一直都有一个需求,需要对部分的图片中的不同语言进行提取(虽然百度翻译也可以直接做),但是权当技术积累。主要是记录一下踩过的坑。
需要安装python3、引入两个库,分别是cv2(opencv-python)、pytesseract
import cv2
import pytesseract
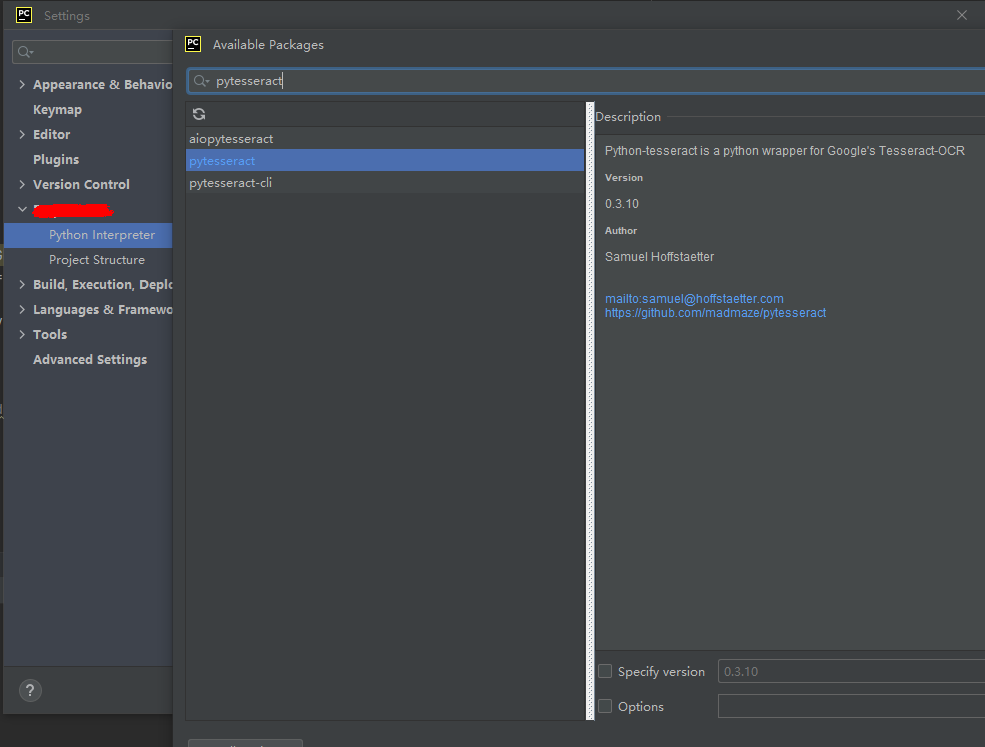
可以通过pip install安装,我这里直接使用pycharm的settings安装的。
安装完了以后,需要安装tesseract.exe,这里避免安全问题,推荐直接通过github官方下载,链接如下:
https://github.com/UB-Mannheim/tesseract/wiki
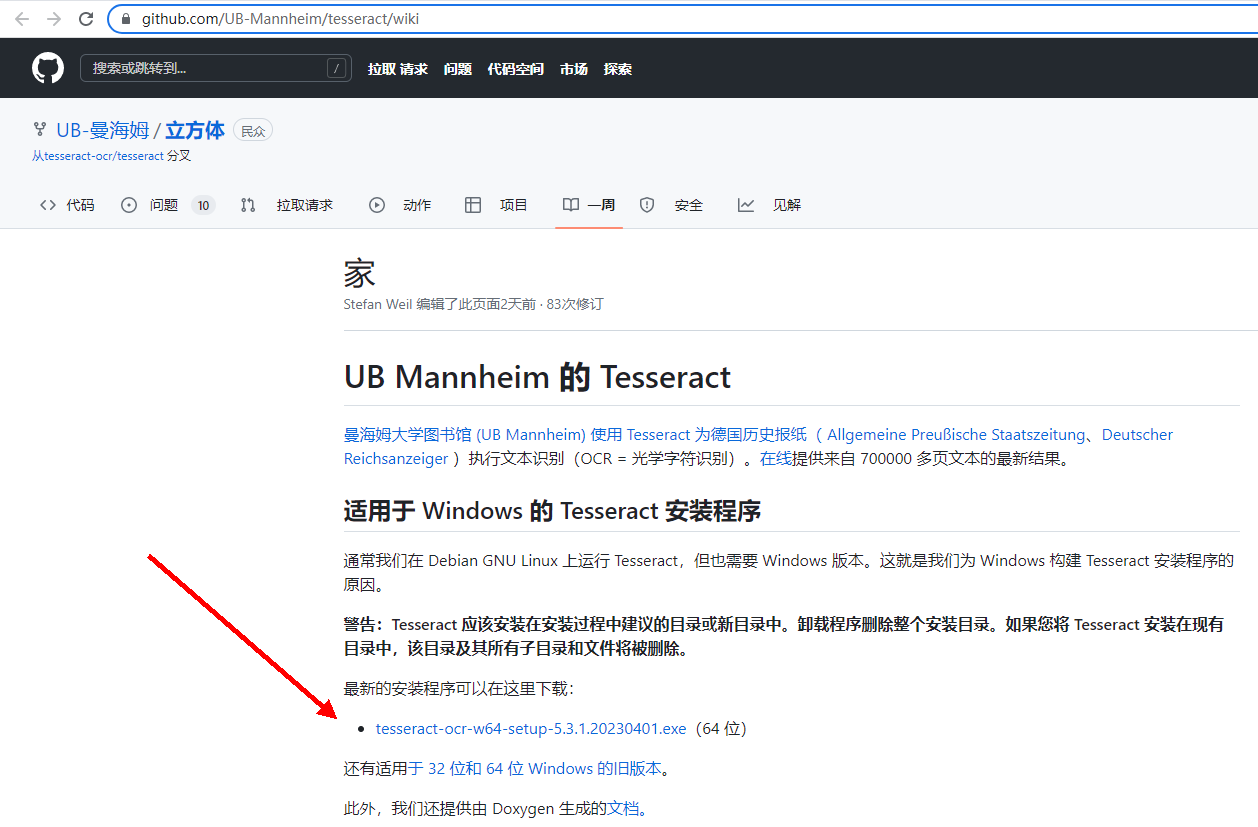
下载好了以后,需要安装,安装记得选择你自己设置好的路径。
同时,记得设置环境变量:
SET TESSDATA_PREFIX=D:\Program Files\Tesseract-OCR\tessdata
下载回来的时候没有kor语言包,需要自行去下载:
https://github.com/tesseract-ocr/tessdata
编写代码跑一下看看:
import cv2
import pytesseract
from PIL import Image
from translate import Translator
#如果需要引入Translator,还需要pip install translate
# 读取图片
image = cv2.imread('comic.png')
# 将图片转换成灰度图,便于识别
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
pytesseract.pytesseract.tesseract_cmd = 'D:\\Program Files\\Tesseract-OCR\\tesseract.exe'
# 识别图片中的文字
text = pytesseract.image_to_string(gray, lang='kor')
# 将韩文转换成中文
#from_lang参数为原来的语言,to_lang为你想要翻译成的语言类型
translator = Translator(from_lang="ko",to_lang="zh-cn")
translation = translator.translate("需要翻译的韩文")
# 输出识别的文字
print(text)
#输出翻译以后的文字
print(translation)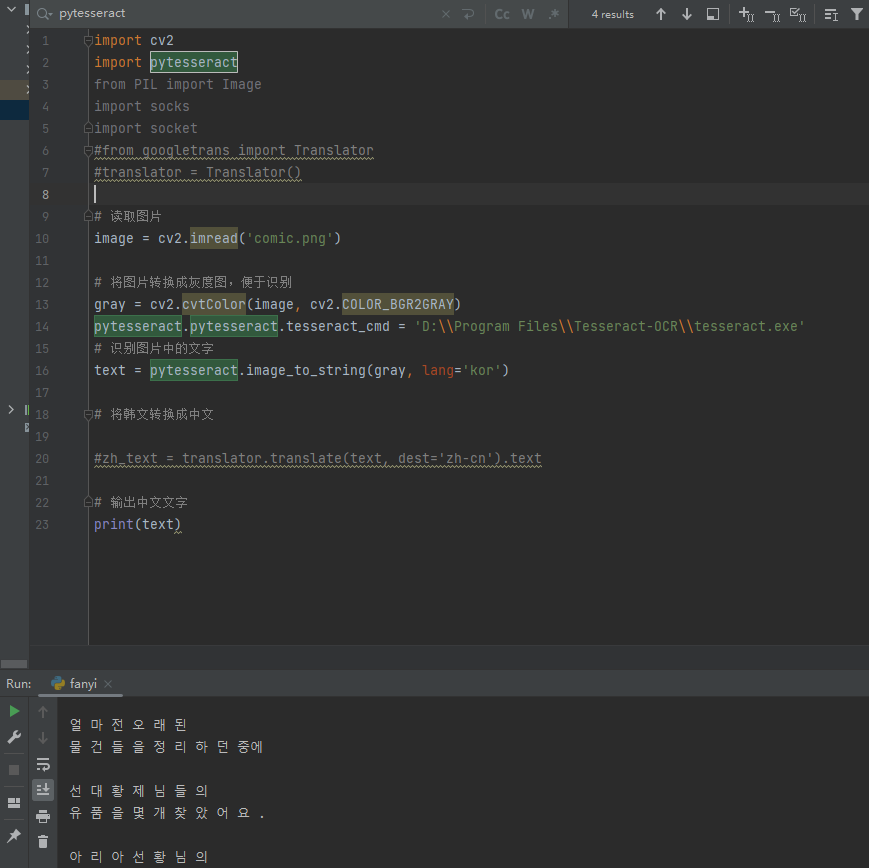
已经完成了自己想要的效果。