本文主要介绍如果使用 qemu 和 unicorn 来搜集程序执行的覆盖率信息以及如何把搜集到的覆盖率信息反馈到 fuzzer 中辅助 fuzz 的进行。
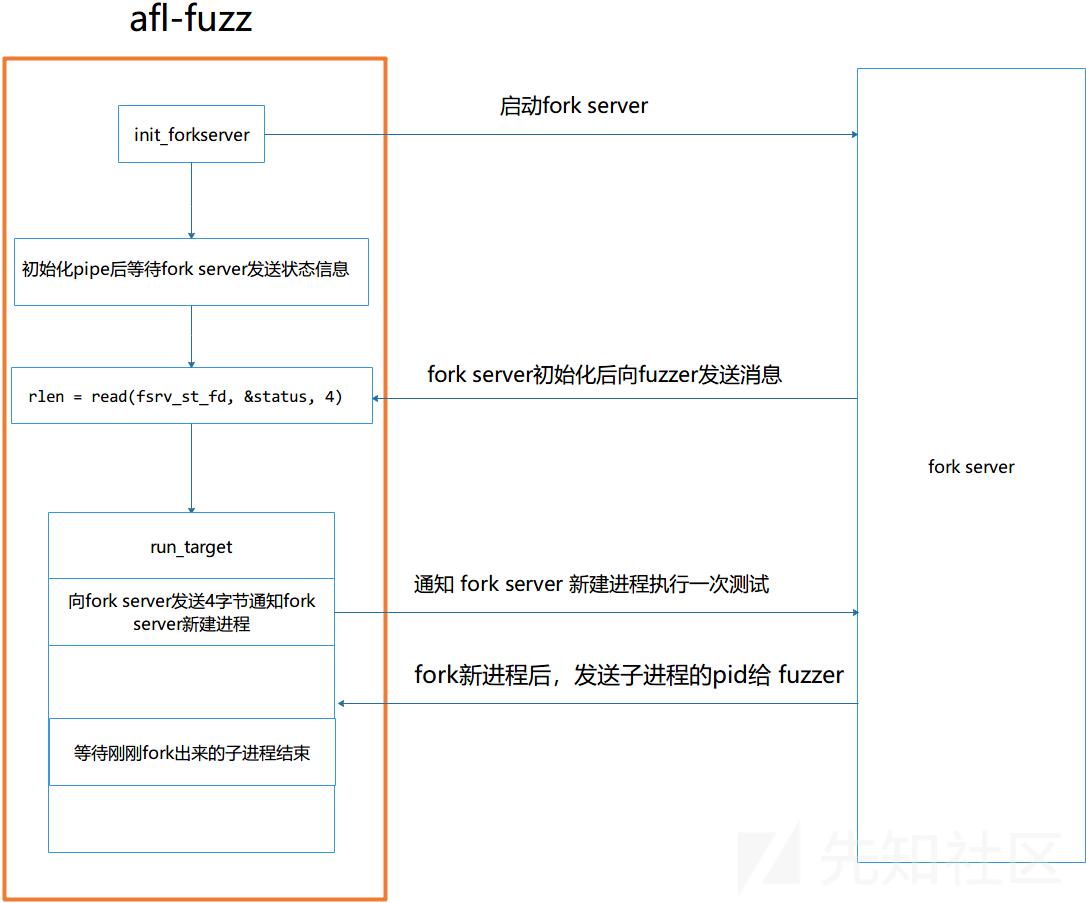
为了后面介绍 afl 的 qemu 模式和 unicorn 模式, 首先大概讲一下 afl 的 fork server 的实现机制。afl 与 fork server 的通信流程如图所示
- 首先
afl-fuzz调用init_forkserver函数fork出一个新进程作为fork server, 然后等待fork server发送4个字节的数据, 如果能够正常接收到数据则表示fork server启动正常。 fork server起来后会使用read阻塞住, 等待afl-fuzz发送命令来启动一个测试进程。- 当需要进行一次测试时,
afl-fuzz会调用run_target, 首先往管道发送 4 个字节通知fork server去fork一个进程来测试。 fork server新建进程后,会通过管道发送刚刚fork出的进程的pid给fork server.afl-fuzz根据接收到的pid等待测试进程结束,然后根据测试生成的覆盖率信息来引导后续的测试。
AFL 的 qemu 模式的实现和 winafl 使用 dynamorio 来插桩的实现方式比较类似,winafl 的实现细节如下
https://xz.aliyun.com/t/5108原始版本
源码地址
https://github.com/google/AFL/tree/master/qemu_mode/patchesqemu 在执行一个程序时,从被执行程序的入口点开始对基本块翻译并执行,为了提升效率,qemu会把翻译出来的基本块存放到 cache 中,当 qemu 要执行一个基本块时首先判断基本块是否在 cache 中,如果在 cache 中则直接执行基本块,否则会翻译基本块并执行。
AFL 的 qemu 模式就是通过在准备执行基本块的和准备翻译基本块的前面增加一些代码来实现的。首先会在每次执行一个基本块前调用 AFL_QEMU_CPU_SNIPPET2 来和 afl 通信。
#define AFL_QEMU_CPU_SNIPPET2 do { \
if(itb->pc == afl_entry_point) { \
afl_setup(); \
afl_forkserver(cpu); \
} \
afl_maybe_log(itb->pc); \
} while (0)如果当前执行的基本块是 afl_entry_point (即目标程序的入口点),就设置好与 afl 通信的命名管道和共享内存并初始化 fork server ,然后通过 afl_maybe_log 往共享内存中设置覆盖率信息。统计覆盖率的方式和 afl 的方式一样。
cur_loc = (cur_loc >> 4) ^ (cur_loc << 8);
cur_loc &= MAP_SIZE - 1;
afl_area_ptr[cur_loc ^ prev_loc]++; // 和 afl 一样 统计 edge 覆盖率fork server 的代码如下
static void afl_forkserver(CPUState *cpu) {
// 通知 afl-fuzz fork server 启动正常
if (write(FORKSRV_FD + 1, tmp, 4) != 4) return;
// fork server 的主循环,不断地 fork 新进程
while (1) {
// 阻塞地等待 afl-fuzz 发送命令,fork 新进程
if (read(FORKSRV_FD, tmp, 4) != 4) exit(2);
child_pid = fork(); // fork 新进程
if (!child_pid) {
// 子进程会进入这,关闭通信管道描述符,然后从 afl_forkserver 返回继续往下执行被测试程序
afl_fork_child = 1;
close(FORKSRV_FD);
close(FORKSRV_FD + 1);
close(t_fd[0]);
return;
}
// fork server 进程,发送 fork 出来的测试进程的 pid 给 afl-fuzz
if (write(FORKSRV_FD + 1, &child_pid, 4) != 4) exit(5);
// 不断等待处理 测试进程的 翻译基本块的请求
afl_wait_tsl(cpu, t_fd[0]);
// 等待子进程结束
if (waitpid(child_pid, &status, 0) < 0) exit(6);
if (write(FORKSRV_FD + 1, &status, 4) != 4) exit(7);
}
}forkserver 的代码流程如下
- 首先发送数据给
afl-fuzz, 表示fork server启动正常,通知完之后会进入循环阻塞在 read ,直到 afl-fuzz 端发送消息。 - 接收到数据后,
fork server会fork出新进程,此时子进程会关闭所有与afl-fuzz通信的文件描述符并从afl_forkserver返回继续往下执行被测试程序。而父进程则把刚刚fork出的测试进程的pid通过管道发送给afl-fuzz。 - 之后
fork server进程进入afl_wait_tsl,不断循环处理子进程翻译基本块的请求。
下面分析 afl_wait_tsl 的原理, 首先 afl 会在 翻译基本块后插入一段代码
tb = tb_gen_code(cpu, pc, cs_base, flags, 0); // 翻译基本块
AFL_QEMU_CPU_SNIPPET1; // 通知父进程 (fork server进程) 刚刚翻译了一个基本块
#define AFL_QEMU_CPU_SNIPPET1 do { \
afl_request_tsl(pc, cs_base, flags); \
} while (0)afl_request_tsl 就是把测试进程刚刚翻译的基本块的信息发送给父进程(fork server 进程)
static void afl_request_tsl(target_ulong pc, target_ulong cb, uint64_t flags) {
struct afl_tsl t;
if (!afl_fork_child) return;
t.pc = pc;
t.cs_base = cb;
t.flags = flags;
// 通过管道发送信息给 父进程 (fork server 进程)
if (write(TSL_FD, &t, sizeof(struct afl_tsl)) != sizeof(struct afl_tsl))
return;
}下面看看 afl_wait_tsl 的代码
static void afl_wait_tsl(CPUState *cpu, int fd) {
while (1) {
// 死循环不断接收子进程的翻译基本块请求
if (read(fd, &t, sizeof(struct afl_tsl)) != sizeof(struct afl_tsl))
break;
// 去fork server进程的 tb cache 中搜索
tb = tb_htable_lookup(cpu, t.pc, t.cs_base, t.flags);
// 如果该基本块不在在 cache 中就使用 tb_gen_code 翻译基本块并放到 cache 中
if(!tb) {
mmap_lock();
tb_lock();
tb_gen_code(cpu, t.pc, t.cs_base, t.flags, 0);
mmap_unlock();
tb_unlock();
}
}
close(fd);
}代码流程如下
- 这个函数里面就是一个死循环,不断地接收测试进程翻译基本块的请求。
- 接收到请求后会使用
tb_htable_lookup在fork server进程的cache中搜索,如果基本块不在cache中的话就使用tb_gen_code翻译基本块并放置到fork server进程的cache中。
这个函数有两个 tips 。
- 首先函数里面是死循环,只有当
read失败了才会退出循环,read又是阻塞的,所以只有fd管道的另一端关闭了才会read失败退出函数,所以当子进程执行结束或者由于进程超时被afl-fuzz杀死后,afl_wait_tsl就会因为read失败而退出该函数,等待接下来的fork请求。 - 子进程向父进程(
fork server进程)发送基本块翻译请求的原因是让fork server进程把子进程刚刚翻译的基本块在fork server进程也翻译一遍并放入cache,这样在后续测试中fork出的新进程就会由于fork的特性继承fork server的tb cache,从而避免重复翻译之前子进程翻译过的基本块。
改进版本
源码地址
https://github.com/vanhauser-thc/AFLplusplus在原始的 AFL qemu 版本中获取覆盖率的方式是在每次翻译基本块前调用 afl_maybe_log 往 afl-fuzz 同步覆盖率信息,这种方式有一个问题就是由于 qemu 会把顺序执行的基本块 chain 一起,这样可以提升执行速度。但是在这种方式下有的基本块就会由于 chain 的原因导致追踪不到基本块的执行, afl 的处理方式是禁用 qemu 的 chain 功能,这样则会削减 qemu 的性能。
为此有人提出了一些改进的方式
https://abiondo.me/2018/09/21/improving-afl-qemu-mode/为了能够启用 chain 功能,可以直接把统计覆盖率的代码插入到每个翻译的基本块的前面
TranslationBlock *tb_gen_code(CPUState *cpu,
............................
............................
tcg_ctx->cpu = ENV_GET_CPU(env);
afl_gen_trace(pc); // 生成统计覆盖率的代码
gen_intermediate_code(cpu, tb);
tcg_ctx->cpu = NULL;
............................afl_gen_trace 的作用是插入一个函数调用在翻译的基本块前面,之后在每次执行基本块前会执行 afl_maybe_log 统计程序执行的覆盖率信息。
同时为了能够进一步提升速度可以把子进程生成的 基本块chain 也同步到 fork server 进程。
bool was_translated = false, was_chained = false;
tb = tb_lookup__cpu_state(cpu, &pc, &cs_base, &flags, cf_mask);
if (tb == NULL) {
mmap_lock();
tb = tb_gen_code(cpu, pc, cs_base, flags, cf_mask);
was_translated = true; // 表示当前基本块被翻译了
mmap_unlock();
/* See if we can patch the calling TB. */
if (last_tb) {
tb_add_jump(last_tb, tb_exit, tb);
was_chained = true; // 表示当前基本块执行了 chain 操作
}
if (was_translated || was_chained) {
// 如果有新翻译的基本块或者新构建的 chain 就通知 fork server 更新 cache
afl_request_tsl(pc, cs_base, flags, cf_mask, was_chained ? last_tb : NULL, tb_exit);
}主要流程就是当有新的基本块和新的 chain 构建时就通知父进程 (fork server进程)更新父进程的 cache.
基于qemu还可以实现 afl 的 persistent 模式,具体的实现细节就是在被测函数的开始和末尾插入指令
#define AFL_QEMU_TARGET_i386_SNIPPET \
if (is_persistent) { \
\
if (s->pc == afl_persistent_addr) { \
\
I386_RESTORE_STATE_FOR_PERSISTENT; \
\
if (afl_persistent_ret_addr == 0) { \
\
TCGv_ptr paddr = tcg_const_ptr(afl_persistent_addr); \
tcg_gen_st_tl(paddr, cpu_regs[R_ESP], persisent_retaddr_offset); \
\
} \
tcg_gen_afl_call0(&afl_persistent_loop); \
\
} else if (afl_persistent_ret_addr && s->pc == afl_persistent_ret_addr) { \
\
gen_jmp_im(s, afl_persistent_addr); \
gen_eob(s); \
\
} \
\
}- 在被测函数的开头(
afl_persistent_addr)插入指令调用afl_persistent_loop函数, 该函数的作用是在每次进入被测函数前初始化一些信息,比如存储程序执行的覆盖率信息的共享内存。 - 然后在 被测函数的末尾
afl_persistent_ret_addr增加一条跳转指令直接跳转到函数的入口(afl_persistent_addr) - 通过这样可以实现不断对函数进行循环测试
源码地址
https://github.com/vanhauser-thc/AFLplusplusafl 可以使用 unicorn 来搜集覆盖率,其实现方式和 qemu 模式类似(因为 unicorn 本身也就是基于 qemu 搞的).它通过在 cpu_exec 执行基本块前插入设置forkserver和统计覆盖率的代码,这样在每次执行基本块时 afl 就能获取到覆盖率信息
static tcg_target_ulong cpu_tb_exec(CPUState *cpu, uint8_t *tb_ptr);
@@ -228,6 +231,8 @@
next_tb & TB_EXIT_MASK, tb);
}
AFL_UNICORN_CPU_SNIPPET2; // unicorn 插入的代码
/* cpu_interrupt might be called while translating the
TB, but before it is linked into a potentially
infinite loop and becomes env->current_tb. Avoid插入的代码如下
#define AFL_UNICORN_CPU_SNIPPET2 do { \
if(afl_first_instr == 0) { \ // 如果是第一次执行就设置 forkserver
afl_setup(); \ // 初始化管道
afl_forkserver(env); \ // 设置 fork server
afl_first_instr = 1; \
} \
afl_maybe_log(tb->pc); \ // 统计覆盖率
} while (0)和 qemu 类似在执行第一个基本块时初始化 afl 的命名管道并且设置好 forkserver,然后通过 afl_maybe_log 与 afl-fuzz 端同步覆盖率。
forkserver 的作用和 qemu 模式中的类似,主要就是接收命令 fork 新进程并且处理子进程的基本块翻译请求来提升执行速度。
源码地址
https://github.com/PAGalaxyLab/uniFuzzerlibfuzzer 支持从外部获取覆盖率信息
__attribute__((section("__libfuzzer_extra_counters")))
uint8_t Counters[PCS_N];上面的定义表示 libfuzzer 从 Counters 里面取出覆盖率信息来引导变异。
那么下面就简单了,首先通过 unicorn 的基本块 hook 事件来搜集执行的基本块信息,然后在回调函数里面更新Counters, 就可以把被 unicorn 模拟执行的程序的覆盖率信息反馈给 libfuzzer
// hook basic block to get code coverage
uc_hook hookHandle;
uc_hook_add(uc, &hookHandle, UC_HOOK_BLOCK, hookBlock, NULL, 1, 0);下面看看 hookBlock 的实现
// update code coverage counters by hooking basic block
void hookBlock(uc_engine *uc, uint64_t address, uint32_t size, void *user_data) {
uint16_t pr = crc16(address);
uint16_t idx = pr ^ prevPR;
Counters[idx]++;
prevPR = (pr >> 1);
}其实就是模拟 libfuzzer 统计覆盖率的方式在 Counters 更新覆盖率信息并反馈给 libfuzzer.
通过分析 afl 的 forkserver 机制、 afl qemu的实现机制以及 afl unicorn 的实现机制可以得出afl 的变异策略调度模块和被测程序执行和覆盖率信息搜集模块是相对独立的,两者通过命名管道进行通信。假设我们需要实现一种新的覆盖率搜集方式并把覆盖率反馈给 afl 来使用 afl 的 fuzz 策略,我们主要就需要模拟 fork server 和 afl-fuzz 进行通信,然后把覆盖率反馈给 afl-fuzz 即可。
对于 libfuzzer 而言,它本身就支持从外部获取程序执行的覆盖率信息(通过全局变量来传递),所以如果要实现新的覆盖率搜集方式,按照 libfuzzer 的规范来实现即可。
如有侵权请联系:admin#unsafe.sh