相比前几天热闹,从今天朋友圈及微博上来看ChatGPT热度明显降低了不少,所以前面大家都是尝鲜的凑热闹的居多,以至于我担心ChatGPT成本问题,毕竟musk都在推特上询问OpenAI CEO关于Ch 2022-12-8 23:15:26 Author: 黑哥虾撩(查看原文) 阅读量:24 收藏
相比前几天热闹,从今天朋友圈及微博上来看ChatGPT热度明显降低了不少,所以前面大家都是尝鲜的凑热闹的居多,以至于我担心ChatGPT成本问题,毕竟musk都在推特上询问OpenAI CEO关于ChatGPT每次查询的成本问题,不过从朋友们的反馈来看,貌似目前不用太担心这个问题。
我在写《ChatGPT,未来可期》文章的时候,提到基本解决了“面向黑哥编程”,但是那些都是简单一句话就能描述清楚的需求,从前面的测试我们发现ChatGPT对用户输入的需求语言理解是非常到位的,但是还没有真正的所谓“图灵完备”的阶段,对于一些完整点、复杂点的需求,ChatGPT还不能自动去通过用户的一句笼统的需求逐步完成,那么这点还需要用户进行分解提炼,并转为语言描述提交给ChatGPT,实际上这点不是那么容易办到的,这点说明ChatGPT可以从“玩具”上升到了“工具”这个层次了,没错ChatGPT晋升了,成为了妥妥的“打工仔”。对于工具的使用还需要看使用者的能力,“打工仔”要看“老板”的能力,当然这点也对我们的思维习惯上需要做出一些改变,这个也就是我说的使用者需要习惯“黄世仁”的“老板”思维模式!
“黄世仁”的变态需求
从用ChatGPT那天开始我就想着怎么让ChatGPT真正开始打工仔之路,今天有空就实战了一把,先说明下我的需求,在《谈谈网络空间“行为测绘”》的文章里我写一个脚本自动提取http返回里相同的字符串,成为自动生成ZoomEye查询关键词组合语法,所以我就给我们小伙提了个需求当然小伙很快就给代码:
header1 = """HTTP/1.1 403 ForbiddenServer: nginx/1.18.0 (Ubuntu)Date: Wed, 13 Oct 2021 18:56:30 GMTContent-Length: 9Connection: closeForbidden"""header2 = """HTTP/1.1 403 ForbiddenServer: nginx/1.14.0 (Ubuntu)Date: Wed, 13 Oct 2021 17:17:29 GMTContent-Length: 9Connection: closeForbidden"""def headers_to_set(header_str):lists = header_str.split('\n')lists = [i for i in lists if i]return set(lists) if header_str else set()def main():h1 = headers_to_set(header1)h2 = headers_to_set(header2)h3 = h1 & h2print(h3)if __name__ == '__main__':main()
不过这个代码还不能完全满足我的需求,另外在实战过程中也存在一些问题,后面因为忙其他问题就没接着搞了,所以今天就是你ChatGPT打工仔的机会啦!
ChatGPT 开始上班
这里注意:我提交的header1 与 header2 是没有赋值的,因为你直接提交过去ChatGPT 报错,简单测试了下与代码里的符号/相关,我猜测是不是这几天大家各种无聊的装x测试导致的,所以我只好直接不赋值说明我的需求。
我的第一个需求:
Q:先需要一个数组,对数组里的元素["Connection: close","Connection: keep-alive"]对header1,header2进行替换为空
(简单说明下这个是什么目的,这个是因为ZoomEye探针发包方式不一样或者因为目标服务器设置不一样,同一类服务器导致有的“Connection: close”有的没有,所以我需要预先处理替换为空)
A:经过一段苦口婆心,且无关紧要的“教学”后给出了代码(这里吐槽下,在这个时候打工仔的这些废话很影响老板的急切压榨打工仔的心情~~)
def headers_to_set(header_str):header_list = ["Connection: close", "Connection: keep-alive"]for header in header_list:header_str = header_str.replace(header, "")lists = header_str.split('\n')lists = [i for i in lists if i]return set(lists) if header_str else set()
然后我继续提了我的第二个需求:
Q:对上面headers_to_set函数里的lists,如果发现存在字符Server:的元素对/进行分割
(继续说明下这个需求,因为通过行为分析发现有的服务器部署的nginx等版本不同,所以不能提取这个Server,这里需要单独处理一下)
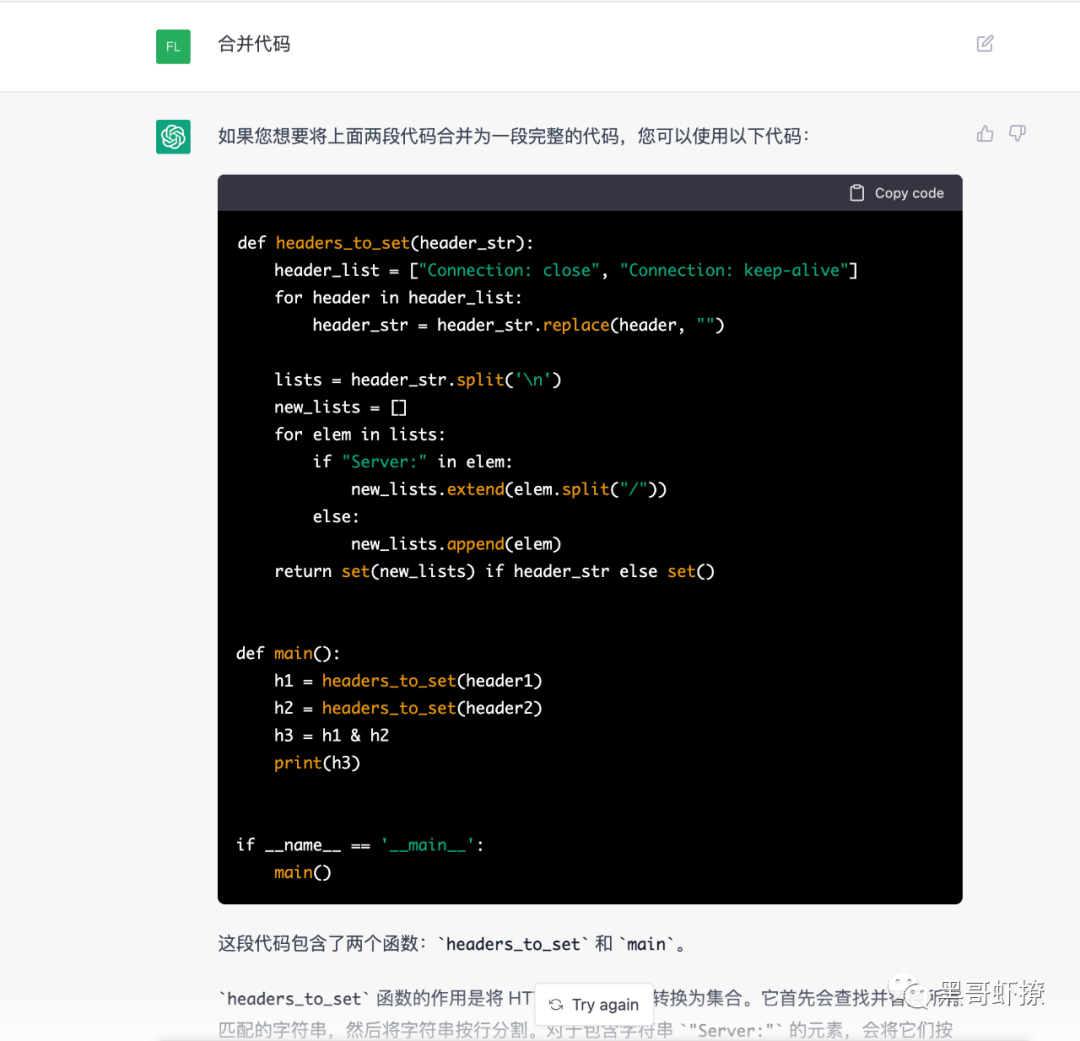
A:又是一段无关紧要的“教学”,所以“好为人师”不光是人类的通病,同样也是AI的通病!!!最后需求相关的代码如下:
def headers_to_set(header_str):lists = header_str.split('\n')new_lists = []for elem in lists:if "Server:" in elem:new_lists.extend(elem.split("/"))else:new_lists.append(elem)return set(new_lists) if header_str else set()
可以看出来这里都是给的关键函数的代码,不是完整代码,于是我输入了“合并代码”,有一说一,打工仔的理解能力没得说,直接就给了完整代码,当然也少不了炫耀下自己解读代码的能力,所以AI除了“好为人师”外,也喜欢装x!如下图:
生成的代码本地补充了header1及header2的值后执行了下:
>python3 b.py{'', 'HTTP/1.1 403 Forbidden', 'Content-Length: 9', 'Server: nginx', 'Forbidden'}
看起来多了一个空值,这个应该是http头跟body之间有两个回车导致的,所以接下来就是去掉这个空值的需求:
Q:需要对headers_to_set里lists数组里为空的元素,剔除
A:
def headers_to_set(header_str):header_list = ["Connection: close", "Connection: keep-alive"]for header in header_list:header_str = header_str.replace(header, "")lists = header_str.split('\n')new_lists = []for elem in lists:if "Server:" in elem:new_lists.extend(elem.split("/"))else:new_lists.append(elem)filtered_list = filter(None, new_lists)return set(filtered_list) if header_str else set()
合并代码后本地测试通过:
>python3 b.py{'Forbidden', 'Server: nginx', 'Content-Length: 9', 'HTTP/1.1 403 Forbidden'}
继续我的下一个需求,下一个需求就需要把这个数组输出为ZoomEye搜索的语法,所以继续提需求给打工仔
Q:对main()里的h3速组里面的元素,每个元素用引号,然后使用“ +”进行连接
A:
def main():h1 = headers_to_set(header1)h2 = headers_to_set(header2)h3 = h1 & h2quoted_h3 = map(lambda x: f'"{x}"', h3)s = " + ".join(quoted_h3)print(s)
合并代码后本地赋值测试,完美通过:
>python3 b.py"Content-Length: 9" + "Server: nginx" + "HTTP/1.1 403 Forbidden" + "Forbidden"
直接copy到ZoomEye搜索框是可以搜索的。到这里我原本的需求算基本完成了,但是本着好的“黄世仁”应该多给“打工仔”一些机会,所以我继续完善,这次我想把header1及header2通过网络请求实现。
Q:定义两个参数,对参数进行http或者https请求,对返回分别赋值给header1和header2
A:这里就出现点问题,前面都是给的请求的教学的例子
from urllib.request import urlopendef get_headers(url1, url2):response1 = urlopen(url1)response2 = urlopen(url2)return response1.info(), response2.info()def main():url1 = "http://www.example.com"url2 = "https://www.example.com"headers1, headers2 = get_headers(url1, url2)print(headers1)print(headers2)if __name__ == '__main__':main()
所以我继续输入了“合并代码”,后给出了代码:
from urllib.request import urlopendef headers_to_set(header_str):header_list = ["Connection: close", "Connection: keep-alive"]for header in header_list:header_str = header_str.replace(header, "")lists = header_str.split('\n')new_lists = []for elem in lists:if "Server:" in elem:new_lists.extend(elem.split("/"))else:new_lists.append(elem)filtered_list = filter(None, new_lists)return set(filtered_list) if header_str else set()def get_headers(url1, url2):response1 = urlopen(url1)response2 = urlopen(url2)return response1.info(), response2.info()def main():url1 = "http://www.example.com"url2 = "https://www.example.com"headers1, headers2 = get_headers(url1, url2)h1 = headers_to_set(headers1)h2 = headers_to_set(headers2)h3 = h1 & h2s = ", ".join(h3)print(s)if __name__ == '__main__':main()
但是这次出问题了,执行上面的代码提示错误了,于是我直接把错误信息丢过去
Q:上面代码运行输出 “raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 403: Forbidden” 是什么问题
A:打工仔觉得这个是服务器的锅,因为我测试例子是403状态 如下图:
所以AI除了上面提到的“好为人师”、“爱装x”外,还特么非常能“甩锅”,所以我实在忍无可忍了,凭着我那点为数不多的python修为,我决定让它使用Requests,这个很简单但是也带来了坑,第一个坑是http头跟body是分开的,所以我不等不让让合并处理。
Q:上面代码get_headers函数里获取到的 请求返回 头及text 合并到一个字符串
A:
import requestsdef headers_to_set(header_str):header_list = ["Connection: close", "Connection: keep-alive"]for header in header_list:header_str = str(header_str).replace(header, "")lists = header_str.split('\n')new_lists = []for elem in lists:if "Server:" in elem:new_lists.extend(elem.split("/"))else:new_lists.append(elem)filtered_list = filter(None, new_lists)return set(filtered_list) if header_str else set()def get_headers(url1, url2):response1 = requests.get(url1)response2 = requests.get(url2)return response1.headers, response1.text, response2.headers, response2.textdef main():url1 = "http://www.example.com"url2 = "https://www.example.com"headers1, html1, headers2, html2 = get_headers(url1, url2)headers1_str = str(headers1) + html1headers2_str = str(headers2) + html2h1 = headers_to_set(headers1_str)h2 = headers_to_set(headers2_str)h3 = h1 & h2s = ", ".join(h3)print(s)if __name__ == '__main__':main()
怎么测试都不能通过,在这里坑了好久,这个坑应该算是“组合”代码带来的,因为我最早的需求提交的headers1及headers2是字符串,而通过requests获取的http头是个数组,由此可见,程序员相比修改别人的代码更喜欢自己重新写来的舒服是有道理的!
Q:get_headers函数获取到的http请求头及对应值输出为一个字符串
Q:headers1_str 里的html1 前面加入“\n” ,headers2_str 一样的处理
A:
import requestsdef headers_to_set(header_str):header_list = ["Connection: close", "Connection: keep-alive"]for header in header_list:header_str = str(header_str).replace(header, "")lists = header_str.split('\n')new_lists = []for elem in lists:if "Server:" in elem:new_lists.extend(elem.split("/"))else:new_lists.append(elem)filtered_list = filter(None, new_lists)return set(filtered_list) if header_str else set()def get_headers(url1, url2):response1 = requests.get(url1)response2 = requests.get(url2)return response1.headers, response1.text, response2.headers, response2.textdef main():url1 = "http://www.example.com"url2 = "https://www.example.com"headers1, html1, headers2, html2 = get_headers(url1, url2)headers1_str = "\n".join([f"{k}: {v}" for k, v in headers1.items()]) + "\n" + html1headers2_str = "\n".join([f"{k}: {v}" for k, v in headers2.items()]) + "\n" + html2h1 = headers_to_set(headers1_str)h2 = headers_to_set(headers2_str)h3 = h1 & h2s = ", ".join(h3)print(s)if __name__ == '__main__':main()
测试后符合要求,当然这里还有一个坑呢就是main()里h3那个地方的处理,因为我可能在前面修改的时候“合并代码”它不小心“回滚”,所以AI写代码的时候也可能存在回滚带来的问题,问题不打,继续让它写就行了:
Q:对main()里的h3速组里面的元素,每个元素用引号,然后使用“ +”进行连接
A:这些它换了一种写法,关键部分代码:
h3 = h1 & h2s = " + ".join(['"' + elem + '"' for elem in h3])print(s)
测试后ok,不过我的需求还没有完,我需要参数化提交url1集url2
Q:对上面的代码url1及url2,进行参数化处理
A:结果很失败!它完全没有理解我这个需求,直接变成了main()函数的参数处理:
def main(url1, url2):headers1, html1, headers2, html2 = get_headers(url1, url2)headers1_str = "\n".join([f"{k}: {v}" for k, v in headers1.items()]) + "\n" + html1headers2_str = "\n".join([f"{k}: {v}" for k, v in headers2.items()]) + "\n" + html2h1 = headers_to_set(headers1_str)h2 = headers_to_set(headers2_str)h3 = h1 & h2s = " + ".join(['"' + elem + '"' for elem in h3])print(s)if __name__ == '__main__':main("http://www.example.com", "https://www.example.com")
一口老血!!!所以这里告诉我们领导给下属提需求是非常讲究艺术的!!!
于是我痛定思痛,反思过户,我换个非常非常卑微的、亲民的提法:
Q:我需要使用python3 xx.py url1 url2 这种方式 的输入参数化
A:它终于还是懂了!!所以上面千错万错都是我的错!!!
import requestsimport sysdef headers_to_set(header_str):header_list = ["Connection: close", "Connection: keep-alive"]for header in header_list:header_str = str(header_str).replace(header, "")lists = header_str.split('\n')new_lists = []for elem in lists:if "Server:" in elem:new_lists.extend(elem.split("/"))else:new_lists.append(elem)filtered_list = filter(None, new_lists)return set(filtered_list) if header_str else set()def get_headers(url1, url2):response1 = requests.get(url1)response2 = requests.get(url2)return response1.headers, response1.text, response2.headers, response2.textdef main():url1 = sys.argv[1]url2 = sys.argv[2]headers1, html1, headers2, html2 = get_headers(url1, url2)headers1_str = "\n".join([f"{k}: {v}" for k, v in headers1.items()]) + "\n" + html1headers2_str = "\n".join([f"{k}: {v}" for k, v in headers2.items()]) + "\n" + html2h1 = headers_to_set(headers1_str)h2 = headers_to_set(headers2_str)h3 = h1 & h2s = " + ".join(['"' + elem + '"' for elem in h3])print(s)if __name__ == '__main__':main()
小结
由此本黄sir宣布,打工仔 ChatGPT 的表现还是非常优秀的,虽然“好为人师”、偶然“装个x”、有时候还会“甩个锅”,但是工作态度及结果还是可以的!所以我想对ChatGPT说一句:你也是刚开始打工,我也是刚开始当你老板,大家都不容易,让我们一起加油,做大做强,共创辉煌!
[顺带提一句有心的小伙可能发现,在我跟ChatGPT沟通的时候,有一些错别字的情况,事实证明这些错别字不影响ChatGPT的理解!]
如有侵权请联系:admin#unsafe.sh