团队科研成果分享2022.11.21-2022.11.27标题: Dynamic Security Assessment Framework for Steel Casting Workshops i 2022-11-25 14:43:34 Author: 网络与安全实验室(查看原文) 阅读量:44 收藏
团队科研成果分享
2022.11.21-2022.11.27
标题: Dynamic Security Assessment Framework for Steel Casting Workshops in Smart Factory
期刊: IEEE Transactions on Reliability
作者: Jinfang Jiang, Guangjie Han, Hongbo Zhu, Chuan Lin.
01
研究背景
BACKGROUND
研究背景
随着人工智能的快速发展,安全评估系统对于确保智能工厂的安全生产至关重要。安全性评估(SA)是工厂日常运营中观察/预测其运行状态的关键程序。在现代工厂中,大多数在用评估程序依赖于手动监控和各种报警传感器,从而产生了大量的人力和物力成本。随着无线传感器网络、大数据融合处理、云和雾计算的快速发展,整个工业生产系统正进入到一场新生的革命时期即工业4.0。它拥有更多的传感模式,为安全评估提供更好的解决方案,为现代工厂营造可持续的智能环境。
与传统的基于传感器的静态监测模式不同,视觉感知模式可以提供更多的动态监测结果,包括操作场景中人体和机械部件的运动状态以及它们之间的交互。通过使用一些鲁棒的方法,例如基于特征工程和基于学习的方法,在安全性评估中可取得优异的检测结果。
02
关键技术
TECHNOLOGY
关键技术
本文提出了一种新的安全评估框架,与传统的基于传感技术的静态监控系统不同,该框架能够通过视觉感知自动检测目标。我们使用基于骨架的图卷积网络(GCN)来生成动作词汇表,以作为动作到动作共现关系的中间表示,这些表示被编码到顺序交互模型中以形成交互表示。以钢水液位状态作为参考标签,将其序列输入到具有多层门控递归单元(GRUs)的递归神经网络(RNN)模型中,捕捉导致事故的关键交互作用,并利用注意力机制对行为进行重新加权,剔除无效交互作用,场景的预测标签和隐藏状态在多层GRU之间传递。最后,通过计算一个带有正则化交叉熵损失的联合目标函数,优化全局输出,实现对安全性的动态评估。在自主收集的合作伙伴I & S公司数据集和在线视频片段上,该框架的性能优于现有的安全评估方案。
论文主要贡献如下:
(1)应用了一种新的基于扩展骨架的编码器模板,该模板能够将人机交互行为封装为动作间关系(action-to-action relations,CAAR)的共现频率,作为操作场景识别的中间表示。基于视觉传感器上的轻量级网络NanoDet检测人体部位,将人体部位的顺序包围盒发送到云服务器,并将其输入到基于STGCN的架构中,采用距离划分策略为每个划分分配一个数字标签。
(2)利用外部支持向量机检测器将序列之间的关系填充到序列张量中。为了丰富每个时间窗口中的空间关系,操作符之间的方向,距离和一致性被顺序排列成交互向量。在多层GRU之间传递人类交互及其隐藏状态的预测标签,以优化DSA的全局输出。
(3)基于CAAR的DSA结果与SSA的结果不同,体现了不同交互操作的潜在影响,具体包括人为避免事故的瞬时操作,以及累积操作错误带来的安全风险。
03
算法介绍
ALGORITHMS
算法介绍
图1 提出的DSA框架架构
如图1所示,所提出的DSA框架组成部分包括操作员、设备(例如:机械部件、中间包和结晶器)和传感器。操作人员可以在铸钢车间的不同区域工作。视觉传感器拍摄操作者的动作,并利用其计算能力检测操作者的位置。位移传感器用于跟踪止动器的运动。所有的传感数据都被发送到云服务器,服务器可以通过基于骨架的GCN(Graph Convolutional Network)来分析人的动作。对于云服务器上的每个操作周期,人的动作在机械动作的四个固定大小的周期处对齐。每一个操作周期都可以得到结晶器液位的响应,该框架的目标是揭示液位与作用-作用共现之间的关系。因此一般过程包括: 动作词汇表生成、空间交互的中间表示以及顺序编码动作到动作关系。
1. 动作词汇表生成
在所提出的框架之前,可以基于深度架构快速检测对象,可以基于深度架构快速检测对象,并且通过回归一系列边界框B来覆盖对象。对于第i个操作者,在固定大小的采样窗口T期间,其运动轨迹被记录在框 的时间序列中。考虑到人体运动的复杂性,我们使用基于骨架的模型对个体动作进行分类,并为它们分配一组标签A。具体而言,利用OpenPose工具箱估计人体模板的关节点,并设定空间配置划分策略,将整个节点集划分为若干个子集。每个子集覆盖一组成员节点及其唯一的根节点。根据有限的人工操作,定义了5种特定的操作,其中包括“锤击”、“钩挂”、“推”、“拉”和“穿”。同时给予了漏钢、低、正常、高、溢出等五种钢水液位状态。
2. 空间相互作用的中间表示
通过操作分解,得到大量带有数值和周期标签的动作分量,形成可能产生液位变化的人机交互。我们更新了用于表示交互作用的对象到对象共现关系的中间表示。对于机械操作的每个周期,将其分解为四个周期,以附加一系列人类操作动作的注释。给定具有滑动时间窗T的总长度为T的视频V,原始视频被分成一系列子视频,这些动作可以被打包成表示共同发生的关系的统计矩阵:
其中 表示第k个子视频Vk中的第i个和第j个人类动作之间的共现的出现频率。我们使用严格的约束来扩展关系,以进一步提高识别精度。
3. 顺序编码动作到动作关系
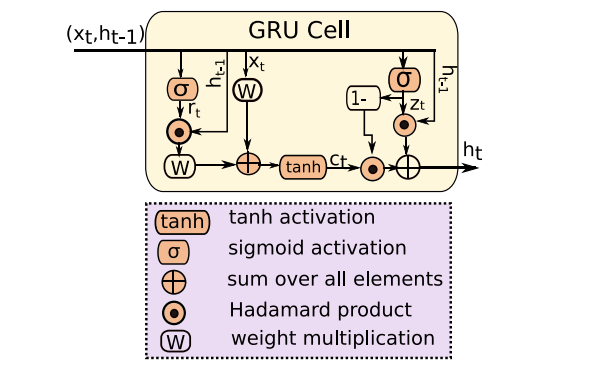
在实际生产过程中,相互作用与钢水液位之间的潜在因果关系已经得到验证,但导致铸造事故的因素却无法量化。大致认为是动作不当,如动作部件错误、手动操作时间早/晚、机械部件动作错误等。因此,我们顺序地将动作组件编码到固定大小的模板中。因此,我们将动作组件顺序编码到固定大小的模板中。特别地,在第k个子视频处,生成的模板被表示为: “范围(i)动作(i)关系(θ)关系(D)关系(C)范围(j)动作(j)”。在上述处理之后,每个空间关系都可以从张量展平为固定大小的向量,这更简单有效地将时空共生关系表示为三元组<action,relation,action>。然后,这些表示被输入GRU单元,以预测交互的DSA标签。这些相互作用在整个铸钢件中离散地执行。相邻但不连续的相互作用可能导致长期DSA标记。对于每个视频,我们可以使用这些离散交互的隐藏状态作为GRU模型的输入,以生成激活向量,经过最大池化,DSA类的最终输出是在两个完全连接的层和一个softmax层之后的结果。
图2 RNN模型中使用的GRU单元架构
04
实验结果
EXPERIMENTS
实验结果
1. 实验数据
通过合作伙伴I&S公司铸造车间的视觉传感器采集视频,这些传感器事先放置在每条生产线的三个视图中。从2018年11月到2019年12月,工控机记录的总时长为14452小时,包括视频记录以及相应的塞棒和钢水液位状态。包含人类动作的5112小时的视频是我们关注的关键信息,它们被分成4090/1022小时的39120/9315个场景的训练/测试集。正面/负面场景的比例约为1:4. 6。视频涵盖了所有预设的动作,并为一些未知的动作聚集了一个“其他”组,占所有动作的7. 52%。此外,部分操作人员反映液位计故障存在潜在风险。因此,我们应用帧间差分方法来校正标记。具有校正标签的场景占所有场景的不到3%。此外,为了获得一些严重事故的场景,我们从优酷网站下载了一些视频片段。
图3 操作员骨骼提取
2. 实验设置
并首先使用Openpose工具箱建立时空骨架模型。为了提取更高级的表示,9个时空图卷积层被分层级联以分别输出64个通道、128个通道和256个通道的特征向量。所有输出以0.5概率随机丢弃,以避免过度拟合。此外,每个级联包含以ResNet层结尾的三个卷积层。在全局池化之后,将生成的具有N×256维特征向量的张量按时间顺序馈送到两个Softmax分类器中,以预测动作类别和范围。衰减学习率列表设置为[0.01,0.001,0.0001],衰减步长为10个时期。
根据预定义动作的固定持续时间,2D窗口可以扩展到三维。详细的卷积操作与一般的基于3D CNN的对应操作相同,它为所有动作输出数字标签。
3. 实验结果
表1 四个视图的准确性
从表1可看出原始STGCN在四个视图上的精度全面领先于其他方法。与最初的STGCN不同,我们框架的扩展模板通过考虑更多的空间布局来重新加权微小动作组件之间的关系,而不是投票决定整个动作的特定语义的最终结果。
表2 不同方案的交互分类结果
如表2所示,对于交互分类一组人和机械操作映射到液位的响应。但实际上,反应存在时滞。因此,我们的工作将交互表示视为一个连续的因果过程,以输入RNN模型,交互分为五种短期安全状态。
图4 使用注意机制后选择的动作组件
从图4的第一行可以看出,两个操作者合作将钢粉推入中间包。该算法利用大尺度目标部分覆盖另一个目标,但被覆盖目标的关节点重新加权,使其与大尺度目标的关节点接近。在另一排,一名操作人员正双手拿着工具,对钢水进行穿孔,以手动测量液位。我们注意到他的被遮挡的左臂被重新加权以形成动作组件的鲁棒表示。
表3 不同方案的敏感性和CPM评分比较
在表3中,将本文的结果与两种最先进的场景识别方法进行了比较。它们的两种架构都是为具有组活动的场景的识别任务而设计的。在我们给定的铸造车间场景中,我们的方法优于其他两种方法。
05
总结
CONCLUSION
总结
本文提出了一种基于视觉感知场景识别的动态安全评估框架。作为一种替代传统传感器的监测方案,我们扩展了基于骨架的模板,改进了原始STGCN框架的输入,包括利用轻量级卷积网络NanoDet发现的操作工具进行的细微操作。基于定义的动作-动作共现关系,并考虑严格的时空一致性,将这些关系分层编码为注意动作序列。利用多尺度编码器,将CAAR和SAAR编码器的输出作为中间表示送入选通递归单元,预测交互向量的安全风险标签,进行动态安全评估。最后,在自主采集的数据集上进行场景识别,取得了较好的识别效果,说明该框架可以为智能工厂的动态安全评估提供一种有效的方案。
END
扫描二维码关注我们
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh