
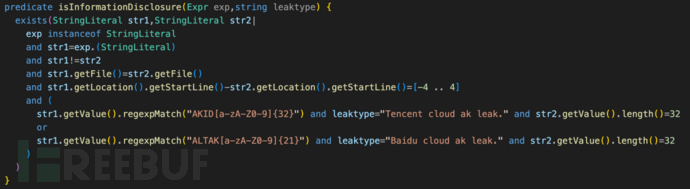
检查硬编码写了一版规则,取相邻4行的字符串,分别命中正则和长度条件时认为是硬编码。而最终在线上运行,却发现大数据库执行一两小时,比流的规则还慢,非常不合理,深入研究发现性能问题。
官方有2份文档关于性能:《QL注释》、《查询性能排查》。并无更多更细的指引,得到几个关键信息:
ql编译时会做编译优化,通过注释可以改变优化逻辑。
ql与sql存在类似的笛卡尔积,条件先后顺序等性能影响因素,但实际优化可能改变条件先后顺序。
ql的谓词实际表现为一张数据库表,执行时异步计算出符合条件的元素,作为表元素。表越大,速度越慢。
2.1 性能日志
Codeql官方并没有提供详细的性能问题定位方法,通过自己摸索,发现通过evaluator log可以看到执行时的时间消耗,获取日志的方法为:
命令行使用codeql database analyze --evaluator-log --tuple-counting输出执行记录,再执行记录转换codeql generate log-summary --format=text -q evaluator.log evaluator.txt
vscode如图操作可查看evaluator log信息
evaluator log的核心信息有2个,一个是predicate时间消耗:
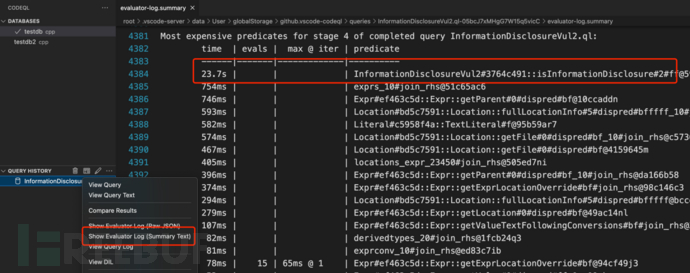
另一个是元组计数,输出每一步语句执行产生的结果数: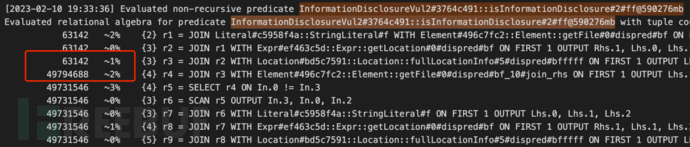
该案例,通过分析日志发现,总耗时39秒,性能损耗最大为InformationDisclosureVul2#3764c491::isInformationDisclosure,达到23.7s,该段逻辑中最大的性能损耗是字符串所在文件的join关联导致的,生成了同文件字符串数两次方的临时数据。
即使把AKID的匹配逻辑放在谓词起始,但经编译优化后,实际执行逻辑依然跟上图一致(优化会改变条件先后顺序),性能损耗严重。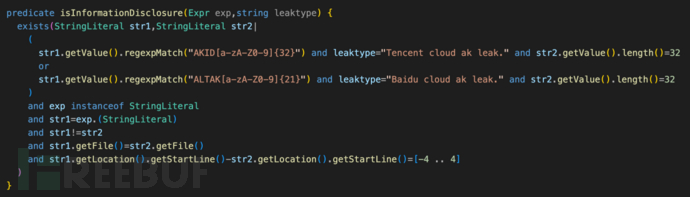

观察ql中间代码可知,导致性能损耗的根本原因是优化后的执行逻辑存在差异:
设想逻辑:找出符合AKID、ALTAK特征的字符串,判断字符串在同个文件,间隔4行内。
计算逻辑:所有字符所在代码行,以文件相同为条件,join关联一次,形成大表,接着计算代码行差间隔4以内,字符串符合AKID、ALTAK特征,得到结果。
提升性能,就需要降低整体计算量。可以通过优化逻辑顺序,添加编译选项、调整代码逻辑等方式实现。对此我使用不同的优化思路,做了不少测试,发现了一些有趣的现象。
3.1减少关联
检测逻辑中,secret长度32是固定的条件,数量有限,可以把逻辑优化成“所有字符所在代码行,以文件相同为条件,关联存在secret的代码行,再进行AKID、ALTAK特征匹配”,代码如下: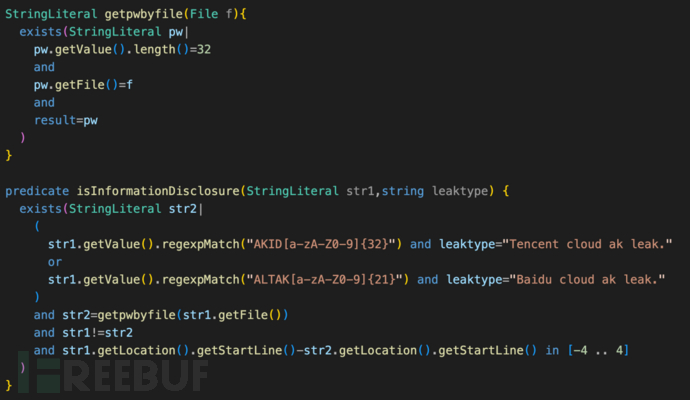
此番优化后,关联的表量级直线下降,总耗时降低到16秒,isInformationDisclosure及getpwbyfile的耗时为169ms、31ms
在大型数据库下运行,性能可以满足要求。但是,该代码不具有通用性,一旦secret不是长度32的字符串,则难以解决。
3.2关闭优化
既然是因为编译优化导致的性能下降,关闭优化也是一种可行的选择,Codeql提供了编译选项pragma[noopt],能禁用谓词内的编译优化,按自己编写的代码逻辑顺序运行。但禁用优化需要同时修改ql代码为“简单的单步执行”代码,类似“三地址IR”的形式。 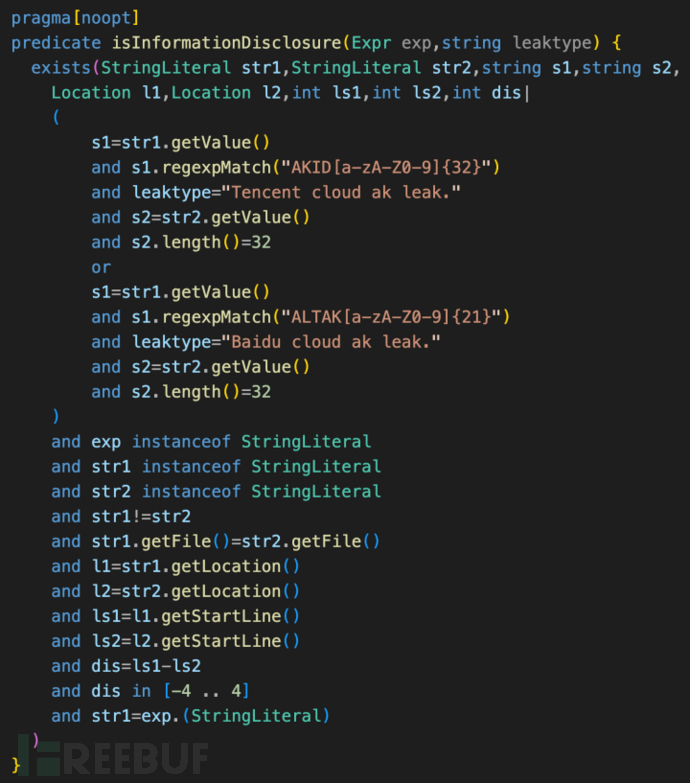
其执行过程也快速简洁得多,字符串匹配不到,后续步骤不再计算。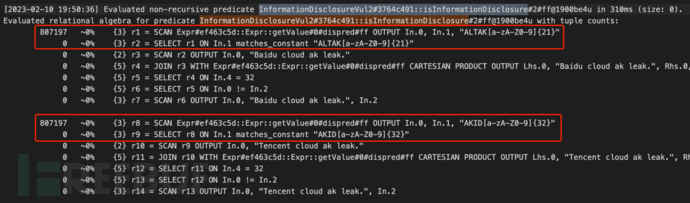
该代码总耗时16秒,isInformationDisclosure执行耗时为310ms。
令人惊讶的是,耗时居然比前面的方法更高。原因分析如下:
减少关联方法:通过文件关联关系,最大元组只有360739个,进一步根据代码行条件剔除,最后需要正则匹配的字符串只有3130个
关闭优化方法:关闭优化后影响类型推断,Codeql从Expr类型中取出总共807197个字符串,全部做正则匹配,消耗较多性能
该例子可以看出,Codeql的语言引擎优化对查询性能的提高,起到非常大的作用,不到万不得已,不要关闭
3.3合并相似逻辑
检查逻辑中,核心是akid、aktak、secret的字符串匹配,将匹配逻辑封在一个谓词,在执行时,会形成一个临时表,后面的字符串位置匹配,复用这张临时表。代码如下: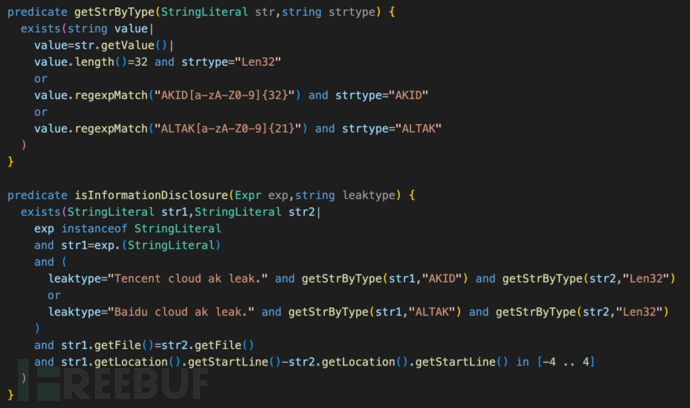
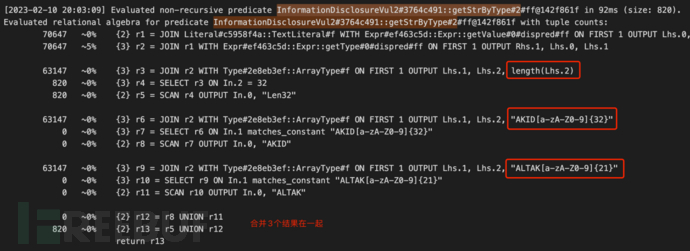

计算过程关联得到的元组数据更少,总耗时16秒,isInformationDisclosure及getStrByType的耗时为1ms、92ms,对比前面的方法,提升数倍。
在实践中,用不少方法提升QL执行性能,汇总如下
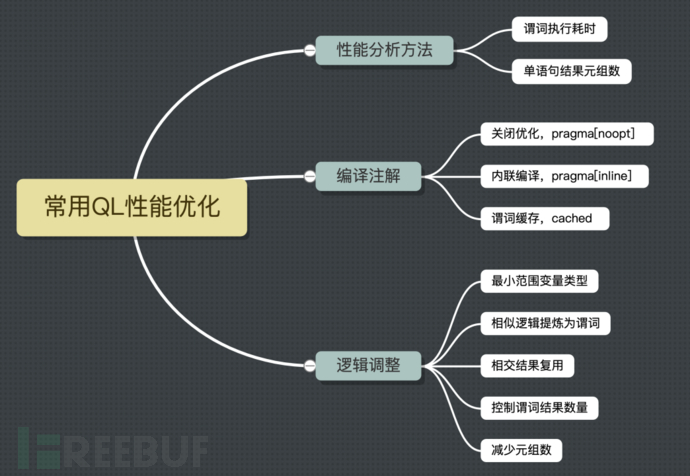
4.1性能分析方法
evaluator log是分析执行性能的日志,其中最需要关注的是谓词执行耗时、及单行语句的结果元组数量,可以快速定位到需要优化的地方。
通过分析元组数较大的位置上下文,理解执行过程,定位到数量“放大”的原因,是接下来优化的关键。
4.2编译注解
关闭优化:
不到万不得已不推荐使用,如果要使用,可以参考正常优化过后的逻辑,转换为QL查询条件,并调节先后顺序,降低元组的数量。
内联编译:
每个谓词,都是独立的计算单元,其初始计算值,是该参数类型的全量表数据,计算完的结果是一个“临时表”,列为谓词的参数。
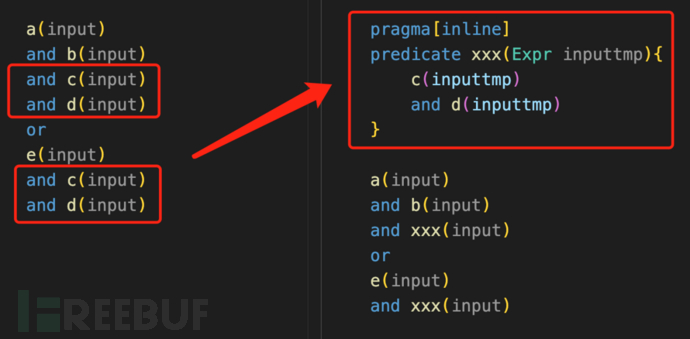
如图,有大量重复代码,提取生成一个谓词更简洁,但有无内联编译注解,差距很大:
无内联编译:对全量的Expr,筛选符合c、d条件,得到一个存有部分Expr的“临时表”,再使用该临时表筛选。谓词单独计算,且Expr数据量大,计算慢。
有内联编译:和左边的ql逻辑一致,input筛选符合a、b条件,元组已经剩余部分,继续筛选符合c、d。input一步步被筛选,元组不断减少。
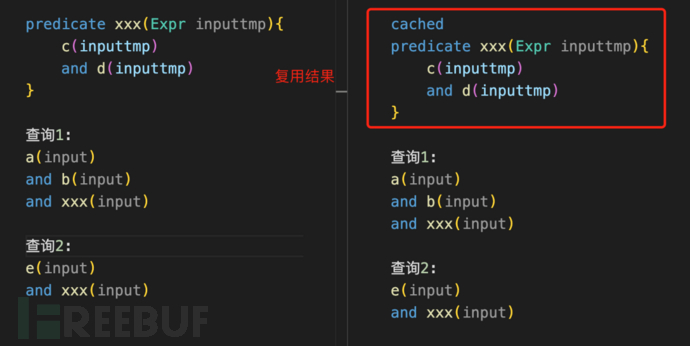
谓词缓存:
谓词计算完的结果是一个“临时表”,ql执行完就没了。但假如多个不同的ql查询都有相同的逻辑,该谓词就重复计算了,只要加上cached,就能在一次查询中,把该结果记录下来,其它查询复用结果。
4.3逻辑调整
最小范围变量类型
例如Call有ExprCall、FunctionCall两个子类型,在ql中,使用Call和FunctionCall对应的元组数差别就很大,使用最小范围的类型,减少元组数,性能更高。
相似逻辑提炼为谓词
前面的"合并相似逻辑"案例,就是一个很好的例子,不过是比较抽象的逻辑上相似。简单点的语句相同,ql编译优化没复用起来,就非常适合提取出来作为单独的谓词。
提炼为谓词的目的,就是为了复用相关逻辑的临时结果。
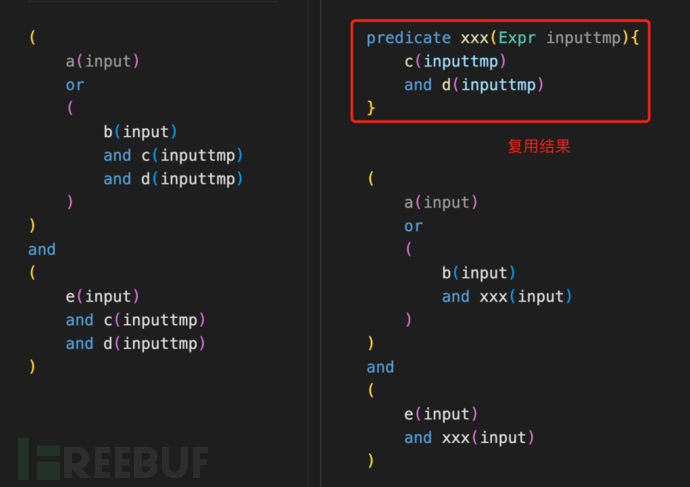
相交结果复用
这个方法尝试是在写sanitizer的时候,发现不同漏洞类型,要打断流的函数各有不同又有不少相似。由于后面还用到dominates,性能消耗极大。
于是把相似部分单独提取出来作为相交部分的结果,减少了部分重复计算。
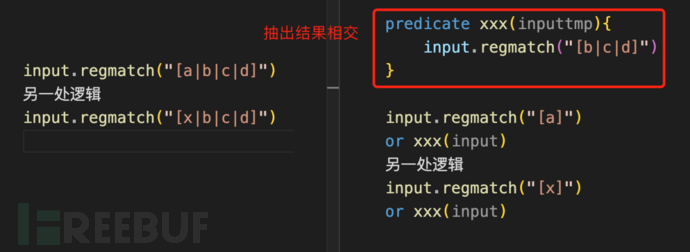
控制谓词结果数量
如前所述,谓词计算完的结果是一个“临时表”,列为谓词的参数。结果越多,后续使用该谓词结果的下一步计算,也会更大。下图例子中,File是少数的,如果是代码行,其计算量将大很多
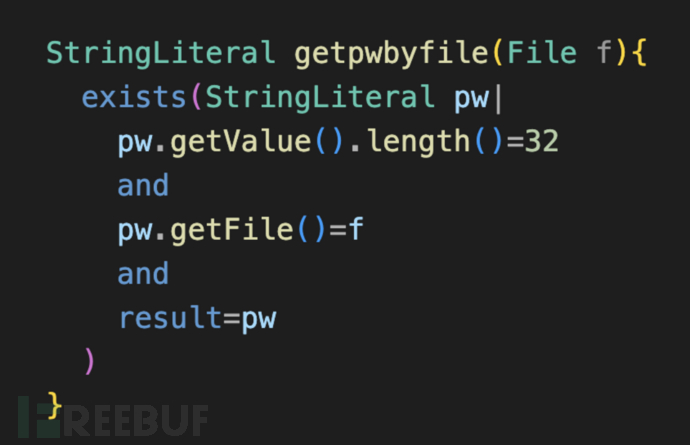
减少元组数
减少元组数的方法有两个方向:
避免元组放大:如前面的“减少关联”案例,把“同文件的字符串”相乘,变成了“字符串”和“同文件secret”相乘,倍数级的减少元组数量。
大幅筛选条件优先:假如A条件可以过滤10%,B条件过滤50%,把B条件前置,能更快速降低元组数量。不过该方法会因编译优化导致顺序调整,适用场景有限。
Codeql规则性能优化,是社区中少人涉及的领域,当前也没有多少资料参考。
在企业内部落地中,规则开发人员掌握程度不一,随着规则复杂程度增加,难以避免的影响规则的健壮性。可能导致性能消耗飙升,出现大量任务失败等情况。因此建立一套扫描耗时监控机制,周期性review并优化规则,也尤为重要。
在实际扫描落地中,我们针对部分高性能消耗的场景优化后,取得了一倍以上效率提升
如有侵权请联系:admin#unsafe.sh