点击上方蓝字谈思实验室
获取更多汽车网络安全资讯
我相信大家刚开始学socket的时候,都跟我一样。
云里雾里的,对socket的概念很模糊。
这篇文章我打算从一个初学者的角度开始聊起,让大家了解下我眼里的socket是什么以及socket的原理和内核实现。
socket的概念
故事要从一个插头说起。
当我将插头插入插座,那看起来就像是将两者连起来了。
而插座的英文,又叫socket。
巧了,我们程序员搞网络编程时也会用到一个叫socket的东西。
其实两者非常相似。通过socket,我们可以与某台机子建立"连接",建立"连接"的过程,就像是将插口插入插槽一样。
大概概念是了解了,但我相信各位对socket其实还是很模糊。
我们从大家最熟悉的使用场景开始说起。
socket的使用场景
我们想要将数据从A电脑的某个进程发到B电脑的某个进程。
这时候我们需要选择将数据发过去的方式,如果需要确保数据要能发给对方,那就选可靠的TCP协议,如果数据丢了也没关系,看天意,那就选择不可靠的UDP协议。
初学者毫无疑问,首选TCP。
那这时候就需要用socket进行编程。
于是第一步就是创建个关于TCP的socket。就像下面这样。
sock_fd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);这个方法会返回socket_fd,它是socket文件的句柄,是个数字,相当于socket的身份证号。
得到了socket_fd之后,对于服务端,就可以依次执行bind(), listen(), accept()方法,然后坐等客户端的连接请求。
对于客户端,得到socket_fd之后,你就可以执行connect()方法向服务端发起建立连接的请求,此时就会发生TCP三次握手。
连接建立完成后,客户端可以执行send() 方法发送消息,服务端可以执行recv()方法接收消息,反过来,服务器也可以执行send(),客户端执行recv()方法。
到这里为止,就是我们大部分程序员最熟悉的使用场景。
socket的设计
现在,socket我们见过,也用过,但对大部分程序员来说,它是个黑盒。
那既然是黑盒,我们索性假设我们忘了socket。重新设计一个内核网络传输功能。
网络传输,从操作上来看,无非就是,发数据和远端之间互相收发数据。也就是对应着写数据和读数据。
但显然,事情没那么简单。
这里还有两个问题。
第一个是,接收端和发送端可能不止一个,因此我们需要一些信息做下区分,这个大家肯定很熟悉,可以用IP和端口。IP用来定位是哪台电脑,端口用来定位是这台电脑上的哪个进程。
第二个是,发送端和接收端的传输方式有很多区别,可以是可靠的TCP协议,也可以是不可靠的UDP协议,甚至还需要支持基于icmp协议的ping命令。
sock是什么
写过代码的都知道,为了支持这些功能,我们需要定义一个数据结构去支持这些功能。
这个数据结构,叫sock。
为了解决上面的第一个问题,我们可以在sock里加入IP和端口字段。
而第二个问题,我们会发现这些协议虽然各不相同,但还是有一些功能相似的地方,比如收发数据时的一些逻辑完全可以复用。按面向对象编程的思想,我们可以将不同的协议当成是不同的对象类(或结构体),将公共的部分提取出来,通过"继承"的方式,复用功能。
基于各种sock实现网络传输功能
于是,我们将功能重新划分下,定义了一些数据结构。
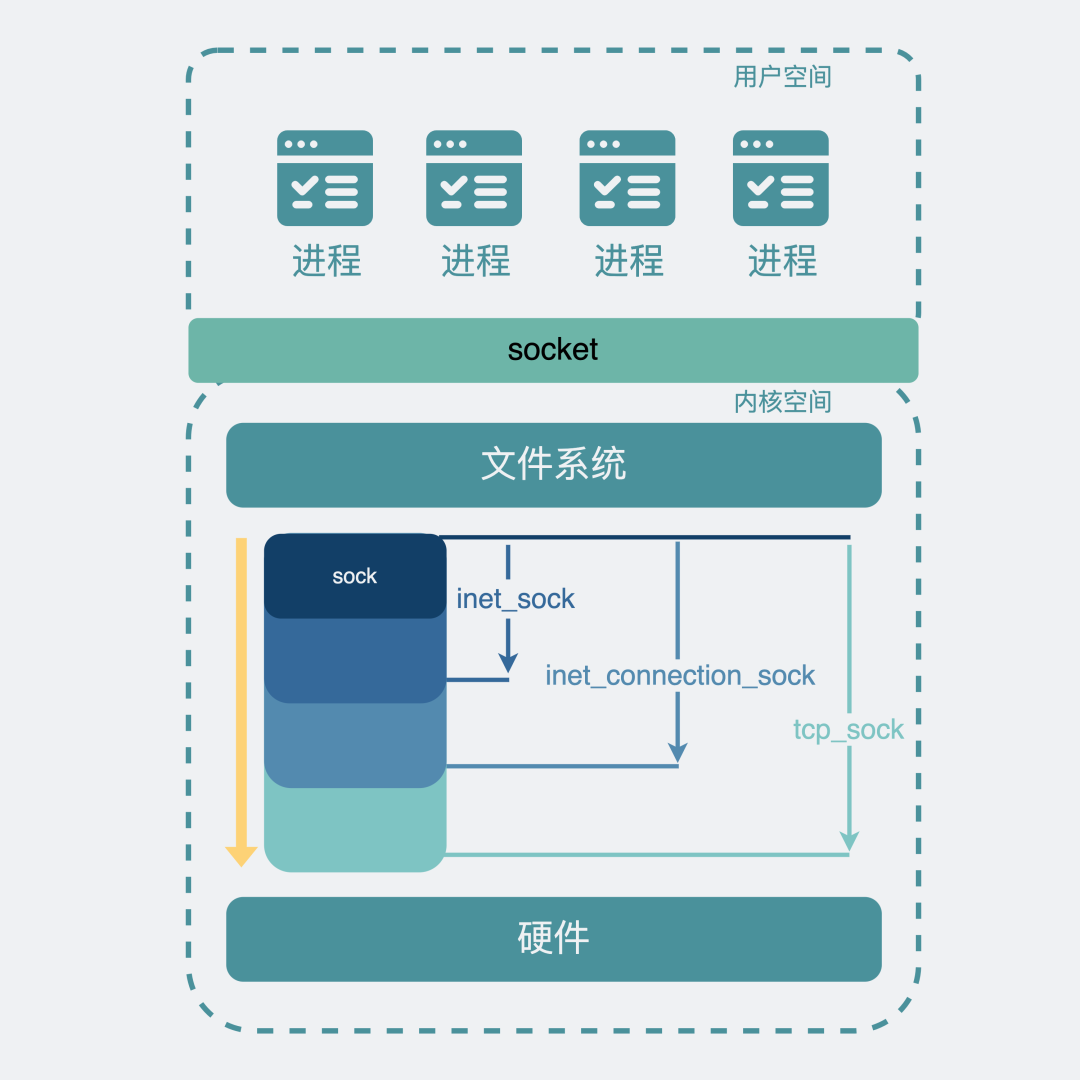
sock是最基础的结构,维护一些任何协议都有可能会用到的收发数据缓冲区。
inet_sock特指用了网络传输功能的sock,在sock的基础上还加入了TTL,端口,IP地址这些跟网络传输相关的字段信息。说到这里大家就懵了,难道还有不是用网络传输的?有,比如Unix domain socket,用于本机进程之间的通信,直接读写文件,不需要经过网络协议栈。这是个非常有用的东西,我以后一定讲讲(画饼)。
inet_connection_sock 是指面向连接的sock,在inet_sock的基础上加入面向连接的协议里相关字段,比如accept队列,数据包分片大小,握手失败重试次数等。虽然我们现在提到面向连接的协议就是指TCP,但设计上linux需要支持扩展其他面向连接的新协议,
tcp_sock 就是正儿八经的tcp协议专用的sock结构了,在inet_connection_sock基础上还加入了tcp特有的滑动窗口、拥塞避免等功能。同样udp协议也会有一个专用的数据结构,叫udp_sock。
好了,现在有了这套数据结构,我们将它们跟硬件网卡对接一下,就实现了网络传输的功能。
提供socket层
可以想象得到,这里面的代码肯定非常复杂,同时还操作了网卡硬件,需要比较高的操作系统权限,再考虑到性能和安全,于是决定将它放在操作系统内核里。
既然网络传输功能做在内核里,那用户空间的应用程序想要用这部分功能的话,该怎么办呢?
这个好办,本着不重复造轮子的原则,我们将这部分功能抽象成一个个简单的接口。以后别人只需要调用这些接口,就可以驱动我们写好的这一大堆复杂的数据结构去发送数据。
那么问题来了,怎么样将这部分功能暴露出去呢?让其他程序员更方便的使用呢?
既然跟远端服务端进程收发数据可以抽象为“读和写”,操作文件也可以抽象为"读和写",正好有句话叫,"linux里一切皆是文件",那我们索性,将内核的sock封装成文件就好了。创建sock的同时也创建一个文件,文件有个句柄fd,说白了就是个文件系统里的身份证号码,通过它可以唯一确定是哪个sock。
这个文件句柄fd其实就是
sock_fd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP)里的sock_fd。
将句柄暴露给用户,之后用户就可以像操作文件句柄那样去操作这个sock句柄。在用户空间里操作这个句柄,文件系统就会将操作指向内核sock结构。
是的,操作这个特殊的文件就相当于操作内核里对应的sock。
有了sock_fd句柄之后,我们就需要提供一些接口方法,让用户更方便的实现特定的网络编程功能。这些接口,我们列了一下,发现需要有send(),recv(),bind(), listen(),connect()这些。到这里,我们的内核网络传输功能就算设计完成了。
现在是不是眼熟了,上面这些接口方法其实就是socket提供出来的接口。
所以说,socket其实就是个代码库 or 接口层,它介于内核和应用程序之间,提供了一些高度封装过的接口,让我们去使用内核网络传输功能。
到这里,我们应该明白了。我们平时写的应用程序里代码里虽然用了socket实现了收发数据包的功能,但其实真正执行网络通信功能的,不是应用程序,而是linux内核。相当于应用程序通过socket提供的接口,将网络传输的这部分工作外包给了linux内核。
这听起来像不像我们最熟悉的前后端分离的服务架构,虽然这么说不太严谨,但看上去linux就像是被分成了应用程序和内核两个服务。内核就像是后端,暴露了好多个api接口,其中一类就是socket的send()和recv()这些方法。应用程序就像是前端,负责调用内核提供的接口来实现想要的功能。
看到这里,我担心大家会有点混乱,来做个小的总结。
在操作系统内核空间里,实现网络传输功能的结构是sock,基于不同的协议和应用场景,会被泛化为各种类型的xx_sock,它们结合硬件,共同实现了网络传输功能。为了将这部分功能暴露给用户空间的应用程序使用,于是引入了socket层,同时将sock嵌入到文件系统的框架里,sock就变成了一个特殊的文件,用户就可以在用户空间使用文件句柄,也就是socket_fd来操作内核sock的网络传输能力。
这个socket_fd是一个int类型的数字。现在回去看socket的中文翻译,套接字,我将它理解为一套用于连接的数字,是不是就觉得特别合理了。
socket如何实现网络通信
上面关于怎么实现网络通信功能这一块一笔带过了。
现在我们来聊聊。
这套sock的结构其实非常复杂。我们以最常用的TCP协议为例,简单了解下它是怎么实现网络传输功能的。
我将它分为两阶段,分别是建立连接和数据传输。
建立连接
对于TCP,要传数据,就得先在客户端和服务端中间建立连接。
在客户端,代码执行socket提供的connect(sockfd, "ip:port")方法时,会通过sockfd句柄找到对应的文件,再根据文件里的信息指向内核的sock结构。通过这个sock结构主动发起三次握手。
在服务端握手次数还没达到"三次"的连接,叫半连接,完成好三次握手的连接,叫全连接。它们分别会用半连接队列和全连接队列来存放,这两个队列会在你执行listen()方法的时候创建好。当服务端执行accept()方法时,就会从全连接队列里拿出一条全连接。
至此,连接就算准备好了,之后,就可以开始传输数据。
虽然都叫队列,但半连接队列其实是个hash表,而全连接队列其实是个链表。
那么问题来了,为什么半连接队列要设计成哈希表而全连接队列是个链表?这个在我在我之前写的《没有accept,能建立TCP连接吗?》 已经提到过,不再重复。
数据传输
为了实现发送和接收数据的功能,sock结构体里带了一个发送缓冲区和一个接收缓冲区,说是缓冲区,但其实就是个链表,上面挂着一个个准备要发送或接收的数据。
当应用执行send()方法发送数据时,同样也会通过sock_fd句柄找到对应的文件,根据文件指向的sock结构,找到这个sock结构里带的发送缓冲区,将数据会放到发送缓冲区,然后结束流程,内核看心情决定什么时候将这份数据发送出去。
接收数据流程也类似,当数据送到linux内核后,数据不是立马给到应用程序的,而是先放在接收缓冲区中,数据静静躺着,卑微的等待应用程序什么时候执行recv()方法来拿一下。就像我的文章,躺在你的推文列表里,卑微的等一个点赞关注转发三连。懂?
IP和端口其实不在sock下,而在inet_sock下,上面这么画只是为了简化。。。
那么问题来了,发送数据是应用程序主动发起,这个大家都没问题。
那接收数据呢?数据从远端发过来了,怎么通知并给到应用程序呢?
这就需要用到等待队列。
当你的应用进程执行recv()方法尝试获取(阻塞场景下)接收缓冲区的数据时。
• 如果有数据,那正好,取走就好了。这点没啥疑问。
• 但如果没数据,就会将自己的进程信息注册到这个sock用的等待队列里,然后进程休眠。如果这时候有数据从远端发过来了,数据进入到接收缓冲区时,内核就会取出sock的等待队列里的进程,唤醒进程来取数据。
有时候,你会看到多个进程通过fork的方式,listen了同一个socket_fd。在内核,它们都是同一个sock,多个进程执行listen()之后,都嗷嗷等待连接进来,所以都会将自身的进程信息注册到这个socket_fd对应的内核sock的等待队列中。如果这时真来了一个连接,是该唤醒等待队列里的哪个进程来接收连接呢?这个问题的答案比较有趣。
• 在linux 2.6以前,会唤醒等待队列里的所有进程。但最后其实只有一个进程会处理这个连接请求,其他进程又重新进入休眠,这些被唤醒了又无事可做最后只能重新回去休眠的进程会消耗一定的资源。就好像你在广东的街头,想问路,叫一声靓仔,几十个人同时回头,但你其实只需要其中一个靓仔告诉你路该怎么走。你这种一不小心惊动这群靓仔的场景,在计算机领域中,就叫惊群效应。
• 在linux 2.6之后,只会唤醒等待队列里的其中一个进程。是的,socket监听的惊群效应问题被修复了。
看到这里,问题又来了。
服务端 listen 的时候,那么多数据到一个 socket 怎么区分多个客户端的?
以TCP为例,服务端执行listen方法后,会等待客户端发送数据来。客户端发来的数据包上会有源IP地址和端口,以及目的IP地址和端口,这四个元素构成一个四元组,可以用于唯一标记一个客户端。
其实说四元组并不严谨,因为过程中还有很多其他信息,也可以说是五元组。。。但大概理解就好,就这样吧。。。
服务端会创建一个新的内核sock,并用四元组生成一个hash key,将它放入到一个hash表中。
下次再有消息进来的时候,通过消息自带的四元组生成hash key再到这个hash表里重新取出对应的sock就好了。所以说服务端是通过四元组来区分多个客户端的。
sock怎么实现"继承"
最后遗留一个问题。
大家都知道linux内核是C语言实现的,而C语言没有类也没有继承的特性,是怎么做到"继承"的效果的呢?
在C语言里,结构体里的内存是连续的,将要继承的"父类",放到结构体的第一位,就像下面这样。
struct tcp_sock {
/* inet_connection_sock has to be the first member of tcp_sock */
struct inet_connection_sock inet_conn;
// 其他字段
}struct inet_connection_sock {
/* inet_sock has to be the first member! */
struct inet_sock icsk_inet;
// 其他字段
}
然后我们就可以通过结构体名的长度来强行截取内存,这样就能转换结构体,从而实现类似"继承"的效果。
// sock 转为 tcp_sock
static inline struct tcp_sock *tcp_sk(const struct sock *sk)
{
return (struct tcp_sock *)sk;
}
总结
• socket中文套接字,我理解为一套用于连接的数字。并不一定准确,欢迎评论。
• sock在内核,socket_fd在用户空间,socket层介于内核和用户空间之间。
• 在操作系统内核空间里,实现网络传输功能的结构是sock,基于不同的协议和应用场景,会被泛化为各种类型的xx_sock,它们结合硬件,共同实现了网络传输功能。为了将这部分功能暴露给用户空间的应用程序使用,于是引入了socket层,同时将sock嵌入到文件系统的框架里,sock就变成了一个特殊的文件,用户就可以在用户空间使用文件句柄,也就是socket_fd来操作内核sock的网络传输能力。
• 服务端可以通过四元组来区分多个客户端。
• 内核通过c语言"结构体里的内存是连续的"这一特点实现了类似继承的效果。
码上报名
WISS 2023 第四届世界物联网安全及数据安全治理峰会火热报名中,3月9-10日,上海
码上报名
AutoSec 7周年年会暨中国汽车网络安全及数据安全合规峰会,5月10-11日,上海
更多文章
会员权益: (点击可进入)谈思实验室VIP会员
END
微信入群
谈思实验室专注智能汽车信息安全、预期功能安全、自动驾驶、以太网等汽车创新技术,为汽车行业提供最优质的学习交流服务,并依托强大的产业及专家资源,致力于打造汽车产业一流高效的商务平台。
每年谈思实验室举办数十场线上线下品牌活动,拥有数十个智能汽车创新技术的精品专题社群,覆盖BMW、Daimler、PSA、Audi、Volvo、Nissan、广汽、一汽、上汽、蔚来等近百家国内国际领先的汽车厂商专家,已经服务上万名智能汽车行业上下游产业链从业者。专属社群有:信息安全、功能安全、自动驾驶、TARA、渗透测试、SOTIF、WP.29、以太网、物联网安全等,现专题社群仍然开放,入满即止。
扫描二维码添加微信,根据提示,可以进入有意向的专题交流群,享受最新资讯及与业内专家互动机会。
谈思实验室,为汽车科技赋能,推动产业创新发展!
如有侵权请联系:admin#unsafe.sh