为纸质书籍进行数字备份:如何制作一本功能完备的 PDF 电子书
为了方便地保存与分享书籍,我们往往需要将纸质书电子化,而最常见的方式则是通过扫描将其保存为 数字世界的纸张——PDF。选择合适的扫描工具与方法,可以提高 PDF 的扫描质量。此外,与直接得到的原版 PDF 相比,扫描版 PDF 一般没有书签,页码往往也不正确,需要进行调整。为了提高处理扫描版书籍的效率,得到一本「功能完备」的 PDF 书籍,下面分享一些我的技巧。
使用手机扫描
尽管有专门的扫描仪器用于扫描文件,但为了扫描书籍,手机基本上就足够了。市面上已有很多扫描 App 可供选择,比如 iOS 系统自带的备忘录、白描、Microsoft Lens、Scanner Pro 等。
在 iOS 上,我选择了完全免费的 vFlat Scan(也有 Android 版本),主要是因为它有一些专门为扫描书籍而设计的功能,包括:
- 扫描区域自动识别:自动识别要扫描的文档或书籍的边框,无需手动裁剪。
- 自动捕获:识别扫描目标并自动捕获,无需反复点按,在扫描数百页的书籍时很有用。
- 展平弯曲的页面:自动拉直书页的曲面,无需拆书。
- 自动去除手指:在需要用手指将书籍平铺的场景下,可以移除书籍边缘的手指印记。
- 双页捕获:自动捕捉书籍的左右页,分割为两页保存。

值得一提的是,vFlat Scan 的「双页捕获」功能在扫描书籍时非常实用,能够有效减少扫描的工作量。当然,如果某些场景 vFlat Scan 识别双页不准确,你也可以关闭这个功能,在后期处理时使用 MuPDF 或 Briss 分割扫描得到的 PDF。

除了选择趁手的软件外,扫描书籍的物理环境也很重要,推荐观看这几个非常专业的扫描书籍的 视频教程。值得一提的是,光线对于扫描书籍来说非常重要,既要保证光线充足,又要考虑光线的角度以避免不必要的阴影,在尝试了很多方案之后,我发现「屏幕挂灯」较好地满足了这个需求,因为它特殊的照明角度,不会造成反光或阴影。
由于各种原因,扫描过程中难免会产生一些噪点甚至黑边,虽然这些细节「无伤大雅」,但对于我这样的强迫症来说,是无法忍受的。如果有这种情况,我一般会使用 PDF Expert 的 隐藏工具 将其移除,具体使用方式见下图。

识别 PDF 文字
「使用手机扫描」之后,纸质书电子化就完成了第一步。很多情况下到这一步就可以了,但是为了让电子版书籍更加完善,还需要进行进一步的处理。而为了搜索 PDF 中的内容,或阅读时进行批注,首先就要识别其中的文字,即 OCR(光学字符识别)。扫描得到的 PDF 文件实际上是一系列图片,而 OCR 则是在其上层增加一层文字图层,已有很多工具可以对 PDF 进行 OCR,我主要使用 Adobe Acrobat 和 DEVONthink。
Adobe 作为 PDF 标准的创立者,旗下的 Acrobat 自然也是最 versatile 的 PDF 软件,缺点就是界面太丑且价格很贵。但如果你订阅了 Adobe,那么可以使用它对 PDF 进行 OCR,效果几乎可以说是无出其右。如下图所示,在 Acrobat 中打开一个扫描版 PDF,点击右侧的「Scan & OCR」,然后在上方点击「识别文字」,选择语言,确认之后,Acrobat 就会自动开始 OCR。

除 Adobe Acrobat 外,我也会使用 DEVONthink 对 PDF 进行 OCR。DEVONthink 使用的是著名的 OCR 引擎 ABBYY,效果同样也是非常不错的。使用方式也很简单,只需在 DEVONthink 中选中 PDF,右键选择「OCR -> to searchable PDF」即可。

除了 Adobe Acrobat 和 DEVONthink 这两种付费方式外,也可以使用 OCRmyPDF 这个开源的命令行工具免费对 PDF 进行 OCR。
另外值得一提的是,在 Apple Silicon Mac 上,macOS 自带的预览(Preview)可以像识别图片中的 实况文本 那样,识别扫描版 PDF 中的文本,iOS 自带的「文件 App」也有类似的功能1。在轻量使用的场景下,比如从 PDF 中复制一些文字,这个功能非常实用,而不需要对整个 PDF 全部 OCR。

制作 PDF 书签
PDF 书签(bookmark)是指导航窗格的书签面板中的超链接文本,对应着不同的页码,一般也叫作「目录」或「大纲」。

PDF 书籍动辄几百页,为其添加书签有助于在不同章节之间方便地跳转,让扫描后的 PDF 更加「电子化」。为 PDF 添加书签,看上去是一项略显复杂但又很常见的需求,有不少 网友 提供了自己的解决方案,其中就包括 派友 的分享。针对为书籍 PDF 增加书签这个需求,我的解决方案是使用命令行工具 PDFtk。
PDFtk 是一个处理 PDF 文件的工具,包括 PDFtk Free、PDFtk Pro 和 PDFtk Server,其中的命令行工具 PDFtk Server 可以免费使用,适用于 macOS、Linux 和 Windows。PDFtk 没有被 Homebrew 的官方源所收录,因此在 macOS 上使用 Homebrew 安装之前,需要先添加一个 Tap (Third-Party Repository) brew tap zph/cervezas,然后执行 brew install zph/cervezas/pdftk,就可以安装了。
下面以《遏制民族主义》这本书为例,说明如何为 PDF 书籍制作书签。
制作目录标题
制作 PDF 书签前,需要提供书签信息,即章节名称和对应的页码,以供 PDFtk 读取并写入 PDF 文件中。好消息是书籍的目录标题一般都很容易获取,不需要自己手动编辑,一般来说,豆瓣、Amazon 或出版社官网页的书籍介绍页都会提供目录,我们只需要复制它,然后将其保存为 heading.txt。

PDF 书签和 Markdown 中的标题一样,也是有层级的,比如在《遏制民族主义》这本书中,第一章 民族主义的困惑是一级标题,民族主义的界定 则是二级标题。为了对不同的标题层级进行区分,我们借用 Markdown 的语法,将其改写为:
# 出版说明
# 目录
# 第一章 民族主义的困惑
## 民族主义的界定
## 治理单元
## 民族
## 民族的突出特征
## 民族主义的类型
# 第二章 民族主义的起因
## 群体的形成
## 群体团结的决定因素
## 为何民族主义是现代的事物
## 谁是民族主义者
## 什么制度才能遏制民族主义?
# 第三章 间接统治与民族主义的缺失
## 间接统治的兴起:原始国家形成理论
## 欧洲历史上的间接统治
## 欧洲殖民地的间接统治
## 结论
# 第四章 国家建设民族主义
## 直接统治的兴起
## 直接统治的影响
## 直接统治与国家建设民族主义
## 结论
……为了提高效率,上述操作可以借用 正则表达式 进行批量查找替换,或者在 iA Writer 或 Typora 中使用快捷键操作。
制作目录页码
尽管豆瓣等网站提供了书籍的目录,但一般没有提供对应的页码,需要单独制作。这一步我们将目光转向扫描版 PDF 书籍中已有的目录,通过 OCR 将目录页码提取出来,可以参考下图使用 Clean Shot X OCR 页码的示例。

按照如上方式将页码全部提取出来,并保存为 pagenumber.txt。对于其中的空行,不必一个个手动移除,之后会在命令行中批量移除。
需要注意的是,通过 OCR 得到的页码是书籍页眉或页脚中注明的页码,并非 PDF 文件中的真实页码,这是由于书籍的第 1 页通常是从正文第一页开始计算的,在正文之前还有序言、致谢、目录等部分,而 PDF 的页码则总是从第 1 页开始计算的。在《遏制民族主义》这本书中,从 PDF 第 1 页开始计算,正文第 1 页实际上位于第 10 页,前面的 9 页是前言部分。

由于 PDF 书签的页码总是从第 1 页开始计算的,因此,通过 OCR 得到的每一个页码都需要加上 9。如果需要对正文之前的部分制作书签,可以在 pagenumber.txt 中手动输入对应页码减去前言部分的页码数。对于《遏制民族主义》这本书来说,「出版说明」和「目录」分别在第 4 和 7 页,减去 9 后分别是 -5 和 -2。下面的例子中,第一列数字是我们 OCR 和手动编辑后的结果,第二列数字是它们在 PDF 中对应的页码:
-5 -> 4 # 出版说明
-2 -> 7 # 目录
1 -> 10 # 正文
5 -> 14
9 -> 18
10 -> 19
13 -> 22
15 -> 24
23 -> 32
24 -> 33
26 -> 35
29 -> 38
33 -> 42
36 -> 45
43 -> 52
45 -> 54
52 -> 61
57 -> 66
60 -> 69
68 -> 77
69 -> 78
71 -> 80
74 -> 83
79 -> 88
…使用 Shell 脚本可以非常容易地实现上面这个转换:
cat pagenumber.txt | awk NF | while read line; do echo $((${line}+9)); done > realpage.text上面这行命令,首先使用 cat 命令读取 pagenumber.txt 的内容,然后使用 awk NF 移除其中所有的空行,再将每行的数字加上 9(这个数字需要根据正文之前的页数确定),输出为 realpage.text。
合并标题和页码
将上面的目录标题和对应页码这两个文件合并到一起:
paste heading.txt realpage.text > bookmark.textpaste 命令 的作用是将文件逐行合并在一起,默认使用 Tab 键分隔两个文件中的内容,因此得到如下的结果:
# 出版说明 4
# 目录 7
# 第一章 民族主义的困惑 10
## 民族主义的界定 14
## 治理单元 18
## 民族 19
## 民族的突出特征 22
## 民族主义的类型 24
# 第二章 民族主义的起因 32
## 群体的形成 33
## 群体团结的决定因素 35
## 为何民族主义是现代的事物 38
## 谁是民族主义者 42
## 什么制度才能遏制民族主义? 45
# 第三章 间接统治与民族主义的缺失 52
## 间接统治的兴起:原始国家形成理论 54
## 欧洲历史上的间接统治 61
## 欧洲殖民地的间接统治 66
## 结论 69
# 第四章 国家建设民族主义 77
## 直接统治的兴起 78
## 直接统治的影响 80
## 直接统治与国家建设民族主义 83
## 结论 88
……转换为 PDF 元数据
使用 PDFtk 导出一个带有书签的 PDF 文件的元数据信息,保存为 test.text:
pdftk input.pdf dump_data output test.text打开 test.text 可以发现,PDF 书签信息的格式形如:
BookmarkBegin
BookmarkTitle: Section 1
BookmarkLevel: 1
BookmarkPageNumber: 10
BookmarkBegin
BookmarkTitle: Subsection 1.1
BookmarkLevel: 2
BookmarkPageNumber: 20
BookmarkBegin
BookmarkTitle: Subsubsection 1.1.1
BookmarkLevel: 3
BookmarkPageNumber: 30
…容易发现,每个书签条目由 4 行组成:
BookmarkBegin:开始一个书签条目BookmarkTitle:书签标题BookmarkLevel:书签层级,用阿拉伯数字 1、2、3 表示BookmarkPageNumber:书签的页码,从第 1 页开始计算
了解了 PDF 书签的构成方式,我们就可以使用 Perl 结合正则表达式,在命令行中将之前得到 bookmark.text 转换为同样的格式:
perl -i -pe 's/^#\s(.*)\t(\d+)/BookmarkBegin\nBookmarkTitle: \1\nBookmarkLevel: 1\nBookmarkPageNumber: \2/g; \
s/^##\s(.*)\t(\d+)/BookmarkBegin\nBookmarkTitle: \1\nBookmarkLevel: 2\nBookmarkPageNumber: \2/g; \
s/^###\s(.*)\t(\d+)/BookmarkBegin\nBookmarkTitle: \1\nBookmarkLevel: 3\nBookmarkPageNumber: \2/g' bookmark.text得到如下的结果:
BookmarkBegin
BookmarkTitle: 出版说明
BookmarkLevel: 1
BookmarkPageNumber: 4
BookmarkBegin
BookmarkTitle: 目录
BookmarkLevel: 1
BookmarkPageNumber: 7
BookmarkBegin
BookmarkTitle: 第一章 民族主义的困惑
BookmarkLevel: 1
BookmarkPageNumber: 10
BookmarkBegin
BookmarkTitle: 民族主义的界定
BookmarkLevel: 2
BookmarkPageNumber: 14
…写入书签信息
做好以上准备工作,下面就可以将 bookmark.text 写入 PDF 中。但是在进行这一步之前,如果该 PDF 本身就有书签信息,需要先将其移除。

首先使用 PDFtk 将 input.pdf 的元数据提取出来,保存为 metadata.text:
pdftk input.pdf dump_data_utf8 output metadata.text然后使用下面的命令将其中已有的无用书签全部移除:
perl -0777 -i -pe 's/(NumberOfPages.*)[\s\S]*BookmarkPageNumber.*/\1/g' metadata.text接下来将我们前面制作好的书签信息文件 bookmark.text 合并到元数据文件 metadata.text 中,最后再用 PDFtk 将更新后的 metadata.text 写入 PDF 中,得到带有书签的 output.pdf:
gsed -i '/NumberOfPages.*/r bookmark.text' metadata.text
pdftk input.pdf update_info_utf8 metadata.text output output.pdf需要注意的是,这里使用了大多数 Linux 发行版预装的 GNU sed,而不是 macOS 预装的 BSD sed2。因此在 Linux 上,需要将 gsed 替换为 sed,而在 macOS 上,则需要通过 brew install gnu-sed 安装 GNU sed。一般情况下,使用 PDFtk 更新 PDF 元数据使用的是 update_info,但这里使用了 update_info_utf8 这个选项,这是为了处理中文等非 ASCII 字符的 编码问题,而对于英文书籍来说,使用 update_info 就可以了。
分步执行以上各个步骤略显麻烦,可以将这些命令集中在一起,写在一个 Makefile 中:
# Create bookmark info for PDF
.SILENT:
bookmark:
# Format the pagenumber, and plus the number of preface
cat pagenumber.txt | awk NF | while read line; do echo $$(($${line}+9)); done > realpage.text
# Combine headings and pagenumber correspondingly
paste heading.txt realpage.text > bookmark.text
# Format the Heading one, two and three
perl -i -pe 's/^#\s(.*)\t(\d+)/BookmarkBegin\nBookmarkTitle: \1\nBookmarkLevel: 1\nBookmarkPageNumber: \2/g; \
s/^##\s(.*)\t(\d+)/BookmarkBegin\nBookmarkTitle: \1\nBookmarkLevel: 2\nBookmarkPageNumber: \2/g; \
s/^###\s(.*)\t(\d+)/BookmarkBegin\nBookmarkTitle: \1\nBookmarkLevel: 3\nBookmarkPageNumber: \2/g' bookmark.text
# Create the metadata information for the scanned PDF
pdftk input.pdf dump_data_utf8 output metadata.text
# Remove existing bookmark information if there is
perl -0777 -i -pe 's/(NumberOfPages.*)[\s\S]*BookmarkPageNumber.*/\1/g' metadata.text
# Insert `bookmark.text` to `metadata.text`
gsed -i '/NumberOfPages.*/r bookmark.text' metadata.text
# Append the bookmark information into the PDF
pdftk input.pdf update_info_utf8 metadata.text output output.pdf
.PHONY: clean
clean:
# Remove auxiliary files
rm -f *.text复制上面的代码,粘贴到文本编辑器中并保存为 Makefile。在制作好 heading.txt 和 pagenumber.txt 后,调整第 6 行 $${line}+9 中的数字,然后执行 make bookmark,就可以得到带有书签的 PDF 书籍 output.pdf,执行 make clean 则会删除中间过程用到的扩展名为 .text 的辅助文件。
调整 PDF 页码
使用 DEVONthink 或 Zotero 提取 PDF 中的批注时,会有相应的页码,而我在写论文引用该页的时候,想要看到的是页眉或页脚中的页码,而不是 PDF 中的页码。而前文已提到,书籍页眉或页脚中的页码与 PDF 中的页码并不一致,因此,需要对 PDF 的页码进行调整,使其与书籍页眉或页脚中的页码保持一致。一般来说,书籍的前言部分页码标签为罗马数字,正文开始使用阿拉伯数字,而正是这个原因,导致 PDF 的页码与书籍页眉或页脚中的页码不一致。因此,调整 PDF 页码就是调整对应的页码标签。
在 Adobe Acrobat 中,打开需要调整页码的 PDF,在左侧缩略图中选中页面,点击右键选择「Page Labels…」,然后在出现的「Page Numbering」窗口中进行调整,包括需要更改的页码范围、页码前缀、起始页码等,其中 Style 一栏包括 6 个选项:
- 无页码标签 (None)
- 阿拉伯数字 (1, 2, 3, …)
- 小写罗马数字 (i, ii, ii, …)
- 大写罗马数字 (I, II, II, …)
- 小写英文字母 (a, b, c, …)
- 大写英文字母 (A, B, C, …)

考虑到 Adobe Acrobat 需要付费使用,且体验不是太好,这里提供另外一种调整页码的方式——直接编辑 PDF 源文件。
为了直接在文本编辑器中编辑 PDF,我们首先使用 PDFtk 对 PDF 进行 解压缩:
pdftk output.pdf output uncompress.pdf uncompress得到解压缩的 PDF 文件 uncompress.pdf 之后,就可以用文本编辑器如 VS Code 打开并编辑它。但考虑到扫描版 PDF 一般都很大,动辄几十甚至几百 MB,有百万行之多,用大多数文本编辑器打开都会卡顿,于是我们使用「编辑器之神」 Vim 来打开并编辑 PDF。
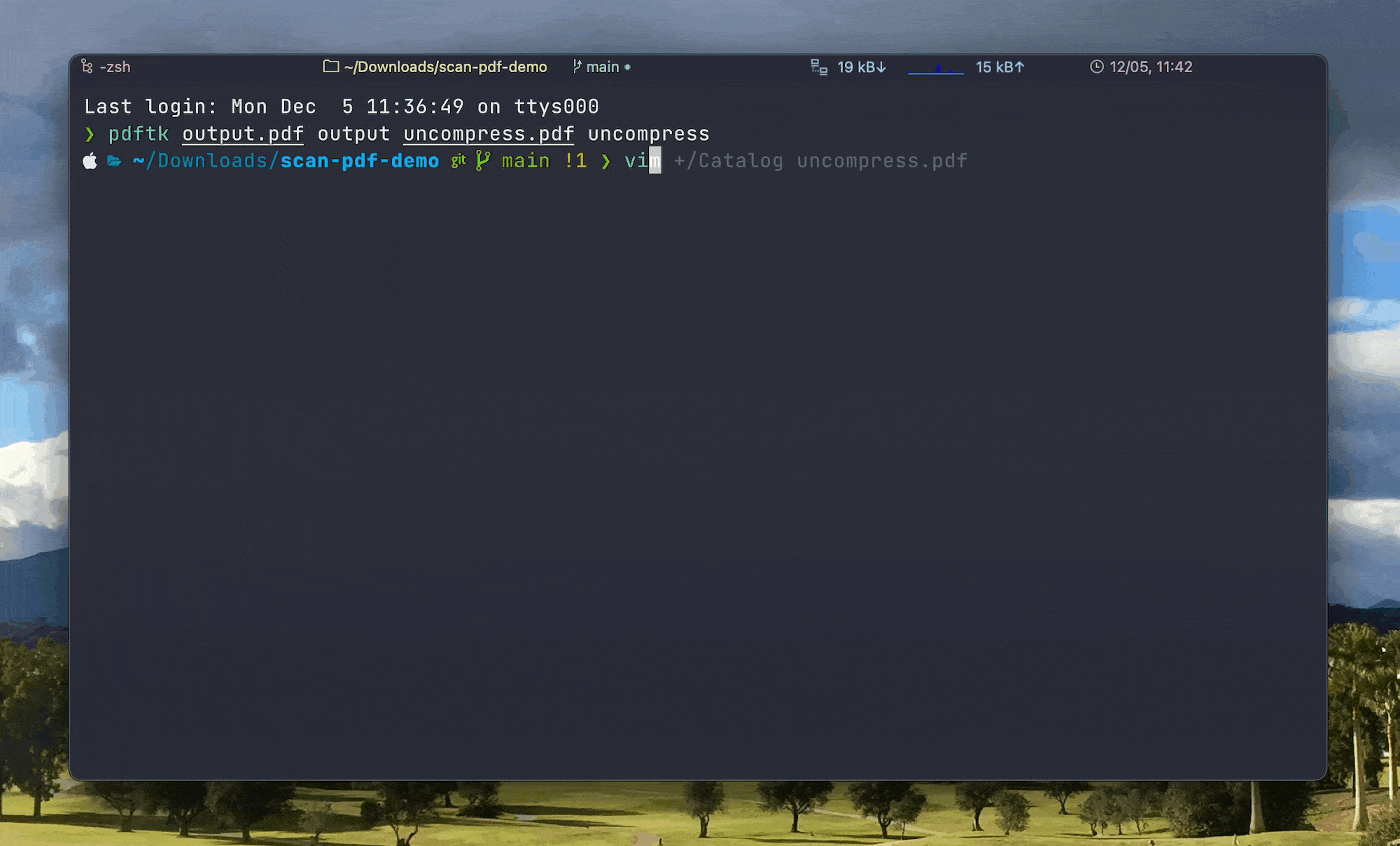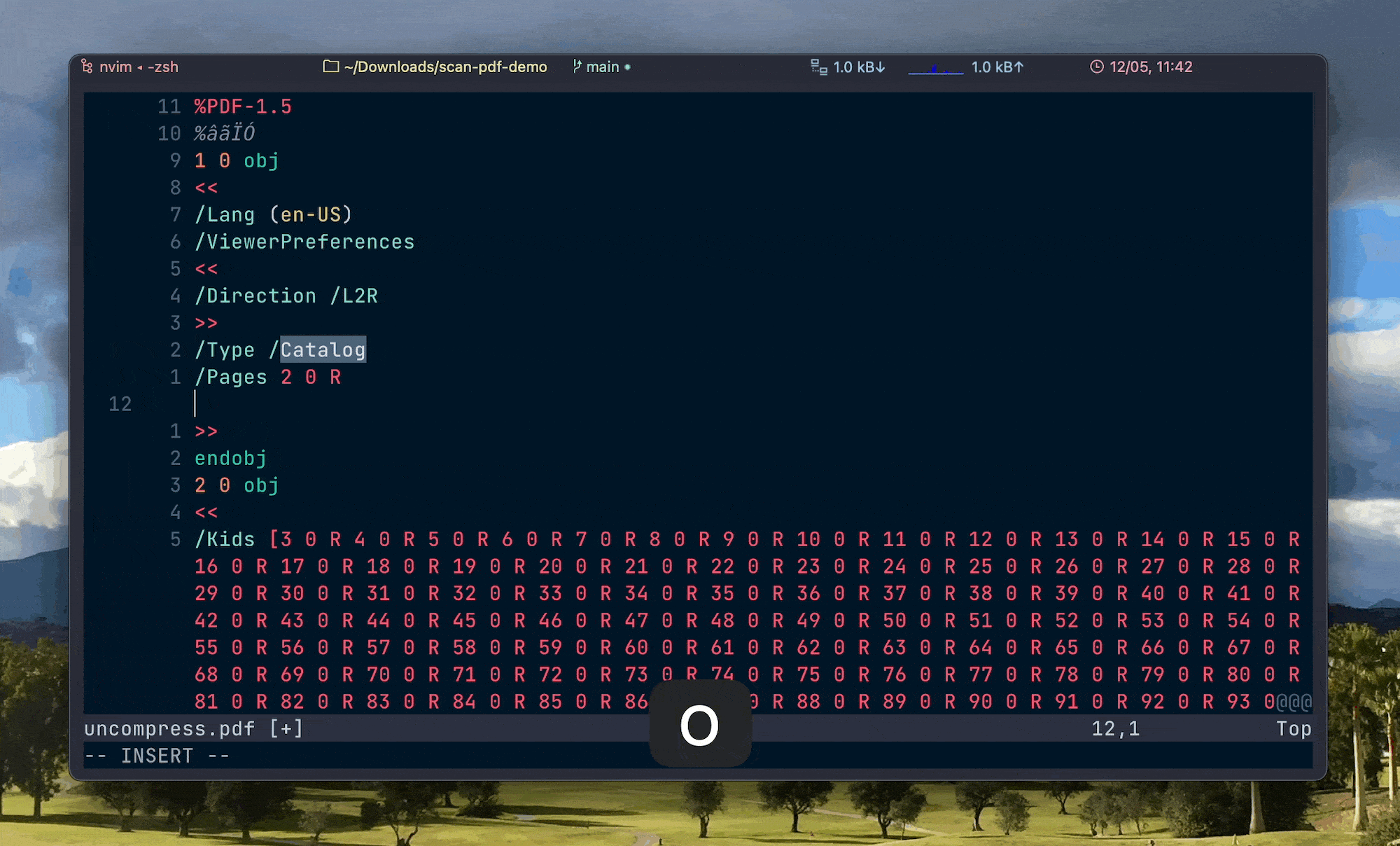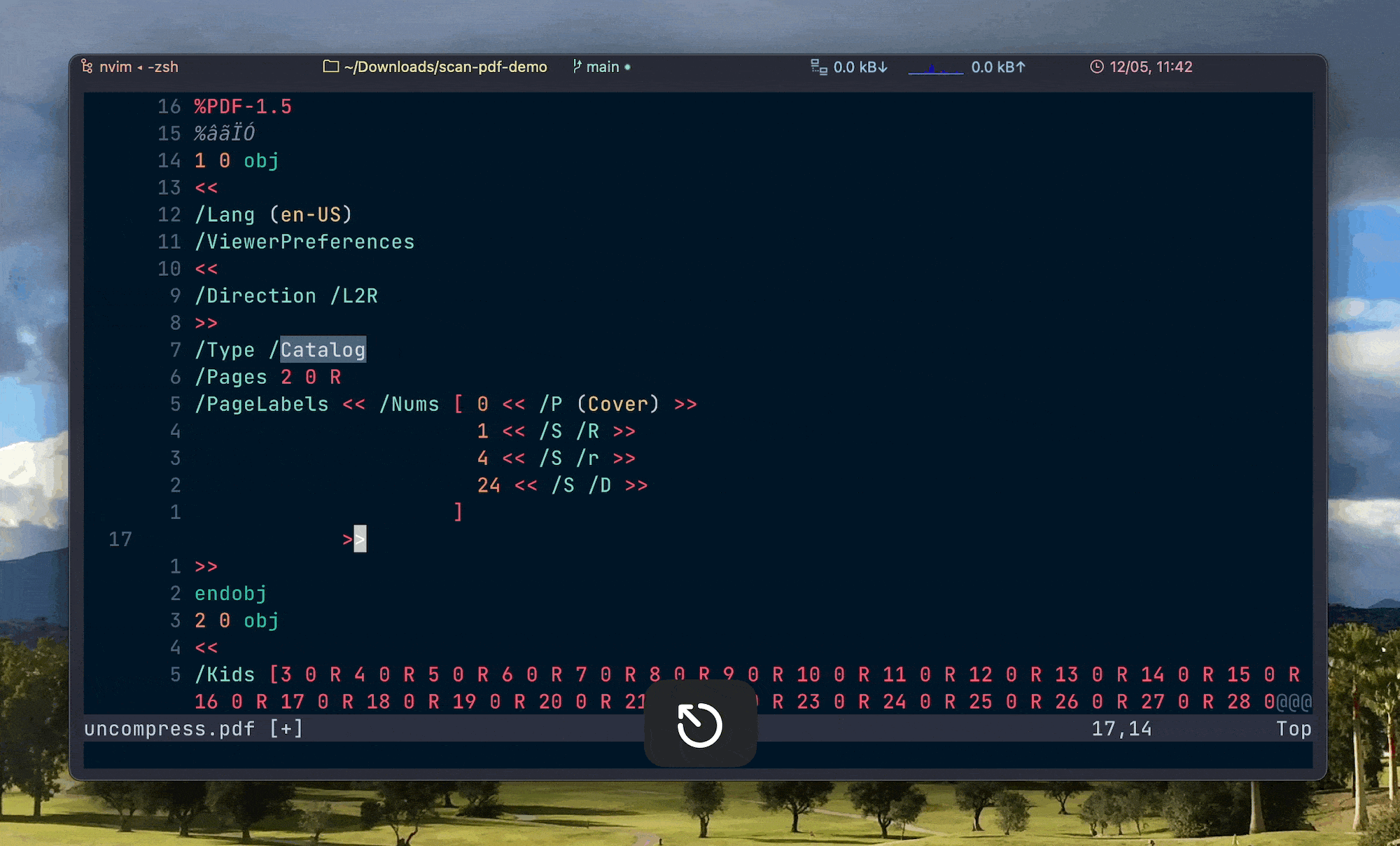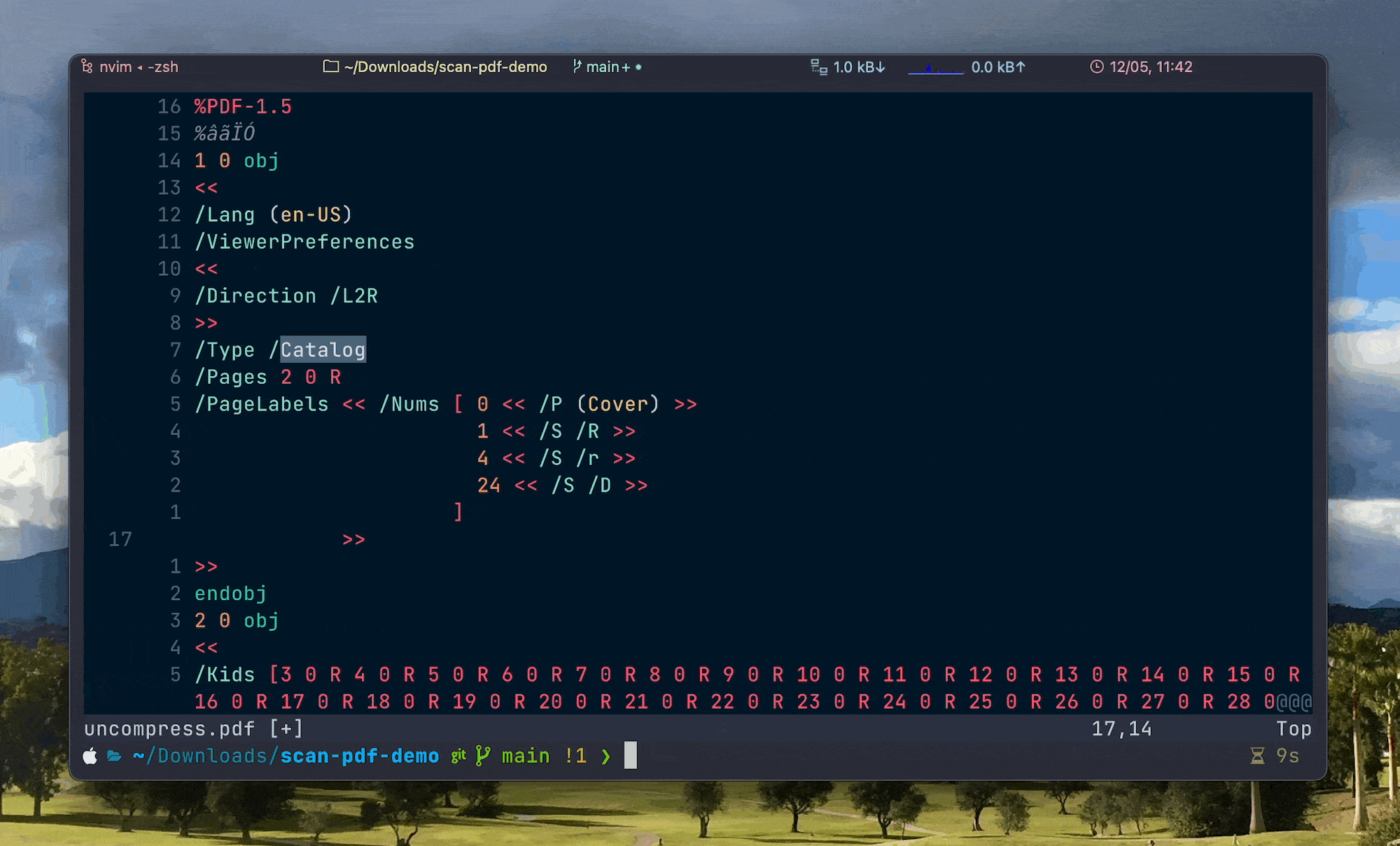
由于 PDF 的页码标签开头有一个独特字符 Catalog,因此可以在终端中输入 vim +/Catalog uncompress.pdf,就会在打开后将光标自动定位到 Catalog 所在的那一行。
接下来点击 j 移动光标到下一行,再点击 o 在下方插入一个空行并进入 Insert Mode,然后粘贴设置页码的文本,例如:
/PageLabels << /Nums [ 0 << /P (Cover) >>
1 << /S /R >>
4 << /S /r >>
24 << /S /D >>
]
>>上面的示例中,0 << /P (Cover) >> 表示第 1 页的页码标签为 Cover(PDF 中第 1 页的索引是 0 而不是 1),1 << /S /R >> 表示 2–4 页的页码标签为大写罗马数字,4 << /S /r >> 表示 5–24 页的页码标签为小写罗马数字,24 << /S /D >> 表示从 25 页到最后一页,页码标签全都为阿拉伯数字。
粘贴完成之后,按下 Esc 键退出 Insert Mode,进入 Normal Mode,然后输入 :wq 保存更改并退出 Vim。

最后,再使用 PDFtk 将 uncompress.pdf 压缩回去3:
pdftk uncompress.pdf output output.pdf compress打开压缩之后得到的 output.pdf,可以看到,页码显示效果与预期一致,修改成功。

小结
在本文中,我分享了将纸质书籍扫描成 PDF 并对其进行 OCR、添加书签、调整页码等步骤,基本实现了纸质书的「电子化」。当然,其中的部分操作不仅限于扫描版 PDF,对于一般的 PDF 文件也是适用的。如果完成上述操作之后,PDF 的体积变得非常大,你可以选择将它压缩一下,然后就可以愉快地阅读与分享电子版 PDF 书籍了。
前段时间 Z-Library 被美国政府封禁,很多人无法再从上面下载电子书了。尽管 Z-Library 面临不少争议,但它和 Sci-Hub 一样,实实在在降低了大多数人 获取知识的门槛,让亚非拉地区的学生也能下载到动辄几百美元的教材,让身处中国大陆的人轻松读到南美文学,甚至让 独立研究 成为可能。
如果你恰好有一本稀缺甚至绝版的纸质书,不妨按照本文分享的方法,把它扫描成 PDF 分享在互联网上,说不定地球上某个角落的人正在焦急地寻找这本书呢。促进知识的开放,需要我们每个人做出自己微小的贡献。试想,没有其他人的上传,Z-Library 怎么可能会有如此丰富的书籍呢?这也是我写这篇文章的最初动机:发挥去中心化的力量,缩小获取知识的鸿沟,促进知识的开放。
> 少数派请你做地图:城市声音收藏夹火热征集中,期待你创作的城市之声 🎧
> 下载少数派 2.0 客户端 、关注少数派公众号,解锁全新阅读体验 📰
> 实用、好用的正版软件,少数派为你呈现 🚀
© 本文著作权归作者所有,并授权少数派独家使用,未经少数派许可,不得转载使用。
如有侵权请联系:admin#unsafe.sh