The Pedersen hash function has gained popularity due to its efficiency in the arithmetic circuit 2023-3-22 21:0:0 Author: research.nccgroup.com(查看原文) 阅读量:27 收藏
The Pedersen hash function has gained popularity due to its efficiency in the arithmetic circuits used in zero-knowledge proof systems. Hash functions are a crucial primitive in cryptography, and zero-knowledge proof systems often make heavy use of them, for example when computing Merkle tree roots and paths. Instead of being based on complex bit-fiddling operations like its standard counterparts (of the SHA or BLAKE families, for example), the Pedersen hash is an algebraic hash function that is simply computed as a linear combination of points on an elliptic curve. They are therefore fairly efficient to compute in zero-knowledge circuits since their computations relies on field arithmetic, contrarily to the more traditional hash functions that have no convenient mathematical structure.
Based on foundational work from the early 1990s that also led to the formalization of commitment schemes (see for example [CHP91] and [Ped91]), the (originally-named) PedersenHash function was recently put in the spotlight when Zcash researchers Sean Bowe and Daira Hopwood developed specific optimizations for its efficient instantiation in zk-SNARK circuits [Zcash].
However, even though the security of the Pedersen hash function is well-understood (since it relies on the assumed hardness of the discrete logarithm problem), a few easily-overlooked subtleties in its definition have the potential to invalidate its security guarantees and thus completely break the security of the systems based on it.
In this blog post, we start by describing the Pedersen hash function, the security guarantees it provides and some of the underlying assumptions it relies on. We then show how some of the security properties can be broken when the requirements are not met. The definition and the different attacks are accompanied by a toy example to illustrate the various concepts more concretely.
Table of Contents
Definition
Let M be the message that we wish to hash (represented as a bit string of fixed length k ⋅ r), and let G1, G2, …, Gk be generators of the prime-order subgroup of our chosen elliptic curve group. These generators must be sampled uniformly at random, such that no relationship between them is known. Split the message M into k chunks of r bits each: M = M1M2 … Mk. The Pedersen hash is defined as the linear combination of the points with the encoding of the message chunks:
H(M) = H(M1M2 … Mk ) = ⟨M1⟩ ⋅ G1 + ⟨M2⟩ ⋅ G2 + … + ⟨Mk⟩ ⋅ Gk
Where the function ⟨⋅⟩, commonly referred to as the encoding function, converts a bit string into a scalar element (for our purpose, scalar can be interpreted as an integer less than the subgroup order).
Note that the output of the hash function defined above is a point on the curve. In practice, the desired output may be a field element, in which case a single coordinate of the resulting point is often used as the hash.
Toy Example: Pedersen Hash Definition
We illustrate the Pedersen Hash function and its security properties and requirements using a toy example, with accompanying code in SageMath. We use an elliptic curve with a prime group order, which is insecure by cryptographic standards due to the prime being small.
We select the elliptic curve defined by the curve equation y2 = x3 + x + 42, defined over the finite field of size 127. The group of points on this curve has order 139, which is prime. We pick two generators of this group, G1 = E(1, 60) and G2 = E(2, 59). Our toy hash function computes the Pedersen hash as follows
H(M) = H(M1 M2) = ⟨M1⟩ ⋅ G1 + ⟨M2⟩ ⋅ G2
Initially, we restrict our message length to be 12 bits, such that the individual message chunks M1 and M2 are 6 bits each.
Additionally, we need to select an encoding function, mapping 6-bit chunks into a scalar. As a first attempt, let us simply interpret the 6-bit value as an integer encoded in little-endian bits, resulting in an integer in the range {0, 63}. We refer to this encoding as the “identity” encoding (IdentityEncode() in the code below).
The following code excerpt first specifies the chosen elliptic curve, picks two generators and defines a few helper functions before defining the GenericPedersenHash() function.
# First we pick an elliptic curve with prime order:
F = GF(127)
E = EllipticCurve(F, [F(1), F(42)])
assert E.order().is_prime()
print(f"{E} with order {E.order()}")
# Elliptic Curve defined by y^2 = x^3 + x + 42 over Finite Field of size 127 with order 139
# We pick two generators. As the curve has prime order, all non-identity points
# are generators
G1 = E(1, 60)
G2 = E(2, 59)
GENERATORS = [G1, G2]
def IdentityEncode(lebs):
"""
Encodes a binary string (assumed to be in little-endian bit order)
to an integer
"""
return int(lebs[::-1], 2)
def EncodeMessage(msg, encode_function):
"""
Helper function which encodes a message given a variable
encode function
"""
return [encode_function(x) for x in msg]
def GenericPedersenHash(generators, encoded_chunks):
"""
Helper function for computing the Pedersen hash of a message
The hash is computed as a linear combination of of the generators with
(already encoded) chunks used as scalar multiples
"""
assert len(generators) == len(encoded_chunks), "Incompatible lengths"
res = E(0)
for chunk, generator in zip(encoded_chunks, generators):
res += chunk * generator
return res
def PedersenHash(message, encode_function=IdentityEncode, generators=GENERATORS):
"""
Computes the Pedersen hash of a message
Input: a message
Output: the Pedersen Hash of the message
Optional:
encode_function: the encoding function to break a message into integers
generators: elements G ∈ E which generate E
"""
encoded_message = EncodeMessage(message, encode_function)
return GenericPedersenHash(generators, encoded_message)Using the above, the code then showcases how the message ["010101", "000111"] is hashed, resulting in the point (3, 31).
# ============================ #
# Example of Pedersen Hash #
# ============================ #
message = ["010101", "000111"] # M = [42, 56]
H = PedersenHash(message)
print(f"Hash of {message} = {H}")
# Hash of ['010101', '000111'] = (3 : 31 : 1)
# We check that the Pedersen hash of the message is equivalent to computing
# the linear combination of the generator points and the integers representations
# of the message chunks
assert H == 42 * G1 + 56 * G2Security Properties and Requirements
The Pedersen Hash function is collision-resistant for fixed-length input, provided the underlying encoding function is injective. This security property and the definition of the hash function presented above have a few subtleties, which we now explore in more depth.
The first caveat is that the hash function is not collision-resistant for variable-length inputs. It is also distinguishable from a random oracle and as such this function should not be used as a pseudorandom function (PRF).
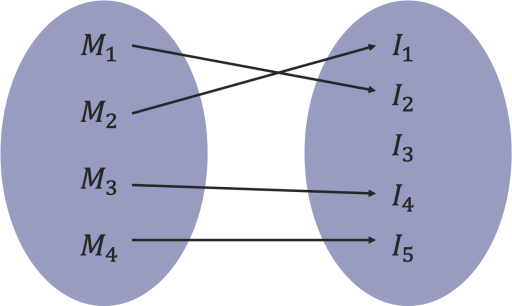
A second important aspect is that in order for this hash function to provide the desired security properties (namely, collision-resistance), it is necessary for the underlying encoding function to be injective. Recall that the property of an injective function is that it maps distinct elements of its domain to distinct elements of its codomain. In the context of the encoding function ⟨⋅⟩, this means that there are no two different message chunks Mi and Mj that result in the same encoded output, see the illustration below.

The encoding function maps bit strings to scalars. In the toy example above, we have seen an example of a simple encoding function where the bit strings were interpreted in little-endian as integers and therefore was clearly injective (within the parameters of our example).
But even with the simple encoding function used in the toy example, care should be taken to ensure that the allowed size of the message we hash is bounded. Indeed, if we allowed larger bit strings to be hashed (such that their encoding is larger than the subgroup order), it would be easy for an attacker to compute collisions. This is because for any point in the subgroup, multiplication by the subgroup order, call it r, yields the point-at-infinity; that is r ⋅ G = 0. Thus, multiplying the point G by a scalar a produces the same result as multiplying G by a + k ⋅ r, for any value of k, since
(a + k ⋅ r) ⋅ G = a ⋅ G + k ⋅ r ⋅ G = a ⋅ G + k ⋅ 0 = a ⋅ G
The example below illustrates how hashing messages larger than the expected size may lead to collisions.
Toy Example: Collisions
Since the subgroup order is 139, adding this quantity (or multiples of it) to the scalar factors of the linear combination performed by the Pedersen hash function results in the same hash output. Equivalently, computing the binary representation of these quantities and hashing them using our toy Pedersen hash function also results in a collision, as shown in the code snippet below.
Notice that the colliding message chunks are larger than 6 bits, further demonstrating that the function is not collision-resistant for variable-length inputs.
# Since the subgroup order is 139, adding this quantity (or multiples of it)
# to the scalar factors of the linear combination computation performed by
# the Pedersen hash function results in the same hash output, as can be seen below.
H2 = (42 + 139) * G1 + (56 + 2 * 139) * G2
assert H == H2
colliding_message = ["10101101", "011100101"]
# Ensures encoding colliding_message results in the integers
# used explicitly above
assert EncodeMessage(colliding_message, IdentityEncode) == [42 + 139, 56 + 2 * 139]
H3 = PedersenHash(colliding_message)
assert H == H3Recall that the output of the hash function is a point on the curve. When implementations require this output to be a field element, they sometimes extract the first coordinate of the resulting curve point, which they use as the output of the hash function. Crucially, this process can also lead to collisions. Indeed, when using a Weierstrass curve with affine coordinates, the negation of a point P = (x, y) is -P = (x, -y). Thus, when computing the Pedersen hash and taking only the first coordinate as a result, there is a natural collision, namely the negation of the point. It is important to ensure that the encoding process followed by the scalar multiplication cannot produce two points that have the same coordinate extracted as output. For example, if using affine coordinates and a curve equation in Weierstrass form, one must ensure that the function cannot produce both P and -P if only the x-coordinate is outputted.
Finally, another important requirement of the Pedersen hash function is that the various generators have to be sampled uniformly at random. Specifically, the discrete logarithm of any generator with respect to another one should not be known, not even to the protocol designers. Implementers traditionally use hash-to-curve algorithms (a process which does not reveal the discrete logarithm of the output point) and nothing-up-my-sleeve numbers, to prove that the inputs to the hash-to-curve process were selected honestly. Odd-looking sets of generators or opaqueness in the generation process could be indicative of a backdoor.
Optimizations
In practice, implementations typically use slightly more complex procedures to encode bit strings to scalar. In doing so, they are able to compute point multiplications in a more efficient way, though special care needs to be taken to ensure the resulting encoding function is injective, as discussed in the previous section.
The simple Pedersen Hash function presented so far can be significantly sped up in the specific contexts used by zero-knowledge proof systems. Since the generators are fixed (and known ahead of time), a method called windowed scalar multiplication can be used to more efficiently perform the multiplication by pre-computing and storing successive powers of the generators.
Windowed scalar multiplication leverages the simple observation that the multiplication of a curve point by a large scalar can be decomposed.
For example, assume our scalar is a 6-bit value b = b0b1b2b3b4b5, and we wish to compute the scalar multiplication b ⋅ G. We have
b ⋅ G = b0 ⋅ G + 2b1 ⋅ G + 22b2 ⋅ G + 23b3 ⋅ G + 24b4 ⋅ G + 25b5 ⋅ G
= (b0 + 2b1 + 22b2) ⋅ G + 23 (b3 + 2b4 + 22b5) ⋅ G
Since the quantities in the parentheses can take any value in the {0, 7} range, one can precompute the eight values in the set {0, G, 2 ⋅ G, 3 ⋅ G, …, 7 ⋅ G} and perform a variant of a double-and-add algorithm, where at each step the doubling operation is repeated 3 times, and the adding operation involves adding one element from the pre-computed set.
This variant uses the same amount of doubling operation as the standard binary double-and-add algorithm, but it uses fewer point additions (which are generally slower than doubling).
Pushing the optimizations even further, the Zcash team decided to use a signed version of the windowed-multiplication method. Specifically, they use a windowed scalar multiplication with an encoding where 3-bit chunks are mapped to elements of the range {-4, …, 4} \ {0}, instead of the range {0, …, 7}.
Nothing forces alternative implementations of the Pedersen Hash to follow the exact same encoding rules, though in practice many do. The encoding function ⟨⋅⟩ defined in the Zcash protocol maps element binary strings of fixed length 3 ⋅ c to a scalar as follows:
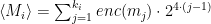
where in turn, the enc() function maps 3-bit chunks m = b0 b1 b2 into elements of the range {-4, …, 4} \ {0} as
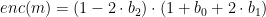
This choice of using a signed-digit windowed-multiplication method reduces the number of constraints necessary in the arithmetic circuit (since the lookup of the negation of a point can be performed efficiently as negating a point only requires a single constraint).
As discussed above, the security of Pedersen hash is guaranteed provided the encoding scheme is injective. Using such a signed representation introduces a few subtleties that should be kept in check in order to ensure the collision-resistance of the hash function. The Zcash team proved (in Theorem 5.4.1. on page 78 of the protocol specifications, see [Zcash]) that the encoding function is indeed injective and thus provides the desired collision-resistance. They did so by showing that the range of the encoding function ⟨⋅⟩ was a subset of the range 

They also ensured that the coordinate extraction procedure couldn’t lead to the issue described above where both a point and its negation could be obtained as the output of the hash procedure, which could be problematic when using the first-coordinate as the hash output. This is described in Section 5.4.9.4 of the Zcash protocol specification [Zcash], where Lemma 5.4.7 shows that if a given point P = (u, v) is on the curve, then (u, -v) is not on the curve, thereby preventing the potential issue outlined.
Note the importance of restricting 0 in the output range of the encoding function. If the zero scalar could be obtained, the result of the scalar multiplication would be the point-at-infinity, which could lead to unexpected issues when trying to use that result.
Now that we have a better understanding of the Pedersen hash and its security, let’s look at some of the attacks that apply if one were to overlook some of the requirements described so far.
Vulnerability 1: Non-unique x-coordinate
In this first vulnerability example, we show how implementations blindly using the x-coordinate of the hash output could lead to collisions.
Instead of using our toy “identity” encoding, we employ Zcash’s signed-digit encoding, which maps bit strings to a range of positive and negative integers centred around 0.
Recall that on a curve in Weierstrass form, the negation of a point P = (x, y) is -P = (x, -y). Considering only the x-coordinate, a collision in the hash function output occurs when two messages result in the pair of points only differing in sign.
By using our toy Pedersen hash example, given a message M whose hash is equal to
H(M) = H(M1 M2) = ⟨M1⟩ ⋅ G1 + ⟨M2⟩ ⋅ G2, the colliding message M’ is computed such that
H(M’) = ⟨M1‘⟩ ⋅ G1 + ⟨M2‘⟩ ⋅ G2
= – H(M) = – (⟨M1⟩ ⋅ G1 + ⟨M2⟩ ⋅ G2)
= – ⟨M1⟩ ⋅ G1 – ⟨M2⟩ ⋅ G2
Hence, to compute a collision for a message M, we have to find the message M′ such that the encoding of the chunks of M′ correspond to the negation of the respective encoded chunks of M, namely ⟨M1′⟩ = −⟨M1⟩ and ⟨M2′⟩ = −⟨M2⟩.
This is straightforward to perform when using Zcash’s encoding scheme, since the third bit of every 3-bit window encoded by the enc() function determines the sign of the output. Hence, given a message hash H(M), the message M’ crafted by flipping every third bit of M produces a hash output equal to the negation of H(M), which coincide in their x-coordinate. The code snippet below illustrates this.
# ========================================== #
# Vulnerability 1 - Non-unique x-coordinate #
# ========================================== #
H = ZcashPedersenHash(message)
print(f"Zcash's Hash of {message} = {H}")
# Zcash's Hash of ['010101', '000111'] = (83 : 83 : 1)
colliding_message = ["011100", "001110"]
H2 = ZcashPedersenHash(colliding_message)
assert H[0] == H2[0]
assert message != colliding_messageNote that this could also happen if using the “identity” encoding used initially in our toy example if we allowed the size of the message chunk range to exceed half the group order.
It is important to repeat that Zcash’s implementation is not susceptible to this issue due to their curve and coordinate choice.
Recall that the original definition requires the generators to be sampled randomly, such that their discrete logarithm with respect to a common generator (or to each other) shall not be known. In practice, standards have been developed for that purpose, see hash-to-curve. Using our toy example, let’s see how an adversary could break the collision-resistance of the hash function if they knew the discrete logarithm of one of the generators with respect to the other one.
Consider the continuation of our example with the two generators G1 = E(1, 60) and G2 = E(2, 59), but with the additional knowledge that G2 = 35 ⋅ G1. Using Zcash’s encoding rules, hashing the message we’ve been using so far, and running our toy example implementation, we can proceed as follows:
# ======================================= #
# Vulnerability 2 - Related Generators #
# ======================================= #
# We know the discrete logarithm of G2 with respect to G1
assert 35 * G1 == G2
message = ["010101", "000111"] # M = [42, 56]
encoded_message = EncodeMessage(message, ZcashEncode)
print(f"Encoded Message: {encoded_message}")
# Encoded Message: [-29, -63]
H = ZcashPedersenHash(message)
assert 129 * G1 == HSince the encoding of our message using Zcash’s encoding function is [-29, -63], the hash of this message corresponds to the linear combination
H(M) = −29 ⋅ G1 − 63 ⋅ G2
However, since we know that G2 = 35 ⋅ G1, we can rewrite the previous equation as
H(M) = −29 ⋅ G1 − 63 ⋅ 35 ⋅ G1 = −2234 ⋅ G1 = 129 ⋅ G1
since -2234 is equal to 129 modulo the group order, 139.
Thus, in order to find a collision, we can simply work in the scalar field and find a solution to the equation
⟨M1⟩ + 35 ⋅ ⟨M2⟩ ≡ 129 mod 139.
One can see the previous equation holds for ⟨M1⟩ = 17 and ⟨M2⟩ = 31. Since Zcash’s encoding is injective, one can decode these values and obtain M1 = "000000", M2 = "001100", which collides with the original message, as shown below.
# We need to find a message M' = M1' || M2' such that
# <M1'> + 35*<M2'> = (-29 -35*63 ) = 129 mod 139
H2 = GenericPedersenHash(GENERATORS, [17, 31])
assert H == H2
H3 = ZcashPedersenHash(["000000", "001100"])
assert H == H3This shows how important it is that the generators be sampled in such a way that no ones knows the discrete logarithm of one with respect to the other one, not even the hash function designers.
Vulnerability 3: Variable-length Input
While implementations usually set a fixed upper bound to the size of the input that can be hashed, they also sometimes accept arbitrary-long (or short) inputs. Zcash’s definition of Pedersen hash is unequivocal regarding the collision-resistance of the hash function when using variable-length input, as stated on page 78 of [Zcash]:
These hash functions are not collision-resistant for variable-length inputs.
One reason why allowing inputs of different sizes to be hashed may result in collisions is that padding is applied to the inputs prior to encoding them. This padding step is sometimes explicit, for example as described in the Zcash protocol specification [Zcash], where the definition of PedersenHashToPoint on page 78 specifies the following padding scheme.
Pad 𝑀 to a multiple of 3 bits by appending zero bits, giving 𝑀′.
But this padding step may also be implicit, such as when using the “identity” encoding and hashing messages of unexpected lengths. In that case, the missing or superfluous bits would simply be interpreted as zeros. We illustrate the issue with our toy example.
In the following code snippet, we see how we can craft a message colliding with msg by trimming or appending zero bits at the end of the message.
# ======================================== #
# Vulnerability 3 - Variable-length Input #
# ======================================== #
message = ["010101", "111000"]
colliding_message = [message[0] + "000", message[1][:3]]
print(f"Colliding Message: {colliding_message}")
# Colliding Message: ['010101000', '111']
assert PedersenHash(colliding_message) == PedersenHash(message)In addition to issues that are exclusively related to padding, the ability to hash larger messages may break injectivity of the function. The toy example in the Definition section also illustrated how hashing messages larger than the expected size may lead to collisions.
Conclusion
While the Pedersen hash function has many desirable advantages due to its simplicity, efficiency in arithmetic circuits, and the known security assumption it relies on, it is also susceptible to many pitfalls. Specifically, implementations adapting the Zcash approach but on different curves or with different encoding schemes may result in fragile constructions vulnerable to subtle issues, as illustrated in this blog post.
The source code is located at https://github.com/ncc-pbottine/ToyPedersenHash/.
Acknowledgements
The author would like to thank Kevin Henry, Aleksandar Kircanski and Giacomo Pope of NCC Group’s Cryptography Services team for their diligent review of this post and Daniele Di Benedetto from Horizen Labs for having drawn our attention to some of the interesting problems described in this blog post. All remaining inaccuracies are the sole responsibility of the author.
References
[Zcash]: Daira Hopwood, Sean Bowe, Taylor Hornby, Nathan Wilcox. Zcash Protocol Specification Version 2022.3.8 [NU5]. September 15, 2022. URL: https://zips.z.cash/protocol/protocol.pdf.
[CHP91]: David Chaum, Eugène van Heijst, and Birgit Pfitzmann. Cryptographically Strong Undeniable Signatures, Unconditionally Secure for the Signer. February 1991. URL: https://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.34.8570.
[Ped91]: Pedersen, T.P. Non-Interactive and Information-Theoretic Secure Verifiable Secret Sharing. 1991. URL: https://doi.org/10.1007/3-540-46766-1_9
如有侵权请联系:admin#unsafe.sh