团队科研成果分享2022.12.12-2022.12.18标题: Fault Diagnosis in Industrial Control Networks Using Transferabilit 2022-12-12 22:38:13 Author: 网络与安全实验室(查看原文) 阅读量:45 收藏
团队科研成果分享
2022.12.12-2022.12.18
标题: Fault Diagnosis in Industrial Control Networks Using Transferability-measured Adversarial Adaptation Network
期刊: IEEE Transactions on Network and Service Management, 2022
作者: Guangjie Han, Zhengwei Xu, Chuanliang Chen, Li Liu, and Hongbo Zhu
分享人: 河海大学——张煜
01
研究背景
BACKGROUND
研究背景
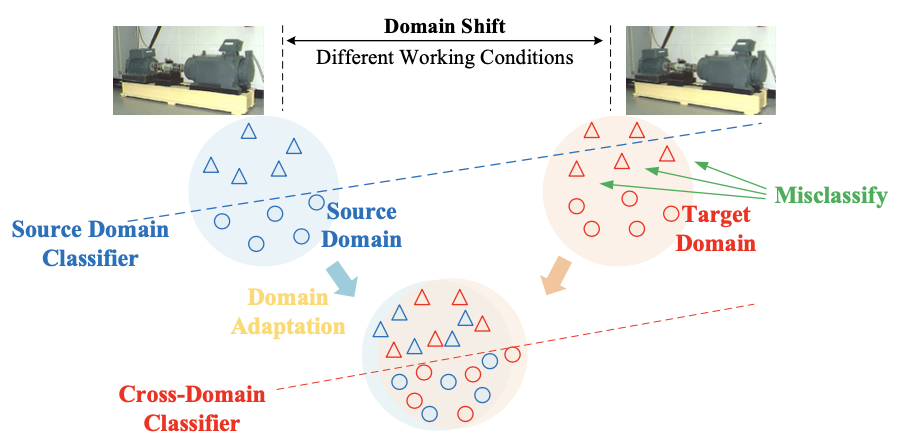
近年来,随着世界各地工业基础设施安全事件数量不断增加, 工业设备的故障诊断成为了智能物联网安全系统中不可或缺的一部分。主流的故障诊断模型依赖于长期的训练和大量的故障数据,但是在环境变化时,无法有效和及时地更新模型,就会导致精度的下降。然而,传统的跨域故障诊断的方法通常假设目标域和源域的样本共享相同的故障模式集,以及对于源域和目标域都有一定的先验知识。这一点在实际的工业场景下很难满足,经常会导致域偏移的问题(如图1所示)。基于上述问题,本文提出了一个可度量迁移性的对抗性适应网络(TAAN),以在没有先验知识的情况下识别未知类别。
图1 ICN中的域偏移现象
02
关键技术
TECHNOLOGY
关键技术
为了解决普遍的DA诊断问题,本文通过混合可迁移性估计嵌入对抗域自适应网络中来权衡每个样本的贡献。通过这种方式,TAAN可以通过选择性地对齐具有高可迁移性的源域样本和目标样本来适当地对公共标签空间中的样本进行分类。因此,可以在标签集没有先验知识的情况下弥合领域和类别差距。TAAN中引入的可迁移机制可以量化每个样本的重要性,并减少无关私有类别的影响。本文将两个辅助分类器和一个辅助域鉴别器添加到传统的对抗性DA网络来计算可迁移性。此外,本文还开发了TAAN的类平衡版本(TAAN-CB),作为处理数据不平衡的补偿机制。通过正确匹配两个域之间的共享标签集中的数据分布,本文的方法可以提取域不变和类判别特征,以提高故障诊断的有效性。
该方法的创新和贡献如下:
1)提出了一个新的TAAN方法,为通用DA诊断问题提供了有效的解决方案。它引入了两个辅助分类器和一个辅助域鉴别器,通过结合预测不确定性和域相似性来计算可传递性。
2)为了解决通用DA诊断中的数据不平衡问题,本文进一步提出了TAAN的类平衡版本。它引入了类平衡损失来弥补由不平衡数据引起的不足,从而放松了类平衡源样本的约束。
3)为了模拟实际工业环境以评估开发的TAAN,本文采用PT700机械故障模拟试验台来构建一个新的故障诊断数据集。结果表明,开发的TAAN和TAAN-CB可以实现比其他流行的诊断方法更好的诊断性能。
03
算法介绍
ALGORITHMS
算法介绍
1. 网络模型
图2 提出的TAAN框架
如图2所示,提出的TAAN框架有两个相互依赖的模块:加权对抗模块和辅助加权模块。TAAN可以通过两个模块的协作来减少共享类别之间的负迁移。
1)加权对抗模块
加权对抗模块由共享的特征提取器F、标签分类器G和域鉴别器D组成。特征提取将原始数据转换为数字特征,这些数字特征可以在保留原始数据集中的信息并同时进行处理。此外,特征提取器可以降低输入原始数据的维度,从而获得深度特征,用于后续的分类操作。在特征提取器中,采用一维(1D)卷积神经网络提取原始输入数据的特征以提高其表示能力。基于从F(x)中提取的特征,标签分类器G输出每个源故障模式的概率,域鉴别器D为一个二元分类器,输出D(F(x))∈ [0, 1]。总的来说,域鉴别器D被训练来区分样本所属的域,而特征提取器F被用来混淆D的判断。
对抗学习这个过程可以被视为一个最小-最大博弈,以弥合域之间的分布差异。
2)辅助加权模块
为了匹配常见故障模式的分布,基于可迁移性的样本加权嵌入到域鉴别器D的训练阶段中,如图3所示。辅助加权模块由两个辅助分类器G1和G2以及一个辅助鉴别器D’组成。D’的结构类似于域鉴别器D,它仍然输出样本的域标签。G1和G2具有相同的网络结构,它们由共享数据集训练。但是,由于它们的决策边界因个体初始化不同而不同,因此它们的标签预测也不同。此外,Gi(i=1,2)和D’不需要对抗性训练,也不需要梯度反向传播到F。
图3 加权对抗和辅助加权模块
2. 可迁移性量化
在训练阶段,输入振动信号数据输入到F中以学习高级表示F(x)以及学习域不变特征。标签分类器G根据F(x)对输入样本进行分类,域鉴别器D被更新以预测正确的域标签。然后,TAAN通过将G、D’的输出与Gi(i=1,2)的输出相结合来量化每个样本的可迁移性,基于可迁移性的样本加权嵌入到D的训练过程中,这有助于对抗网络在共享故障模式下选择性地对齐分布。
在机械故障诊断中,具有相同故障模式的样本即使来自不同的工作环境,也具有更高的相似性和可迁移性。因此,合理的可迁移性应满足:
本文通过结合预测不确定性和域相似性,采用UAN来设计可传递性准则。受最大分类器多样性(MCD)的启发,本文在TAAN中引入了辅助分类器。使用辅助分类器的预测不一致性来测量目标样本的不确定性,而不是用对抗性训练代替域鉴别器。其输出的较强不一致性和输入数据与源域的较低相似性增加了样本落入目标私有标签集的可能性。与MCD类似,本文设置了两个辅助分类器以获得更高的性能。
因此,包括置信度、熵、不一致性和域相似性在内的多个不确定性被组合起来形成一个可迁移的机制来量化目标域中的样本属于共享故障模式的可能性。分别表示为:熵we、不一致性wd、置信度wc和域相似度ws。因此目标类级权重可计算为:
上述不确定性采用最小-最大归一化,以将其值统一在[0,1]内。由于标记的源数据可用,因此无需设计源权重。在公共标签集合中,源样本比私有标签样本更接近目标样本,因此,源类级别权重可以表示如下:
其中w0是可以将目标私有类与公共类区分开来的预定义阈值。
3. 网络优化
类似于对抗性训练过程,在源域中的标记样本被输入F后,G根据提取的高级特征尽可能正确地将样本分类为源故障模式之一。因此,G的损失函数表示为:
L表示为交叉熵损失,因为故障诊断本质上是一个多类分类问题。同时,D根据提取的高级特征确定输入样本属于源域还是目标域。如果D的输出被评估为源域样本,则用1表示,如果被评估为目标域样本,那么用0表示。因此,结合设计的加权机制,D的损失函数可以表示为:
对于D’和Gi(i=1,2),它们也在F之后进行输出样本的域预测和分类预测。相应的损失表示为:
在加权对抗训练过程中,F应确保提取的高维特征具有类可伸缩性,并最小化分类器损失。此外,F应弥合不同域之间特征分布的差异,同时混淆D以做出错误的预测并最大化D的损失。为了实现这一目的,在D和F之间添加了梯度反转层(GRL)。因此,优化目标可以表述为:
其中λ是在学习期间控制可转移性和可辨别性成形特征之间的权衡的惩罚系数。它可以通过在训练过程中监督域鉴别器和分类器的输出来调整。
在诊断过程中,首先将目标样本输入F以获得域不变表示,然后使用该域不变表示来获得目标可转移性wt。TAAN将wt与验证的阈值w0进行比较。如果wt小于w0,则输出G的标签预测。否则,样本将被标记为“未知”。y表示为网络的最终输出:
4. TAAN-CB
在真实的工业生产过程中,收集到的关于健康模式的数据通常多于故障模式数据。因此,即使在通用DA中,每个源故障模式的样本数量也可能不平衡。除了域之间的差异,源域中的知识质量也影响目标域中的泛化误差。特别是在通用DA中,源类级别权重受源知识质量的影响更为显著,因为它由在源样本上训练的分类器的输出组成。通常,源域中较高的知识质量和较小的泛化误差导致目标域中更好的诊断能力。在本文中,引入了类平衡(CB)损失来弥补由不平衡数据引起的缺陷。CB损失采用有效样本来重新平衡每个类别的损失。其表示如下:
从而,标签分类器G的损失可以更新为:
CB损失可以应用于损失函数和广泛的深度网络,这是损失不可知的和模型不可知的。
04
实验结果
EXPERIMENTS
实验结果
1. 仿真参数设置
图4 PT700数据集的采集设备和相应的故障模式
如图4所示,本文在两个个数据集上进行了实验(CWRU数据集和PT700数据集),其中每个数据集都包含四种不同的故障类型和不同严重程度的故障模式。通过与一些最先进的故障诊断方法进比较,来评估提出的TAAN的有效性。本文设计了几个DA任务来评估开发的诊断模型。具体而言,建立了五个不同规格的UnDA任务,以研究共性对迁移效应的影响。随机选择每个任务的源和目标标签空间中包含的健康状态,以增强模拟结果的可信度。具体参数设置如表1所示,每个故障模式包含200个样本,每个样本的维数为1024。原始信号被划分为多个窗口。采用Adam算法对1000个时期的模型参数进行优化。
表1 TAAN中的参数设置
2. 结果与分析
CWRU数据集上N1-N8诊断任务的模拟结果如图5(左)所示,PT700数据集上的结果见图5(右)。可以看出,本文提出的TAAN对于所有数据集的平均准确度超过80%,这在所有这些场景中都与其他比较方法精度高。对于任务N1和U1,所有DA方法都能获得令人满意的性能,这说明了知识迁移的必要性。在部分DA任务(N2和U2)和开放集DA任务(N3和U3)中,TAAN实现了与W ANT和OSBP几乎相同的诊断精度。与为特定设置设计的方法不同,TAAN无需先验知识的假设来促进正向迁移并选择有效样本来解决DA问题。关于通用DA问题,本文设计了几个不同规格的任务,即N4-N8和U4-U8,以探讨诊断任务的共性的影响。可以发现,对于所有通用DA任务,DADAN、WANT和OSBP的准确性显著降低。TAAN仍能保持良好的性能。原因是DADAN旨在调整整个分布,而WANT和OSBP分别特别关注部分和开放集DA问题。当实际场景与这些模型中考虑的相应设置之间存在任何不一致时,由于跨域不匹配,将发生负迁移。当共性较低时,这种现象很明显。在这种情况下,比较的DA方法的性能不如1D CNN。相比之下,TAAN可以不考虑共性变化实现有希望的诊断准确性。这是因为设计的可迁移性有助于TAAN识别共享故障模式下的样本,并进一步避免负迁移。
图5 TAAN在CWRU和PT700数据集上的诊断精度
此外,本文还考虑了噪声数据对诊断结果的影响。在真实世界的工业环境中收集的数据不可避免地受到噪声的污染。因此,应考虑诊断模型对噪声的鲁棒性。为了模拟实际的故障诊断环境,我们在任务N5中为每个目标测试样本添加了信噪比(SNR)范围为{-4,-2,0,2,4,6}dB的高斯白噪声。采用纯数据来训练模型,并使用噪声数据来测试训练的模型。TAAN的诊断结果和比较方法如图6所示。可以看出,当SNR值较高时,所有方法都获得了良好的诊断性能。随着噪声变强,即SNR值逐渐降低,所有方法的性能都会相应降低。这是因为噪声的添加掩盖了样本的有效信息,这进一步增加了两个域之间的特征分布差异。最终,跨域故障诊断的难度增加了。相比之下,所提出的TAAN在噪声环境中保持了令人满意的诊断精度。当信噪比降低时,其性能下降也低于其他方法,这证明了TAAN的抗噪声能力和鲁棒性。
图6 具有不同SNR值的信号精度
上述实验是使用每类平衡数量的样本进行的。然而在真实的工业生产中获取足够的等级平衡数据并不容易,长尾数据分布也会影响最终的DA性能。基于CWRU数据集,我们通过减少特定类别的训练样本数量,构建了几个不平衡版本的CWRU。数据集的类不平衡程度由不平衡因子来衡量,不平衡因子定义为最大类中的训练样本数除以最小类。图7给出了不平衡因子为100、50、20、10和1的实验结果。其中,TAAN表示不使用CB损耗,TAAN-CB表示在所提出的方法中使用CB损耗。TAAN和TAAN-CB的诊断性能同时随着不平衡因素的增加而降低。然而,TAANCB下降相对缓慢,并保持可接受的识别精度,这表明它可以有效地消除样本数量的分布差异。因此,CB损失可以帮助故障诊断模型减少不平衡分布对DA性能的影响,并显著增强其对小样本类的鲁棒性。
图7 CWRU数据集上不平衡故障诊断的精度
05
总结
CONCLUSION
总结
本文提出了一种解决故障诊断问题的新方法,用于通用的DA问题。以前的方法对于数据条件十分苛刻,实际工业生产场景很难满足。所提出的TAAN为了弥合域之间的分布差异,设计了一个对抗性学习网络,以在不同的操作条件下提取域不变和类判别特征。此外,通过引入辅助分类器和鉴别器,在DA模型中嵌入了可迁的加权机制。因此,TAAN可以识别共享故障模式中的样本,并过滤掉无用的知识。为了使所提出的方法能够处理不平衡数据,本文还提出了可以嵌入TAAN的CB损失。相比较其他先进的诊断方法精度都有所提高。
然而,所提出的方法的主要限制之一就是是它简单地将所有私有目标样本标记为“未知”。甚至“未知”样本可能来自许多不同的类别,需要复杂的手动标记才能进行故障诊断。未来的研究将致力于“未知”样本的初步分类,并使用无监督聚类方法,通过伪标签来标记它们。此外,如何仅使用目标域数据来完成模型训练以克服数据孤岛问题,以及如何将单点故障扩展到复合故障,也是我们未来将考虑的研究方向。
END
扫描二维码关注我们
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh