1、主要用于加密机制的协议是()。
SSL
2、向有限的空间输入超长的字符串是哪一种攻击手段?
缓冲区溢出
3、为了防御网络监听,最常用的方法是
信息加密
4、使网络服务器中充斥着大量要求回复的信息,消耗带宽,导致网络或系统停止正常服务,这属于什么攻击类型?
BIND漏洞
5、用户收到了一封可疑的电子邮件,要求用户提供银行账户及密码,这是属于何种攻击手段?
钓鱼攻击
6、Windows NT 和Windows Server系统能设置为在几次无效登录后锁定帐号,这可以防止
暴力攻击
7、下列不属于系统安全的技术是( )
认证
8、以下关于DOS攻击的描述,哪句话是正确的?( )
导致目标系统无法处理正常用户的请求
9、许多黑客攻击都是利用软件实现中的缓冲区溢出的漏洞,对于这一威胁,最可靠的解决方案是什么?( )
给系统安装最新的补丁
10、下面哪个功能属于操作系统中的日志记录功能( )
对计算机用户访问系统和资源的情况进行记录
11、邮件炸弹攻击主要是( )
添满被攻击者邮箱
12、故意制作、传播计算机病毒等破坏性程序,影响计算机系统正常运行,后果严重的,将受到____处罚
处五年以下有期徒刑或者拘役
13、网络物理隔离是指( )
两个网络间链路层、网络层在任何时刻都不能直接通讯
14、VPN是指( )
虚拟的协议网络
15、NAT 是指( )
网络地址转换
16、局域网内如果一个计算机的IP地址与另外一台计算机的IP地址一样,则( )
两台计算机都无法通讯
17、一台交换机具有48个10/100Mbps端口和2个1000Mbps端口,如果所有端口都工作在全双工状态,那么交换机总带宽应为( )
13.6Gbps
18、IP地址块211.64.0.0/11的子网掩码可写为 ( )
255.224.0.0
19、某企业产品部的IP地址块为211.168.15.192/26,市场部的为211.168.15.160/27,财务部的为211.168.15.128/27,这三个地址块经聚合后的地址为
211.168.15.128/25
20、下列对IPv6地址FF23:0:0:0:0510:0:0:9C5B的简化表示中,错误的是 ( )
FF23:0:0:0:051::9C5B
1.key在哪里
url:http://lab1.xseclab.com/base1_4a4d993ed7bd7d467b27af52d2aaa800/index.php
查看网页源代码的方式有4种,分别是:1、鼠标右击会看到”查看源代码“,这个网页的源代码就出现在你眼前了;2、可以使用快捷Ctrl+U来查看源码;3、在地址栏前面加上view-source,如view-source:https://www.baidu.com ; 4、浏览器的设置菜单框中,找到“更多工具”,然后再找开发者工具,也可以查看网页源代码。
这道题明显考查查看源代码的方式,右键审查元素
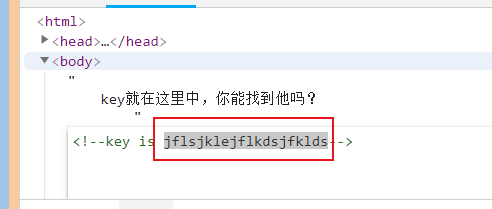
key is jflsjklejflkdsjfklds
2.ROT13加密
url:http://hackinglab.cn/ShowQues.php?type=bases
根据题意,“再加密一次”判断是ROT-13
ROT13是它自己本身的逆反;也就是说,要还原ROT13,套用加密同样的算法即可得,故同样的操作可用再加密与解密
使用在线解密工具
xrlvf23xfqwsxsqf 把数据复制过去,点击下方的按钮
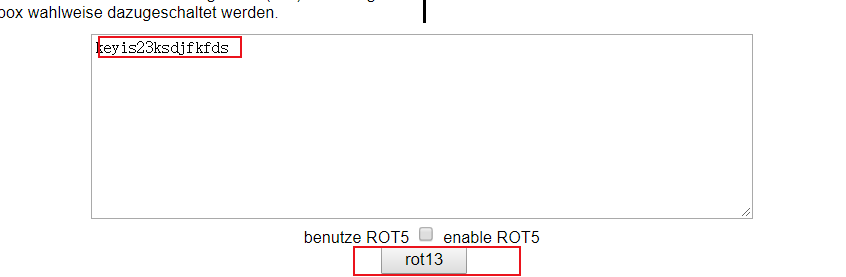
key is 23ksdjfkfds
3.base64 加密
url:http://hackinglab.cn/ShowQues.php?type=bases
因为后面有“=”初次判断为base64
BASE64:是一种基于64个可打印字符来表示二进制数据的表示方法。Base64编码要求把3个8位字节(38=24)转化为4个6位的字节(46=24),之后在6位的前面补两个0,形成8位一个字节的形式,Base64的尾部填充用的是“=”号,只是用来补足位数的,以四个字符为一个块,最末尾不足四个字符的用“=”号填满。
base64,base32,base16的区别:
base64中包含大写字母(A-Z)、小写字母(a-z)、数字0——9以及+/;
base32中只有大写字母(A-Z)和数字234567
base16中包含了数字(0-9)和大写字母(A~F)
根据加密后的字符串所以只能是base64
第一种方法:使用base64在线解密工具
http://tool.oschina.net/encrypt?type=3
把加密后的字符串复制黏贴到右边,进行解密
点击 BASE64解码,发现没有出来没发现key.
再次解密!!!!复制左面的面的编码粘贴至右面再次解码!!!一直复制粘贴出来key为止
进行了20次的复制黏贴,终于得到了!

key is jkljdkl232jkljkdl2389
第二种方法:使用php脚本
<?php $data = "ba64加密的代码..."; $num = 0; for ($i=0; $i < 1000; $i++) { $data2 = base64_decode($data); $data = base64_decode($data2); echo $data."<br/>";//不是$data就是$data2;两个随便输出一个就行了。 }
第三种方法:使用python脚本
第一个脚本:python3
#base64模块,专门用作base64编码解码的。 import base64 # 加密解密函数 def encrypt_decrypt(string): #首先,Base64生成的编码都是ascii字符。其次,python3中字符都为unicode编码,而b64encode函数的参数为byte类型,所以必须先转码。 #将字符串转换成bytes 编码格式utf-8 #编码可以将抽象字符以二进制数据的形式表示,有很多编码方法,如utf-8、gbk等,可以使用encode()函数对字符串进行编码,转换成二进制字节数据,也可用decode()函数将字节解码成字符串;用decode()函数解码,可不要用指定编码格式; #m查看循环次数 m = 0 #把string通过encode()进行转换 bytesString = string.encode(encoding='utf-8') #使用了try···except···finally····捕获异常 try: while True: m += 1 decodeStr = base64.b64decode(bytesString) #赋值 bytesString = decodeStr #发生异常则输出这个 except Exception: #decode()方法以encoding指定的编码格式解码字符串,默认编码为字符串编码 print('base64解码后的字符串:', decodeStr.decode()) #无论try是否异常,finally总会执行 finally: print(m) #程序的入口main ,作用:防止在被其他文件导入时显示多余的程序主体部分。 if __name__ == '__main__': #测试数据 encrypt_decrypt('字符串')
第二个脚本:python2
import base64 s = "加密后的字符串" a = 0 try: while True: s = base64.decodestring(s) a += 1 except Exception: print s print a
4.MD5加密
url:http://hackinglab.cn/ShowQues.php?type=bases
使用md5在线解密
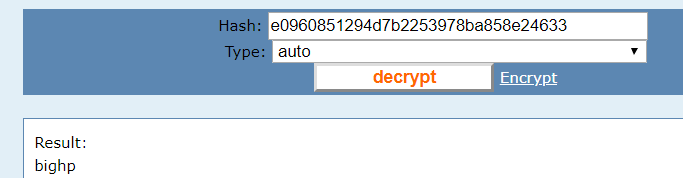
bighp
5.种族歧视
url:http://lab1.xseclab.com/base1_0ef337f3afbe42d5619d7a36c19c20ab/index.php
第一种方法:burp抓包
发现语言,因为这个网站只能让外国人进,所以把语言换成en-US
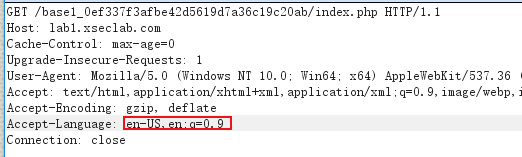
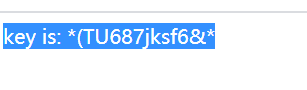
放包,得到key is: *(TU687jksf6&*
第二种方法:使用Python3脚本
import urllib,urllib.request headers = { "Accept-Language": "en-US,en;q=0.9", 'User-Agent': "HAHA" } def getpage(path): # 抓取网页源代码 # data = urllib.request.urlopen(path).read().decode("gbk", "ignore") # 中文网页 # return data request = urllib.request.Request(url=path, headers=headers) # 冒充其他浏览器 response = urllib.request.urlopen(request) # 会话,打开网页 data = response.read().decode("utf-8", "ignore") # 读取网页并且编码 return data print(getpage('http://lab1.xseclab.com/base1_0ef337f3afbe42d5619d7a36c19c20ab/index.php'))# 网址自行更换
6.HAHA浏览器
url:http://lab1.xseclab.com/base6_6082c908819e105c378eb93b6631c4d3/index.php
第一种方法:burp抓包
发现有浏览器信息,那我们把浏览器改成HAHA

放包,得到key is: meiyouHAHAliulanqi

第二种方法:使用Python3脚本
import urllib,urllib.request headers = { "Accept-Language": "en-US,en;q=0.9", 'User-Agent': "HAHA" } def getpage(path): # 抓取网页源代码 # data = urllib.request.urlopen(path).read().decode("gbk", "ignore") # 中文网页 # return data request = urllib.request.Request(url=path, headers=headers) # 冒充其他浏览器 response = urllib.request.urlopen(request) # 会话,打开网页 data = response.read().decode("utf-8", "ignore") # 读取网页并且编码 return data print(getpage('http://lab1.xseclab.com/base6_6082c908819e105c378eb93b6631c4d3/index.php'))# 网址自行更换
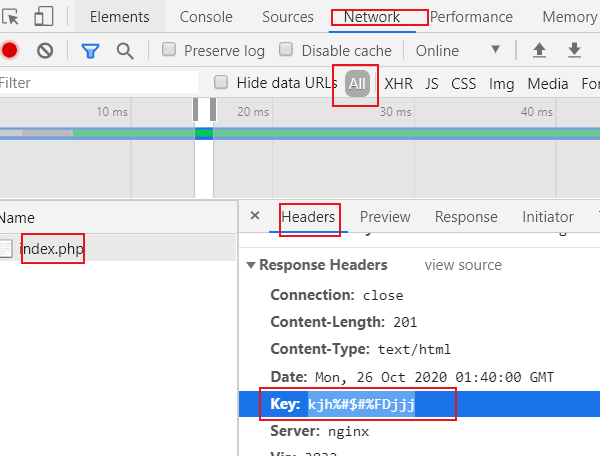
7.key究竟在哪里呢?
第一种方法:右键审查元素,得到Key: kjh%#$#%FDjjj
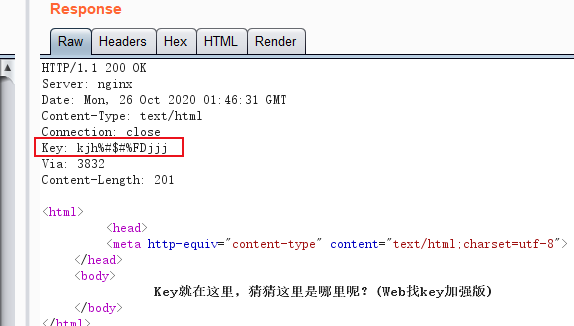
第二种方法:burp抓包,发送到重放模块,点击go,得到Key: kjh%#$#%FDjjj
8.key又找不到了
url:http://lab1.xseclab.com/base8_0abd63aa54bef0464289d6a42465f354/index.php
点击到这里找key,抓包重放,得到./key_is_herenow.php
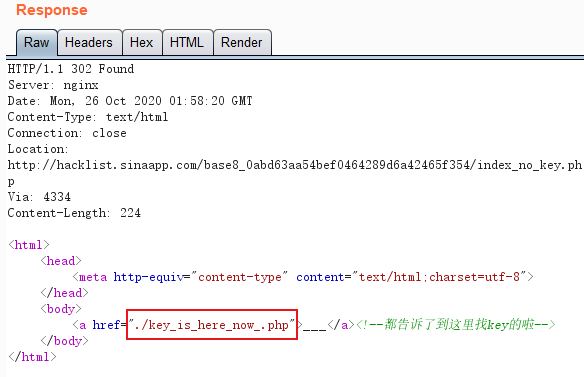
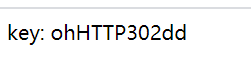
访问http://lab1.xseclab.com/base8_0abd63aa54bef0464289d6a42465f354/key_is_here_now_.php
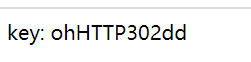
得到key: ohHTTP302dd
9.冒充登陆用户
url:http://lab1.xseclab.com/base9_ab629d778e3a29540dfd60f2e548a5eb/index.php
第一种方法:burp抓包,cookie里的login参数改为1
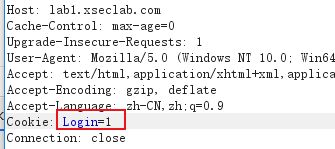
得到key is: yescookieedit7823789KJ

第二种方法:使用python3脚本
import urllib,urllib.request headers = { "Accept-Language": "en-US,en;q=0.9", 'Cookie': "Login=1" } def getpage(path): # 抓取网页源代码 # data = urllib.request.urlopen(path).read().decode("gbk", "ignore") # 中文网页 # return data request = urllib.request.Request(url=path, headers=headers) # 冒充其他浏览器 response = urllib.request.urlopen(request) # 会话,打开网页 data = response.read().decode("utf-8", "ignore") # 读取网页并且编码 return data print(getpage('http://lab1.xseclab.com/base9_ab629d778e3a29540dfd60f2e548a5eb/index.php'))# 网址自行更换
10.比较数字大小
url:http://lab1.xseclab.com/base10_0b4e4866096913ac9c3a2272dde27215/index.php
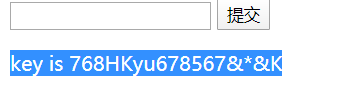
第一种方法,右键审查元素,前端验证,发现在框里最大长度是3,如图修改

输入9999,得到key is 768HKyu678567&*&K
第二种方法,burp抓包,直接输9999即可

11.本地的诱惑
url:http://lab1.xseclab.com/base11_0f8e35973f552d69a02047694c27a8c9/index.php
第一种方法:审查元素,得到key is ^&*(UIHKJjkadshf
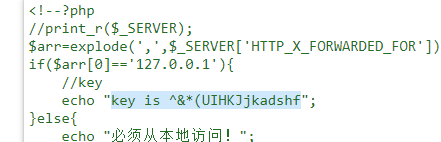
第二种方法,必须本地访问,burp抓包,在 Request 中加入请求头 X-Forwarded-For: 127.0.0.1 ,得到key is ^&*(UIHKJjkadshf

注:X-Forwarded-For:简称XFF头,它代表客户端,也就是HTTP的请求端真实的IP,只有在通过了HTTP 代理或者负载均衡服务器时才会添加该项。它不是RFC中定义的标准请求头信息,在squid缓存代理服务器开发文档中可以找到该项的详细介绍。标准格式如下:X-Forwarded-For: client1, proxy1, proxy2。
12.就不让你访问
url:http://lab1.xseclab.com/base12_44f0d8a96eed21afdc4823a0bf1a316b/index.php
查看robots.txt,http://lab1.xseclab.com/base12_44f0d8a96eed21afdc4823a0bf1a316b/robots.txt
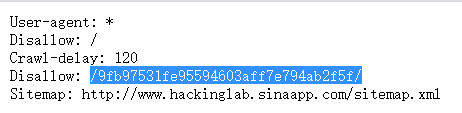
注:disallow 一般是用在robots.txt中的。表示禁止搜索引擎抓取。
Disallow,正是robots.txt文件中设置禁止搜索引擎收录哪些目录的一个词语。
访问http://lab1.xseclab.com/base12_44f0d8a96eed21afdc4823a0bf1a316b/9fb97531fe95594603aff7e794ab2f5f/

得到right! key is UIJ%%IOOqweqwsdf
文笔生疏,措辞浅薄,望各位大佬不吝赐教,万分感谢。
免责声明:由于传播或利用此文所提供的信息、技术或方法而造成的任何直接或间接的后果及损失,均由使用者本人负责, 文章作者不为此承担任何责任。
转载声明:儒道易行 拥有对此文章的修改和解释权,如欲转载或传播此文章,必须保证此文章的完整性,包括版权声明等全部内容。未经作者允许,不得任意修改或者增减此文章的内容,不得以任何方式将其用于商业目的。
如有侵权请联系:admin#unsafe.sh