移动互联网时代,直面C端用户的业务系统规模一般都很庞大,系统消耗的机器资源也很可观,系统使用的CPU核数、内存都是在消耗公司的真金白银。在服务水平不下降的前提下尽量降低单服务实例的资源消耗,即我们俗称 2022-10-21 09:4:45 Author: Go语言中文网(查看原文) 阅读量:48 收藏
移动互联网时代,直面C端用户的业务系统规模一般都很庞大,系统消耗的机器资源也很可观,系统使用的CPU核数、内存都是在消耗公司的真金白银。在服务水平不下降的前提下尽量降低单服务实例的资源消耗,即我们俗称的“少吃草多产奶”,一直是各个公司经营人员的目标,有些公司每降低1%的CPU核数使用,每年都能节省几十万的开销。
在编程语言选择不变的情况下,要想持续降低服务资源消耗,一方面要靠开发人员对代码性能持续地打磨,另一方面依靠编程语言编译器在编译优化方面提升带来的效果则更为自然和直接。不过,这两方面也是相辅相成的,开发人员如果能对编译器的优化场景和手段理解更为透彻的话,就能写出对编译优化更为友好的代码,从而获得更好的性能优化效果。
Go核心团队在Go编译器优化方面一直在持续投入并取得了不俗的效果,虽然和老牌的GCC[1]和llvm[2]的代码优化功力相比还有不小的空间。近期看到的一篇文章“字节大规模微服务语言发展之路”中也有提到:字节内部通过修改Go编译器的内联优化(收益最大的改动),从而让字节内部服务的Go代码获得了更多的优化机会,实现了线上服务10-20%的性能提升以及内存资源使用的下降,节约了大概了十几万个核。
看到这么明显的效果,想必各位读者都很想了解一下Go编译器的内联优化了。别急,在这一篇文章中,我就和大家一起来学习和理解一下Go编译器的内联优化。希望通过本文的学习,能让大家掌握如下内容:
什么是内联优化以及它的好处是什么 内联优化在Go编译过程中所处的环节和实现原理 哪些代码能被内联优化,哪些还不能被内联优化 如何控制Go编译器的内联优化 内联优化的弊端有哪些
下面我们就先来了解一下什么是内联优化。
1. 什么是编译器的内联优化
内联(inlining)[3]是编程语言编译器常用的优化手段,其优化的对象为函数,也称为函数内联。如果某函数F支持内联,则意味着编译器可以用F的函数体/函数定义替换掉对函数F进行调用的代码,以消除函数调用带来的额外开销,这个过程如下图所示:
我们知道Go从1.17版本[4]才改为基于寄存器的调用规约[5],之前的版本一直是基于栈传递参数与返回值,函数调用的开销更大,在这样的情况下,内联优化的效果也就更为显著。
除此之外,内联优化之后,编译器的优化决策可以不局限在每个单独的函数(比如上图中的函数g)上下文中做出,而是可以在函数调用链上做出了(内联替换后,代码变得更平(flat)了)。比如上图中对g后续执行的优化将不局限在g上下文,由于f的内联,让编译器可以在g->f这个调用链的上下文上决策后续要执行的优化手段,即内联让编译器可以看得更广更远了。
我们来看一个简单的例子:
// github.com/bigwhite/experiments/tree/master/inlining-optimisations/add/add.go//go:noinline
func add(a, b int) int {
return a + b
}
func main() {
var a, b = 5, 6
c := add(a, b)
println(c)
}
这个例子中,我们的关注点是add函数,在add函数定义上方,我们用//go:noinline告知编译器对add函数关闭inline,我们构建该程序,得到可执行文件:add-without-inline;然后去掉//go:noinline这一行,再进行一次程序构建,得到可执行文件add,我们用lensm工具[6]以图形化的方式查看一下这两个可执行文件的汇编代码,并做以下对比:
我们看到:非内联优化的版本add-without-inline如我们预期那样,在main函数中通过CALL指令调用了add函数;但在内联优化版本中,add函数的函数体并没有替换掉main函数中调用add函数位置上的代码,main函数调用add函数的位置上对应的是一个NOPL的汇编指令,这是一条不执行任何操作的空指令。那么add函数实现的汇编代码哪去了呢?
// add函数实现的汇编代码
ADDQ BX, AX
RET
结论是:被优化掉了!这就是前面说的内联为后续的优化提供更多的机会。add函数调用被替换为add函数的实现后,Go编译器直接可以确定调用结果为11,于是连加法运算都省略了,直接将add函数的结果换成了一个常数11(0xb),然后直接将常量11传给了println内置函数(MOVL 0xb, AX)。
通过一个简单的benchmark,也可以看出内联与非内联add的性能差异:
// 开启内联优化
$go test -bench .
goos: darwin
goarch: amd64
pkg: github.com/bigwhite/experiments/inlining-optimisations/add
BenchmarkAdd-8 1000000000 0.2720 ns/op
PASS
ok github.com/bigwhite/experiments/inlining-optimisations/add 0.307s// 关闭内联优化
$go test -bench .
goos: darwin
goarch: amd64
pkg: github.com/bigwhite/experiments/inlining-optimisations/add
BenchmarkAdd-8 818820634 1.357 ns/op
PASS
ok github.com/bigwhite/experiments/inlining-optimisations/add 1.268s
我们看到:内联版本是非内联版本性能的5倍左右。
到这里,很多朋友可能会问:既然内联优化的效果这么好,为什么不将Go程序内部的所有函数都内联了,这样整个Go程序就变成了一个大函数,中间再没有任何函数调用了,这样性能是不是可以变得更高呢?虽然理论上可能是这种情况,但内联优化不是没有开销的,并且针对不同复杂性的函数,内联的效果也是不同的。下面我就和大家一起先来看看内联优化的开销!
2. 内联优化的“开销”
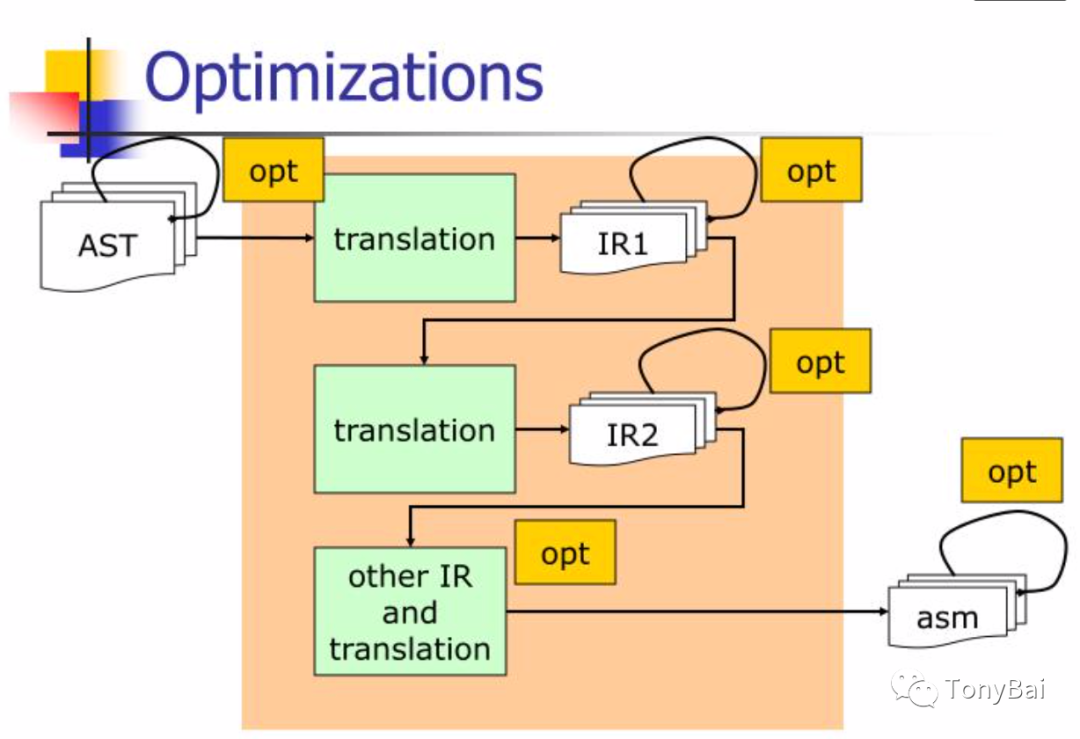
在真正理解内联优化的开销之前,我们先来看看内联优化在Go编译过程中的位置,即处于哪个环节。
Go编译过程
和所有静态语言编译器一样,Go编译过程大致分为如下几个阶段:
编译前端
Go团队并没有刻意将Go编译过程分为我们常识中的前后端,如果非要这么分,源码分析(包括词法和语法分析)、类型检查和中间表示(Intermediate Representation)构建可以归为逻辑上的编译前端,后面的其余环节都划归为后端。
源码分析形成抽象语法树,然后是基于抽象语法树的类型检查,待类型检查通过后,Go编译器将AST转换为一个与目标平台无关的中间代码表示。
目前Go有两种IR实现方式,一种是irgen(又名"-G=3"或是"noder2"),irgen是从Go 1.18版本[7]开始使用的实现(这也是一种类似AST的结构);另外一种是unified IR,在Go 1.19版本[8]中,我们可以使用GOEXPERIMENT=unified启用它,根据最新消息,unified IR将在Go 1.20版本落地。
注:现代编程语言编译过程多数会多次生成中间代码(IR),比如下面要提到的静态单赋值形式(SSA)也是一种IR形式。针对每种IR,编译器都会有一些优化动作:
编译后端
编译后端的第一步是一个被Go团队称为中端(middle end)的环节,在这个环节中,Go编译器将基于上面的中间代码进行多轮(pass)的优化,包括死代码消除、内联优化、方法调用实体化(devirtualization)和逃逸分析等。
注:devirtualization是指将通过接口变量调用的方法转换为接口的动态类型变量直接调用该方法,消除通过接口进行方法表查找的过程。
接下来是中间代码遍历(walk),这个环节是基于上述IR表示的最后一轮优化,它主要是将复杂的语句分解成单独的、更简单的语句,引入临时变量并重新评估执行顺序,同时在这个环节,它还会将一些高层次的Go结构转换为更底层、更基础的操作结构,比如将switch语句转换为二分查找或跳表,将对map和channel的操作替换为运行时的调用(如mapaccess)等。
接下来是编译后端的最后两个环节,首先是将IR转换为SSA(静态单一赋值)形式,并再次基于SSA做多轮优化,最后针对目标架构,基于SSA的最终形式生成机器相关的汇编指令,然后交给汇编器生成可重定位的目标机器码。
注:编译器(go compiler)产生的可重定位的目标机器码最终提供给链接器(linker)生成可执行文件。
我们看到Go内联发生在中端环节,是基于IR中间代码的一种优化手段,在IR层面上实现函数是否可内联的决策,以及对可内联函数在其调用处的函数体替换。
一旦了解了Go内联所处环节,我们就能大致判断出Go内联优化带来的开销了。
Go内联优化的开销
我们用一个实例来看一下Go内联优化的开销。reviewdog[9]是一个纯Go实现的支持github、gitlab等主流代码托管平台的代码评审工具,它的规模大约有12k行(使用loccount[10]统计):
// reviewdog代码行数统计结果:$loccount .
all SLOC=14903 (100.00%) LLOC=4613 in 141 files
Go SLOC=12456 (83.58%) LLOC=4584 in 106 files
... ...
我们在开启内联优化和关闭内联优化的情况下分别对reviewdog进行构建,采集其构建时间与构建出的二进制文件的size,结果如下:
// 开启内联优化(默认)
$time go build -o reviewdog-inline -a github.com/reviewdog/reviewdog/cmd/reviewdog
go build -o reviewdog-inline -a github.com/reviewdog/reviewdog/cmd/reviewdog 53.87s user 9.55s system 567% cpu 11.181 total// 关闭内联优化
$time go build -o reviewdog-noinline -gcflags=all="-l" -a github.com/reviewdog/reviewdog/cmd/reviewdog
go build -o reviewdog-noinline -gcflags=all="-l" -a 43.25s user 8.09s system 566% cpu 9.069 total
$ ls -l
-rwxrwxr-x 1 tonybai tonybai 23080429 Oct 13 12:05 reviewdog-inline*
-rwxrwxr-x 1 tonybai tonybai 20745006 Oct 13 12:04 reviewdog-noinline*
... ...
我们看到开启内联优化的版本,其编译消耗时间比关闭内联优化版本的编译时间多出24%左右,并且生成的二进制文件size要大出11%左右 - 这就是内联优化带来的开销!即会拖慢编译器并导致生成的二进制文件size变大。
注:hello world级别的程序是否开启内联优化大多数情况是看不出来太多差异的,无论是编译时间,还是二进制文件的size。
由于我们知道了内联优化所处的环节,因此这种开销就可以很好地给予解释:根据内联优化的定义,一旦某个函数被决策为可内联,那么程序中所有调用该函数的位置的代码就会被替换为该函数的实现,从而消除掉函数调用带来的运行时开销,同时这也导致了在IR(中间代码)层面出现一定的代码“膨胀”。前面也说过,代码膨胀后的“副作用”是编译器可以以更广更远的视角看待代码,从而可能实施的优化手段会更多。可实施的优化轮次越多,编译器执行的就越慢,这进一步增加了编译器的耗时;同时膨胀的代码让编译器需要在后面环节处理和生成更多代码,不仅增加耗时,还增加了最终二进制文件的size。
Go向来对编译速度和binary size较为敏感,所以Go采用了相对保守的内联优化策略。那么到底Go编译器是如何决策一个函数是否可以内联呢?下面我们就来简单看看Go编译器是如何决策哪些函数可以实施内联优化的。
3. 函数内联的决策原理
前面说过,内联优化是编译中端多轮(pass)优化中的一轮,因此它的逻辑相对独立,它基于IR代码进行,改变的也是IR代码。我们可以在Go源码的 $GOROOT/src/cmd/compile/internal/inline/inl.go中找到Go编译器进行内联优化的主要代码。
注:Go编译器内联优化部分的代码的位置和逻辑在以前的版本以及在未来的版本中可能有变化,目前本文提到的是代码是Go 1.19.1中的源码。
内联优化IR优化环节会做两件事:第一遍历IR中所有函数,通过CanInline判断某个函数是否可以内联,对于可内联的函数,保存相应信息,比如函数body等,供后续做内联函数替换使用;第二呢,则是对函数中调用的所有内联函数进行替换。我们重点关注CanInline,即Go编译器究竟是如何决策一个函数是否可以内联的!
内联优化过程的“驱动逻辑”在 $GOROOT/src/cmd/compile/internal/gc/main.go的Main函数中:
// $GOROOT/src/cmd/compile/internal/gc/main.go
func Main(archInit func(*ssagen.ArchInfo)) {
base.Timer.Start("fe", "init") defer handlePanic()
archInit(&ssagen.Arch)
... ...
// Enable inlining (after RecordFlags, to avoid recording the rewritten -l). For now:
// default: inlining on. (Flag.LowerL == 1)
// -l: inlining off (Flag.LowerL == 0)
// -l=2, -l=3: inlining on again, with extra debugging (Flag.LowerL > 1)
if base.Flag.LowerL <= 1 {
base.Flag.LowerL = 1 - base.Flag.LowerL
}
... ...
// Inlining
base.Timer.Start("fe", "inlining")
if base.Flag.LowerL != 0 {
inline.InlinePackage()
}
noder.MakeWrappers(typecheck.Target) // must happen after inlining
... ...
}
从代码中我们看到:如果没有全局关闭内联优化(base.Flag.LowerL != 0),那么Main就会调用inline包的InlinePackage函数执行内联优化。InlinePackage的代码如下:
// $GOROOT/src/cmd/compile/internal/inline/inl.go
func InlinePackage() {
ir.VisitFuncsBottomUp(typecheck.Target.Decls, func(list []*ir.Func, recursive bool) {
numfns := numNonClosures(list)
for _, n := range list {
if !recursive || numfns > 1 {
// We allow inlining if there is no
// recursion, or the recursion cycle is
// across more than one function.
CanInline(n)
} else {
if base.Flag.LowerM > 1 {
fmt.Printf("%v: cannot inline %v: recursive\n", ir.Line(n), n.Nname)
}
}
InlineCalls(n)
}
})
}
InlinePackage遍历每个顶层声明的函数,对于非递归函数或递归前跨越一个以上函数的递归函数,通过调用CanInline函数判断其是否可以内联,无论是否可以内联,接下来都会调用InlineCalls函数对其函数定义中调用的内联函数进行替换。
VisitFuncsBottomUp是根据函数调用图从底向上遍历的,这样可以保证每次在调用analyze时,列表中的每个函数都只调用列表中的其他函数,或者是在之前的调用中已经analyze过(在这里就是被内联函数体替换过)的函数。
什么是递归前跨越一个以上函数的递归函数,看下面这个例子就懂了:
// github.com/bigwhite/experiments/tree/master/inlining-optimisations/recursion/recursion1.go
func main() {
f(100)
}func f(x int) {
if x < 0 {
return
}
g(x - 1)
}
func g(x int) {
h(x - 1)
}
func h(x int) {
f(x - 1)
}
f是一个递归函数,但并非自己调用自己,而是通过g -> h这个函数链最终又调回自己,而这个函数链长度>1,所以f是可以内联的:
$go build -gcflags '-m=2' recursion1.go
./recursion1.go:7:6: can inline f with cost 67 as: func(int) { if x < 0 { return }; g(x - 1) }
我们继续看CanInline函数。CanInline函数有100多行代码,其主要逻辑分为三个部分。
首先是对一些//go:xxx指示符(directive)的判定,当该函数包含下面指示符时,则该函数不能内联:
//go:noinline //go:norace或构建命令行中包含-race选项 //go:nocheckptr //go:cgo_unsafe_args //go:uintptrkeepalive //go:uintptrescapes ... ...
其次会对该函数的状态做判定,比如如果函数体为空,则不能内联;如果未做类型检查(typecheck),则不能内联等。
最后调用visitor.tooHairy对函数的复杂性做判定。判定方法就是先为此次遍历(visitor)设置一个初始最大预算(budget),这个初始最大预算值为一个常量(inlineMaxBudget),目前其值为80:
// $GOROOT/src/cmd/compile/internal/inline/inl.go
const (
inlineMaxBudget = 80
)
然后在visitor.tooHairy函数中遍历该函数实现中的各个语法元素:
// $GOROOT/src/cmd/compile/internal/inline/inl.go
func CanInline(fn *ir.Func) {
... ...
visitor := hairyVisitor{
budget: inlineMaxBudget,
extraCallCost: cc,
}
if visitor.tooHairy(fn) {
reason = visitor.reason
return
}
... ...
}
不同元素对预算的消耗都有不同,比如调用一次append,visitor预算值就要减去inlineExtraAppendCost,再比如如果该函数是中间函数(而非叶子函数),那么visitor预算值也要减去v.extraCallCost,即57。就这样一路下来,如果预算被用光,即v.budget < 0,则说明这个函数过于复杂,不能被内联;相反,如果一路下来,预算依然有,那么说明这个函数相对简单,可以被内联优化。
注:为什么inlineExtraCallCost的值是57?这是一个经验值,是通过一个benchmark得出来的[11]。
一旦确定可以被内联,那么Go编译器就会将一些信息保存下来,保存到IR中该函数节点的Inl字段中:
// $GOROOT/src/cmd/compile/internal/inline/inl.go
func CanInline(fn *ir.Func) {
... ...
n.Func.Inl = &ir.Inline{
Cost: inlineMaxBudget - visitor.budget,
Dcl: pruneUnusedAutos(n.Defn.(*ir.Func).Dcl, &visitor),
Body: inlcopylist(fn.Body), CanDelayResults: canDelayResults(fn),
}
... ...
}
Go编译器设置budget值为80,显然是不想让过于复杂的函数被内联优化,这是为什么呢?主要是权衡内联优化带来的收益与其开销。让更复杂的函数内联,开销会增大,但收益却可能不会有明显增加,即所谓的“投入产出比”不足。
从上面的原理描述可知,对那些size不大(复杂性较低)、被反复调用的函数施以内联的效果可能更好。而对于那些过于复杂的函数,函数调用的开销占其执行开销的比重已经十分小了,甚至可忽略不计,这样内联效果就会较差。
很多人会说:内联后不是还有更多编译器优化机会么?问题在于究竟是否有优化机会以及会实施哪些更多的优化,这是无法预测的事情。
4. 对Go编译器的内联优化进行干预
最后我们再来看看如何对Go编译器的内联优化进行干预。Go编译器默认是开启全局内联优化的,并按照上面inl.go中CanInline的决策流程来确定一个函数是否可以内联。
不过Go也给了我们控制内联的一些手段,比如我们可以在某个函数上显式告知编译器不要对该函数进行内联,我们以上面示例中的add.go为例:
//go:noinline
func add(a, b int) int {
return a + b
}
通过//go:noinline指示符,我们可以禁止对add的内联:
$go build -gcflags '-m=2' add.go
./add.go:4:6: cannot inline add: marked go:noinline
注:禁止某个函数内联不会影响InlineCalls函数对该函数内部调用的内联函数的函数体替换。
我们也可以在更大范围关闭内联优化,借助-gcflags '-l'选项,我们可以在全局范围关闭优化,即Flag.LowerL == 0,Go编译器的InlinePackage将不会执行。
我们以前面提到过的reviewdog来验证一下:
// 默认开启内联
$go build -o reviewdog-inline github.com/reviewdog/reviewdog/cmd/reviewdog// 关闭内联
$go build -o reviewdog-noinline -gcflags '-l' github.com/reviewdog/reviewdog/cmd/reviewdog
之后我们查看一下生成的binary文件size:
$ls -l |grep reviewdog
-rwxrwxr-x 1 tonybai tonybai 23080346 Oct 13 20:28 reviewdog-inline*
-rwxrwxr-x 1 tonybai tonybai 23087867 Oct 13 20:28 reviewdog-noinline*
我们发现noinline版本居然比inline版本的size还要略大!这是为什么呢?这与-gcflags参数的传递方式有关,如果只是像上面命令行那样传入-gcflags '-l',关闭内联仅适用于当前package,即cmd/reviewdog,而该package的依赖等都不会受到影响。-gcflags支持pattern匹配:
-gcflags '[pattern=]arg list'
arguments to pass on each go tool compile invocation.
我们可以通过设置不同pattern来匹配更多包,比如all这个模式就可以包括当前包的所有依赖,我们再来试试:
$go build -o reviewdog-noinline-all -gcflags='all=-l' github.com/reviewdog/reviewdog/cmd/reviewdog
$ls -l |grep reviewdog
-rw-rw-r-- 1 tonybai tonybai 3154 Sep 2 10:56 reviewdog.go
-rwxrwxr-x 1 tonybai tonybai 23080346 Oct 13 20:28 reviewdog-inline*
-rwxrwxr-x 1 tonybai tonybai 23087867 Oct 13 20:28 reviewdog-noinline*
-rwxrwxr-x 1 tonybai tonybai 20745006 Oct 13 20:30 reviewdog-noinline-all*
这回我们看到reviewdog-noinline-all要比reviewdog-inline的size小了不少,这是因为all将reviewdog依赖的各个包的内联也都关闭了。
5. 小结
在这篇文章中,我带大家一起了解了Go内联相关的知识,包括内联的概念、内联的作用、内联优化的“开销”以及Go编译器进行函数内联决策的原理,最后我还给出控制Go编译器内联优化的手段。
内联优化是一种重要的优化手段,使用得当将会给你的系统带来不小的性能改善。Go编译器组也在对Go内联优化做持续改善,从之前仅支持叶子函数的内联,到现在支持非叶子节点函数的内联,相信Go开发者在未来还会继续得到这方面带来的性能红利。
本文涉及的源码可以在这里[12]下载。
6. 参考资料
Introduction to the Go compiler - https://go.dev/src/cmd/compile/README Proposal: Mid-stack inlining in the Go compiler - https://github.com/golang/proposal/blob/master/design/19348-midstack-inlining.md Mid-stack inlining in the Go compiler - https://golang.org/s/go19inliningtalk Inlining optimisations in Go - https://dave.cheney.net/2020/04/25/inlining-optimisations-in-go Mid-stack inlining in Go - https://dave.cheney.net/2020/05/02/mid-stack-inlining-in-go cmd/compile: relax recursive restriction while inlining - https://github.com/golang/go/issues/29737
参考资料
GCC: http://gcc.gnu.org
[2]llvm: https://llvm.org
[3]内联(inlining): http://en.wikipedia.org/wiki/Inline_expansion
[4]1.17版本: https://tonybai.com/2021/08/17/some-changes-in-go-1-17
[5]基于寄存器的调用规约: https://tonybai.com/2021/08/20/using-register-based-calling-convention-in-go-1-17/
[6]lensm工具: https://github.com/loov/lensm
[7]Go 1.18版本: https://tonybai.com/2022/04/20/some-changes-in-go-1-18
[8]Go 1.19版本: https://tonybai.com/2022/08/22/some-changes-in-go-1-19
[9]reviewdog: https://tonybai.com/2022/09/08/make-reviewdog-support-gitlab-push-commit-to-preserve-the-code-quality-floor
[10]loccount: https://gitlab.com/esr/loccount
[11]通过一个benchmark得出来的: https://github.com/golang/go/issues/19348#issuecomment-439370742
[12]这里: https://github.com/bigwhite/experiments/tree/master/inlining-optimisations
如有侵权请联系:admin#unsafe.sh