前言
java-object-searcher作为一款java内存对象搜索工具,能够快速定位在内存中关键变量在内存中的具体位置
不仅能够快速找到特定的中间的回显方法,更能够定位到我们自定义的任何关键词路径,我们这篇就详细的看看这个工具的具体实现原理
使用方法
根据readme的描述,可以直接在github下载源码,之后使用maven打包成jar包
- 可以选择将其添加在目标项目中的classpath中
- 又或者是直接将该jar包添加在JDK的ext目录下,在加载JDK包的同时加载这个jar到classpath
我们直接对readme中的案例进行调试分析
//设置搜索类型包含Request关键字的对象
List<Keyword> keys = new ArrayList<>();
keys.add(new Keyword.Builder().setField_type("Request").build());
//定义黑名单
List<Blacklist> blacklists = new ArrayList<>();
blacklists.add(new Blacklist.Builder().setField_type("java.io.File").build());
//新建一个广度优先搜索Thread.currentThread()的搜索器
SearchRequstByBFS searcher = new SearchRequstByBFS(Thread.currentThread(),keys);
// 设置黑名单
searcher.setBlacklists(blacklists);
//打开调试模式,会生成log日志
searcher.setIs_debug(true);
//挖掘深度为20
searcher.setMax_search_depth(20);
//设置报告保存位置
searcher.setReport_save_path("D:\\apache-tomcat-7.0.94\\bin");
searcher.searchObject();
实现原理
首先我们看看项目结构

分为三个package, entity / searcher / utils
entity
在entity包下定义了三个类Blacklist / Keyword / NodeT
Blacklist
其中Blacklist类,顾名思义,就是一个黑名单类

定义了三个变量属性field_name / field_value / field_type,分别代表着需要过滤的类名 / value / 类型
我们可以注意到他的构造方法传入的是一个内部静态类对象

通样是对相对的属性进行操作的方法
作者建立这个黑名单的目的就是减少搜索的对象数量,凭借着经验,可以将完全不可能存在有目标对象的对象添加进入黑名单中,大大的减少对象搜索的数量,加快寻找的速度
比如说
- java.lang.Byte - java.lang.Short - java.lang.Integer - java.lang.Long - java.lang.Float - java.lang.Boolean - java.lang.String - java.lang.Class - java.lang.Character - java.io.File ....
这些基本的数据类型,可以果断的添加进入黑名单加快速度
Keyword
而对于Keyword类,和Blacklist类具有类似的结构

设置该类的目的,主要是设置我们需要寻找的对象的信息,什么名称?什么值?什么样的类型?
NodeT
对于这个类同样具有相同的数据结构

主要是记录查看目标的过程中经历过的每一个结点,方便在最后找到目标之后输出
其中chain属性记录的是这个利用链,而field_name记录的是当前的节点的名称, 而field_object记录的就是当前节点的类对象
而最重要的就是Interger类型的属性current_depth,这个用来记录当前节点相比较于入口的深度,用来和之后在搜索器中会提到的最大搜索深度进行比较
searcher
在这个包下,定义的是三个搜索器
- 普通的版本:JavaObjectSearcher
- 采用广度优先算法进行搜索:SearchRequestByBFS
- 采用深度优先算法进行搜索:SearchRequestByDFS
SearchRequestByBFS
我们首先看看常用的采用广度优先算法的搜索器
在创建一个搜索器的时候,传入的是一个target目标对象和一个List<Keyword>列表

这里的第一个参数就是我们需要搜索的入口,一般是Thread.currentThread()或者Thread.getThreads从线程对象中获取想要的目标
在进行赋值之后

将一个NodeT节点对象添加在q这个队列属性的末尾
在创建了这个搜索器之后,我们能够进行相应的个性化设置,比如
设置黑名单

设置最大的搜索深度

设置最后Gadget的输出路径

设置是否调试,设置为true之后,将会输出运行过程中的日志文件

.........
在设置之后就调用对应的searchObject方法进行搜索
首先就是调用initSavePath初始化保存位置

之后直接就进入了一个while死循环

直接一串的do / while结果,在获取了q这个队列中的首部的节点信息之后
一步一步的进行判断
首先是判断搜索深度,之后就是搜索对象是否为null,再然后就是调用CheckUtil.isSysType判断该对象是不是系统类型

最后就是判断是否是在黑名单中
之后就是进行对象的匹配

在进行匹配之前,首先要判断在visited属性中是否存在有我们匹配的对象,这个属性的建立就是用来避免重复匹配相同的对象
如果没有匹配过,在将目标对象添加进入该属性中之后调用了MatchUtil.matchObject方法进行匹配
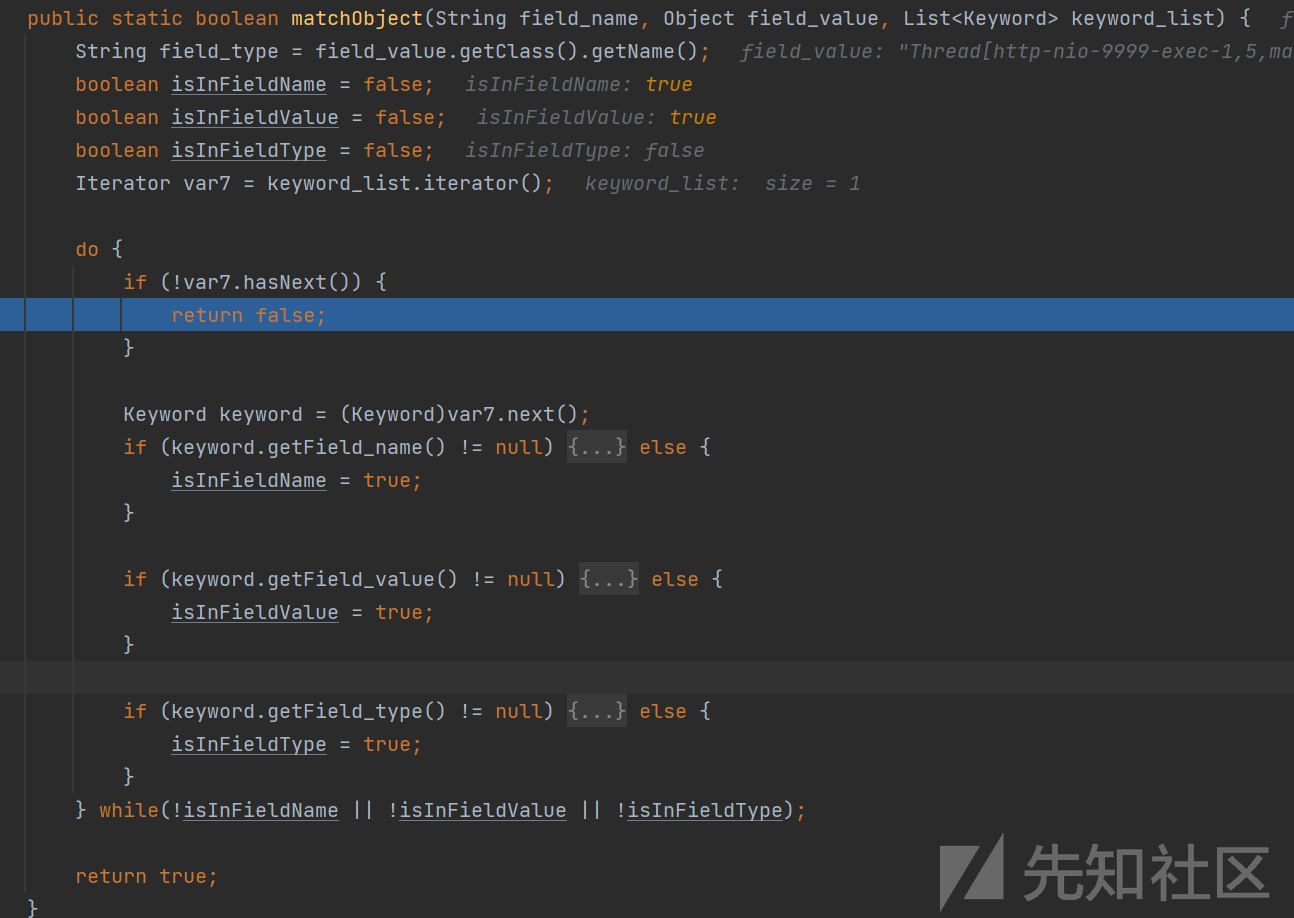
对于这个方法的实现,首先是将几个布尔变量初始化为false,之后就是通过do / while结构来遍历匹配传入的keyword_list信息
通过获取对应的Keyword类对象的信息,如果存在有对应的field_name / field_value / field_type描述,将会调用对应的isIn方法进行匹配
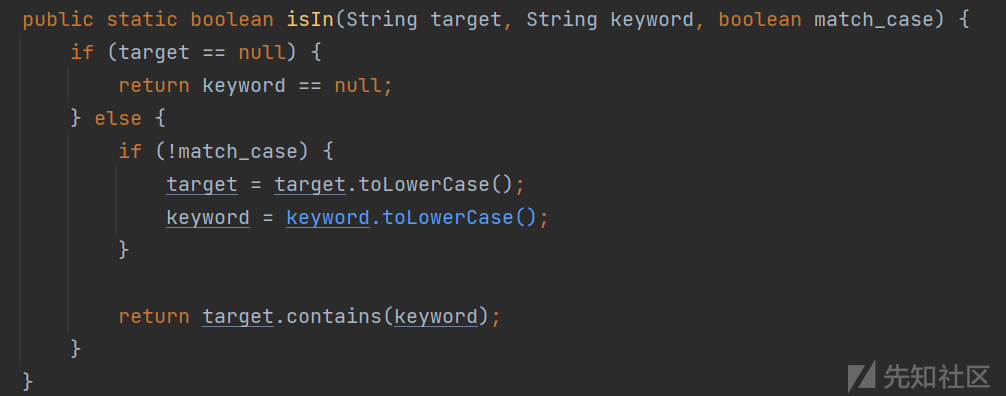
就是简单的将目标和关键词都转化为小写的字符串之后,使用contains方法进行匹配,因为这里使用的是contains方法而不是equals,所以这里是支持模糊匹配的方式的
如果没有匹配到,将会返回false
以至于在最后的while判断语句中返回了true,继续进行下一个Keyword对象的匹配
当然,如果这里能够匹配成功的话,返回的是true,将会进入if语句中

就会调用CommonUtil.write2log方法将对应的调用链进行记录

这里因为开启了is_debug选项,所以将会进行日志的记录
之后就是一步一步拆开目标
这里将其分为了Map / Array / Class三种
首先看看Map对象的处理
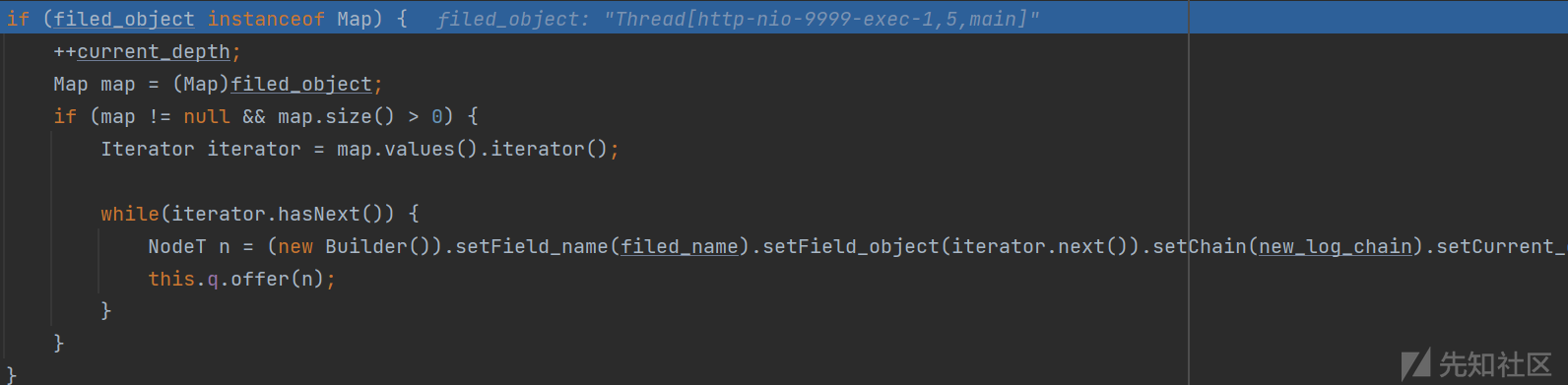
首先是将搜索深度加一,之后将该对象的所有Values生成对应的NodeT对象,之后将其添加进入q这个队列的末尾

如果目标对象对一个数组对象,通过在将其深度加一之后,遍历数组中的所有元素,通过相关信息生成对应的NodeT对象之后将其添加到q这个队列的末尾
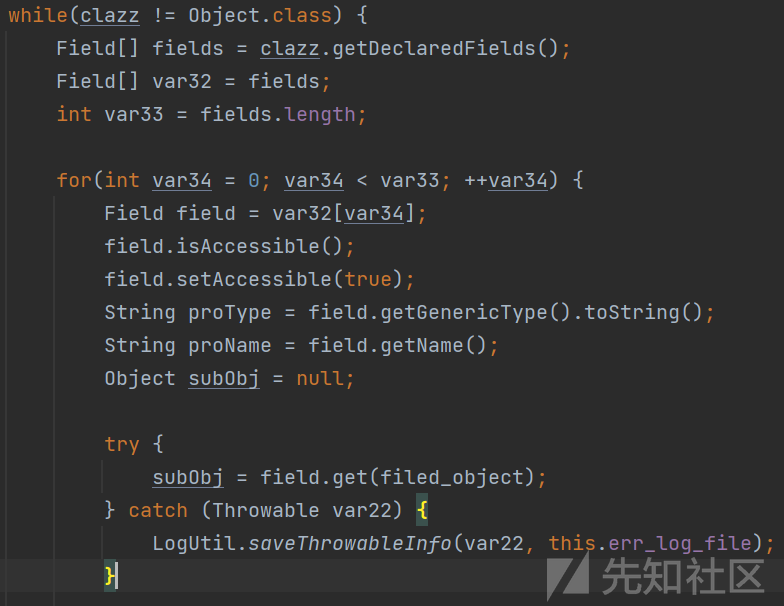
而如果目标对应是一个Class类对象,且其不是Object类

通过反射获取该类对象的所有属性

之后在对属性对象进行筛选之后,首先会判断该属性是否是一个List对象
如果是,将会将其深度加一,之后获取所有的元素生成对应的NodeT对象之后添加进入q这个队列的末尾
后面同样也有着是否是Map对象的判断和处理

也有着类似的是否是数组的判断和处理

如果不是这些特殊的类型就直接使用属性对象的相关信息生成了一个NodeT对象添加进入队列中

最后的最后,在处理了该对象的所有属性之后,调用该类的getSuperclass方法获取父类的所有属性进行同样的处理,这个步骤的终点就是获取到Object类对象
在这样的处理之后,就能够将该层的所有属性生成对应的NodeT对象放置在q这个队列中等待进行匹配
最后进入了最外层的while死循环
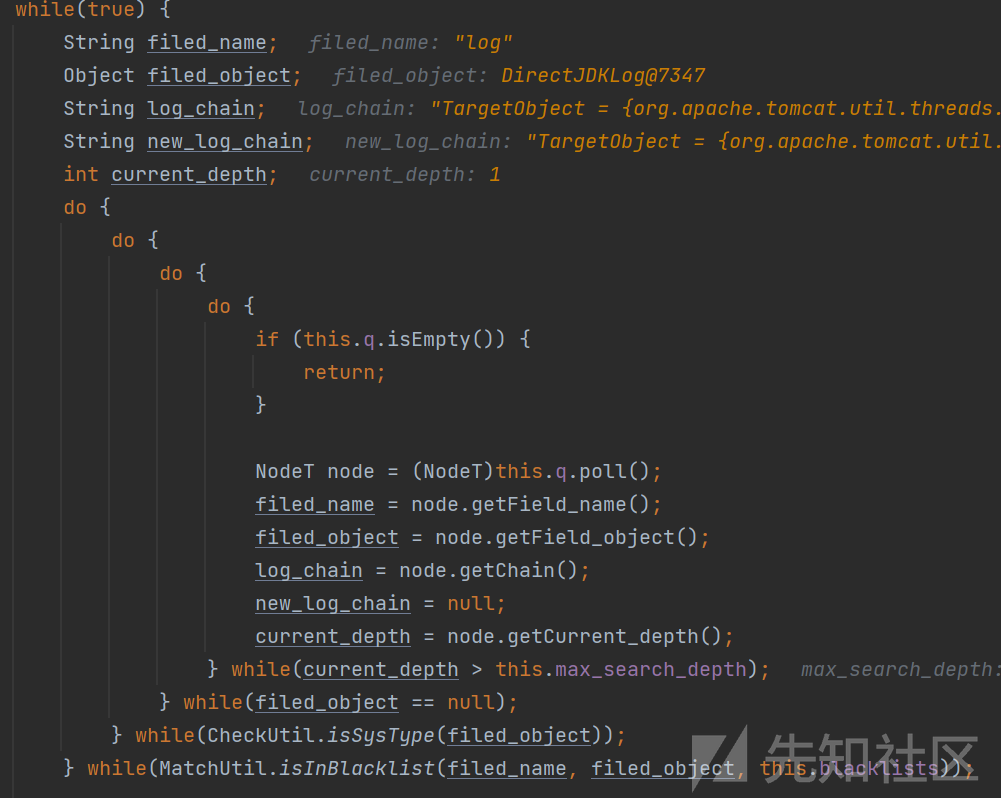
之后就是同样的操作,取出队列中的头部结点进行匹配,就这样筛选出所有的对象
他这里主要是处理匹配每次都只是取出头部第一个来进行首先匹配来达到广度优先算法的实现
SearchRequestByDFS
这个搜索器和上面搜索器在实现方面没有很大的区别
主要就是算法的实现
在上个搜索器中主要是定义了一个队列q,其中存放了一个个NodeT对象来存储节点信息,每次在进行目标匹配的时候总是取出队列中的首部结点,通过这样的设计思路,达到了广度优先算法的实现
而对于SearchRequestByDFS这种基于深度优先算法的实现,并没有定义一个队列来进行存储,而是采用,即时匹配的原则进行实现
具体点来看看,主要是在searchObject方法的实现上有所不同
在这个搜索器中有两个重载方法

在使用这种搜索器的时候只需要调用无参方法就行了,对于目标对象的设置,在创建对象的时候进行设置
主要看看有参方法的实现

首先开局就是判断搜索深度和筛选目标对象
之后判断目标对象的类型,首先如果是Map对象
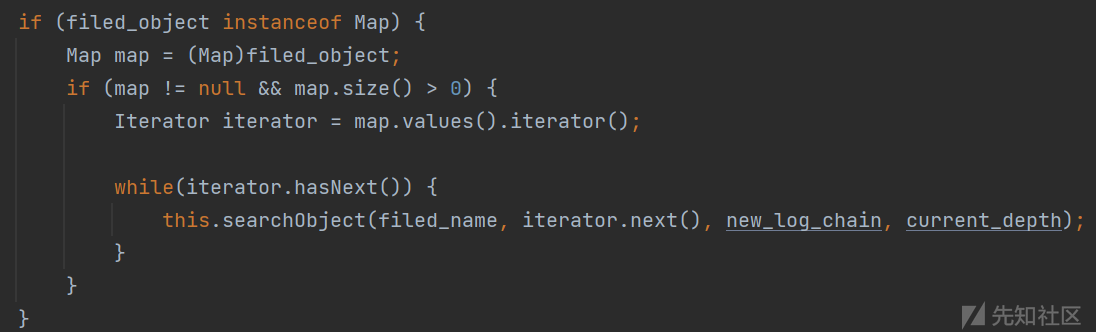
直接获取其中的所有values,依次调用searchObject方法进行匹配,这里就会一直向内嵌套,直到将一个value对象匹配到底,或者是到达最大搜索深度才会截至继续匹配下一个value值
如果目标对象是数组对象

同样类似的思路,将会即时调用searchObject方法进行匹配
又或者是一个类对象

获取所有的属性对象进行匹配
结束之后会继续使用其父类进行匹配

这个搜索器主要是通过即时匹配的方式进行深度优先算法的实现,类似于递归的方式进行嵌套使用来实现
尝试搜索
//设置搜索类型包含Request关键字的对象 List<Keyword> keys = new ArrayList<>(); keys.add(new Keyword.Builder().setField_type("Request").build()); List<Blacklist> blacklists = new ArrayList<>(); blacklists.add(new Blacklist.Builder().setField_type("java.io.File").build()); SearchRequstByBFS searcher = new SearchRequstByBFS(Thread.currentThread(),keys); searcher.setBlacklists(blacklists); searcher.setIs_debug(true); searcher.setMax_search_depth(10); searcher.setReport_save_path("xx"); searcher.searchObject();
我这里的环境是springboot 2.5.0的环境
在运行搜索器之后得到结果

选用这条链子能够构造回显
参考
如有侵权请联系:admin#unsafe.sh