
UPack(Ultimate Pack)是一种运行时压缩器,经过UPack压缩后的PE文件的文件头会出现非常奇怪的变形,这种变形会导致许多PE装载器和PE模板浏览器都无法正确的解析它的结构。后来UPack被广泛用于压缩病毒,木马,恶意代码等,由于许多情况下无法被作为PE文件进行解析,所以在当时可以绕过许多杀毒软件,现在基本上所有的杀毒软件都将UPack压缩的文件识别为恶意文件。
在调试一个UPack压缩的PE文件时要注意在杀毒软件中设置信任或者先暂时关闭杀毒软件,本篇文章的调试使用Windows XP下的notepad.exe进行分析。
概述中讲到UPack是一种运行时压缩器,那么什么是运行时压缩器?这里简单讲一下:
我们平时用到的诸如7z、WinRAR等都属于是普通压缩器,这种压缩器压缩后的文件是无法执行的而且基本上都有自己独特的后缀,但是运行时压缩器压缩后的PE文件是可以直接运行的,被压缩的程序在进入内存的瞬间会被程序中自带的解压代码解压出来放入内存并正常执行。
所以运行时压缩器和普通压缩器的最大区别就在于被压缩后的文件是否可以直接执行。
对于一个PE文件来说最重要的部分就是文件头,那么我们先使用UPack压缩器将notepad.exe进行压缩处理,得到一个notepad_packed.exe,之后使用十六进制文件编辑器将这个压缩后的PE文件打开(这里使用的是010Editor):

我的010editor使用了PE的模块化工具,再打开PE时会按照PE的标准格式进行解析,但是在打开压缩后的notepad.exe时发现它解析失败了,010editor的模块工具是无法正常识别这个压缩后的PE文件的,所以我们需要一个功能更强大的PE解析器:Stud_PE(下载链接放在文末)。下面使用Stud_PE来看一下这个变形的PE头
正常PE头与变形PE头的比较:

Stud_PE初步解析出了这个变形的PE文件头,可以看见一些非常奇怪的信息:

File Header的可选头大小变成了0x148。

节区头数量变为了0xA,这些都与正常的PE头相去甚远,下面来看看正常的notepad.exe的文件头:

可以看见在变形的PE头中,PE的文件头表示位置非常靠前,并且在文件头中设置出现了函数名称,这些看似非常离谱的操作其实都非常巧妙,下面逐步分析。
重叠文件头:
在UPack压缩后的PE文件头中, _IMAGE_DOS_HEADER与 _IMAGE_NT_HEADERS其实是重叠的,先来复习一下 _IMAGE_DOS_HEADER结构体的成员:(代码来源为winnt.h)
typedef struct _IMAGE_DOS_HEADER { // DOS .EXE header
WORD e_magic; // Magic number
WORD e_cblp; // Bytes on last page of file
WORD e_cp; // Pages in file
WORD e_crlc; // Relocations
WORD e_cparhdr; // Size of header in paragraphs
WORD e_minalloc; // Minimum extra paragraphs needed
WORD e_maxalloc; // Maximum extra paragraphs needed
WORD e_ss; // Initial (relative) SS value
WORD e_sp; // Initial SP value
WORD e_csum; // Checksum
WORD e_ip; // Initial IP value
WORD e_cs; // Initial (relative) CS value
WORD e_lfarlc; // File address of relocation table
WORD e_ovno; // Overlay number
WORD e_res[4]; // Reserved words
WORD e_oemid; // OEM identifier (for e_oeminfo)
WORD e_oeminfo; // OEM information; e_oemid specific
WORD e_res2[10]; // Reserved words
LONG e_lfanew; // File address of new exe header
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;其中最重要的成员就只有两个:
e_magic
e_lfanew分别是魔数和NT文件头的起始位置,在压缩后的文件头中来找一下这两个信息:

开头是固定的4D 5A(MZ的ASCII码值),e_lfanew的值为0x10
由于_IMAGE_NT_HEADERS的开始位置其实是由e_lfanew这个值决定的,将 _IMAGE_NT_HEADERS的位置置于 _IMAGE_DOS_HEADER之中,利用了DOS头中没有用的部分,这样就节约了空间也使PE装载器的反调试变得更困难。
_IMAGE_FILE_HEADER.SizeOfOptionalHeader:
为了确定OptionalHeader的位置,首先看一下FILE_HEADER结构体:
typedef struct _IMAGE_FILE_HEADER {
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;在在大多数PE文件头中,OptionalHeader的大小看起来是固定的,32位下是0xE0,在64位下是0xF0。
其实这是一个误区,OptionalHeader的具体大小其实是由FILE_HEADER中的SizeOfOptionalHeader来决定的,这样的设计就为这种超越常理的PE头提供了条件,,回到Stud_PE中看一下这个值:

这个值是0x148,比正常的32位OptionalHeader的大小要大一点,那么为什么要改变这个值呢?这是由于压缩器将PE头扭曲后,为了让其能够正常运行就需要进行解码,而进行解码的代码就放在额外的区域之中。
首先来计算一下SECTION_HEADER的起始位置,前面得到OptionalHeader的大小为0x148,OptionalHeader的起始位置是0x28,所以SECTION_HEADER的起始位置应该是:0x28+0x148 = 0x170,而OptionalHeader结束的位置的地方是0xD7,所以从0xD7到0x170这段空间中存储的就是程序的解码代码,也就是下面这个区域:

进入OD中看下这部分代码的操作:

中间出现了rep和stos这两个非常明显的循环以及传送指令,这其实就是程序再将解码出的代码传送到相应区域,后面的调试中会再次接触到解码代码。
_IMAGE_OPTIONAL_HEADER.NumberOfRvaAndSizes:
按照常规的PE头,处于OptionalHeader末尾的数据目录数组的个数应该是0x10,其实这个数目是由OptionalHeader中的NumberOfRvaAndSizes来决定的,回头看一下前面找到的这个信息:

然后再来看一下数据目录的完整结构:
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;以及数据目录的0x10个完整成员:
#define IMAGE_DIRECTORY_ENTRY_EXPORT 0 // Export Directory 导出表:动态链接库导出的函数会显示在这里
#define IMAGE_DIRECTORY_ENTRY_IMPORT 1 // Import Directory 导入表:写程序时调用的动态链接库会显示在这里
#define IMAGE_DIRECTORY_ENTRY_RESOURCE 2 // Resource Directory 资源表:图片,图标,字符串,嵌入的程序都在这里
#define IMAGE_DIRECTORY_ENTRY_EXCEPTION 3 // Exception Directory 异常目录表:保存文件中异常处理相关的数据
#define IMAGE_DIRECTORY_ENTRY_SECURITY 4 // Security Directory 安全目录:存放数字签名和安全证书之类的东西
#define IMAGE_DIRECTORY_ENTRY_BASERELOC 5 // Base Relocation Table 基础重定位表:保存需要执行重定位的代码偏移
#define IMAGE_DIRECTORY_ENTRY_DEBUG 6 // Debug Directory 调试表
// IMAGE_DIRECTORY_ENTRY_COPYRIGHT 7 // (X86 usage)
#define IMAGE_DIRECTORY_ENTRY_ARCHITECTURE 7 // Architecture Specific Data 缓存信息表:有一些保留字段必须是0
#define IMAGE_DIRECTORY_ENTRY_GLOBALPTR 8 // RVA of GP 全局指针偏移目录
#define IMAGE_DIRECTORY_ENTRY_TLS 9 // TLS Directory 线程局部存储(暂时未知)
#define IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG 10 // Load Configuration Directory 载入配置
#define IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT 11 // Bound Import Directory in headers 存储一些API的绑定输入信息
#define IMAGE_DIRECTORY_ENTRY_IAT 12 // Import Address Table 导入地址表:导入函数的地址
#define IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT 13 // Delay Load Import Descriptors
#define IMAGE_DIRECTORY_ENTRY_COM_DESCRIPTOR 14 // COM Runtime descriptor com运行时的目录这里的数字是0xA,而省略的那一部分被填充进了程序的解码代码,也就是说从LAOD_CONFIG开始,后面的6个数据目录被忽略的,也就是上一个部分提到的,在0xD8开始的那一部分。
_IMAGE_SECTION_HEADER:
前面结束了FILE_HEADER和OPTIONAL_HEADER的分析,那么紧接着的就是节区头,根据前面的分析,节区头的起始位置应该在0x170,然后来看一下节区头(SECTION_HEADER)结构体的构成:
typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME];
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;在看一下Stud_PE中区段表:
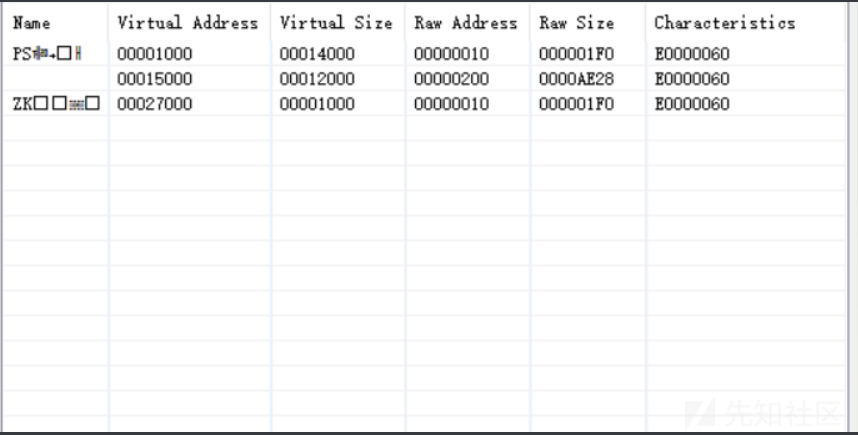
可以发现有总共有三个节区,所以应该有三个节区头,这里可以发现一个很奇怪的事:节区一和节区三的Raw Address和Raw size是一样的,也就是说,这两个节区是重叠的,这是UPack的一个重要操作:重叠节区,下面会详细介绍这个操作。
重叠节区:
根据tud_PE中的区段信息,可以得知第一节区和第三节区是重叠的,但是文件在被映射到内存时,文件中0x10~0x1FF这段内容会被分别映射到其实地址为0x1000和0x27000的两块内存中,大概的映射过程如下图所示:

这里还可以发现一个信息,第二节区的大小是AE28,这比第一和第三节区打了很多,其实这里就是原本notepad.exe的代码压缩后存储的地方,它在文件被装入内存时填充进第二节区中,在经过程序中的解压代码处理后再放入到第一节区中,而第一节区中就会有可以执行的,完整的代码(观察区段信息时其实也可以发现第一节区的virtual size是14000,比第二节区的12000要大一些,其实就是解压后的大小要大一点)。
上一篇文章对壳的简述中其实也提到了这个问题,就是经过压缩壳处理后的文件在载入内存时的解压与覆盖操作,如果在上一篇文章中没有理解到的话就可以结合这个例子来看:
- 将压缩后的代码全部放在一个区段中
- 再装入内存时设置两个节区(一个大一点的用存储解压后的代码,一个小一点用来存储解压前的代码)
- 将被解码处理后的代码放入先前准备好的节区中,执行时直接执行该节区中的代码即可
RVA to RAW转换的新理解:
当涉及到文件到内存的映射时,就会有RVA to RAW的转换,在正常的PE文件中,这个转化的过程是:
RAW - PointerToRawData = RVA - VirtualAddress
RAW = RVA - VirtualAddress + PointerToRawData如果在UPack处理后的PE文件中也使用这个公式的话,那么第一节区的开始位置就应该是:
RAW = RVA(0x1018)- VirtualAddress(0x1000) + PointerToRawData(0x10)
RAW = 0x28这里的RVA和PointerToRawData信息要自己去找:
PointerToRawData

RVA(EntryPoint):

这里计算出来的RAW是0x28,去OD里面看一下这个地方:

这里的数据无法被解析为代码,这也是为什么UPack处理后文件无法被正常解析或者执行的原因,就是由于无法正常进行RVA to RAW转换。那么这个RVA to RAW的转换应该怎么正常进行?
在OPTIONAL_HEADER中有这样一个成员:
DWORD FileAlignment这个成员就是文件对齐参数,简单来说就是在文件中的PointerToRawData需要是是它的整数倍,在这个文件中它的值为:0x200

也就是说用于计算RAW的PointerToRawData值需要为0,0x200,0x400,0x600等,而这里的PointerToRawData值为0x10,显然不是整数倍,应该要被处理为0才能正常进行运算,也就是说正确的计算结果应该是:
RAW = RVA(0x1018)- VirtualAddress(0x1000) + PointerToRawData(0)
RAW = 0x18到OD中看一下这个部分:

这里出现了跳转指令和数据传送指令,基本可以判断这里就是正确的EP。
IMAGE_IMPORT_DESCRIPTOR:
现在分析只剩下最后一个重要的结构了,就是这个程序的导入表,UPack处理后的导入表构造很奇特,下面来具体看一下:
首先在OPTIONAL_HEADER中找到导入表的数据目录:

RVA是0x217EE,Size为0x14;根据这个RVA找到导入表的具体位置:

蓝框选中的部分即使导入表的数据,再来看一下导入表结构体的构造:
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA)
} DUMMYUNIONNAME;
DWORD TimeDateStamp; // 0 if not bound,
// -1 if bound, and real date\time stamp
// in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
// O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name;
DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR;那么就可以找到这几个关键信息:
DWORD Name:0x2
DWORD FirstThunk:0x11E8根据这两个RVA可以找到name的RVA为:0x2 FirstThunk的RVA为0x1E8:
Name:

FirstThunk(先找指针再找数据):

到这里看起来一切都是正常的,但是按照正常的规范来说,导入表后应该用一个NULL的结构体作为结尾,但是这里却没有正常使用NULL结构体截断导入表,这里其实就是他奇特的地方:它使用区段的结束作为导入表的结束
什么意思呢?首先我们知道第一节区的结束位置是:0x10 + 0x1F0 = 0x200,也就是说,第一节区的数据在0X200的地方就截断了,导入表只使用了一个WORD来表示FirstThunk,而0x200后面的数据不会被映射入第一节区,导入表就这要被截断了(省去了一个NULL结构体的空间)
IAT与INT:
在学习PE文件的时候总会遇到这个问题,就是IAT与INT到底有什么区别?
这两个结构的差异要看阶段,当文件处于磁盘中时,这两个结构是相同的,使用的都是一个位置上的数据,但是当文件被加载到内存中时,IAT中的数据会根据INT中的函数名称、序号和库文件导出表信息被修改为函数的具体地址,而INT中的数据则保持原样,这也是为什么在IMAGE_IMPORT_DESCRIPTOR中INT对应的成员是OriginalFirstThunk(原初首thunk)。
#调试软件是高版本的OD,高版本的OD修复了这个RAW to RAV的bug,可以直接找到EP,旧版本的OD可能需要自己定位一下EP#
OD打开文件后就是程序的EP:

跟随这个跳转继续调试:
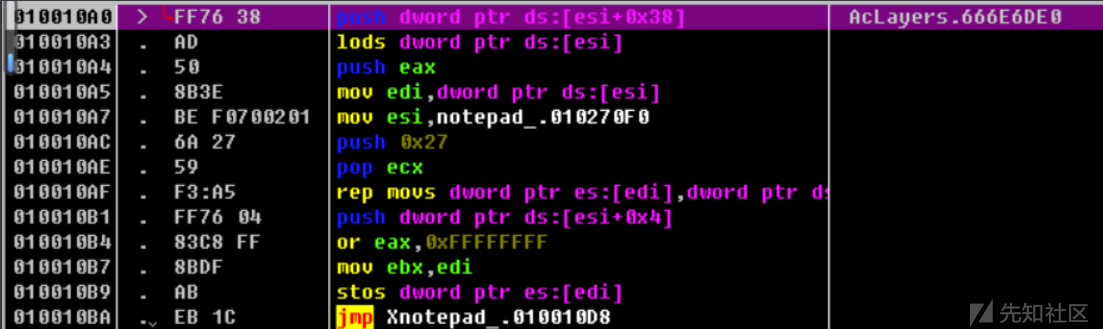
这一段代码的主要操作就是将ESI指向的地址(RVA:10270F0 RAW:F0)开始的0x27个字节拷贝到EDI指向的地址(RVA:0x101FE28 RAW:B028),这个EDI指向的地址正好就是文件的末尾。总体操作就是将文件头中的一段数据复制到文件的末尾。然后继续调试:
来到这样一段代码:

这里有一个函数调用,进入里面看一下:

这其实就是程序中的解码函数,但是光从这个地方来看还看不出来它是什么功能,要继续F8跟踪,来到这样一段代码:

这里发生了一个向前的跳转,转回了了这个地方
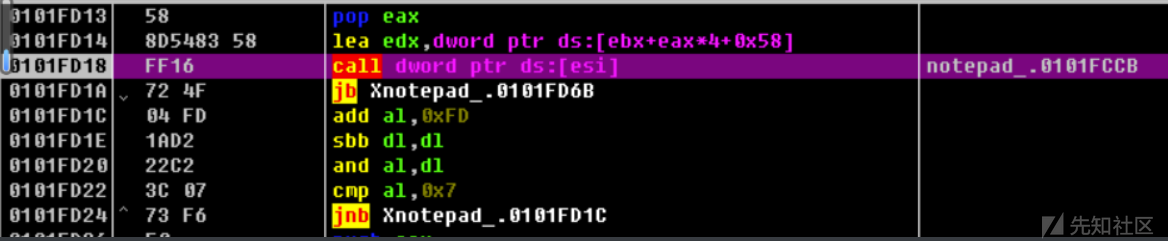
也就是这个0x101FCCB的位置上,再次跟踪的话会发现多次调用这个函数,印证了前面说到的它是解码函数的猜想,在调用函数后的操作就是某种算法以及将解码出来的代码放在文件末尾(也就是前面说到的第二节区解码出来的放入第一届全),感兴趣的话可以仔细的去分析一下。
那么当解码循环完成后,又要进行什么操作,我们下断点跳过循环后看一下:
我们单步运行到这个地方:

注意这个call ecx和call ebp,逐步运行,可以发现这个call ecx是调用 LoadLibrary和GetProcAddress这两个函数,也就是出现在我们PE文件头中的两个函数,这两个函数组合起来就是获得某个导入函数的实际地址,并且在call ebp后出现了一个jmp 跳转回最开始的地方,是一个明显的循环结构,在中间出现了lods的数据传送指令。那么我们就可以基本确定这个地方在循环获取导入函数的地址并填入到IAT中。(一直跟踪的话会发现esi中有类似于函数名的字符串在不停变动,也可以印证我们的猜想)
这个循环就是在修复被壳抹去的IAT。
在程序完成解码和修复IAT后,就会进入到真正的程序入口地址,也就是OEP,在程序中以RETN的形式表现:

步进到这个retn即可返回程序的OEP:

这里也就找到了程序的OEP:0x100739D
参考资料:
《逆向工程核心原理》 [韩] 李承远
工具下载:
如有侵权请联系:admin#unsafe.sh