文章首发于:奇安信攻防社区https://forum.butian.net/share/2068环境搭建源码:https://www.ujcms.com/uploads/jspxcms-9.0.0-r 2023-1-5 08:52:33 Author: 亿人安全(查看原文) 阅读量:51 收藏
文章首发于:奇安信攻防社区
https://forum.butian.net/share/2068
环境搭建
源码:https://www.ujcms.com/uploads/jspxcms-9.0.0-release-src.zip
下载之后解压
然后用idea导入
先创建数据库导入数据库文件
然后导入源码
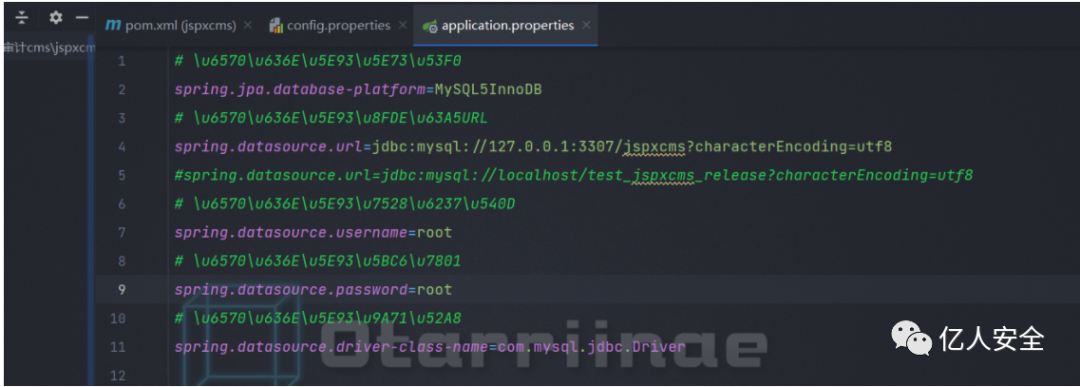
然后配置好数据库连接
加载maven依赖
根据本地数据库版本情况 记得调整数据库依赖版本
然后启动
后台地址:http://127.0.0.1:8080/cmscp/index.do
因为刚开始代码也那么多就没有直接看代码 先熟悉熟悉有什么功能点
XSS
随便进入了一篇文章 然后评论
这里发现是没有xss的
但是后面来到“我的空间”
点击评论的时候
这里触发了xss
这里相当于是黑盒摸到的 单既然是审计 就要从代码来看 重新回到评论的地方 评论进行抓包 看看请求的路径是什么 先找到入口
然后回到idea搜索comment_submit
然后在这里打上断点
然后一步一步放
跟进submit
主要是看传进来的text的走向
到这里text的值都没有变化
然后来到最下面这里是save操作
这里也是直接进行存储 说明存入的时候是没有进行过滤的 那最开始没弹 肯定就是输入的问题了 因为摸到弹的情况
直接根据弹的情况来分析为什么回弹 先找到弹的页面的代码 因为路径有一个space 所以搜索space
打上断点 进行调试
这里最后返回了一个模板
发现这个是一个html 搜索这个html
通过pom.xml
是freemarker模板
先搜搜这玩意是咋转义的
看到一个熟悉的
这个页面这里有填写这个 但是最终还是弹了 说明有漏网之鱼的页面
通过查找 发现一个没有写这个的页面
搜索 看看哪里用到了这俩
刚还这里的type=comment对应上之前访问时候的type
所以访问这个页面的时候能触发xss payload没有进行任何过滤 这个页面也没有进行转义
SSRF
在审计ssrf的时候 一般都是搜索关键函数
URL.openConnection()
URL.openStream()
HttpClient.execute()
HttpClient.executeMethod()
HttpURLConnection.connect()
HttpURLConnection.getInputStream()
HttpServletRequest()
BasicHttpEntityEnclosingRequest()
DefaultBHttpClientConnection()
BasicHttpRequest()
第一处
直接在idea里面搜索
然后一个一个点进去分析
找到这里
会进行连接 然后我们往上分析这个src的来源
发现这里是从请求中获取source[]参数来的 说明这个是我们所能控制的
在往上看 根据函数名能够大概猜出是编辑器图片相关的函数
看看哪里调用了这个函数
在uploadcontroller下 继续跟进ueditorCatchImage函数 看看那里调用
发现在同一页的66行找到 也找到这个路由是在ueditor.do下
最上面controller 是core
所以路径是/core/ueditor.do?action=catchimage
进行测试
但因为是在back下 所以是一个后台的洞
通过后面的代码可以看到 似乎是对一个图片的操作 直接就进行断点看看这里是到底执行了什么
测试:
传入了一个jpg地址 但这个地址是不存在的 来到断点的地方
这里获取到source的值存入数组
这里获得后缀
这里判断请求的是不是图片 因为我们传入的是不存在也就不是 到这里也就直接结束了 在此输入一个存在的链接
跟到这里是重新设置文件名
然后读取输入流
然后跟进这里创建文件对象
然后这里直接保存文件 中间也没有任何过滤操作 就判断了是不是图片 然后就保存了文件
相当于这里就是一个进行 图片请求然后保存到本地的操作
那么这里是不是可以进行svg的xss呢 尝试一些
测试:
先创建一个svg xss
第二处
继续搜索ssrf的关键函数HttpClient.execute()
然后查看哪里调用了这个函数
继续跟进
发现在这里进行的调用以及url的传入 而且这个url是 可控的
往上找到控制层
最后拼接 进行测试
http://192.168.1.2:8080/cmscp/ext/collect/fetch_url.do?url=http://127.0.0.1:8080
直接能访问到服务
最后在页面找到位置
RCE
第一处
在逛后台的时候 发现上传的地方
可以任意上传东西 但是直接jsp这些传上去访问直接下载 无法利用 但是在上传zip的时候会自动解压 这就有意思了 于是乎 先抓包抓到路由 然后全局搜索
然后跟进来
这里调用了这个zipupload 继续跟进
经过简单代码跟进 发现 这一步才开始对参数进行利用
经过初步判断这个函数的作用是将zip里面的文件取出来 然后存入到文件夹里面 具体是不是 利用断点来进行详细的分析
这里是将传进来的文件先写入了临时文件 然后将临时文件和一个路径传入到zip函数
继续跟进
先判断传入的路径是不是文件夹 不是就直接报错
然后看下面 定义了一些相关变量
这里创建了一个zipfile文件对象 目标正式传入的zip文件的临时存储文件
这一步一个就是获取了文件的相关信息
然后走到这一步就直接将文件写入到文件里面 其中也没有任何的过滤 所以我们哪怕是文件里面放入jsp一句话也可以
先试试
jsp文件访问不到 发现在uploads前面竟然多了一个/jsp 其他类型文件直接下载 但是文件又确实存在 那说明肯定是拦截器之类的
经过搜索 找到这里 在这里打上断点
访问之后 确实是走到这里来了 所以直接jsp文件无法利用
那么这里 既然存入文件的过程没有什么过滤 直接利用跨目录的方式写一个war包到 但是这里前提得用tomcat搭建 因为我之前直接用的springboot的 重新切换到tomcat
jspxcms安装包(部署到Tomcat):https://www.ujcms.com/uploads/jspxcms-9.0.0-release.zip
也是有安装手册的
根据手册把配置文件改了 然后启动tomcat
然后来到上传的地方
先准备恶意的zip包
把一句话打包成war包
然后把war包压缩 这里得用到脚本来
import zipfilefile = zipfile.ZipFile('shell.zip','w',zipfile.ZIP_DEFLATED)
with open('test.war','rb') as f:
data = f.read()
file.writestr('../../../test.war',data)
file.close()
然后上传
冰蝎连接
第二处
在pom.xml中发现该系统用的shiro版本是1.3.2
符合shiro-721的条件 现在版本符合了 就需要寻找构造链了
这是该系统的 和ysoserial的利用链的版本有些差异 但能不能用 先测试一下
要了一个payload
然后利用exp脚本 开始爆破
https://github.com/inspiringz/Shiro-721
爆破的时间有点久
然后把cookie复制 我们来执行
反序列化的细节就不在这篇文章叙述了 请听下回分解
参考:https://www.freebuf.com/articles/others-articles/229928.html
JAVA代码审计入门篇
新书推荐
内容简介
本书以“熟悉Maya”为出发点,以“用好Maya”为目标来安排内容,全书共6篇,分为14章。第1篇为基础篇(第1~2章),主要针对Maya初学者,以及有一定Maya应用基础的用户,系统地讲解了Maya软件的特点、2022版本主要的新功能和应用领域等内容;第2篇为建模篇(第3~4章),介绍了Maya中强大、完善的建模模块,如编辑多边形网格、曲面建模技术等;第3篇为渲染篇(第5~8章),介绍了UV的编辑与展开、Maya中渲染常用材质和纹理、默认灯光和阿诺德灯光、PBR 渲染技术,以及材质预设的使用等;第4篇为动画篇(第9~10章),系统并全面地讲解了动画制作中必备的技术与相关知识点,如时间编辑器、变形器、运动路径动画和角色动画的制作等;第5篇为特效篇(第11~12章),介绍了Maya中的动力学特效模块,如粒子系统、布料、毛发和流体等;第6篇为实战篇(第13~14章),详细地讲解了影视场景和次时代载具两个实战案例的操作流程。
如有侵权请联系:admin#unsafe.sh