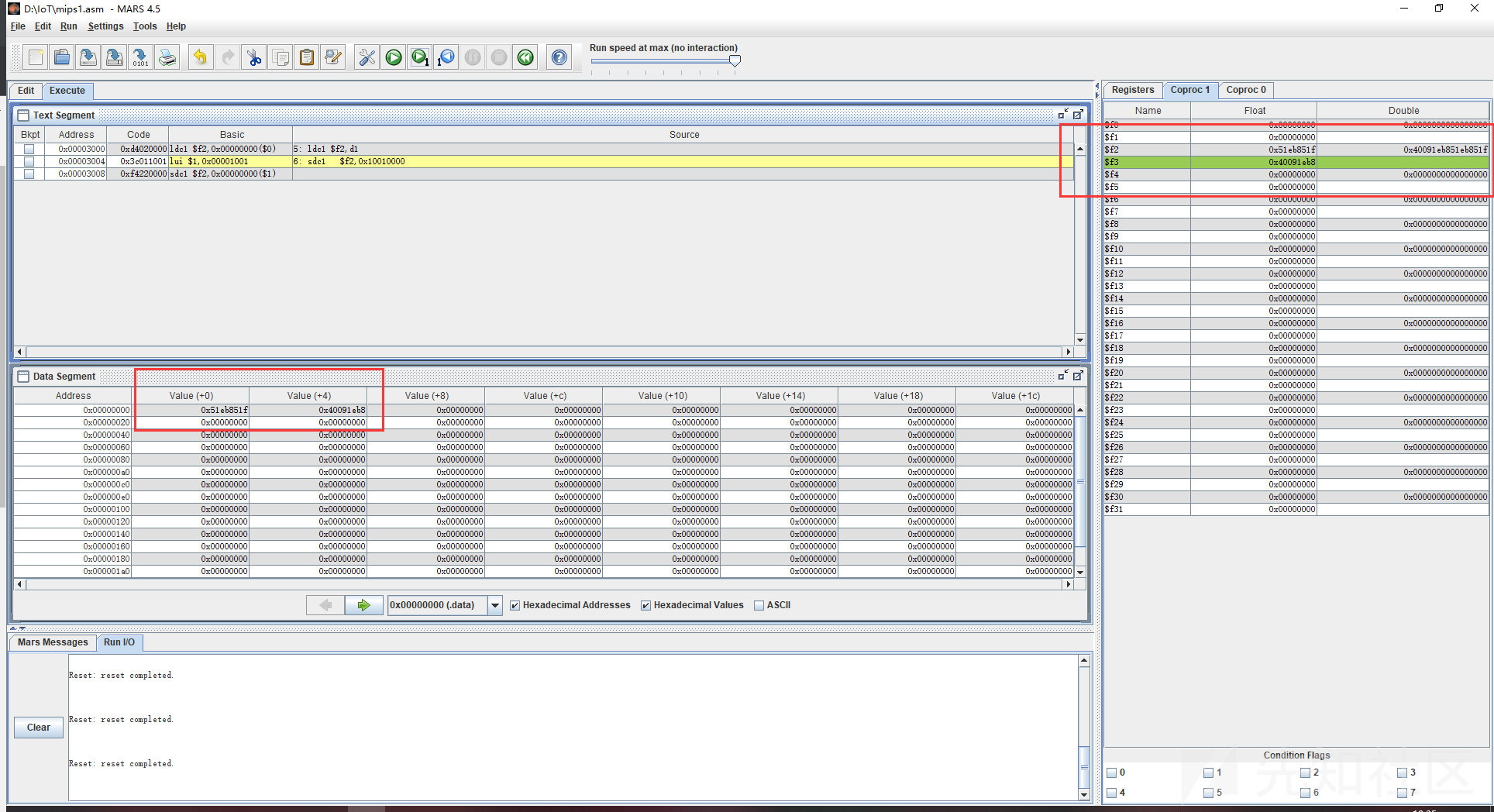
继续看双精度浮点数的测试,因为双精度浮点数会占用64位也就是八个字节的大小来存储数据,所以再数据段中会占八个字节来进行存储,之后我们将d1的值通过ldc1,其实就是ld,ld其实是ldc1的别名,是加载双字的意思,也就是加载64位,相当于加载了8个字节。它会将加载指定的寄存器+下一个寄存器,因此ldc1 $f2,d1,也就是ldc1 $f2+$f3,d1,所以f2和f3都有值。后面也是将sdc1拆分成了两条命令执行,基本和上面的过程一样,首先是执行了lui,也就是取了$at中的立即数,也就是获取保留的内容,然后再用swc1将$at中保留的内容给$f2存入内存,最终的结果就是将$f2寄存器中的数据存入0x10010000这个物理地址
第二种,在代码段中使用指令
以上直接使用的是简单粗暴的十六进制表示物理地址,很多时候内存的地址会保存在寄存器中,你可能会看到以下写法:
lw $s1, $s2
sw $s1, $s2
或者
lw $s1, 20($s2)
sw $s1, 20($s2) ;将地址往高位偏移20个字节 相当于sw $s1, 20+$s2
或者
lw $s1, -20($s2)
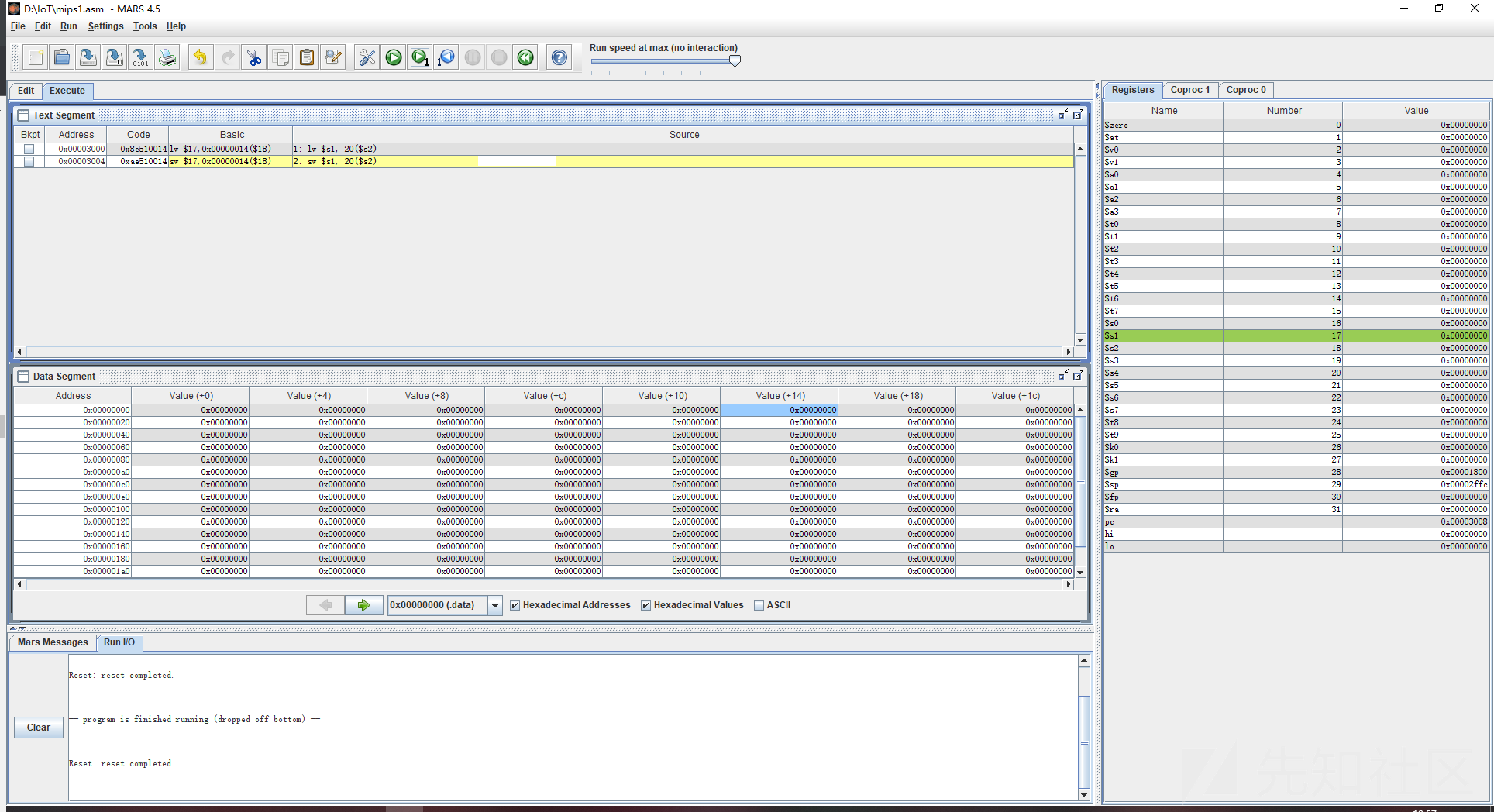
sw $s1, -20($s2) ;将地址往低位偏移20个字节但是要注意,往指定内存中读取和写入数据时,代码段不允许直接写入和读取
我们单步执行可以看到,我们将在内存中存储的$s2的20个字节加载到了$s1中,也就是加载到了寄存器里,执行之后s1就有了值,然后通过sw将寄存器的值在写回内存,加了20个字节,这样原本在内存中的$s1也就向高位偏移了20个字节
一组数组的定义
数组本质上就是多个数据的集合,在内存中按照一定顺序排列,角标即为每个数据的偏移值,在mips中内存数据是按照4个字节进行对齐的,也就是说一个数据最少占用4个字节内存空间,因此数组中数据之间的偏移量固定为n*4,n为角标值
.data
array: .space 20 #别名的另外一种用法 通过array(寄存器)这种格式 寄存器中存放地址偏移地址量
.text
# $t0寄存器存放角标值*4之后的偏移量 $s1中存放需要存入的值
li $s1,1
li $t0,0
sw $s1,array($t0) #相当于 sw $s1,array+$t0
li $s1,2
li $t0,4
sw $s1,array($t0)
li $s1,3
li $t0,8
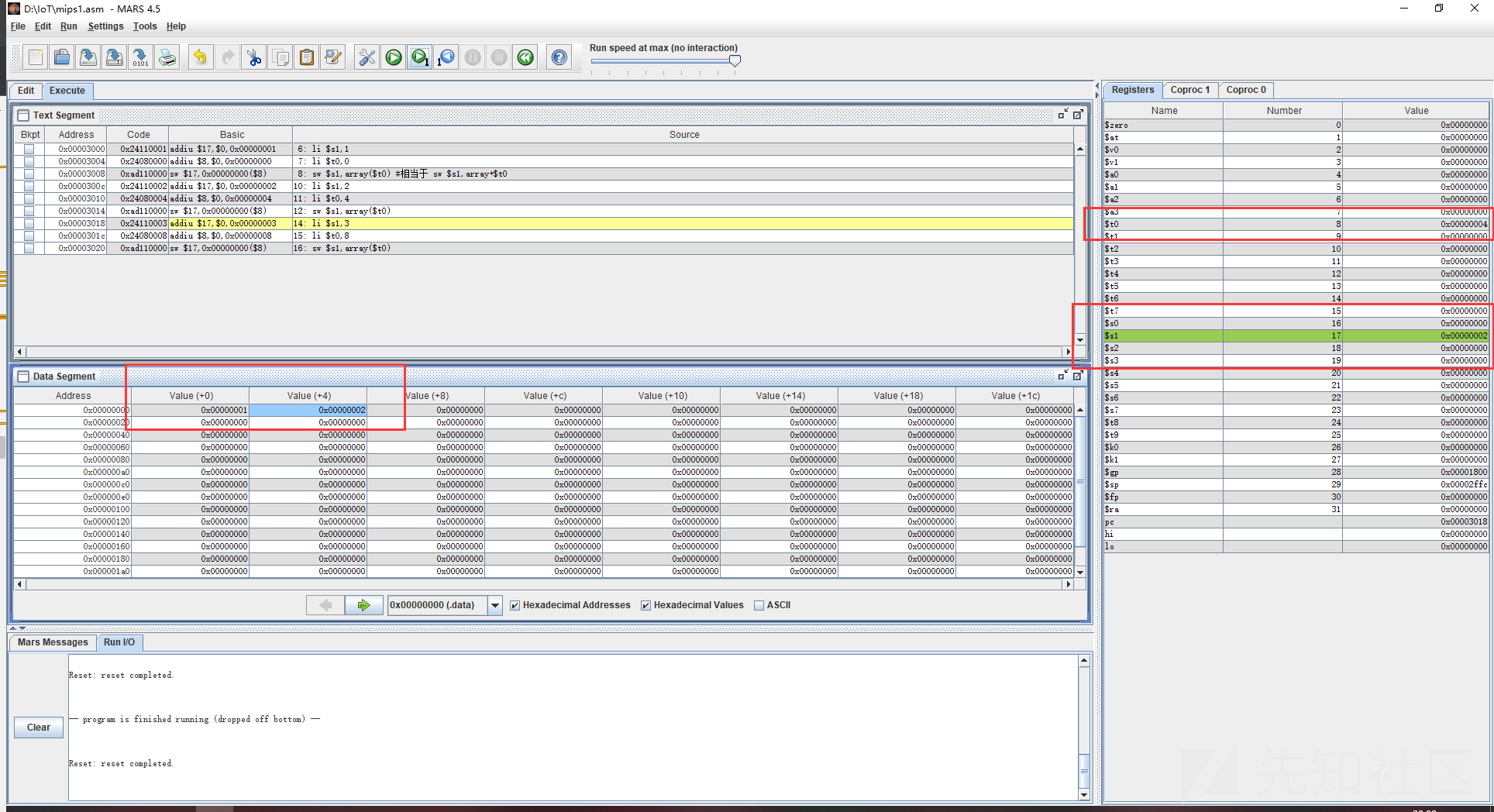
sw $s1,array($t0)我们把它放到mars中看下
.data段中存放了下偏移量,之后进入.text段,先将s1中存入一个值,然后将t0赋一个值,也就是这里的偏移量,然后执行sw存字,将s1的值从寄存器0个偏移的位置取出存入内存。这里我截图截的是在进行完第二段之后的状态,这里就很直观了,可以看到t0中存入了4,这里也就代表着偏移量为4,在下面的+4位置上正好可以看到s1所存放的值,第三段同理。
那么我们怎么输出他呢?也就是怎么打印出来呢?
.data
array: .space 20
.text
#初始化数组中的数据
li $s1,1
li $t0,0
sw $s1,array($t0)
li $s1,2
li $t0,4
sw $s1,array($t0)
li $s1,3
li $t0,8
sw $s1,array($t0)
#查找角标为2的数值
getData:
la $s1 ,array
li $a0,2
mul $a0,$a0,4
add $s1,$s1,$a0
lw $a0,0($s1)
li $v0,1
syscall
#将角标临时置为0 方便下面循环操作
li $t0,0
while:
beq $t0,12,exit
lw $t2,array($t0)
addi $t0,$t0,4
li $v0,1
move $a0,$t2
syscall
j while
exit:
li $v0,10
syscall我们分段来看,先看如何查找角标为2的数值。先将array的地址传入s1,将s1初始化。因为我们要查询角标为2的值,所以我们将a0的值加载为立即数2,因为存储的时候是四个字节一组,所以我们将a0,也就是角标乘4,获得开始的地址,然后把s1的值和a0的值相加得到想要获取的数值的偏移量,此时的s1就是8了,然后我们知道了偏移量和初始地址,通过lw来进行读取,此时的a0内就存放了从第八位开始的值,也就是角标为2的时候的值了。

我们再看第二段,将角标临时设置为0的。
首先先初始化寄存器$t0的值为 0。然后进入一个循环,如果$t0的值等于 12,则跳转到exit标签处结束程序。从数组array中读取数据,存入寄存器$t2中。将寄存器$t0的值加 4,以便在下一次循环中读取下一个整数。输出寄存器 $t2 中的整数。通过跳转回while标签处,继续循环读取下一个整数。循环结束后,执行 exit 标签处的代码,将程序结束。

快速初始化数组
.data
array: .word 20 :3 #批量定义3个整型数据20分支跳转
bgt(branch if greater than):用于大于比较
bgt $t0,$t1,sub # 如果$t0中的数据大于$t1,则跳转到sub分支,执行sub中的代码,否则,按照顺序执行bgt下面的代码, sub是一个代号,可以自定义
sub:beq(branch equal):用于等于比较
beq $t0,$t1,sub # 如果$t0中的数据等于$t1,则跳转到sub分支,执行sub中的代码,否则,按照顺序执行beq下面的代码, sub是一个代号,可以自定义
sub:ble(branch if less than):用于小于比较
ble $t0,$t1,sub # 如果$t0中的数据小于$t1,则跳转到sub分支,执行sub中的代码,否则,按照顺序执行ble下面的代码, sub是一个代号,可以自定义
sub:这个东西怎么用呢?举个例子
当我们在c语言中简单写好饿了一个比较数字大小的小工具
scanf("%d",$a); scanf("%d",$b); if(a>b){ printf("YES"); }else{ printf("NO"); }
在mips中如何实现呢?首先在.data节定义了两个字符串变量msg_yes和msg_no,分别存储"YES\0"和"NO\0"两个字符串,其中 \0 表示字符串的结尾。
接下来在.text节中,使用li指令将$v0寄存器设置为5,表示要使用syscall服务5读取一个整数。然后使用syscall指令,等待用户输入一个整数,并将输入的结果存储在$v0寄存器中。接着使用move指令将$v0中的值复制到$t0寄存器中。
接下来再次使用li和syscall指令读取一个整数,并将输入结果存储在$t1寄存器中。
然后使用bgt指令比较$t0和$t1的大小,如果$t0大于$t1,则跳转到标记为sub的代码块;否则继续执行下一条指令。
如果$t0大于$t1,则使用li和la指令将$v0和$a0寄存器分别设置为4和msg_no,表示要使用syscall服务4输出字符串msg_no。然后使用syscall指令将msg_no字符串输出到控制台。
最后使用li指令将$v0寄存器设置为10,表示要使用syscall服务10退出程序,然后使用syscall指令退出程序。
如果$t0不大于$t1,则直接跳转到标记为sub的代码块。在sub代码块中,使用li和la指令将$v0和$a0寄存器分别设置为4和msg_yes,表示要使用syscall服务4输出字符串msg_yes。然后使用syscall指令将msg_yes字符串输出到控制台。
最后使用li指令将$v0寄存器设置为10,表示要使用syscall服务10退出程序,然后使用syscall指令退出程序。
可以发现,麻烦了不少。
# 用$t0指代a ,$t1指代b
.data
msg_yes: .ascii "YES\0" # \0表示字符串结尾
msg_no: .ascii "NO\0"
.text
li $v0,5 #控制syscall为读取integer状态
syscall # 此时io控制台显示光标,可输入数字,回车后将输入的数字保存在$v0中
move $t0,$v0 #由于接下来还需要使用$v0 ,为避免数据被覆盖掉 将输入的数据转移到$t0中进行临时保存
li $v0,5
syscall
move $t1,$v0
bgt $t0,$t1,sub
li $v0,4
la $a0,msg_no
syscall
#结束程序
li $v0,10
syscall
sub:
li $v0,4
la $a0,msg_yes
syscall我们再看一个计算从一到一百的和的mips汇编。首先,通过 .text 段设置了两个寄存器 $t0 和 $t1 分别为 1 和 0。
然后,通过 loop 标签实现了一个循环,每次循环中:
- 计算 $t1 = $t1 + $t0,将 $t0 加到 $t1 中。
- 计算 $t0 = $t0 + 1,将 $t0 加 1。
- 检查 $t0 是否小于等于 100,如果小于等于 100,则跳转到 loop 标签继续执行循环。
最后,将 $t1 中的值作为参数传递给系统调用函数,通过 syscall 输出到控制台上。
总体来说,以上代码实现的功能是计算从 1 到 100 的所有整数的和,并将结果输出到控制台上。
# 用$t0指代i ,$t1指代s
.text
li $t0 ,1
li $t1 ,0
loop:
# s=s+i;
add $t1,$t1,$t0
add $t0,$t0,1
ble $t0,100,loop
move $a0,$t1
li $v0,1
syscall关于多文件的处理
在文件A中定义函数
fun:
li $v0,1
li $a0,1
syscall
jr $ra在文件B中使用关键字.include引用A文件中的函数
.text
jal fun
.include "A.asm"所有文件必须在同一目录下!!!
宏
宏的替换
全局替换,使用我们上面的.include伪指令进行替换
宏匹配
在汇编中,如果我们要依次打印1、2、3三个整数,那么汇编如下
print1:
li $v0,1
li $a0,1
syscall
jr $ra
print2:
li $v0,1
li $a0,2
syscall
jr $ra
print2:
li $v0,1
li $a0,3
syscall
jr $ra我们发现使用标签的方式定义函数,当函数体内容存在不确定变量值时,代码非常冗余, 如果使用高级语言进行封装的话,我们一般一个函数就搞定了:
void print(int a){ print(a); }
有没有办法使得汇编能像高级语言一样简洁呢?
在MARS中给我们提供了一个扩展伪指令,叫做宏匹配
宏匹配使用的格式如下:
.macro 别名
#汇编指令...
.end_macro举个例子
li $v0,10
syscall
#比如我们要对以上两行指令使用宏匹配进行封装
#封装结果为
.macro exit
li $v0,10
syscall
.end_macro
#在代码中引用
.text
exit #直接使用别名调用如果我们要封装一个打印整型数据的函数,那么我们可以:
#封装结果为
.macro print_int(%param)
li $v0,1
li $a0,%param
syscall
.end_macro
#在代码中引用
.text
print_int(1) #直接使用别名调用
print_int(2)
print_int(3)经过这样对程序的封装之后,我们使用再去编写程序的成本就大大降低了,避免了重复编写系统调用代码的繁琐。
结合上面学的对多文件的处理,我们会在很多地方见到将封装好的函数单独放在一个文件中,然后直接在头部.include。
宏定义
我们可以使用伪指令.eqv来对系统中原生的东西进行定义别名进行调用
举个例子:首先,使用伪指令 ".eqv" 定义了三个常量。其中,常量 "LIMIT" 被定义为数值 20 的别名,常量 "CTR" 被定义为寄存器 $t2的别名,常量 "CLEAR_CTR" 被定义为将寄存器,常量 "CLEAR_CTR" 被定义为将寄存器$t2的值清零的伪指令add CTR, $zero, 0的别名。
在 ".text" 段中,首先将系统调用号 1 (即 "print_int") 装载到寄存器$v0中。然后调用伪指令 "CLEAR_CTR",将寄存器 $t2 清零。接着使用 "li" 指令将数值 20 装载到寄存器 $t0 中,该值为之前定义的常量 "LIMIT" 的值。
.eqv LIMIT 20 #给20这个立即数取个别名为LIMIT
.eqv CTR $t2
.eqv CLEAR_CTR add CTR, $zero, 0
.text
li $v0,1
CLEAR_CTR
li $t0,LIMIT宏定义和宏匹配必须 先定义后使用 ,也就是说定义的代码需要放在前头
Mips汇编指令汇总
这里乱码三千师傅已经整理的很全了,直接放图吧
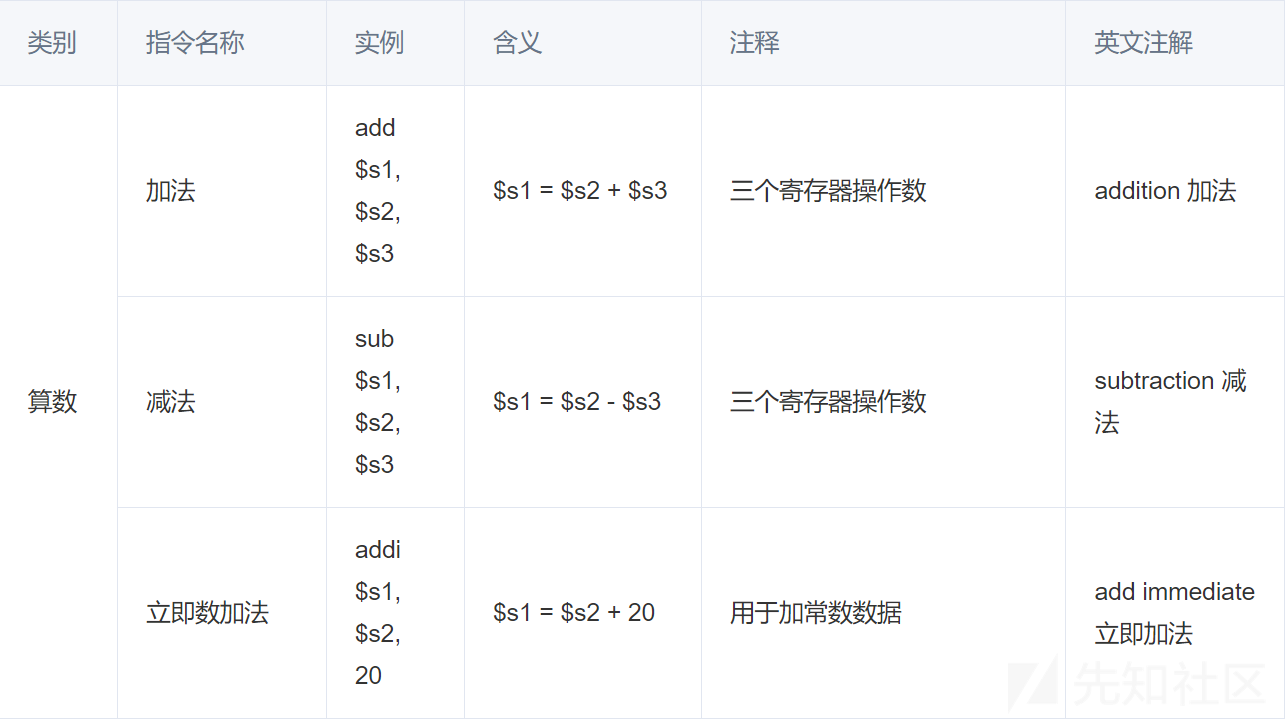
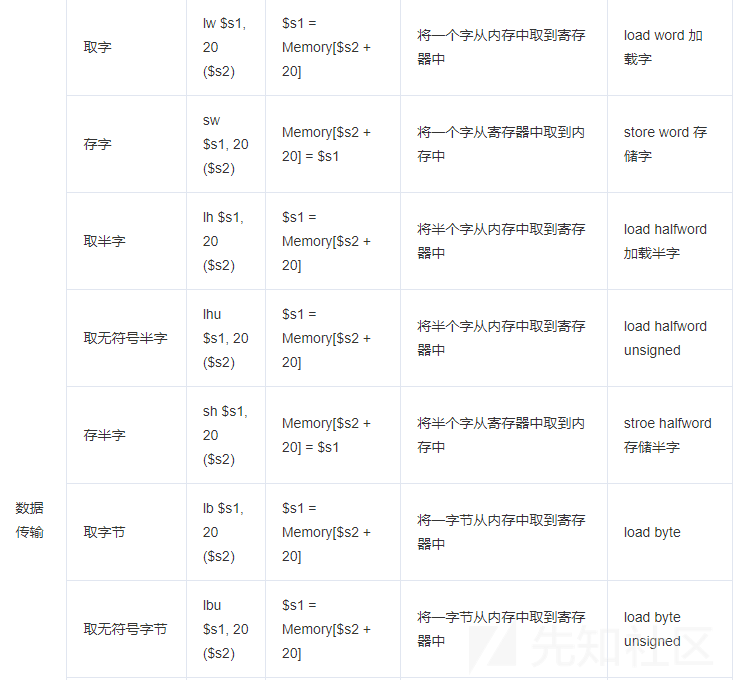

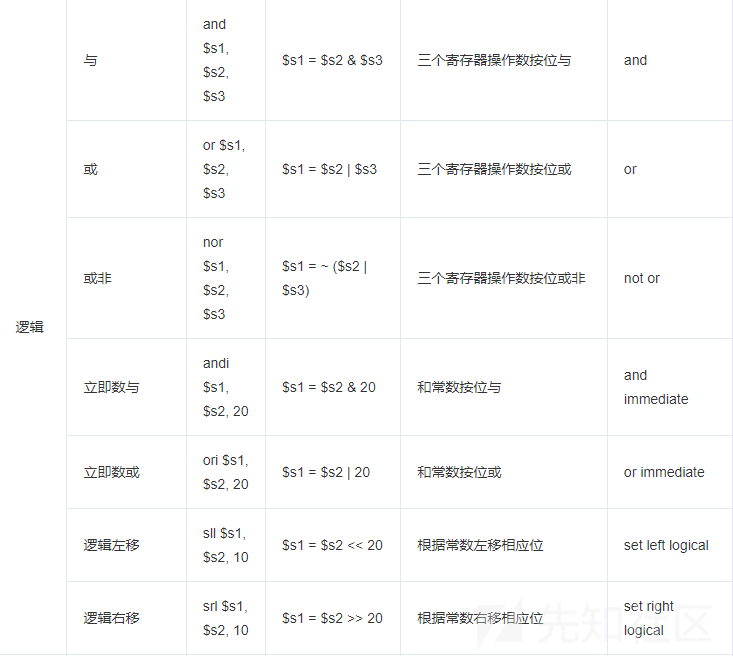


参考链接
https://cloud.tencent.com/developer/article/1867013 汇编语言之MIPS汇编
https://www.cnblogs.com/thoupin/p/4018455.html Mips汇编入门
https://valeeraz.github.io/2020/05/08/architecture-mips/ MIPS汇编语言入门
如有侵权请联系:admin#unsafe.sh