背景
伴随着AI时代的到来,人们生活的方方面面都离不开计算机,人们也越来越依赖于电子产品,而恶意代码的数量规模呈指数级增长,且大多是已知种类的变种,人们的隐私和安全受到了极大的挑战。
同时当代社会正经历着一次又一次的技术变革,而人工智能,也称机器智能,就是在技术变革的浪潮中衍生出来的产物。而深度学习作为人工智能的一个分支,也得到了非常多的应用,但就目前的研究来看,将之应用到与恶意代码家族标注方面的研究较少。
本文是针对恶意代码进行静态分析,利用恶意代码的反汇编文件,生成恶意代码的图像,针对图像进行gist全局特征提取,并搭建卷积神经网络,采用监督学习的方式,进行上万个样本的训练,实现了恶意代码家族的标注。实验结果表明,该方法可以有效的判别恶意代码的种类,具有较高的正确率以及较低的误报率。同时,本文搭建了用于预测恶意代码家族种类的系统,具备预测样本家族种类,展示恶意代码样本图像等功能,本系统大大提高了用户对于恶意代码的防范能力和警觉性。
主要思路
目前针对恶意代码图像进行的分类研究在恶意代码领域总体而言较少,因此本文使用恶意代码样本的反汇编机器码文件,将B2M算法改进,生成长宽相同的正方形恶意代码图像,这样就将对恶意代码的分类转为对图片种类的识别。随后对图像进行标准化,归一化等预处理。把预处理完成后的图像利用Gist算法,调用Matlab软件的接口对其进行特征提取。随后采用搭建好的卷积神经网络模型进行训练,模型中采用了优化卷积核方法,退化学习率方法,批量归一化算法等进行优化处理。训练好模型后,在测试集进行测试,同时使用图形化窗口将其做成系统,可根据所上传恶意代码样本文件进行检测,并返回检测结果。利用预测系统,可大大提高用户对恶意代码文件的防范能力与警觉性。
具体实现方法
利用IDA实现恶意代码样本反汇编获得其机器码
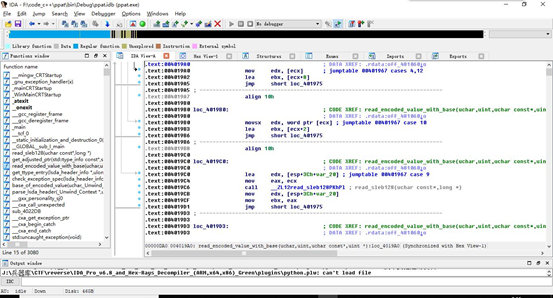
具体操作步骤:首先打开IDA反汇编软件,在软件中打开exe可执行文件。
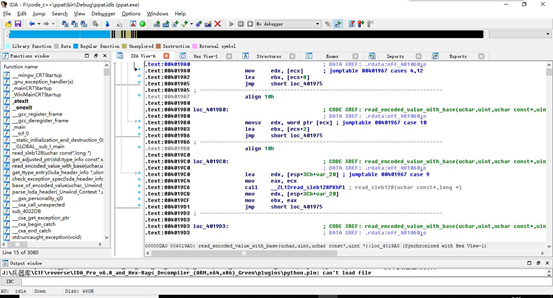
可以看见在整个IDA窗口里面,存在很多小窗口,有IDA View-A, Hex View-A,Structures等等很多窗口,在这么多窗口中,需要的是反汇编生成的汇编码文件以及机器码文件。单击菜单栏File->Produce file->Create ASM file即可生成该二进制可执行文件的汇编码文件。
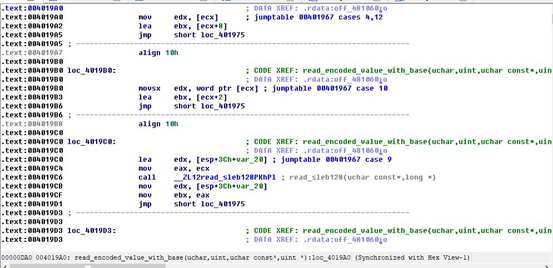
生成机器码文件的过程比较复杂,在Hex View1窗口中,可以看到二进制文件的机器码,而后在窗口里单击右键->Text->Show(将Show前面的对号取消),则在窗口内显示的就变成了纯机器码。
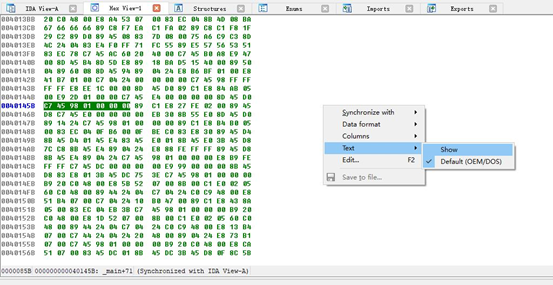
随后单击菜单栏Edit, 选择Select all,就会将所有的机器码选中,这时复制,在一个固定的文件夹下新创建一个名为该exe文件原名的bytes文件,并将其粘贴进去即可完成机器码文件的生成。或者可以采用其他十六进制文件进行操作,在这里就不一一赘述了。
恶意代码图像的生成
在恶意代码可视化方面,我国的研究人员也取得了一定的成果。早在2014年,北京科技大学的韩晓光博士与北京启明星辰研究院合作在通信学报上发表了一篇论文名为《基于纹理指纹的恶意代码变种检测方法研究》,在这篇文章中,韩博士利用B2M算法,针对PE文件以二进制的形式读取,而后每8bit作为一个单位,这样每个单位的范围控制在0-255之间,也就是每个像素的实际单位大小,给定固定的宽,而图像的高度选择,为整个文件大小与宽度的比值,使整个文件生成一个固定宽的灰度图的形式,通过上述方法绘制灰度图,恶意代码样本的纹理特征就清晰的可视化表现出来了。
同理,利用上述步骤生成的机器码文件也可以生成该恶意代码样本的灰度图,机器码为十六进制表示,十六进制的字符范围在0x00-0xff之间,而其转化为十进制范围同样在0-255之间,与二进制文件转化成的恶意代码图像原理完全相同。生成的灰度图如下图所示。

聚类存放
使用上述步骤将恶意代码样本转为恶意代码图像后,对近万个样本生成的恶意代码图像进行聚类存放,相同家族放在一起。可以观察出其在纹理、色泽等特征方面具有明显的相似之处。下图所示为Ramnit家族图像:

下图所示为Kelihos_ver1家族图像:

图像标准化处理
由于恶意代码样本文件大小不一,而后需要进行特征提取等方面的工作,需故要将所有的图片进行调整图片大小,标准化,归一化等操作。只有在图片大小相同的情况下,标准化,归一化操作进行完成后,对后续的操作即特征提取,作为网络的输入等才会有意义,图像标准化处理算法如下图所示:
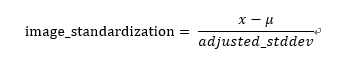
其中μ是图像像素点的均值,x表示图像矩阵,其中adjust_stddev的值:
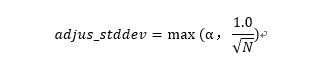
其中"α" 表示标准方差,N表示图像的像素数量。如下图是经过标准化处理后的图片与原始图片的对比。
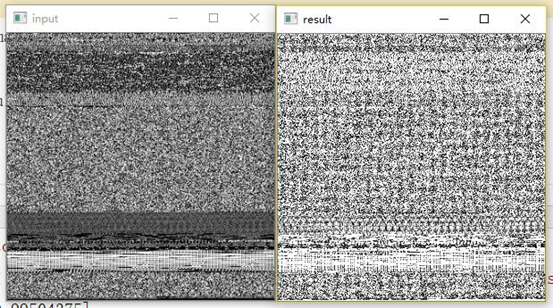
图像归一化处理
图像归一化最常用的方法为最大最小值归一方法,图像归一化处理算法:
norm= (x_i-min(x))/(max(x)-min(x)).其中x_i表示图像在第i个点处的像素点值,max(x), min(x)分别表示图像像素的最大值和最小值。经过图像归一化处理后,图像的像素点范围由[0, 255]转为[0,1]之间的实数,这样做有利于后续神经网络对于数据的处理,有助于快速收敛和反向传播。
图像特征提取
图像特征主要有图像的颜色特征,纹理特征,形状特征和空间关系特征。颜色特征是一种全局特征,描述了图像或图像区域所对应的景物的表面性质。显然,前文中指出的使用B2M算法生成的恶意代码图像属于灰度图,并不具备颜色特征。纹理特征也是一种全局特征,它也描述了图像或图像区域所对应的景物的表面性质。与颜色特征不同,纹理特征不是基于像素点的特征,它需要在包含多个像素点的区域中进行统计计算。
GIST算法作为一种针对图片的宏观特征提取方式,忽略图片的局部特点。其又称为全局特征信息,为场景的低维签名向量。采用全局特征信息对场景进行识别和分类,不需要对图像进行分割和局部特征提取,可以实现快速场景识别和分类。
具体方法为:假设待提取特征的恶意代码图像为f(x,y)。首先,将其划分为n×n的网格,每个网格表示一个子区域,用c个通道的滤波器对子区域进行卷积滤波,其中c等于滤波尺度和方向数的乘积。然后在每个网格内计算每个通道的平均能量得到特征。将每个网格的特征级联,就得到恶意代码图像的全局Gist特征。
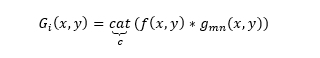
首先32个Gabor滤波在4个尺度,8个方向上进行卷积,得到32个feature map,大小和输入图像一致。然后把每个map分成4*4=16个区域,计算每个区域内的均值。得到均值后,就获得了4*4*32=512维向量特征。这个512维向量特征作为恶意代码图像的全局特征指纹。
将一幅预处理好的恶意代码图像作为输入,Matlab中有已经实现好的Gist算法,可以直接调用Matlab软件的接口,并将输出保存在文件中。下图为算法输出。
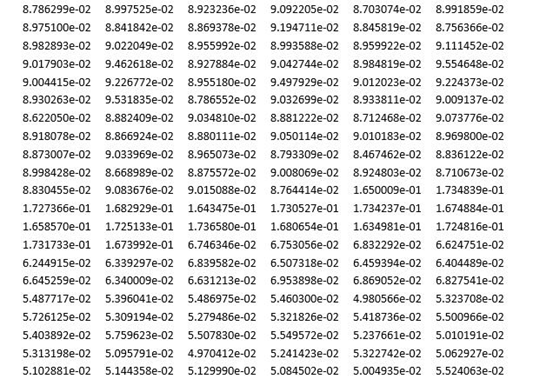
MATLAB代码如下:
function get_gist(imgname)
% Load image
img = imread(imgname);
% GIST Parameters:
clear param
param.orientationsPerScale = [8 8 8 8]; % number of orientations per scale (from HF to LF)
param.numberBlocks = 4;
param.fc_prefilt = 4;
% Computing gist:
gist = LMgist(img, '', param);
%disp(gist);
%length(gist)
%resultName = 'C:\Users\49627\Desktop\two_eight\test_file\gist_pic\';
resultName = './test_file/gist_pic/';
imgname = regexp(imgname,'/','split');
imgname = imgname(4);
resultName = strcat(resultName,imgname);
resultName =regexprep(resultName,'.tif','.gist');
resultName = char(resultName);
fid = fopen(resultName,'w');
for i=1:512
fprintf(fid,'%d ',gist(i));
end
fclose(fid);
end之后使用python批量化提取gist特征:
def call_matlab(AllImg): # 利用os.system() 执行cmd中的命令。
cmmd = 'matlab -nojvm -nosplash -r "'
get_gist = "get_gist"
i = 0
for img in AllImg:
cmmd += get_gist +"('"+img+"');"
if i==10:
cmmd +='exit"'
os.system(cmmd)
print(cmmd)
time.sleep(4)
i = 0
cmmd = 'matlab -nojvm -nosplash -r "'
i += 1卷积网络结构
上文使用Matlab软件进行Gist特征提取,提取结果为[1, 512]的二维数组,调整数据形状为[32, 16],输入形状为32×16×1,第一层卷积核为5×5,将输入的1通道转为32通道,第二层使用批量归一化(BN算法),最大限度的保证输出在同一分布上,第三层为Relu激励层,第四层是卷积核形状为2×2的最大池化层。第五层为两个卷积核并行的卷积层,两个卷积核形状分别为3×3,5×5,第六层分别对上一层两个卷积操作进行批量归一化处理,第七层为两个卷积的Relu激励层,第八层使用concat函数将两个卷积操作后的输出拼合在一起。第九层是卷积核形状为2×2的最大池化层。第十层输出1024节点的全连接层,第十一层为Relu激励层,第十二层为dropout层,随机的选择一些数据进行丢弃,降低对小概率异常数据的学习机会。第十三层为9个节点的全连接层,最后归为9类。第十四层为softmax层。网络层次结构如下图所示:
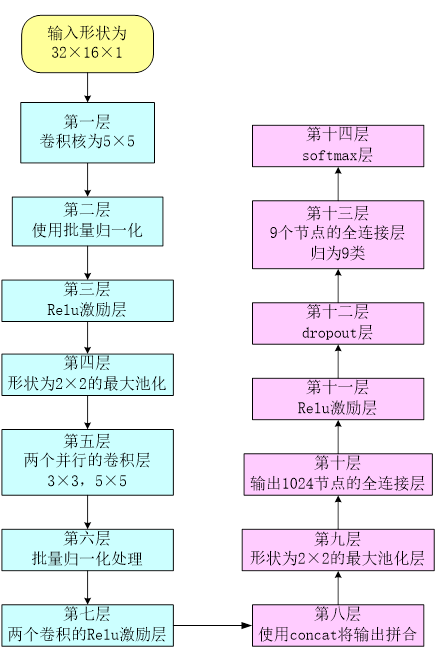
数据集、训练设备及结果说明
数据集
本项目所采用的数据集为2015年微软公司在kaggle上发布的一个项目,项目地址为:https://www.kaggle.com/c/malware-classification/。
数据集解压后为400G大小,包括训练样本,测试样本,以及训练样本的标签,标签为一个csv文件,其中详细的标注了训练样本中每一个恶意代码样本的名称以及它所对应的家族种类。
系统样本库中所使用的九类恶意代码家族种类为:Ramnit,Lollipop,Kelihos_ver3,Vundo,Simda,Tracur,Kelihos_ver1,Obfuscator.ACY,Gatak。
以下是每个家族的详细介绍:
- Ramnit家族所具备的危害为感染Windows可执行文件和HTML文件并尝试允许远程访问的病毒的检测。
- Lollipop家族所具备的危害为此广告软件程序会在您浏览网页时显示广告。它还可以重定向搜索引擎结果,监控您在PC上执行的操作,下载应用程序以及将有关PC的信息发送给黑客。
- Kelihos_ver3家族所具备的危害为可以分发垃圾邮件,其中可能包含自身安装程序的Web链接。它还可以连接到远程计算机以交换配置数据以及下载和执行任意文件。
- Vundo所具备的危害为提供“脱离上下文”的弹出式广告,下载和运行文件,经常作为DLL文件传播,并在未经您同意的情况下作为浏览器帮助对象(BHO)安装在您的PC上。
- Simda所具备的危害为威胁可以为您的PC提供恶意黑客后门访问和控制。然后,他们可以窃取您的密码并收集有关您PC的信息。
- Tracur所具备的危害为运行时,此脚本会将“ explorer.exe ”进程添加到Windows防火墙例外列表中,以故意降低系统安全设置。
- Kelihos_ver1所具备的危害为可以分发垃圾邮件,其中可能包含自身安装程序的Web链接。它还可以连接到远程计算机以交换配置数据以及下载和执行任意文件。
- Obfuscator.ACY所具备的危害为这种威胁一直是“obfuscated“,这意味着它试图隐藏其目的,因此您的安全软件无法检测到它。混淆之下的恶意软件几乎可以用于任何目的。
- Gatak所具备的危害为收集有关您的PC的信息并将其发送给黑客。它可以作为密钥生成器应用程序的一部分到达您的PC,或者看起来是合法应用程序的更新。
样本数据共10860个,本实验采取随机抽样来分割训练样本和测试样本,即在任意类别中以4:1进行切分数据。训练样本共有8686个,测试样本有2174个。
训练设备环境配置
- cpu 40核
- 内存256G
- ubuntu系统;
- python3.6;
- python装有以下库:numpy, tensorflow, pyqt5, cv2;
结果
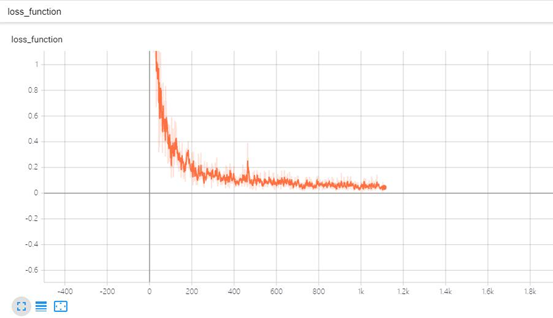
在测试集上准确率表现为98.758%,交叉熵表现为0.0858844。训练与测试如下图所示:
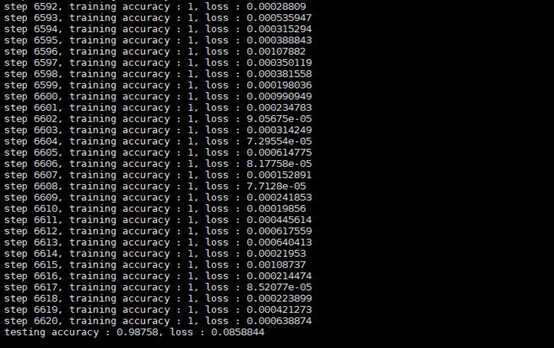
TensorBoard可视化
在训练网络的代码中添加TensorBoard模块的API,生成日志文件,随后使用日志文件观测训练是否正常,准确率accuracy,交叉熵loss如图所示:
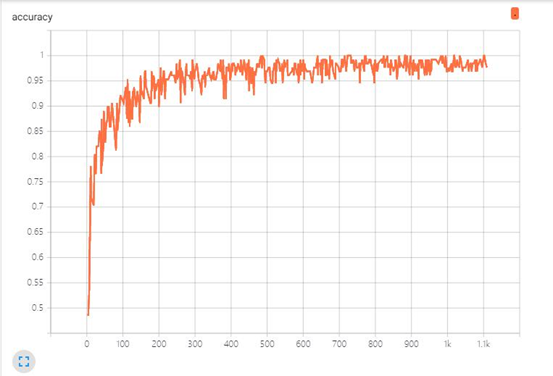
缺陷及限制
数据源中的样本并不包含正常文件,只有九类恶意代码家族样本,利用九类恶意代码家族样本训练出成熟的模型最后只能用于预测恶意代码家族分类,这是先天的因素所限制,导致本项目的可适用性略窄。而针对恶意代码家族标注的系统一般都会具备检测是否恶意代码功能,如果为恶意代码,则会进一步检测恶意代码的家族种类。
如有侵权请联系:admin#unsafe.sh