前言
这几天继续在重写GadgetInspector工具,进一步的增强该自动化工具的source点和sink点,同时增强过程中的漏报和误报的问题。
这里主要是对其中有关于XXE中的两点sink进行几点分析。
sinks
DocumentBuilder类
这个JDK中内置的类是一种的DOM型的解释器,该种Parser的特点是将完整的xml文档内容加载到树结构中去,然后我们通过遍历结点来获取我们需要的内容。
首先编写一段实例代码,来使用DocumentBuilder类来读取xml文档的内容。
Employee.xml
<employees><employee id="111"><firstName>Rakesh</firstName><lastName>Mishra</lastName><location>Bangalore</location></employee><employee id="112"><firstName>John</firstName><lastName>Davis</lastName><location>Chennai</location></employee><employee id="113"><firstName>Rajesh</firstName><lastName>Sharma</lastName><location>Pune</location></employee></employees>
DOMParserDemo.java。
public class DOMParserDemo {public static void main(String[] args) throws Exception{// 获取DOM Builder FactoryDocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();// 获取DOM BuilderDocumentBuilder builder = factory.newDocumentBuilder();// 加载xml文档Document document = builder.parse("Employee.xml");// 建立一个链表存放Employee对象List<Employee> employeeList = new ArrayList<>();// 提取数据NodeList nodeList = document.getDocumentElement().getChildNodes();// 迭代进行读取xml文档for (int i = 0; i < nodeList.getLength(); i++) {// 获取对应结点,这里的结点是employee标签Node node = nodeList.item(i);if (node instanceof Element) {// 创建一个Employee空对象Employee employee = new Employee();// 获取xml文档中的id值employee.id = node.getAttributes().getNamedItem("id").getNodeValue();// 获取子结点信息NodeList childNodes = node.getChildNodes();for (int j = 0; j < childNodes.getLength(); j++) {// 获取对应结点Node node1 = childNodes.item(j);if (node1 instanceof Element) {// 获取对应的信息String content = node1.getTextContent().trim();switch (node1.getNodeName()) {case "firstName":employee.firstName = content;break;case "lastName":employee.lastName = content;break;case "location":employee.location = content;break;}}}// 将获取的每一个对象添加进入列表中去employeeList.add(employee);}}// 打印数据for (Employee employee : employeeList) {System.out.println(employee);}}}
(向右滑动、查看更多)
这种方式就是遍历xml文档中的一个一个的文档来进行对应信息的读取。
这里只是一个简单的使用该种解释器进行xml文档的读取。我们主要是进行XXE的展示。
XXE.xml:
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE test [<!ENTITY xxe SYSTEM "http://127.0.0.1:9999">]><doc>&xxe;</doc>(向右滑动、查看更多)
主要的漏洞点是在调用
DocumentBuilder#parse方法进行xml文档的加载的时候,如果加载的是上面给出的xml内容,将会导致XXE。
简单的调试了一下。
resolveEntity:95, ChainingEntityResolver (weblogic.xml.jaxp)resolveEntity:110, EntityResolverWrapper (com.sun.org.apache.xerces.internal.util)resolveEntityAsPerStax:997, XMLEntityManager (com.sun.org.apache.xerces.internal.impl)startEntity:1212, XMLEntityManager (com.sun.org.apache.xerces.internal.impl)scanEntityReference:1908, XMLDocumentFragmentScannerImpl (com.sun.org.apache.xerces.internal.impl)next:3061, XMLDocumentFragmentScannerImpl$FragmentContentDriver (com.sun.org.apache.xerces.internal.impl)next:602, XMLDocumentScannerImpl (com.sun.org.apache.xerces.internal.impl)scanDocument:505, XMLDocumentFragmentScannerImpl (com.sun.org.apache.xerces.internal.impl)parse:842, XML11Configuration (com.sun.org.apache.xerces.internal.parsers)parse:771, XML11Configuration (com.sun.org.apache.xerces.internal.parsers)parse:141, XMLParser (com.sun.org.apache.xerces.internal.parsers)parse:243, DOMParser (com.sun.org.apache.xerces.internal.parsers)parse:339, DocumentBuilderImpl (com.sun.org.apache.xerces.internal.jaxp)parse:163, RegistryDocumentBuilder (weblogic.xml.jaxp)parse:177, DocumentBuilder (javax.xml.parsers)main:22, DOMParserDemo (study.xmlParser)(向右滑动、查看更多)
在将xml文档路径传入了DocumentBuilder#parser方法之后。
将会将其转换为InputSource类传入DocumentBuilderImpl#parser方法中进行解析。
这里将会调用DOMParser#parser继续进行解析。
按照其中的逻辑将会一次性加载xml文件的所有内容,之后通过调用parse方法进行解析。
最后经过一系列的解析,特别是通过调用XMLDocumentFragmentScannerImpl#scanEntityReference方法的调用来扫描获取xml文件中的实体,之后方法中调用了XMLEntityManager#startEntity方法进行实体的处理。
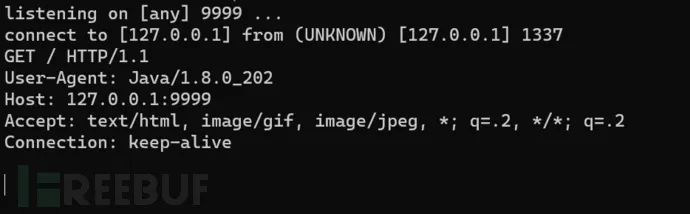
在该方法中存在有是否是外部实体的判断,如果存在有外部实体,将会调用resolveEntityAsPerStax方法来获取外部实体中的信息,这里将会发起一个请求,也即能达到前面截图中的效果。
防御方法:
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();dbf.setFeature("http://apache.org/xml/features/disallow-doctype-decl", true);
(向右滑动、查看更多)
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();dbf.setFeature("http://xml.org/sax/features/external-general-entities", false); //防止外部实体dbf.setFeature("http://xml.org/sax/features/external-parameter-entities", false); //防止参数实体
(向右滑动、查看更多)
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();String FEATURE = null;FEATURE = "http://javax.xml.XMLConstants/feature/secure-processing";dbf.setFeature(FEATURE, true);FEATURE = "http://apache.org/xml/features/disallow-doctype-decl";dbf.setFeature(FEATURE, true);FEATURE = "http://xml.org/sax/features/external-parameter-entities";dbf.setFeature(FEATURE, false);FEATURE = "http://xml.org/sax/features/external-general-entities";dbf.setFeature(FEATURE, false);FEATURE = "http://apache.org/xml/features/nonvalidating/load-external-dtd";dbf.setFeature(FEATURE, false);dbf.setXIncludeAware(false);dbf.setExpandEntityReferences(false);DocumentBuilder builder = dbf.newDocumentBuilder();builder.parse(xxxx);(向右滑动、查看更多)
SAXParser类
接下来的一个XXE的sink点就是在SAXParser#parser方法的调用中,这种方式的xml文档的解析,主要是依靠的SAX Parser这个,这个解析器的不同于DOM Parser,这个解释器是不会直接将完整的XML文档加载进入内存中,这种解释器转而逐行进行XML文档的解析,当他们遇到不同的元素的时候触发不同的事件,例如:开始标签 / 结束标签 / 字符类似的数据等等事件类型,这种解释器是一种基于事件的解释器。
这里也是简单的举一个例子,使用的xml文件也是上面已经提到了的Employee.xml文件内容。
SAXParserDemo.java
public class SAXParserDemo extends Exception {public static void main(String[] args) throws Exception{// 创建SAXParser FactorySAXParserFactory factory = SAXParserFactory.newInstance();SAXParser saxParser = factory.newSAXParser();// 创建自定义的handler对象SAXHandler saxHandler = new SAXHandler();// 加载xml文档,加上自定义的handler对象saxParser.parse("Employee.xml", saxHandler);// 打印结果for (Employee employee : saxHandler.employeeList) {System.out.println(employee);}}}class SAXHandler extends DefaultHandler {// 定义属性List<Employee> employeeList = new ArrayList<>();Employee employee = null;String content = null;@Overridepublic void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {switch (qName) {case "employee":// 如果遇到了employee标签采用的逻辑employee = new Employee();employee.id = attributes.getValue("id");break;}}@Overridepublic void endElement(String uri, String localName, String qName) throws SAXException {switch (qName) {// 遇到结束标签采用的逻辑case "firstName":employee.firstName = content;break;case "lastName":employee.lastName = content;break;case "location":employee.location = content;break;case "employee":employeeList.add(employee);break;}}@Overridepublic void characters(char[] ch, int start, int length) throws SAXException {content = String.copyValueOf(ch, start, length).trim();}}
(向右滑动、查看更多)
这种解释器的方式,主要是在传入xml文件路径的时候,同时传入了一个handler对象,这个对象是继承了DefaultHandler这个内置的默认Handler对象的。
在这个类中定义了很多方法。
在查看这个类的结构的时候,其中这个类是实现了几个接口的,其中实现的有一个接口是ContentHandler,在这个接口中定义了多个和XML文档内容有关的方法。
startDocument()
endElement()
endDocument()
startElement()
......
有关这些方法的作用,也是很明显,运行一下子看看效果。
如果我们将XML文档的地址替换成XXE.xml路径,同样将会触发XXE,同样简单的调试了一下。
startElement:36, SAXHandler (study.xmlParser)startElement:509, AbstractSAXParser (com.sun.org.apache.xerces.internal.parsers)startElement:745, XMLDTDValidator (com.sun.org.apache.xerces.internal.impl.dtd)scanStartElement:1359, XMLDocumentFragmentScannerImpl (com.sun.org.apache.xerces.internal.impl)scanRootElementHook:1289, XMLDocumentScannerImpl$ContentDriver (com.sun.org.apache.xerces.internal.impl)next:3132, XMLDocumentFragmentScannerImpl$FragmentContentDriver (com.sun.org.apache.xerces.internal.impl)next:852, XMLDocumentScannerImpl$PrologDriver (com.sun.org.apache.xerces.internal.impl)next:602, XMLDocumentScannerImpl (com.sun.org.apache.xerces.internal.impl)scanDocument:505, XMLDocumentFragmentScannerImpl (com.sun.org.apache.xerces.internal.impl)parse:842, XML11Configuration (com.sun.org.apache.xerces.internal.parsers)parse:771, XML11Configuration (com.sun.org.apache.xerces.internal.parsers)parse:141, XMLParser (com.sun.org.apache.xerces.internal.parsers)parse:1213, AbstractSAXParser (com.sun.org.apache.xerces.internal.parsers)parse:643, SAXParserImpl$JAXPSAXParser (com.sun.org.apache.xerces.internal.jaxp)parse:392, SAXParser (javax.xml.parsers)parse:274, SAXParser (javax.xml.parsers)main:20, SAXParserDemo (study.xmlParser)
(向右滑动、查看更多)
对于这种解释器,和上面的一种不同在于,前面主要是调用的DOMParser类进行解析,而这里主要是调用了SAXParser类进行解析。
在对应的parse方法中:
传入了两个参数,一个是XML文档的路径,一个是自己实现的继承了DefaultHandler类的类对象。
在将XML文档路径封装成了InputSource对象之后进行解析的逻辑。
这里不同于前面的,这里在创建了一个XMLReader对象之后,设定了对应的Handler对象。
独特的点体现在调用XMLDocumentFragmentScannerImpl#scanDocument方法进行XML的扫描的过程中。
在扫描到ROOT Element位置的时候,将会触发对应的Hook点。
具体点就是调用了scanRootElementHook方法。
这里是配置了对应的Handler的,这里将会在AbstractSAXParser#startElement方法的调用中,调用其中的ContentHandler的对象方法进行处理。
防御方法:
SAXParserFactory spf = SAXParserFactory.newInstance();spf.setFeature("http://apache.org/xml/features/disallow-doctype-decl", true);spf.setFeature("http://xml.org/sax/features/external-general-entities", false);spf.setFeature("http://xml.org/sax/features/external-parameter-entities", false);spf.setFeature("http://apache.org/xml/features/nonvalidating/load-external-dtd", false);SAXParser parser = spf.newSAXParser();parser.parse(InputSource, (HandlerBase) null);
(向右滑动、查看更多)
精彩推荐
如有侵权请联系:admin#unsafe.sh