本文基于笔者对doop静态程序分析框架源代码和规则学习,并结合对目前漏洞公开技术细节的学习,修改增强doop app only模式下的分析规则后,实现通过doop工具识别commons text rce漏洞(CVE-2022-42889)。内容包含三部分,第一部分简单介绍doop分析框架,第二部分简单介绍commons text漏洞的原理和代码调用栈,第三部分重点介绍如何改造doop app only模式下的规则以识别commons text漏洞的污点信息流。
一、doop静态分析框架简介
doop静态分析框架由希腊雅典大学plast-lab Yannis Smaragdakis团队设计开发,目前看是一款开源领域的比较先进的程序静态分析框架,一些程序静态分析论文的理论也有通过doop的规则实现后实验。
doop整体架构简单明了,符合通常静态代码漏洞扫描工具扫描器内核的设计思路。doop架构上由groovy写的调用程序“粘合”在一起,通过调用fact-generator和datalog分析器,得出自动化的分析结果。
下面是笔者画的doop整体架构图,包含doop中一些关键的组件模块:

doop支持对java源码及字节码的分析,不过源码的jdk版本受限,建议直接使用字节码进行分析。doop的fact generator模块会对输入进行解析(例如jar包的解析或者类的resolve从而加载进必要的类信息到内存中),再调用soot、wala等工具生成jimple IR,在此基础上生成后续分析引擎需要的facts文件。而后doop使用LogicBlox(目前doop已不维护)或者Soufflé(开源的datalog分析引擎),基于facts文件和既定的datalog分析规则文件进行分析,得到最终的程序分析结果。
doop核心是其实现的一套datalog分析规则,其中包含了由粗糙到精细的context-insensitive、1-call-site-sensitive、1-call-site-sensitive+heap的丰富的静态程序分析策略等等等,同时通过在addons中添加了额外的对信息流分析、对spring等生态框架、对java反射特性的支持,十分强大。
以上是对doop的架构和功能的简单介绍,jar包信息的解析、规则的预处理、编译执行和解释执行、程序的并发设计或者由于大量sootclass加载造成的内存溢出问题等一些细节由于篇幅限制不在此介绍。
二、commons text rce漏洞简介
先对该漏洞进行简单介绍。
Apache Commons Text是一款处理字符串和文本块的开源项目,之前被披露存在CVE-2022-42889远程代码执行漏洞,这个漏洞目前网上的分析文章比较多,在此不做复述。该漏洞原理上有点类似log4j2,当然影响不可相比,其代码中存在可以造成代码执行的插值器,例如ScriptStringLookup(当然这里提到这个插值器是因为我们目标就是分析这一条sink污点流),同时没有对输入字符串的安全性进行验证导致问题。

借用网上公开的poc触发ScriptStringLookup中的代码执行,使用commons text 1.9版本 :

完整的漏洞调用栈如下:

从调用栈可以看出,通过调用commons text的字符串替换函数,可以调用到ScriptStringLookup类的lookup方法,从而调用scriptEngine.eval执行代码。可以看出该条漏洞链路较浅,但链路关键节点也涉及了接口抽象类的cast、输入字符串的词法分析状态机以及各种字符串的处理函数,作为实验对象非常合适。
三、commons text rce污点信息流的doop识别规则
我们选取上述二中commons text中org.apache.commons.text.StringSubstitutor replace函数作为source,ScriptEngine eval函数作为sink。
将doop设置app only模式去进行分析,doop在app only模式下会将!ApplicationMethod(?signature)加入isOpaqueMethod(?signature),这样一些分析不会进入jdk的类中,可以大大提高doop的分析效率。依据莱斯定理,静态程序分析难以达到完全的完备(truth或者perfect),也是尽可能优化sound。类似在企业级的SAST部署使用也是如此,也需要在扫描精度、扫描速度以及实际可用性中进行取舍或者平衡,所以doop的app only模式下在个人看来更接近实际嵌入到devsecops中的轻量级静态代码漏洞扫描的应用。
1.doop的datalog分析规则简单介绍
由于涉及doop app only规则的改造,首先先简单介绍doop使用的datalog规则。
doop目前维护使用开源的Soufflé分析datalog规则。datalog是声明式的编程语言,也是prolog语言的非图灵完备子集,所以本质上也是建立在形式逻辑中的一阶逻辑上。所以基础概念也是命题推导,在Soufflé的形式上就是表现为关系(relation)。
如下例子:

很明显可以看出该例子通过datalog定义的关系逻辑实现相等关系的自反性、对称性和传递性,首先定义了equivalence关系,该关系可以由rel1和rel2关系蕴涵得到,而equivalence的a需要满足关系rel1,b需要满足关系rel2。具体语法和高阶特性可以通过souffle-lang.github.io网站进行了解。
2.doop配置使用简单介绍
doop可以通过gradle去编译使用,需要提前在类unix系统中借助cmake编译安装Soufflé,doop的具体安装使用可以在[https://github.com/plast-lab/doop-mirror](https://github.com/plast-lab/doop-mirror中了解。
对doop的命令行使用进行简单,分析,有几个关键的命令参数,-i参数接受需要分析的文件(例如jar包),-a参数配置分析策略(例如是选择context sensitive还是context insensitive),--app-only参数配置开启doop的app only模式,--information-flow开启doop的信息流分析模式(可以用来做污点分析),--platform设置分析需要的jdk平台,--fact-gen-cores配置生成facts的并发性。
本文使用的doop命令参数:
-a context-insensitive --app-only --information-flow spring --fact-gen-cores 4 -i docs/commons-text.jar --platform java_8 --stats none3.重新编译打包commons text
这是我最初使用doop分析commos text的方法,主要为了尽可能减轻的对原生规则的侵入。doop在使用jackee进行分析事,分析入口的确定及一些mockobject的构建都需要依赖于对springmvc注解的识别。
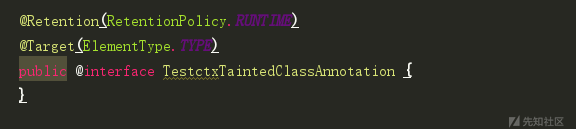
下载commons text的源码,自定义两条class和method注解TestctxTaintedClassAnnotation、 TestctxTaintedParamAnnotation:

注解实现为一个空注解,主要是为了标注一下我们的source,将注解打到对应的class类和方法:

重新编译打包为jar包,得到2中命令参数-i的commons-text.jar。
4.改造doop app only下的规则
doop的污点信息流识别依赖于指针分析结果,同时也依赖污点转移函数。doop中已经预置了多条污点转移函数,其中包含了字符串、链表、迭代器等基础类方法。
ParamToBaseTaintTransferMethod(0, "<java.lang.StringBuffer: java.lang.StringBuffer append(java.lang.Object)>").
ParamToBaseTaintTransferMethod(0, "<java.lang.StringBuffer: java.lang.StringBuffer append(java.lang.String)>").
ParamToBaseTaintTransferMethod(0, "<java.lang.StringBuffer: java.lang.StringBuffer append(java.lang.StringBuffer)>").
ParamToBaseTaintTransferMethod(0, "<java.lang.StringBuffer: java.lang.StringBuffer append(java.lang.CharSequence)>").
ParamToBaseTaintTransferMethod(0, "<java.lang.StringBuffer: java.lang.StringBuffer append(char[])>").
ParamToBaseTaintTransferMethod(0, "<java.lang.StringBuffer: java.lang.StringBuffer append(char)>").
BaseToRetTaintTransferMethod("<java.lang.Float: float floatValue()>").
BaseToRetTaintTransferMethod("<java.lang.String: byte[] getBytes(java.lang.String)>").
BaseToRetTaintTransferMethod("<java.lang.String: char charAt(int)>").
BaseToRetTaintTransferMethod("<java.util.Enumeration: java.lang.Object nextElement()>").
BaseToRetTaintTransferMethod("<java.util.Iterator: java.lang.Object next()>").
BaseToRetTaintTransferMethod("<java.util.LinkedList: java.lang.Object clone()>").
BaseToRetTaintTransferMethod("<java.util.LinkedList: java.lang.Object get(int)>").
BaseToRetTaintTransferMethod("<java.util.Map: java.util.Set entrySet()>").
BaseToRetTaintTransferMethod("<java.util.Map$Entry: java.lang.Object getValue()>").
BaseToRetTaintTransferMethod("<java.util.Set: java.util.Iterator iterator()>").
BaseToRetTaintTransferMethod("<java.lang.String: char[] toCharArray()>").
BaseToRetTaintTransferMethod("<java.lang.String: java.lang.String intern()>").然而其中没有包含String split函数的污点转移规则,需要添加上:
BaseToRetTaintTransferMethod("<java.lang.String: java.lang.String[] split(java.lang.String,int)>").如上述,doop自有的jackee规则肯定没有包含我们自定义的注解,所以需要在EntryPointClass、Mockobj等关系定义中添加对我们自定义的class污点注解的识别。
EntryPointClass(?type) :-
//...
Type_Annotation(?type, "org.apache.commons.text.TestctxTaintedClassAnnotation");
//...
MockObject(?mockObj, ?type) :-
//...
Type_Annotation(?type, "org.apache.commons.text.TestctxTaintedClassAnnotation");同时也需要添加param污点的注解。doop需要通过这些注解识别分析入口方法,构建污点mockobj,建立初始的指向关系等。
//...
mainAnalysis.VarPointsTo(?hctx, cat(cat(cat(cat(?to, "::: "), ?type), "::: "), "ASSIGN"), ?ctx, ?to) :-
FormalParam(?idx, ?meth, ?to),
(Param_Annotation(?meth, ?idx, "org.springframework.web.bind.annotation.RequestParam");
Param_Annotation(?meth, ?idx, "org.springframework.web.bind.annotation.RequestBody");
Param_Annotation(?meth, ?idx, "org.apache.commons.text.TestctxTaintedParamAnnotation");为了确保方法的可达性,我们还添加了:
ImplicitReachable("<org.apache.commons.text.StringSubstitutor: java.lang.String replace(char[])>") :- isMethod("<org.apache.commons.text.StringSubstitutor: java.lang.String replace(char[])>").但后续看不一定有必要,仅供参考。
通过注解我们在规则中定义了source,接下来需要定义sink,我们将ScriptEngine的eval方法定义为sink:
LeakingSinkMethodArg("default", 0, method) :- isMethod(method), match("<javax.script.ScriptEngine: java.lang.Object eval[(].*[)]>", method).正如前述,由于是在app only下,doop下通过OpaqueMethod关系过滤了jdk类的识别,这样会导致相应的上述预置的污点转移函数无法完成污点转移,所以需要另外定制规则流去将转移函数包含进数据流分析过程。
于是需要定义OptTaintedtransMethodInvocationBase关系,
.decl OptTaintedtransMethodInvocationBase(?invocation:MethodInvocation,?method:Method,?ctx:configuration.Context,?base:Var)
OptTaintedtransMethodInvocationBase(?invocation,?tomethod,?ctx,?base) :-
ReachableContext(?ctx, ?inmethod),
//Reachable(?inmethod),
Instruction_Method(?invocation, ?inmethod),
(
_VirtualMethodInvocation(?invocation, _, ?tomethod, ?base, _);
_SpecialMethodInvocation(?invocation, _, ?tomethod, ?base, _)
).在此基础上,为了完成新的污点转移,doop需要根据以下自定义规则分析出返回值的类型信息
.decl MaytaintedInvocationInfo(?invocation:MethodInvocation,?type:Type,?ret:Var)
MaytaintedInvocationInfo(?invocation, ?type, ?ret) :-
Method_ReturnType(?method, ?type),
MethodInvocation_Method(?invocation, ?method),
AssignReturnValue(?invocation, ?ret).
.decl MaytaintedTypeForReturnValue(?type:Type, ?ret:Var, ?invocation:MethodInvocation)
MaytaintedTypeForReturnValue(?type, ?ret, ?invocation) :-
MaytaintedInvocationInfo(?invocation, ?type, ?ret),
!VarIsCast(?ret).基于以上的污点转移过程分析规则,应用到污点变量的转移分析规则中
VarIsTaintedFromVar(?type, ?ctx, ?ret, ?ctx, ?base) :-
//mainAnalysis.OptTaintedtransMethodInvocationBase(?invocation,?method,?base),
mainAnalysis.OptTaintedtransMethodInvocationBase(?invocation,?method,?ctx,?base),
MaytaintedTypeForReturnValue(?type, ?ret, ?invocation),
BaseToRetTaintTransferMethod(?method).
//mainAnalysis.VarPointsTo(_, _, ?ctx, ?base).同时也需要重新定义LeakingSinkVariable关系,因为我们这里自定义的sink方法也是Opaque方法,这样才能识别到我们的ScriptEngine 的eval方法。
LeakingSinkVariable(?label, ?invocation, ?ctx, ?var) :-
LeakingSinkMethodArg(?label, ?index, ?tomethod),
mainAnalysis.OptTaintedtransMethodInvocationBase(?invocation,?tomethod,?ctx,?base),
//mainAnalysis.VarPointsTo(_, _, ?ctx, ?base),//here problem
ActualParam(?index, ?invocation, ?var).从上面规则的定义可以看出,改造的流程还是比较清晰的,并且通过关系的名字,这些关系的含义和用途也很容易理解。添加这些自定义规则到我们的doop分析中运行,在结果中可以看出,doop完成了对commons text的污点信息流的识别。
在结果集中的LeakingTaintedInformation.csv文件中可以找到我们需要捕捉到的souce-sink流,
default default <<immutable-context>> <org.apache.commons.text.lookup.ScriptStringLookup: java.lang.String lookup(java.lang.String)>/javax.script.ScriptEngine.eval/0 <org.apache.commons.text.StringSubstitutor: java.lang.String replace(java.lang.String)>/@parameter0LeakingTaintedInformation.csv给出了污点信息。包括污点的标签(这里是默认的default,可以自定义),sink方法的调用信息,该sink方法对应的污点源头souce信息。
如上图可以看出org.apache.commons.text.lookup.ScriptStringLookup: java.lang.String lookup(java.lang.String)中调用到javax.script.ScriptEngine.eval,并且污点的源头是org.apache.commons.text.StringSubstitutor: java.lang.String replace(java.lang.String)方法的参数parameter0。
同时,在结果集中的AppTaintedVar.csv文件也可以看到具体的应用代码中由于污点传播过程中的被污染的变量.以上面commons text 漏洞执行方法栈中的resolveVariable方法为例:

可以看出方法中被污染的入参variableName、buf,还有resolver,以及$stack7等(这是经过soot生成jimple的过程中SSA pack部分优化新增的栈变量)。

基于这两个结果集基本可以看出漏洞的触发流程或者说污点的传播过程(虽然不是特别直观),如果需要也可以再搭配生成的CallGraphEdge.csv去更方便的进行分析。
四、总结
doop直接用来分析大型项目需要一定的计算资源,并且无论是规则的定制还是分析结果查看都不是特别直观,毕竟它的设计初衷就是一款分析框架,用在实际漏扫漏洞挖掘中可能需要进一步包装修改 。但可以看出,doop作为一款优秀的开源静态分析框架,在算法上毋庸置疑是比较先进和丰富的,而且基于开源的算法规则,我们可以任意去定制我们需要的分析逻辑。其与codeql在设计思路也较为相近,将程序信息提取后生成数据库,开放查询接口,将程序分析转变为数据关系的查询,可以扩展出更多的用途。
目前网上深入分析doop的文章不是特别多,笔者水平有限平时也无时间投入做专门技术研究,希望师傅们指正和私信交流。
如有侵权请联系:admin#unsafe.sh