编者按2022年5月,由网络安全研究国际学术论坛(InForSec)汇编的《网络安全国际学术研究进展》一书正式出版。全书立足网络空间安全理论与实践前沿,主要介绍网络和系统安全领域华人学者在国际学术领域 2022-10-20 18:56:39 Author: 网安国际(查看原文) 阅读量:33 收藏
编者按
2022年5月,由网络安全研究国际学术论坛(InForSec)汇编的《网络安全国际学术研究进展》一书正式出版。全书立足网络空间安全理论与实践前沿,主要介绍网络和系统安全领域华人学者在国际学术领域优秀的研究成果,内容覆盖创新研究方法及伦理问题、软件与系统安全、基于模糊测试的漏洞挖掘、网络安全和物联网安全等方向。全书汇总并邀请了近40篇近两年在网络安全国际顶级学术议上发表的论文(一作为华人),联系近百位作者对研究的内容及成果进行综述性的介绍。从即日起,我们将陆续分享《网络安全国际学术研究进展》的精彩内容。
本文从黑盒与灰盒测试两方面入手,一方面研究如何在不同测试目标的黑盒测试中生成高质量的测试用例。另一方面,研究基于反馈的灰盒测试中,如何充分利用程序反馈的信息,研究高效的种子选择、调度、变异策略,定向测试,以及针对特定漏洞类型的高效发现方法。
模糊测试(Fuzzing)是一种软件与系统的安全测试技术。它通过发送随机变异的输入给被测试软件或系统,并实时监控被测试对象的异常状态(如崩溃等),从而发现潜藏在软件与系统中安全漏洞。相比其他安全测试技术(如数据流分析、污点分析、符号执行等),Fuzzing具备高效、准确率高等特点,它在学术界与工业界都得到了广泛的应用。AFL(America fuzzy lop)作为最广泛使用的Fuzzing工具,已经发现超过15000个漏洞,且基于AFL做二次开发的研究工作在这3年已经有超过100篇文章发表,可见Fuzzing技术在软件安全领域的重要价值。
Fuzzing根据软件信息的收集情况,可以分为黑盒测试、灰盒测试、白盒测试这3个类别。其中,黑盒测试将软件作为“黑盒子”,不收集软件的任何信息对软件进行测试。白盒测试对软件做复杂的静态分析,包括污点分析、符号执行等,获取丰富的软件信息,从而引导测试用例的生成。灰盒测试介于黑盒测试与白盒测试之间,通过轻量级的方式获取软件执行信息,如代码覆盖率、路径等信息,用于引导测试用例的生成。黑盒测试的优势在于不需要了解软件具体运作原理即可对其进行测试。而灰盒测试的优势在于轻量级地获取软件运行情况,以极小的性能开销辅助生成更有价值的测试用例,从而更快地发现深层次的软件安全缺陷与漏洞。
已有的Fuzzing技术在软件与系统的安全测试中已具备很好的泛用性,然而在测试特定目标对象、解决特定问题上仍然存在一定的不足。因此,我们的研究从黑盒与灰盒测试两方面入手,一方面研究如何在不同测试目标的黑盒测试中生成高质量的测试用例。另一方面,研究基于反馈的灰盒测试中,如何充分利用程序反馈的信息,研究高效的种子选择、调度、变异策略,定向测试,以及针对特定漏洞类型的高效发现方法。
01
黑盒测试中高质量测试用例的生成
针对黑盒测试的高质量测试用例生成,我们的研究主要分为两个方面。一方面,面向特定测试目标,研究如何基于已有的大规模原始数据,生成高质量的测试用例,保证其能够通过测试目标的语法与语义检查,从而执行到程序的深层次状态,并以此挖掘代码的深层次漏洞。另一方面,分析测试目标的状态与行为并生成高鲁棒性模型,在此基础上,研究基于模型的高效测试用例生成方法。
我们对现实世界中各类型的软件进行分析,涉及程序语言的解析引擎、移动APP、Web应用、大型网络游戏、macOS SDK库等,研究出针对各类型软件的Fuzzing高质量测试用例的生成方法。研究结果表明,这些高质量种子可以快速、高效地发现这些软件中的安全缺陷与漏洞。
1.语言解析引擎的测试
针对被测程序生成高质量的测试用例时,需要保证测试用例能够通过语法的解析,以及语义的分析,执行到程序真正和核心代码部分进行动态测试,从而发现影响力大的漏洞。通常来说,同类型的被测程序的输入有相似的语法结构,但由于程序功能的多样性,在语义实现上差异较大,因此手动生成满足语义的输入非常困难,需要消耗大量的人力。由此可知,针对特定类型软件,如何生成高质量满足语义规则的输入是一个重要的研究问题。
针对程序语言解析引擎的测试,我们提出研究“Skyfire:Data-Driven Seed Generation for Fuzzing”,并发表在2017年IEEE S&P会议上。Skyfire针对XML、XSLT等语言解析引擎,研究如何根据大量的开源项目的数据,生成能够通过语法解析与语义分析,且具有高覆盖率的种子集合。后续在测试过程中使用这些生成的种子,快速地发现被测引擎的漏洞。具体来说,本研究创新性地提出PCSG(基于概率的上下文敏感的文法),先从数据样本中抽取出抽象语法树,然后根据推导法生成原始种子。在此基础上,优先选择高代码覆盖率的种子,并随机的变异种子的叶子节点,从而构造满足语法条件的测试用例。最后,本研究集成AFL,并对开源的libxslt、libxml2和sabotron等引擎进行测试。结果表明,相比使用爬取的网络数据作为种子,本研究生成的种子在内存破坏和拒绝服务类的漏洞发现能力都有很大的提高。同时,Skyfire在代码覆盖率和函数覆盖率上分别有20%和15%的提高。Skyfire的工作流程如图1所示。
图1
2. Android应用GUI的测试
针对Android应用GUI的测试,我们提出研究“Guided,Stochastic Model-Based GUI Testing of Android Apps”,并发表在2017年FSE会议上。该研究针对Android移动端的APP,研究高质量测试用例生成方法。在针对移动端APP的测试,目前主要有模糊测试(代表工作有谷歌的Monkey,2016年FSE的WCTester,2013年FSE的Dynodroid)、符号执行(代表工作有2012年FSE的ACTeve,2012年SSEN的JPF-Android)、基于进化算法的测试方法(代表工作有2014年FSE的Evodroid,2016年ISSTA的Sapienz)、基于模型的测试方法(代表工作有2015年IEEE Software的MobiGuitar,2016年ASE的AMOLA)等。
本研究属于基于模型的测试方法,主要以APP为输入,通过动静态的分析生成APP的行为模型,并以此为指导生成高质量的测试用例。具体来说,在动静态分析阶段,通过静态分析提取APP的事件,通过动态的UI探寻获取APP的状态信息,并在此基础上构建初始的有限状态机器。紧接着,在有限状态机的基础上,通过调整状态之间的转移概率,生成新的测试用例进行测试。另一方面,对测试用例的执行结果进行监控,获取测试覆盖度和差异度,从而对模型进行调整。在测试的过程中,对监测的异常进行分析从而发现漏洞。
本研究在3个数据集上进行了验证。
(1) 首先测试了93个benchmarkAPP,相比已有工作,测试覆盖度提高了17%~31%,发现程序崩溃数量提高了3倍。
(2) 接着对谷歌商店的1661真实APP进行测试,发现2210个未知异常,其中包括大量空指针引用漏洞、窗口组件泄露漏洞、Activity组件未找到漏洞等。而漏洞涉及有大量用户群体的APP,其中包括1个微信漏洞,1个gmail漏洞,2个google+漏洞。
(3) 通过测试2104个F-droid的APP,发现3535个程序崩溃,涉及75种类型的错误。
3. macOS闭源SDK库测试
针对macOS闭源SDK库的测试,我们提出研究“APICRAFT:Fuzz Driver Generation for Closed-source SDK Libraries”,并发表在2021年USENIX Security会议上。通常来说,fuzz driver用于测试闭源的SDK库,其通过调用SDK库中的库函数,将fuzzer的输入数据投喂给库函数,从而进行安全测试。由于fuzz driver由安全专家手动编写,其质量取决于专家的水平和对库的熟悉程度。为了减轻人力消耗并提高fuzz driver的质量,一些自动化生成fuzz driver的技术被提出。然而,这些技术采用对源代码进行静态分析的方法来生成,并不适用于闭源SDK库fuzz driver的生成。fuzz driver的生成主要有两个挑战:
■ 闭源SDK库能提取的信息有限;
■ SDK库里的API调用关系复杂且正确性需要保证。
为了解决这两个挑战,论文提出针对闭源SDK库的fuzz driver自动化生成技术APICRAFT。APICRAFT采用收集-合并的核心策略,首先利用静态与动态信息(头文件、二进制、执行序列)来收集API之间的控制与数据依赖关系,接着使用多目标遗传算法来组合依赖的API,从而生成高质量的fuzz driver。在实验部分,APICRAFT通过对macOS SDK库的5个攻击面进行测试,相比手动编写的fuzz driver,测试代码覆盖率平均提升64%。在长达8个月Fuzzing测试中,APICRAFT发现142个漏洞(包含54个CVE),漏洞涉及广泛使用的苹果产品,如Safari、Messages、Preview等。
4.网络游戏测试
针对大型复杂对抗类网络游戏的测试,我们提出研究“Wuji:Automatic Online Combat Game Testing Using Evolutionary Deep Reinforcement Learning”,并发表在 2019年ASE会议上。Wuji针对大体量的商业网络对抗类型游戏,实现了高效、智能的自动化测试。由于当前的大型游戏具有非常复杂且持续的决策过程,因此普通的测试方法很难发现游戏的深层次漏洞。该研究通过分析4款网易游戏的真实漏洞,总结出4个检测bug的方法。在此基础上,该研究提出Wuji游戏测试引擎,采用深度强化学习算法和多目标优化算法,实现了对游戏胜利和状态空间的多重探索,保证对游戏进展和状态空间测试的平衡性。进一步地,传统的游戏测试仅以胜率作为唯一反馈,导致测试用例只具备取胜的能力,而忽略了对更多状态的空间的探索。而Wuji将胜率和状态空间探索能力同时作为衡量指标,用于生成后续的测试用例,既保证了测试用例具有促进游戏剧情任务发展的能力,同时保证了对状态空间的大量探索,从而提升发现漏洞的能力。
该研究使用Wuji对网易游戏公司的大型游戏倩女幽魂和逆水寒,以及仿真游戏BlockMase进行测试,相比只使用强化学习算法、基于单目标优化的进化算法、基于多目标优化的进化算法和单目标优化算法+强化学习算法,Wuji的漏洞检测能力都有极大地提高。
5.自动化Web测试
针对Web应用,我们提出研究“Automatic Web Testing using Curiosity-Driven Reinforcement Learning”,并发表在2021年ICSE会议上。该研究针对Web应用,研究高质量测试用例生成方法。为了实现此目标,该研究提出WebExplor,采用基于好奇心驱动的强化学习算法,实现对更多的Web状态进行测试,避免陷入局部状态测试。具体来说,该研究分为3个步骤。
(1) 状态提取。由于Web应用的状态非常多,为了能够使用强化学习技术,我们将业务逻辑相同的页面归结为一个状态。同时,将页面中的具体内容过滤,只保留按钮、文本框、选择器等可操作元素,然后将页面进行相似度匹配,划分出不同的状态集合。
(2) 基于好奇心驱动的强化学习。在强化学习中,除了动作和状态集合,还需要定义奖励函数。不同于有明确奖励机制的应用(如游戏的奖励机制是胜利或分数),Web应用并没有明确的奖励机制。因此,本研究提出好奇心驱动的奖励函数,主要的思路是若某状态转移次数较高,则对该状态转移的好奇心降低,导致奖励降低。在该机制的激发下,能够测试更多的状态。
(3) 基于有限状态机的引导。若在步骤(2)下无法发现新的状态,则利用被测试应用的有限状态机,选择好奇心度最高的状态进行进一步的探索。该研究对GitHub上排名前50的Web项目进行测试,相比基于模型的方法和基于模型导航的方法,在代码覆盖率和错误检测率上都有一定的提升。
02
基于反馈的灰盒测试
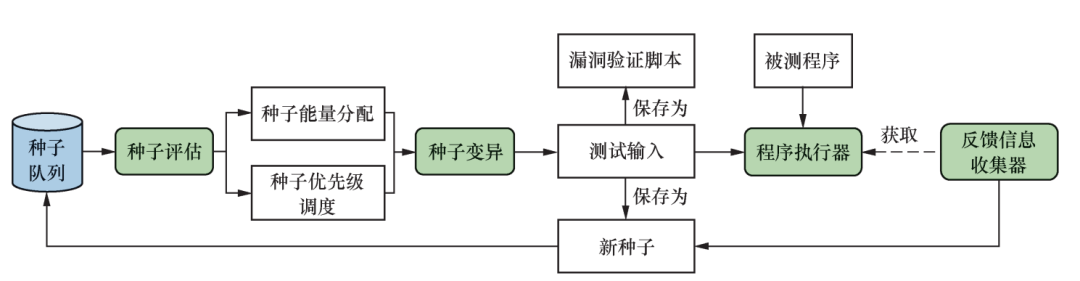
除了研究黑盒测试高质量种子的生成,我们同样研究了基于反馈的灰盒测试中的重要研究问题。已有的基于反馈的灰盒测试技术(如AFL、AFLGo等)在安全测试上具备很强的泛用性,但在处理特定问题,以及发现特定类型漏洞上,仍然存在较强的局限性。因此,我们研究了通用灰盒测试在特定问题上(种子选择、调度与变异策略、定向灰盒测试)和针对特定漏洞类型的高效挖掘方法。图2所示为基于反馈的灰盒测试工作流程。其中,种子评估、变异、多类型反馈信息收集都是重要的核心部件,其好坏影响整个测试的效率。
图2
1.种子的选择、调度和变异
在基于反馈的灰盒测试中,AFL将提升代码覆盖率的种子作为“感兴趣的”,并存放在种子队列中,用于后续测试输入的生成。然而AFL在后续种子的选择与调度上却采取随机选择与同等策略分配的原则,导致一些潜力更高的种子没有更多机会进行变异与测试。为了进一步提升灰盒测试的效率,我们提出研究“Cerebro: context-aware adaptive fuzzing for effective vulnerability detection”,并发表在2019年FSE会议上。该研究利用测试程序反馈的信息,分析判断种子的后续潜能,挑选出潜能高的种子并为其分配更多的测试时间。具体来说,灰盒测试在运行的过程中会维护一个测试种子队列,而这里有两个阶段的策略将影响到整个灰盒测试过程的效率。第一个阶段是种子优先级调度,即在输入队列中如何选取下一个测试种子。第二个阶段是种子能量分配,即针对这个被选择的种子生成多少个新的输入。若在灰盒测试过程中,选择一个潜能低的种子(如让程序输出错误信息的种子),并对其进行大量变异生成输入,那么程序将长时间进行低效率的测试。为了选择高潜能的种子,并对其进行高效地变异,Cerebro根据种子的属性和在执行过程产生的一些信息,利用多目标优化算法来评价种子的质量和潜力。其中属性信息涉及的目标包括种子文件大小、种子执行时间,以及执行序列的特性(路径覆盖率、是否提升代码覆盖率、被覆盖的代码的复杂度等)。通过在8个真实程序中测试,Cerebro发现了14个未知漏洞(包含1个CVE)。同时,与AFL和AFLFast相比,Cerebro在相同时间内能够有更高的代码覆盖度并发现更多的漏洞。
除了种子的选择与调度,高效的种子变异也是提高测试效率的重要环节。对于一些结构化的输入,AFL的随机变异方式会完全破坏输入本身的结构,导致生成的输入不满足语法结构而被测试程序直接丢弃。为了提升对有结构化输入程序的测试,我们提出研究“Superion:Grammar-Aware Greybox Fuzzing”,并发表在2019年ICSE会议上。具体来说,根据测试输入的语法结构,我们提出基于抽象语法树的语法感知输入修剪策略,并在此基础上提出基于树的和改进的基于字典的种子变异方式。在实验方面,通过对广泛使用的1个XML引擎和3个JavaScript引擎进行测试,相比AFL与jsfunfuzz,Superion在一定程度上提高了代码覆盖率(在代码行数上多覆盖了16.7%,在函数覆盖率上提高8.8%)。同时,Superion发现了21个新漏洞。
此外,为了使灰盒测试技术覆盖深层次代码逻辑,我们提出基于程序状态反馈的灰盒测试技术“Steelix:program-state based binary fuzzing”,并在2017年FSE会议上发表。Steelix的主要目标是在基于代码覆盖率引导的灰盒测试基础上,能够实现对魔法字节(magic byte)的快速突破。该研究主要分为3个步骤。
(1) 通过静态分析方法过滤不感兴趣的比较操作,如单字节比较、函数返回值的比较。然后抽其余感兴趣比较操作的信息,包括指令地址、函数名、操作数信息。
(2) 进行二进制插桩。
(3) 利用执行过程中程序状态变化(魔法字节的比较)作为反馈,引导种子保留与变异,并生成能穿透魔法字节的测试用例。Steelix在LAVA-M数据集、DARPA CGC和5个真实程序上进行测试,发现了9个漏洞(包含1个CVE)。同时,Steelix与AFL、AFL-laf-intel进行比较,在相同时间内能够发现更多的漏洞,以及覆盖更多的代码。
2.定向灰盒测试
上述的通用灰盒测试的目标是尽可能地多覆盖程序状态和路径,而定向灰盒测试是对程序中的特定目标进行测试,其用途非常广泛,包括如下用途。
■ 对开源项目的补丁进行测试,分析补丁是否引入了新的安全漏洞。
■ 对疑似漏洞进行确认。通常情况下,安全人员可通过静态分析或人工检查发现疑似漏洞,接着可通过定向灰盒测试进行验证。
■ 复现已知漏洞。可根据已知漏洞的描述(CVE描述),进行定向灰盒测试从而获取触发漏洞的输入,完成漏洞复现。
作者简介
郑尧文,中国科学院大学网络空间安全专业博士,目前就职于南洋理工大学,博士后。他的研究领域为系统与软件安全,物联网设备安全,研究兴趣包括二进制分析,模糊测试,漏洞分析与利用。
刘杨,新加坡南洋理工大学(NTU)计算机学院教授,NTU网络安全实验室主任、HP-NTU公司实验室项目主任、新加坡国家卓越卫星中心副主任,并于2019年荣获大学领袖论坛讲席教授。他专攻软件验证、软件安全和软件工程,其研究填补了形式化方法和程序分析中理论和实际应用之间的空白,评估了软件的设计与实现以确保高安全性。到目前为止,他已经在顶级会议和顶级期刊上发表了超过300篇文章。他还获得多项著名奖项,包括MSRA fellowship、TRF Fellowship、南洋助理教授、Tan Chin Tuan Fellowship、Nanyang Research Award 2019、NRF Investigatorship 2020,并且在ASE、FSE、ICSE等顶级会议上获得10项最佳论文奖和最具影响力软件奖。
(本文选取了文章部分章节,更多精彩内容请阅读《网络安全国际学术研究进展》一书。)
版权声明:本书由网络安全研究国际学术论坛(InForSec)汇编,人民邮电出版社出版,版权属于双方共有,并受法律保护。转载、摘编或利用其它方式使用本研究报告文字或者观点的,应注明来源。
本报告数量有限,关注公众号私信我们可以享受六折优惠,欢迎订阅!
如有侵权请联系:admin#unsafe.sh