Hi,欢迎阅读[Golang三关]之内存篇。如果您对Golang的内存结构体系没有详细系统的理解,本篇文章《一站式Golang内存洗髓经》希望可以帮助你理解内存结构原理,一步到位。文章内容较长,约3万字,50张彩色配图。
Golang的内存管理及设计也是开发者需要了解的领域之一,要理解 Go 语言的内存管理,就必须先理解操作系统以及机器硬件是如何管理内存的。因为 Go 语言的内部机制是建立在这个基础之上的,它的设计,本质上就是尽可能的会发挥操作系统层面的优势,而避开导致低效情况。
(4)如何用Golang自己实现一个内存管理模型。(5)Golang内存管理之魂:TCMalloc。 说到内存,即使没有任何的软件基础知识,那么第一印象应该想到的是如下实物,如图1所示。图1 物理内存条
图1中常被称之为内存条,是计算机硬件组成的一个部分,也是真正给软件提供内存的物理空间。如果计算机没有内存条,那么根本谈不上有内存之说。 那么内存的作用在于什么呢?如果将计算机的存储媒介中的处理性能与容量做一个对比,会出现如下的金字塔模型,如图2所示。图2 计算机存储媒介金字塔模型
从图中可以得出处理速度与存储容量是成反比的。也就是说,性能越大的计算机硬件资源,越是稀缺,所以合理的利用和分配就越重要。 比如内存与硬盘的对比,因为硬盘的容量是非常廉价的,虽然内存目前也可以用到10G级别的使用,但是从处理速度来看的话,两者的差距还是相差甚大的,具体如表1所示。表1 硬盘与内存对比表| DDR3内存读写速度大概10G/s(10000M) | DDR4内存读写速度大概50G/s(50000M) |
| 固态硬盘速度是300M/s,是内存的三十分之一 | 固态硬盘速度是300M/s,是内存的二百分之一 |
| 机械硬盘的速度是100M/s,是内存的百分之一 | 机械硬盘的速度是100M/s,是内存的五百分之一 |
所以将大部分程序逻辑临时用的数据,全部都存在内存之中,比如,变量、全局变量、函数跳转地址、静态库、执行代码、临时开辟的内存结构体(对象)等。 当存储的东西越来越多,也就发现物理内存的容量依然是不够用,那么对物理内存的利用率和合理的分配,管理就变得非常的重要。
(2)基于操作系统的基础上,不同语言的内存管理机制也应允而生,有的一些语言并没有提供自动的内存管理模式,有的语言就已经提供了自身程序的内存管理模式,如表2所示。表2 自动与非自动内存管理的语言| 内存自动管理的语言(部分) | 内存非自动管理的语言(部分) |
| Golang | C |
| Java | C++ |
| Python | Rust |
所以为了降低内存管理的难度,像C、C++这样的编程语言会完全将分配和回收内存的权限交给开发者,而Rust则是通过生命周期限定开发者对非法权限内存的访问来自动回收,因而并没有提供自动管理的一套机制。但是像Golang、Java、Python这类为了完全让开发则关注代码逻辑本身,语言层提供了一套管理模式。因为Golang编程语言给开发者提供了一套内存管理模式,所以开发者有必要了解一下Golang做了哪些助力的功能。
在理解Golang语言层内存管理之前,应先了解操作系统针对物理内存做了哪些管理的方式。当插上内存条之后,通过操作系统是如何将软件存放在这个绿色的物理内存条中去的。 计算机对于内存真正的载体是物理内存条,这个是实打实的物理硬件容量,所以在操作系统中定义这部门的容量叫物理内存。
实则物理内存的布局实际上就是一个内存大数组,如图3所示。图3 物理内存布局
每一个元素都会对应一个地址,称之为物理内存地址。那么CPU在运算的过程中,如果需要从内存中取1个字节的数据,就需要基于这个数据的物理内存地址去运算即可,而且物理内存地址是连续的,可以根据一个基准地址进行偏移来取得相应的一块连续内存数据。 一个操作系统是不可能只运行一个程序的,那么这个大数组物理内存势必要被N个程序分成N分,供每个程序使用。但是程序是活的,一个程序可能一会需要1MB的内存,一会又需要1GB的内存。操作系统只能取这个程序允许的最大内存极限来分配内存给这个进程,但这样会导致每个进程都会多要去一大部分内存,而这些多要的内存却大概率不会被使用,如图4所示。图4 物理内存分配的困局
当N个程序同时使用同一块内存时,那么产生读写的冲突也在所难免。这样就会导致这些昂贵的物理内存条,几乎跑不了几个程序,内存的利用率也就提高不上来。所以就引出了操作系统的内存管理方式,操作系统提供了虚拟内存来解决这件事。 所谓虚拟,类似是假、凭空而造的大致意思。对比上图3.3所示的物理内存布局,虚拟内存的大致表现方式如图5所示。
图5 虚拟内存布局
虚拟内存地址是基于物理内存地址之上凭空而造的一个新的逻辑地址,而操作系统暴露给用户进程的只是虚拟内存地址,操作系统内部会对虚拟内存地址和真实的物理内存地址做映射关系,来管理地址的分配,从而使物理内存的利用率提高。 这样用户程序(进程)只能使用虚拟的内存地址来获取数据,系统会将这个虚拟地址翻译成实际的物理地址。这里面每一个程序统一使用一套连续虚拟地址,比如 0x 0000 0000 ~ 0x ffff ffff。从程序的角度来看,它觉得自己独享了一整块内存,且不用考虑访问冲突的问题。系统会将虚拟地址翻译成物理地址,从内存上加载数据。 但如果仅仅把虚拟内存直接理解为地址的映射关系,那就是过于低估虚拟内存的作用了。 对于(1),(2)两点,上述应该已经有一定的描述了,其中针对(1)的最大化,虚拟内存还实现了“读时共享,写时复制”的机制,可以在物理层同一个字节的内存地址被多个虚拟内存空间映射,表现方式如图6所示。图6 读时共享,写时复制
上图所示如果一个进程需要进行写操作,则这个内存将会被复制一份,成为当前进程的独享内存。如果是读操作,可能会多个进程访问的物理空间是相同的空间。 如果一个内存几乎大量都是被读取的,则可能会多个进程共享同一块物理内存,但是他们的各自虚拟内存是不同的。当然这个共享并不是永久的,当其中有一个进程对这个内存发生写,就会复制一份,执行写操作的进程就会将虚拟内存地址映射到新的物理内存地址上。 对于第(3)点,是虚拟内存为了最大化利用物理内存,如果进程使用的内存足够大,则导致物理内存短暂的供不应求,那么虚拟内存也会“开疆拓土”从磁盘(硬盘)上虚拟出一定量的空间,挂在虚拟地址上,而且这个动作进程本身是不知道的,因为进程只能够看见自己的虚拟内存空间,如图7所示。图7 虚拟内存从磁盘映射空间
综上可见虚拟内存的重要性,不仅提高了利用率而且整条内存调度的链路完全是对用户态物理内存透明,用户可以安心的使用自身进程独立的虚拟内存空间进行开发。 那么对于虚拟内存地址是如何映射到物理内存地址上的呢?会不会是一个固定匹配地址逻辑处理的?假设使用固定匹配地址逻辑做映射,可能会出现很多虚拟内存打到同一个物理内存上,如果发现被占用,则会再重新打。这样对映射地址寻址的代价极大,所以操作系统又加了一层专门用来管理虚拟内存和物理内存映射关系的东西,就是MMU(Memory Management Unit),如图8所示。
图 8 MMU内存管理单元
MMU是在CPU里的,或者说是CPU具有一个内存管理单元MMU,下面来介绍一下MMU具体的管理逻辑。 虚拟内存本身是通过一个叫页表(Page Table)的东西来实现的,接下来介绍页和页表这两个概念。1.页
页是操作系统中用来描述内存大小的一个单位名称。一个页的含义是大小为4K(1024*4=4096字节)的内存空间。操作系统对虚拟内存空间是按照这个单位来管理的。2.页表
页表实际上就是页的集合,就是基于页的一个数组。页只是表示内存的大小,而页表条目(PTE[1]), 才是页表数组中的一个元素。[1] PTE是Page Table Entry的缩写,表示页表条目。PTE是由一个有效位和N位地址字段构成,能够有效标识这个虚拟内存地址是否分配了物理内存。
为了方便读者理解,下面用一个抽象的图来表示页、页表、和页表元素PTE的概念和关系,如图9所示。图 9 页、页表、PTE之间的关系
虚拟内存的实现方式,大多数都是通过页表来实现的。操作系统虚拟内存空间分成一页一页的来管理,每页的大小为 4K(当然这是可以配置的,不同操作系统不一样)。磁盘和主内存之间的置换也是以页为单位来操作的。4K 算是通过实践折中出来的通用值,太小了会出现频繁的置换,太大了又浪费内存。 虚拟内存到物理内存的映射关系的存储结构就是由类似上述图3.9中的页表记录,实则是一个数组。这里要注意的是,页是一次读取的内存单元,但是真正起到虚拟内存寻址的是PTE,也就是页表中的一个元素。PTE的大致内部结构如图10所示。图 10 PTE内部构造
可以看出每个PTE是由一个有效位和一个包含物理页号或者磁盘地址组成,有效位表示当前虚拟页是否已经被缓存在主内存中(或者CPU的高速缓存Cache中)。 虚拟页为何有会是否已经被缓存在主内存中一说?虚拟页表(简称页表)虽然作为虚拟内存与物理内存的映射关系,但是本身也是需要存放在某个位置上,所以自身本身也是占用一定内存的。所以页表本身也是被操作系统放在物理内存的指定位置。CPU 把虚拟地址给MMU,MMU去物理内存中查询页表,得到实际的物理地址。当然 MMU 不会每次都去查的,它自己也有一份缓存叫Translation Lookaside Buffer (TLB)[2],是为了加速地址翻译。CPU、MMU与TLB的相互关系如图11所示。[2]CPU每次访问虚拟内存,虚拟地址都必须转换为对应的物理地址。从概念上说,这个转换需要遍历页表,页表是三级页表,就需要3次内存访问。就是说,每次虚拟内存访问都会导致4次物理内存访问。简单点说,如果一次虚拟内存访问对应了4次物理内存访问,肯定比1次物理访问慢,这样虚拟内存肯定不会发展起来。幸运的是,有一个聪明的做法解决了大部分问题:现代CPU使用一小块关联内存,用来缓存最近访问的虚拟页的PTE。这块内存称为translation lookaside buffer(TLB),参考《IA-64 Linux Kernel: Design and Implementation》
图 11 CPU、MMU与TLB的交互关系
从上图可以看出,TLB是虚拟内存页,即虚拟地址和物理地址映射关系的缓存层。MMU当收到地址查询指令,第一时间是请求TLB的,如果没有才会进行从内存中的虚拟页进行查找,这样可能会触发多次内存读取,而读取TLB则不需要内存读取,所进程读取的步骤顺序为: 下面继续分析PTE的内部构造,根据有效位的特征可以得到不同的含义如下: (1)有效位为1,表示虚拟页已经被缓存在内存(或者CPU高速缓存TLB-Cache)中。 (2)有效位为0,表示虚拟页未被创建且没有占用内存(或者CPU高速缓存TLB-Cache),或者表示已经创建虚拟页但是并没有存储到内存(或者CPU高速缓存TLB-Cache)中。 通过上述的标识位,可以将虚拟页集合分成三个子集,如表3所示。表2 虚拟页被分成的三种子集| 有效位 | 集合特征 |
| 1 | 虚拟内存已创建和分配页,已缓存在物理内存(或TLB-Cache)中。 |
| 0 | 虚拟内存还未分配或创建。 |
| 0 | 虚拟内存已创建和分配页,但未缓存在物理内存(或TLB-Cache)中。 |
对于Golang开发者,对虚拟内存的存储结构了解到此步即可,如果想更深入的了解MMU存储结果可以翻阅其他操作系统或硬件相关书籍或资料。下面来分析一下在访问一次内存的整体流程。
图 12 CPU内存访问的详细流程
当某个进程进行一次内存访问指令请求,将触发如图3.12的内存访问具体的访问流程如下: (1)进程将内存相关的寄存器指令请求运算发送给CPU,CPU得到具体的指令请求。 (2)计算指令被CPU加载到寄存器当中,准备执行相关指令逻辑。 (3)CPU对相关可能请求的内存生成虚拟内存地址。一个虚拟内存地址包括虚拟页号VPN(Virtual Page Number)和虚拟页偏移量VPO(Virtual Page Offset)[3]。[3]一个虚拟地址VA(Virtual Address)= 虚拟页号VPN + 虚拟页偏移量VPO。
(6)MMU通过虚拟页号查找对应的PTE条目(优先层TLB缓存查询)。 (7)通过得到对应的PTE上的有效位来判断当前虚拟页是否在主存中。 (8)如果索引到的PTE条目的有效位为1,则表示命中,将对应PTE上的物理页号PPN(Physical Page Number)和虚拟地址中的虚拟页偏移量VPO进行串联从而构造出主存中的物理地址PA(Physical Address)[4],进入步骤(9)。[4]一个物理地址PA(Physical Address)= 物理页号PPN * 页长度PageSize+ 物理页号偏移PPO(Physical Page Offset)
(9)通过物理内存地址访问物理内存,当前的寻址流程结束。 (10)如果有效位为0,则表示未命中,一般称这种情况为缺页。此时MMU将产生一个缺页异常,抛给操作系统。 (11)操作系统捕获到缺页异常,开始执行异常处理程序。 (12)此时将选择一个牺牲页并将对应的所缺虚拟页调入并更正新页表上的PTE,如果当前牺牲页有数据,则写入磁盘,得到物理内存页号PPN(Physical Page Number)。 (13)缺页处理程序更新之前索引到的PTE,并且写入物理内存怒页号PPN,有效位设置为1。 (14)缺页处理程序再次返回到原来的进程,且再次执行缺页指令,CPU重新将虚拟地址发给MMU,此时虚拟页已经存在物理内存中,本次一定会命中,通过(1)~(9)流程,最终将请求的物理内存返回给处理器。 以上就是一次CPU访问内存的详细流程。可以看出来上述流程中,从第(10)步之后的流程就稍微有一些繁琐。类似产生异常信号、捕获异常,再处理缺页流程,如选择牺牲页,还要将牺牲页的数据存储到磁盘上等等。所以如果频繁的执行(10)~(14)步骤会对性能影响很大。因为牺牲页有可能会涉及到磁盘的访问,而磁盘的访问速度非常的慢,这样就会引发程序性能的急剧下降。 一般从(1)~(9)步流程结束则表示页命中,反之为未命中,所以就会出现一个新的性能级指标,即命中率。命中率是访问次数与页命中次数之比。一般命中率低说明物理内存不足,数据在内存和磁盘之间交换频繁,但如果物理内存充分,则不会出现频繁的内存颠簸现象。 上述了解到内存的命中率实际上是一衡量每次内存访问均能被页直接寻址到而不是产生缺页的指标。所以如果经常在一定范围内的内存则出现缺页的情况就会降低。这就是程序的一种局部性特性的体现。
局部性就是在多次内存引用的时候,会出现有的内存被经常引用多次,而且在该位置附近的其他位置,也有可能接下来被引用到。一般大多数程序都会具备局部性的特点。 实际上操作系统在设计过程中经常会用到缓存来提升性能,或者在设计解决方案等架构的时候也会考虑到缓存或者缓冲层的概念,实则就是利用程序或业务天然的局部性特征。因为如果没有局部性的特性,则缓存级别将起不到太大的作用,所以在设计程序或者业务的时候应该多考虑增强程序局部性的特征,这样的程序会更快。 下面是一个非常典型的案例来验证程序局部性的程序示例,具体代码如下:package MyGolang
func Loop(nums []int, step int) { l := len(nums) for i := 0; i < step; i++ { for j := i; j < l; j += step { nums[j] = 4 //访问内存,并写入值 } }}
Loop()函数的功能是遍历数组nums,并且将nums中的每个元素均设置为4。但是这里用了一个step来规定每次遍历的跨度。可以跟读上述代码,如果step等于1,则外层for循环只会执行1次。内层for循环则正常遍历nums。实则相当于代码如下:
func Loop(nums []int, step int) { l := len(nums) for j := 0; j < l; j += 1 { nums[j] = 4 //访问内存,并写入值 }}
如果Step等于3,则表示外层for循环要一共完成3次,内层for循环每次遍历的数组下标值都相差3。第一次遍历会被遍历的nums下标为0、3、6、9、12……,第二次遍历会遍历的nums下标为1、4、7、10、13……,第三次遍历会遍历的nums下标为2、5、8、11、14……。那么三次外循环就会将全部遍历完整个nums数组。
上述的程序表示了访问数组的局部性,step跨度越小,则表示访问nums相邻内存的局部性越好,step越大则相反。 接下来用Golang的Benchmark性能测试来分别对step取不同的值进行压测,来看看通过Benchmark执行Loop()函数而统计出来的几种情况,最终消耗的时间差距为多少。首先创建loop_test.go文件,实现一个制作数组并且赋值初始化内存值的函数CreateSource(),代码如下:package MyGolang
import "testing"
func CreateSource(len int) []int { nums := make([]int, 0, len)
for i := 0 ; i < len; i++ { nums = append(nums, i) }
return nums}
其次实现一个Benchmark,制作一个长度为10000的数组,这里要注意的是创建完数组后要执行b.ResetTimer()重置计时,去掉CreateSource()消耗的时间,step跨度为1的代码如下:func BenchmarkLoopStep1(b *testing.B) { //制作源数据,长度为10000 src := CreateSource(10000)
b.ResetTimer() for i:=0; i < b.N; i++ { Loop(src, 1) }}
Golang中的b.N表示Golang一次压测最终循环的次数。BenchmarkLoopStep1()会将N次的总耗时时间除以N得到平均一次执行Loop()函数的耗时。因为要对比多个step的耗时差距,按照上述代码再依次实现step为2、3、4、5、6、12、16等Benchmark性能测试代码,如下:func BenchmarkLoopStep2(b *testing.B) { //制作源数据,长度为10000 src := CreateSource(10000)
b.ResetTimer() for i:=0; i < b.N; i++ { Loop(src, 2) }}
func BenchmarkLoopStep3(b *testing.B) { //制作源数据,长度为10000 src := CreateSource(10000)
b.ResetTimer() for i:=0; i < b.N; i++ { Loop(src, 3) }}
func BenchmarkLoopStep4(b *testing.B) { //制作源数据,长度为10000 src := CreateSource(10000)
b.ResetTimer() for i:=0; i < b.N; i++ { Loop(src, 4) }}
func BenchmarkLoopStep5(b *testing.B) { //制作源数据,长度为10000 src := CreateSource(10000)
b.ResetTimer() for i:=0; i < b.N; i++ { Loop(src, 5) }}
func BenchmarkLoopStep6(b *testing.B) { //制作源数据,长度为10000 src := CreateSource(10000)
b.ResetTimer() for i:=0; i < b.N; i++ { Loop(src, 6) }}
func BenchmarkLoopStep12(b *testing.B) { //制作源数据,长度为10000 src := CreateSource(10000)
b.ResetTimer() for i:=0; i < b.N; i++ { Loop(src, 12) }}
func BenchmarkLoopStep16(b *testing.B) { //制作源数据,长度为10000 src := CreateSource(10000)
b.ResetTimer() for i:=0; i < b.N; i++ { Loop(src, 16) }}
上述每个Benchmark都是相似的代码,只有step传参不同,接下来通过执行下述指令来进行压测,指令如下:$ go test -bench=. -count=3
其中“count=3”表示每个Benchmark要执行3次,这样是更好验证上述的结果。具体的运行结果如下:goos: darwingoarch: amd64pkg: MyGolangBenchmarkLoopStep1-12 366787 2792 ns/opBenchmarkLoopStep1-12 432235 2787 ns/opBenchmarkLoopStep1-12 428527 2849 ns/opBenchmarkLoopStep2-12 374282 3282 ns/opBenchmarkLoopStep2-12 363969 3263 ns/opBenchmarkLoopStep2-12 361790 3315 ns/opBenchmarkLoopStep3-12 308587 3760 ns/opBenchmarkLoopStep3-12 311551 4369 ns/opBenchmarkLoopStep3-12 289584 4622 ns/opBenchmarkLoopStep4-12 275166 4921 ns/opBenchmarkLoopStep4-12 264282 4504 ns/opBenchmarkLoopStep4-12 286933 4869 ns/opBenchmarkLoopStep5-12 223366 5609 ns/opBenchmarkLoopStep5-12 202597 5655 ns/opBenchmarkLoopStep5-12 214666 5623 ns/opBenchmarkLoopStep6-12 187147 6344 ns/opBenchmarkLoopStep6-12 177363 6397 ns/opBenchmarkLoopStep6-12 185377 6333 ns/opBenchmarkLoopStep12-12 126860 9660 ns/opBenchmarkLoopStep12-12 127557 9741 ns/opBenchmarkLoopStep12-12 126658 9492 ns/opBenchmarkLoopStep16-12 95116 12754 ns/opBenchmarkLoopStep16-12 95175 12591 ns/opBenchmarkLoopStep16-12 92106 12533 ns/opPASSok MyGolang31.712s
(1)“BenchmarkLoopStep1-12”其中的“-12”表示GOMAXPROCS(线程数)为12,这个在此处不需要过度的关心。(2)“366787”表示一共执行了366787次,即代码中b.N的值,这个值不是固定不变的。实际上是通过循环调用366787次Loop()函数得到的最后性能结果。(3)“2792 ns/op”表示平均每次Loop()函数所消耗的时间是2792纳秒。通过上述结果可以看出,随着Step参数的增加,内存访问的局部性就越差,那么执行Loop()的性能也就越差,在Step为16和Step为1的结果来看,性能相差近4~5倍之间。通过结果可以得出如果要设计出一个更加高效的程序,提高代码的局部性访问是非常有必要的程序性能优化手段之一。思考 在Golang的GPM调度器模型中,为什么一个G开辟的子G优先放在当前的本地G队列中,而不是放在其他M上的本地P队列中?GPM为何要满足局部性的调度设计? 本节介绍自主实现一个内存管理模块都大致需要哪些基础的开发和组件建设。接下来的一些代码不需要读者去掌握,因为Golang已经给开发者提供的内存管理模式,开发者不需要关心Golang的内存分配情况。但是为了更好的理解Golang的内存管理模型,需要了解如果自己实现一套简单的内存管理模块应该需要关注哪些点和需要实现哪些必要的模块和机制。
本节接下来的内容即是通过Golang自我实现一个内存管理模块和内存池的建设,该模块非企业级开发而是促进理解内存管理模型的教程型代码。 因为Golang语言已经内置的内存管理机制,所以如果用Golang原生的语法结构如Slice、String、Map等都会自动触发Golang的内存管理机制。本案例为了介绍如何实现一个自我管理的内存模型,所以直接使用的C语言的malloc()、free()系统调用来开辟和释放内存空间,使用C语言的memcpy()、memmove()等进行内存的拷贝和移动。至于如何封装Golang语法的Malloc()、Free()、Memcpy()、Memmove()等函数,即是利用的Golang中的Cgo机制。
注意 Cgo提供了 Golang 和 C 语言相互调用的机制。可以通过 Cgo 用 Golang 调用 C 的接口,对于C++的接口可以用 C 包装一下提供给 Golang 调用。被调用的 C 代码可以直接以源代码形式提供或者打包静态库或动态库在编译时链接。 Cgo 的具体使用教程本章将不继续详细介绍,本章主要介绍下在内存管理设计所涉及到部分Cgo语法部分。 开始创建一个zmem/目录,作为当前内存实现案例的项目名称。在zmem/目录下再创建c/文件夹,这里用来实现通过Cgo来封装的C语言内存管理接口。 在c/目录下创建memory.go文件,分别封装的C语言内存接口代码如下://zmem/c/memory.go
package c
/*#include <string.h>#include <stdlib.h> */import "C"import "unsafe"
func Malloc(size int) unsafe.Pointer { return C.malloc(C.size_t(size))}
func Free(data unsafe.Pointer) { C.free(data)}
func Memmove(dest, src unsafe.Pointer, length int) { C.memmove(dest, src, C.size_t(length))}
func Memcpy(dest unsafe.Pointer, src []byte, length int) { srcData := C.CBytes(src) C.memcpy(dest, srcData, C.size_t(length))}
1.import“C”
代表Cgo模块的启动,其中import “C”上面的全部注释代码(中间不允许有空白行)均为C语言原生代码。因为在下述接口封装中使用到了C语言的malloc()、free()、memmove()、memcpy()等函数,这些函数的声明需要包含头文件string.h和stdlib.h,所以在注释部分添加了导入这两个头文件的代码,并且通过import “C”导入进来。2.unsafe.Pointer
这里以malloc()系统调用为例,通过man[5]手册查看malloc()函数的原型如下:#include <stdlib.h>
void *malloc(size_t size);
[5] Man 手册页(Manua pages,缩写man page)是在Linux操作系统在线软件文档的一种普遍形式。内容包括计算机程序库和系统调用等命令的帮助手册。
函数malloc()形参是C语言中的size_t数据类型类型,那么在Golang中使用对应的C类型是C.size_t,是的,一般的C基本类型只需要通过C包直接访问即可。但是对于malloc()的返回值void*来说,这是一个万能指针,期功能用法类似Golang中的interface{},但是在语法上并不能将二者直接划等号。而Golang给开发这提供了一个可以直接对等C中void*的数据类型,就是unsafe.Pointer。unsafe.Pointer是Golang封装好的可以比较自由访问的指针类型,其含义和void*万能指针相似。在语法上,也可以直接将void*类型数据赋值给unsafe.Pointer类型数据。3.Golang与C的字符串等类型转换
在Cgo中Go的字符串与Byte数组都会转换为C的char数组,其中Golang的Cgo模块提供了几个方法供开发者使用:// Go字符串转换为C字符串。C字符串使用malloc分配,因此需要使用C.free以避免内存泄露func C.CString(string) *C.char
// Go byte数组转换为C的数组。使用malloc分配的空间,因此需要使用C.free避免内存泄漏func C.CBytes([]byte) unsafe.Pointer
// C字符串转换为Go字符串func C.GoString(*C.char) string
// C字符串转换为Go字符串,指定转换长度func C.GoStringN(*C.char, C.int) string
// C数据转换为byte数组,指定转换的长度func C.GoBytes(unsafe.Pointer, C.int) []byte
其中C.CBytes()方法可以将Golang的[]byte切片转换成unsafe.Pointer类型。利用这个转换功能,来分析一下是如何封装memcpy()函数的:func Memcpy(dest unsafe.Pointer, src []byte, length int) { srcData := C.CBytes(src) C.memcpy(dest, srcData, C.size_t(length))}
新封装的Memcpy()的第一个形参是任意指针类型,表示拷贝的目标地址,第二个形参是[]byte类型,表示被拷贝的源数据,第三个参数表示本次拷贝数据的长度。因为C语言中的memcpy()函数原型如下:#include <string.h>
void *memcpy(void *dst, const void *src, size_t n);
对于src数据源形参需要[]byte转换为unsafe.Pointer,因此在调用C的接口是通过C.CBytes()转换了一下。 Free()和Memmove()方法的封装和上述一样。Free()与Malloc()对应,Memmove()为移动一块连续内存。 接下来将上述封装做一个简单的单元测试,在c/目录下创建memory_test.go,实现代码如下:package c_test
import ( "zmem/c" "bytes" "encoding/binary" "fmt" "testing" "unsafe")
func IsLittleEndian() bool { var n int32 = 0x01020304
//下面是为了将int32类型的指针转换成byte类型的指针 u := unsafe.Pointer(&n) pb := (*byte)(u)
//取得pb位置对应的值 b := *pb
//由于b是byte类型,最多保存8位,那么只能取得开始的8位 // 小端: 04 (03 02 01) // 大端: 01 (02 03 04) return (b == 0x04)}
func IntToBytes(n uint32) []byte { x := int32(n) bytesBuffer := bytes.NewBuffer([]byte{})
var order binary.ByteOrder if IsLittleEndian() { order = binary.LittleEndian } else { order = binary.BigEndian } binary.Write(bytesBuffer, order, x)
return bytesBuffer.Bytes()}
func TestMemoryC(t *testing.T) { data := c.Malloc(4) fmt.Printf(" data %+v, %T\n", data, data) myData := (*uint32)(data) *myData = 5 fmt.Printf(" data %+v, %T\n", *myData, *myData)
var a uint32 = 100 c.Memcpy(data, IntToBytes(a), 4) fmt.Printf(" data %+v, %T\n", *myData, *myData)
c.Free(data)}
单元测试接口是TestMemoryC(),首先通过Malloc()开辟4个字节内存,然后将这4个字节赋值为5,打印结果看data的值是否是5。最后是将100通过Memcpy()拷贝给这4个字节,看最后的结果是否是100,运行结果如下:=== RUN TestMemoryCdata 0x9d040a0, unsafe.Pointerdata 5, uint32data 100, uint32--- PASS: TestMemoryC (0.00s)PASS
通过单元测试结果来看,目前的内存开辟和拷贝的相关接口可以正常使用,接下来就是基于这些接口来实现内存管理的模块实现。 在zmem目录下再创建mem文件夹,包mem模块作为内存管理相关代码的包名,然后再mem目下面创建buf.go,作为Buf的代码实现。文件路径结构如下:
zmem/├── README.md├── c/│ ├── memory.go│ └── memory_test.go├── go.mod└── mem/└── buf.go
接下来定义一个Buf数据结构,具体的定义实现如下://zmem/mem/buf.go
package mem
import "unsafe"
type Buf struct { //如果存在多个buffer,是采用链表的形式链接起来 Next *Buf //当前buffer的缓存容量大小 Capacity int //当前buffer有效数据长度 length int //未处理数据的头部位置索引 head int //当前buf所保存的数据地址 data unsafe.Pointer}
(1)Capacity,表示当前缓冲的容量大小,实则是底层内存分配的最大内存空间上限。(2)length,当前缓冲区的有效数据长度,有效数据长度为用户存入但又未访问的剩余数据长度。(4)data,是当前buf所保存内存的首地址指针,这里用的事unsafe.Pointer类型,表示data所存放的为基础的虚拟内存地址。(5)Next,是Buf类型的指针,指向下一个Buf地址。Buf与Buf之间的关系是一个链表结构。图 13 Buf的数据结构布局
Buf是采用链表的集合方式,每个Buf通过Next进行关联,其中Data为指向底层开辟出来供用户使用的内存。一个内存中有几个刻度索引,内存首地址索引位置定义为0,Head为当前用户应用有效数据的首地址索引,Length为有效数据尾地址索引,有效数据的长度为“Length-Head”。Capacity是开辟内存的尾地址索引,也表示当前Buf的可使用内存容量。//zmem/mem/buf.go
//构造,创建一个Buf对象func NewBuf(size int) *Buf { return &Buf{ Capacity: size, length: 0, head: 0, Next: nil, data : c.Malloc(size), }}
NewBuf()接收一个size形参,用来表示开辟的内存空间长度。这里调用封装的c.Malloc()方法来申请size长度的内存空间,并且赋值给data。 Buf被初始化之后,需要给Buf赋予让调用方传入数据的接口,这里允许一个Buf的内存可以赋予[]byte类型的源数据,方法名称是SetBytes(),定义如下://zmem/mem/buf.go
//给一个Buf填充[]byte数据func (b *Buf) SetBytes(src []byte) { c.Memcpy(unsafe.Pointer(uintptr(b.data)+uintptr(b.head)), src, len(src)) b.length += len(src)}
(1)将[]byte源数据src通过C接口的内存拷贝,给Buf的data赋值。这里要注意的是被拷贝的data的起始地址是b.head。 (2)拷贝之后Buf的有效数据长度要相应的累加偏移,具体的过程如图14所示。图 14 SetBytes内存操作
这里要注意的是,拷贝的起始地址会基于data的基地址向右偏移head的长度,因为定义是从Head到Length是有效合法数据。对于unsafe.Pointer的地址偏移需要转换为uintptr类型进行地址计算。与SetBytes()对应的是GetBytes(),是从Buf的data中获取数据,具体实现代码如下://zmem/mem/buf.go
//获取一个Buf的数据,以[]byte形式展现func (b *Buf) GetBytes() []byte { data := C.GoBytes(unsafe.Pointer(uintptr(b.data)+uintptr(b.head)), C.int(b.length)) return data}
其中C.GoBytes()是Cgo模块提供的将C数据转换为byte数组,并且指定转换的长度。 取数据的起始地址依然是基于data进行head长度的偏移。 Buf还需要提供一个Copy()方法,用来将其他Buf缓冲对象直接复制拷贝到自身当中,且head、length等于对方完全一样,具体实现的代码如下://zmem/mem/buf.go
//将其他Buf对象数据考本到自己中func (b *Buf) Copy(other *Buf) { c.Memcpy(b.data, other.GetBytes(), other.length) b.head = 0 b.length = other.length}
接下来需要提供可以移动head的方法,其作用是缩小有效数据长度,当调用方已经使用了一部分数据之后,这部分数据可能会变成非法的非有效数据,那么就需要将head向后偏移缩小有效数据的长度,Buf将提供一个名字叫Pop()的方法,具体定义如下://zmem/mem/buf.go
//处理长度为len的数据,移动head和修正lengthfunc (b *Buf) Pop(len int) { if b.data == nil { fmt.Printf("pop data is nil") return } if len > b.length { fmt.Printf("pop len > length") return } b.length -= len b.head += len}
一次Pop()操作,首先会判断弹出合法有效数据的长度是否越界。然后对应的head向右偏移,length的有效长度对应做缩减,具体的流程如图15所示。图 15 Pop内存操作的head与length偏移
因为调用方经常的获取数据,然后调用Pop()缩减有效长度,那么不出几次,可能就会导致head越来越接近Capacity,也会导致有效数据之前的已经过期的非法数据越来越多。所以Buf需要提供一个Adjust()方法,来将有效数据的内存迁移至data基地址位置,覆盖之前的已使用过的过期数据,将后续的空白可使用空间扩大。Adjust()的实现方法如下://zmem/mem/buf.go
//将已经处理过的数据,清空,将未处理的数据提前至数据首地址func (b *Buf) Adjust() { if b.head != 0 { if (b.length != 0) { c.Memmove(b.data, unsafe.Pointer(uintptr(b.data) + uintptr(b.head)), b.length) } b.head = 0 }}
Adjust()调用之前封装好的c.Memmove()方法,将有效数据内存平移至Buf的data基地地址,同时将head重置到0位置,具体的流程如图16所示。图 16 Adjust操作的内存平移
Buf也要提供一个清空缓冲内存的方法Clear(),Clear()实现很简单,只需要将几个索引值清零即可,Clear()并不会以操作系统层面回收内存,因为Buf的是否回收,是否被重置等需要依赖BufPool内存池来管理,将在下一小结介绍内存池管理Buf的情况。为了降低系统内存的开辟和回收,Buf可能长期在内存池中存在。调用方只需要改变几个地址索引值就可以达到内存的使用和回收。Clear()方法的实现如下://zmem/mem/buf.go
//清空数据func (b *Buf) Clear() { b.length = 0 b.head = 0}//其他的提供的访问head和length的方法如下:func (b *Buf) Head() int { return b.head}
func (b *Buf) Length() int { return b.length}
现在Buf的基本功能已经实现完成了,接下来实现对Buf的管理内存池模块。 一个Buf只是一次内存使用所需要存放数据的缓冲空间,为了方便多个Buf直接的申请与管理,则需要设计一个内存池来统一进行Buf的调配。 内存池的设计是预开辟内存,就是在首次申请创建内存池的时候,就将池子里全部可以被使用的Buf内存空间集合一并申请开辟出来。调用方在申请内存的时候,是通过内存池来申请,内存池从Buf集合中选择未被使用或占用的Buf返回给调用方。调用方在使用完Buf之后,也是将Buf退还给内存池。这样调用方即使频繁的申请和回收小空间的内存也不会出现频繁的系统调用申请物理内存空间,降低了内存动态开辟的开销成本,业务方的内存访问速度也会有很大的提升。 下面来实现内存池BufPool,首先在zmem/mem/目录下创建buf_pool.go文件,在当前文件来实现BufPool内存池的功能,BufPool的数据结构,代码如下所示://zmem/mem/buf_pool.gopackage mem
import ( "sync")
//内存管理池类型type Pool map[int] *Buf
//Buf内存池type BufPool struct { //所有buffer的一个map集合句柄 Pool Pool PoolLock sync.RWMutex
//总buffer池的内存大小单位为KB TotalMem uint64}
首先定义Pool数据类型,该类型表示管理全部Buf的Map集合,其中Key表示当前 一组Buf的Capacity容量,Value则是一个Buf链表。每个Key下面挂载着相同Capacity的Buf集合链表,其实是BufPool的成员属性定义如下: (1)Pool,当前内存池全部的Buf缓冲对象集合,是一个Map数据结构。 (2)PoolLock,对Map读写并发安全的读写锁。 (3)TotalMem,当前BufPool所开辟内存池申请虚拟内存的总容量。 接下来提供BufPoll的初始化构造函数方法,BufPool作为内存池,全局应该设计成唯一,所以采用单例模式设计,下面定义公共方法MemPool(),用来初始化并且获取BufPoll单例对象,具体的实现方式如下://zmem/mem/buf_pool.go
//单例对象var bufPoolInstance *BufPoolvar once sync.Once
//获取BufPool对象(单例模式)func MemPool() *BufPool{ once.Do(func() { bufPoolInstance = new(BufPool) bufPoolInstance.Pool = make(map[int]*Buf) bufPoolInstance.TotalMem = 0 bufPoolInstance.prev = nil bufPoolInstance.initPool() })
return bufPoolInstance}
全局遍历指针bufPoolInstance作为指向BufPool单例实例的唯一指针,通过Golang标准库提供sync.Once来做只执行依次的Do()方法,来初始化BufPool。在将BufPool成员均赋值完之后,最后通过initPool()方法来初始化内存池的内存申请布局。 内存申请initPool()会将内存的分配结构如图17所示。BufPool会预先将所有要管理的Buf按照内存刻度大小进行分组,如4KB的一组,16KB的一组等待。容量越小的Buf,所管理的Buf链表的数量越多,容量越大的Buf数量则越少。全部的Buf关系通过Map数据结构来管理,由于Buf本身是链表数据结构,所以每个Key所对应的Value只需要保存头结点Buf信息即可,之后的Buf可以通过Buf的Next指针找到。图 17 BufPool内存池的内存管理布局
BufPool的initPool()初始化内存方法的具体实现如下://zmem/mem/buf_pool.go
const ( m4K int = 4096 m16K int = 16384 m64K int = 655535 m256K int = 262144 m1M int = 1048576 m4M int = 4194304 m8M int = 8388608)
/* 初始化内存池主要是预先开辟一定量的空间 这里BufPool是一个hash,每个key都是不同空间容量 对应的value是一个Buf集合的链表
BufPool --> [m4K] -- Buf-Buf-Buf-Buf...(BufList) [m16K] -- Buf-Buf-Buf-Buf...(BufList) [m64K] -- Buf-Buf-Buf-Buf...(BufList) [m256K]-- Buf-Buf-Buf-Buf...(BufList) [m1M] -- Buf-Buf-Buf-Buf...(BufList) [m4M] -- Buf-Buf-Buf-Buf...(BufList) [m8M] -- Buf-Buf-Buf-Buf...(BufList) */func (bp *BufPool) initPool() { //----> 开辟4K buf 内存池 // 4K的Buf 预先开辟5000个,约20MB供开发者使用 bp.makeBufList(m4K, 5000)
//----> 开辟16K buf 内存池 //16K的Buf 预先开辟1000个,约16MB供开发者使用 bp.makeBufList(m16K, 1000)
//----> 开辟64K buf 内存池 //64K的Buf 预先开辟500个,约32MB供开发者使用 bp.makeBufList(m64K, 500)
//----> 开辟256K buf 内存池 //256K的Buf 预先开辟200个,约50MB供开发者使用 bp.makeBufList(m256K, 200)
//----> 开辟1M buf 内存池 //1M的Buf 预先开辟50个,约50MB供开发者使用 bp.makeBufList(m1M, 50)
//----> 开辟4M buf 内存池 //4M的Buf 预先开辟20个,约80MB供开发者使用 bp.makeBufList(m4M, 20)
//----> 开辟8M buf 内存池 //8M的io_buf 预先开辟10个,约80MB供开发者使用 bp.makeBufList(m8M, 10)}
其中makeBufList()为每次初始化一种刻度容量的Buf链表,代码实现如下:
//zmem/mem/buf_pool.go
func (bp *BufPool) makeBufList(cap int, num int) { bp.Pool[cap] = NewBuf(cap)
var prev *Buf prev = bp.Pool[cap] for i := 1; i < num; i ++ { prev.Next = NewBuf(cap) prev = prev.Next } bp.TotalMem += (uint64(cap)/1024) * uint64(num)}
每次创建一行BufList之后,BubPool内存池的TotalMem就对应增加响应申请内存的容量,这个属性就作为当前内存池已经从操作系统获取的内存总容量为多少。 现在BufPool已经具备了申请首次初始化内存池的能力,还应该提供从BufPool获取一个Buf内存的接口,也同时需要当调用方使用完后,再将内存退还给BufPool的接口。1.获取Buf
下面定义Alloc()方法来标识从BufPool中申请一个可用的Buf对象,具体的代码实现如下://zmem/mem/buf_pool.go
package mem
import ( "errors" "fmt" "sync")
const ( //总内存池最大限制单位是Kb 所以目前限制是 5GB EXTRA_MEM_LIMIT int = 5 * 1024 * 1024)
/* 开辟一个Buf*/func (bp *BufPool) Alloc(N int) (*Buf, error) { //1 找到N最接近哪hash 组 var index int if N <= m4K { index = m4K } else if (N <= m16K) { index = m16K } else if (N <= m64K) { index = m64K } else if (N <= m256K) { index = m256K } else if (N <= m1M) { index = m1M } else if (N <= m4M) { index = m4M } else if (N <= m8M) { index = m8M } else { return nil, errors.New("Alloc size Too Large!"); }
//2 如果该组已经没有,需要额外申请,那么需要加锁保护 bp.PoolLock.Lock() if bp.Pool[index] == nil { if (bp.TotalMem + uint64(index/1024)) >= uint64(EXTRA_MEM_LIMIT) { errStr := fmt.Sprintf("already use too many memory!\n") return nil, errors.New(errStr) }
newBuf := NewBuf(index) bp.TotalMem += uint64(index/1024) bp.PoolLock.Unlock() fmt.Printf("Alloc Mem Size: %d KB\n", newBuf.Capacity/1024) return newBuf, nil }
//3 如果有该组有Buf内存存在,那么得到一个Buf并返回,并且从pool中摘除该内存块 targetBuf := bp.Pool[index] bp.Pool[index] = targetBuf.Next bp.TotalMem -= uint64(index/1024) bp.PoolLock.Unlock() targetBuf.Next = nil fmt.Printf("Alloc Mem Size: %d KB\n", targetBuf.Capacity/1024) return targetBuf, nil}
(1)如果上层需要N个字节的大小的空间,找到与N最接近的Buf链表集合,从当前Buf集合取出。(2)如果该组已经没有节点使用,可以额外申请总申请长度不能够超过最大的限制大小 EXTRA_MEM_LIMIT。(3)如果有该节点需要的内存块,直接取出,并且将该内存块从BufPool摘除。2.退还Buf
定义Revert()方法为为退还使用后的Buf给BufPool内存池,具体的代码实现如下://当Alloc之后,当前Buf被使用完,需要重置这个Buf,需要将该buf放回pool中func (bp *BufPool) Revert(buf *Buf) error { //每个buf的容量都是固定的在hash的key中取值 index := buf.Capacity //重置buf中的内置位置指针 buf.Clear()
bp.PoolLock.Lock() //找到对应的hash组 buf首届点地址 if _, ok := bp.Pool[index]; !ok { errStr := fmt.Sprintf("Index %d not in BufPoll!\n", index) return errors.New(errStr) }
//将buffer插回链表头部 buf.Next = bp.Pool[index] bp.Pool[index] = buf bp.TotalMem += uint64(index/1024) bp.PoolLock.Unlock() fmt.Printf("Revert Mem Size: %d KB\n",index/1024)
return nil}
Revert()会根据当前Buf的Capacity找到对应的Hash刻度,然后将Buf插入到链表的头部,在插入之前通过Buf的Clear()将Buf的全部有效数据清空。 接下来对上述接口做一些单元测试,在zmem/mem/目录下创建buf_test.go文件。1.TestBufPoolSetGet
首先测试基本的SetBytes()和GetBytes()方法,单测代码编写如下://zmem/mem/buf_test.go
package mem_test
import ( "zmem/mem" "fmt" "testing")
func TestBufPoolSetGet(t *testing.T) { pool := mem.MemPool()
buffer, err := pool.Alloc(1) if err != nil { fmt.Println("pool Alloc Error ", err) return }
buffer.SetBytes([]byte("Aceld12345")) fmt.Printf("GetBytes = %+v, ToString = %s\n", buffer.GetBytes(), string(buffer.GetBytes())) buffer.Pop(4) fmt.Printf("GetBytes = %+v, ToString = %s\n", buffer.GetBytes(), string(buffer.GetBytes()))}
单测用例是首先申请一个内存buffer,然后设置“Aceld12345”内容,然后输出日志,接下来弹出有效数据4个字节,再打印buffer可以访问的合法数据,执行单元测试代码,通过如下指令:$ go test -run TestBufPoolSetGetAlloc Mem Size: 4 KBGetBytes = [65 99 101 108 100 49 50 51 52 53], ToString = Aceld12345GetBytes = [100 49 50 51 52 53], ToString = d12345PASSok zmem/mem 0.010s
通过上述结果可得出通过Pop(4)之后,已经弹出了“Acel”前4个字节数据。2.TestBufPoolCopy
接下来测试Buf的Copy()赋值方法,具体的代码如下://zmem/mem/buf_test.go
package mem_test
import ( "zmem/mem" "fmt" "testing")
func TestBufPoolCopy(t *testing.T) { pool := mem.MemPool()
buffer, err := pool.Alloc(1) if err != nil { fmt.Println("pool Alloc Error ", err) return }
buffer.SetBytes([]byte("Aceld12345")) fmt.Printf("Buffer GetBytes = %+v\n", string(buffer.GetBytes()))
buffer2, err := pool.Alloc(1) if err != nil { fmt.Println("pool Alloc Error ", err) return } buffer2.Copy(buffer) fmt.Printf("Buffer2 GetBytes = %+v\n", string(buffer2.GetBytes()))}
将buffer拷贝的buffer2中,看buffer存放的数据内容,执行单元测试指令和所得到的结果如下:$ go test -run TestBufPoolCopyAlloc Mem Size: 4 KBBuffer GetBytes = Aceld12345Alloc Mem Size: 4 KBBuffer2 GetBytes = Aceld12345PASSok zmem/mem 0.008s
3.TestBufPoolAdjust
之后来针对Buf的Adjust()方法进行单元测试,相关代码如下://zmem/mem/buf_test.go
package mem_test
import ( "zmem/mem" "fmt" "testing")
func TestBufPoolAdjust(t *testing.T) { pool := mem.MemPool()
buffer, err := pool.Alloc(4096) if err != nil { fmt.Println("pool Alloc Error ", err) return }
buffer.SetBytes([]byte("Aceld12345")) fmt.Printf("GetBytes = %+v, Head = %d, Length = %d\n", buffer.GetBytes(), buffer.Head(), buffer.Length()) buffer.Pop(4) fmt.Printf("GetBytes = %+v, Head = %d, Length = %d\n", buffer.GetBytes(), buffer.Head(), buffer.Length()) buffer.Adjust() fmt.Printf("GetBytes = %+v, Head = %d, Length = %d\n", buffer.GetBytes(), buffer.Head(), buffer.Length())}
首先buffer被填充“Aceld12345”,然后打印Head索引和Length长度,然后通过Pop弹出有效数据4个字节,继续打印日志,然后通过Adjust()重置Head,再输出buffer信息,通过下述指令执行单元测试和得到的结果如下:$ go test -run TestBufPoolAdjustAlloc Mem Size: 4 KBGetBytes = [65 99 101 108 100 49 50 51 52 53], Head = 0, Length = 10GetBytes = [100 49 50 51 52 53], Head = 4, Length = 6GetBytes = [100 49 50 51 52 53], Head = 0, Length = 6PASSok zmem/mem 0.009s
可以看出第三次输出的日志Head已经重置为0,且GetBytes()得到的有效数据没有改变。 前面小结已经基本实现了一个简单的内存池管理,但如果希望更方便的使用,则需要对Buf和BufPool再做一层封装,这里定义新数据结构Zbuf,对Buf的基本操作做已经封装,使内存管理的接口更加友好,在zmem/mem/目录下创建zbuf.go文件,切定义数据类型Zbuf,具体代码如下:
//zmem/mem/zbuf.gopackage mem
//应用层的buffer数据type ZBuf struct { b *Buf}
1.Clear()方法
Zbuf的Clear()方法实则是将ZBuf中的Buf退还给BufPool,具体代码如下://zmem/mem/zbuf.go
//清空当前的ZBuffunc (zb *ZBuf) Clear() { if zb.b != nil { //将Buf重新放回到buf_pool中 MemPool().Revert(zb.b) zb.b = nil }}
在Buf的Clear()中调用了MemPool()的Revert()方法,回收了当前Zbuf中的Buf对象。
2.Pop()方法
Zbuf的Pop()方法对之前的Pop进行了一些安全性越界校验,具体代码如下://zmem/mem/zbuf.go
//弹出已使用的有效长度func (zb *ZBuf) Pop(len int) { if zb.b == nil || len > zb.b.Length() { return }
zb.b.Pop(len)
//当此时Buf的可用长度已经为0时,将Buf重新放回BufPool中 if zb.b.Length() == 0 { MemPool().Revert(zb.b) zb.b = nil }}
如果Buf在Pop()之后的有效数据长度为0,那么就将当前Buf退还给BufPool。3.Data()方法
Zbuf的Data()方法就是返回Buf的数据,代码如下://zmem/mem/zbuf.go
//获取Buf中的数据func (zb *ZBuf) Data() []byte { if zb.b == nil { return nil } return zb.b.GetBytes()}
4.Adjust()方法
Zbuf的Adjust()方法的封装也没有任何改变://zmem/mem/zbuf.go
//重置缓冲区func (zb *ZBuf) Adjust() { if zb.b != nil { zb.b.Adjust() }}
5.Read()方法
Zbuf的Read()方法是将数据填充到Zbuf的Buf中。Read()方法是将被填充的数据作为形参[]byte传递进来。//zmem/mem/zbuf.go
//读取数据到Buf中func (zb *ZBuf) Read(src []byte) (err error){ if zb.b == nil { zb.b, err = MemPool().Alloc(len(src)) if err != nil { fmt.Println("pool Alloc Error ", err) } } else { if zb.b.Head() != 0 { return nil } if zb.b.Capacity - zb.b.Length() < len(src) { //不够存,重新从内存池申请 newBuf, err := MemPool().Alloc(len(src)+zb.b.Length()) if err != nil { return nil } //将之前的Buf拷贝到新申请的Buf中去 newBuf.Copy(zb.b) //将之前的Buf回收到内存池中 MemPool().Revert(zb.b) //新申请的Buf成为当前的ZBuf zb.b = newBuf } }
//将内容写进ZBuf缓冲中 zb.b.SetBytes(src)
return nil}
如果当前Zbuf的Buf为空则会向BufPool中申请内存。如果传递的源数据超过的当前Buf所能承载的容量,那么Zbuf会申请一个更大的Buf,将之前的已有的数据通过Copy()到新申请的Buf中,之后将之前的Buf退还给BufPool中。6.其他可拓展方法等
上述的Read()方法代表Zbuf从参数获取源数据,如果为了更方便的填充Zbuf,可以封装类似接口,如Fd文件描述符中读取数据到Zbuf中、从文件读取数据到Zbuf中、从网络套接字读取数据到Zbuf中等等,相关函数原型如下://zmem/mem/zbuf.go
//读取数据从Fd文件描述符中func (zb *ZBuf) ReadFromFd(fd int) error { //... return nil}
//将数据写入Fd文件描述符中func (zb *ZBuf) WriteToFd(fd int) error { //... return nil}
//读取数据从文件中func (zb *ZBuf) ReadFromFile(path string) error { //... return nil}
func (zb *ZBuf) WriteToFile(path string) error { //... return nil}
//读取数据从网络连接中func (zb *ZBuf) ReadFromConn(conn net.Conn) error { //... return nil}
func (zb *ZBuf) WriteToConn(conn net.Conn) error { //... return nil}
这里就不一一展开的,具体实现方式和Read()方法类似。这样Zbuf就可以通过不同的媒介来填充Buf并且来使用,业务层只需要面向Zbuf就可以获取数据,无需关心具体的IO层逻辑。 在了解Golang的内存管理之前,一定要了解的基本申请内存模式,即TCMalloc(Thread Cache Malloc)。Golang的内存管理就是基于TCMalloc的核心思想来构建的。本节将介绍TCMalloc的基础理念和结构。
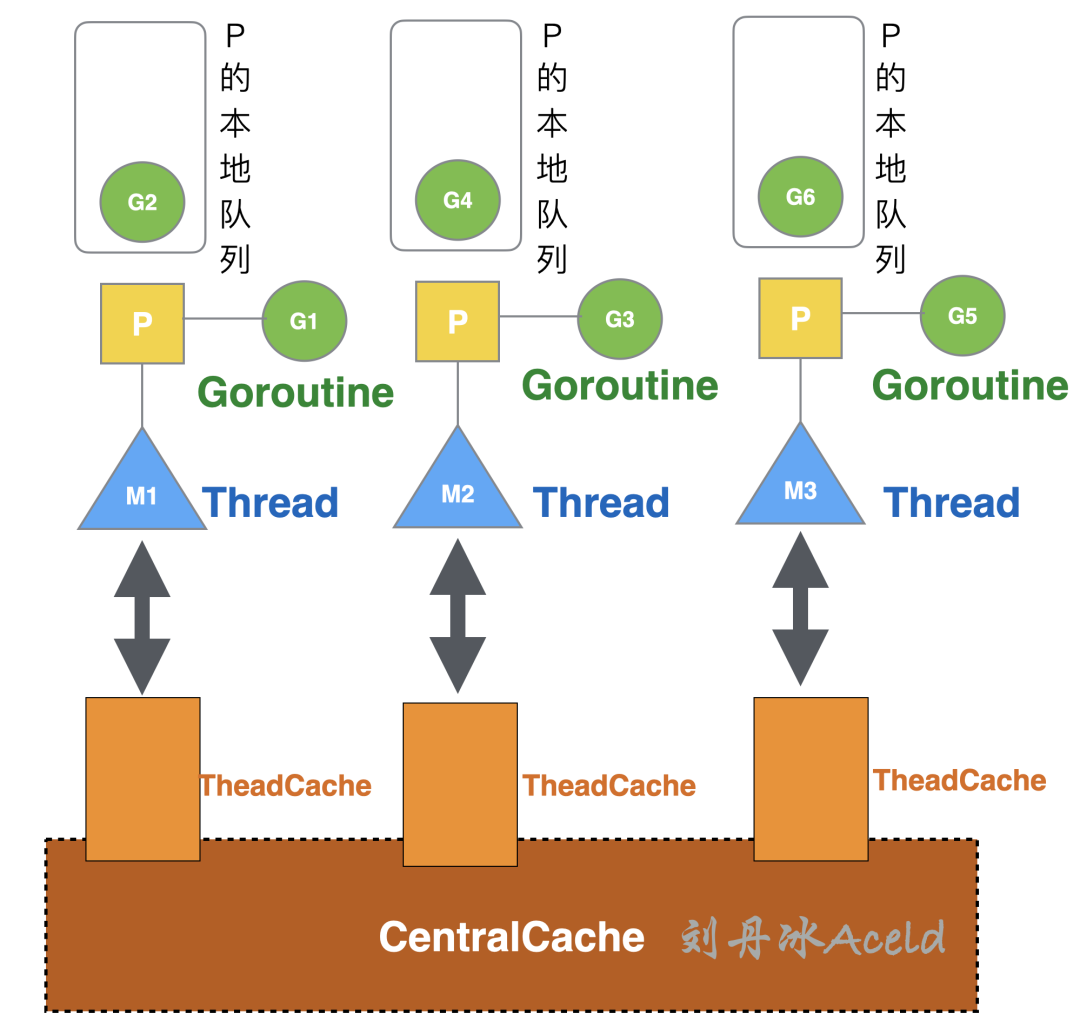
TCMalloc最大优势就是每个线程都会独立维护自己的内存池。在之前章节介绍的自定义实现的Golang内存池版BufPool实则是所有Goroutine或者所有线程共享的内存池,其关系如图18所示。
图 18 BufPool内存池与线程Thread的关系
这种内存池的设计缺点显而易见,应用方全部的内存申请均需要和全局的BufPool交互,为了线程的并发安全,那么频繁的BufPool的内存申请和退还需要加互斥和同步机制,影响了内存的使用的性能。 TCMalloc则是为每个Thread预分配一块缓存,每个Thread在申请内存时首先会先从这个缓存区ThreadCache申请,且所有ThreadCache缓存区还共享一个叫CentralCache的中心缓存。这里假设目前Golang的内存管理用的是原生TCMalloc模式,那么线程与内存的关系将如图19所示。图 19 TCMalloc内存池与线程Thread的关系
这样做的好处其一是ThreadCache做为每个线程独立的缓存,能够明显的提高Thread获取高命中的数据,其二是ThreadCache也是从堆空间一次性申请,即只触发一次系统调用即可。每个ThreadCache还会共同访问CentralCache,这个与BufPool的类似,但是设计更为精细一些。CentralCache是所有线程共享的缓存,当ThreadCache的缓存不足时,就会从CentralCache获取,当ThreadCache的缓存充足或者过多时,则会将内存退还给CentralCache。但是CentralCache由于共享,那么访问一定是需要加锁的。ThreadCache作为线程独立的第一交互内存,访问无需加锁,CentralCache则作为ThreadCache临时补充缓存。 TCMalloc的构造不仅于此,提供了ThreadCache和CentralCache可以解决小对象内存块的申请,但是对于大块内存Cache显然是不适合的。 TCMalloc将内存分为三类,如表4所示。表4 TCMalloc的内存分离| 对象 | 容量 |
| 小对象 | (0,256KB] |
| 中对象 | (256KB, 1MB] |
| 大对象 | (1MB, +∞) |
所以为了解决中对象和大对象的内存申请,TCMalloc依然有一个全局共享内存堆PageHeap,如图20所示。
图 20 TCMalloc中的PageHeap
PageHeap也是一次系统调用从虚拟内存中申请的,PageHeap很明显是全局的,所以访问一定是要加锁。其作用是当CentralCache没有足够内存时会从PageHeap取,当CentralCache内存过多或者充足,则将低命中内存块退还PageHeap。如果Thread需要大对象申请超过的Cache容纳的内存块单元大小,也会直接从PageHeap获取。 在链接TCMalloc的一些内部设计结构时,首要了解的是一些TCMalloc定义的基本名词Page、Span和Size Class。
1.Page
TCMalloc中的Page与之前章节介绍操作系统对虚拟内存管理的MMU定义的物理页有相似的定义,TCMalloc将虚拟内存空间划分为多份同等大小的Page,每个Page默认是8KB。 对于TCMalloc来说,虚拟内存空间的全部内存都按照Page的容量分成均等份,并且给每份Page标记了ID编号,如图21所示。图 21 TCMalloc将虚拟内存平均分层N份Page
将Page进行编号的好处是,可以根据任意内存的地址指针,进行固定算法偏移计算来算出所在的Page。2.Span
多个连续的Page称之为是一个Span,其定义含义有操作系统的管理的页表相似,Page和Span的关系如图22所示。图 22 TCMalloc中Page与Span的关系
TCMalloc是以Span为单位向操作系统申请内存的。每个Span记录了第一个起始Page的编号Start,和一共有多少个连续Page的数量Length。 为了方便Span和Span之间的管理,Span集合是以双向链表的形式构建,如图23所示。图 23 TCMalloc中Span存储形式
3.Size Class
参考表3-3所示,在256KB以内的小对象,TCMalloc会将这些小对象集合划分成多个内存刻度[6],同属于一个刻度类别下的内存集合称之为属于一个Size Class。这与之前章节自定义实现的内存池,将Buf划分多个刻度的BufList类似。[6] TCMalloc官方文档称一共划分88个size-classes,“Each small object size maps to one of approximately 88 allocatable size-classes”,参考《TCMalloc : Thread-Caching Malloc》
每个Size Class都对应一个大小比如8字节、16字节、32字节等。在申请小对象内存的时候,TCMalloc会根据使用方申请的空间大小就近向上取最接近的一个Size Class的Span(由多个等空间的Page组成)内存块返回给使用方。 如果将Size Class、Span、Page用一张图来表示,则具体的抽象关系如图24所示。图 24 TCMalloc中Size Class、Page、Span的结构关系
接下来剖析一下ThreadCache、CentralCache、PageHeap的内存管理结构。5.3 ThreadCache
在TCMalloc中每个线程都会有一份单独的缓存,就是ThreadCache。ThreadCache中对于每个Size Class都会有一个对应的FreeList,FreeList表示当前缓存中海油多少个空闲的内存可用,具体的结构布局如图25所示。图 25 TCMalloc中ThreadCache
使用方对于从TCMalloc申请的小对象,会直接从TreadCache获取,实则是从FreeList中返回一个空闲的对象,如果对应的Size Class刻度下已经没有空闲的Span可以被获取了,则ThreadCache会从CentralCache中获取。当使用方使用完内存之后,归还也是直接归还给当前的ThreadCache中对应刻度下的的FreeList中。 整条申请和归还的流程是不需要加锁的,因为ThreadCache为当前线程独享,但如果ThreadCache不够用,需要从CentralCache申请内存时,这个动作是需要加锁的。不同Thread之间的ThreadCache是以双向链表的结构进行关联,是为了方便TCMalloc统计和管理。5.4 CentralCache
CentralCache是各个线程共用的,所以与CentralCache获取内存交互是需要加锁的。CentralCache缓存的Size Class和ThreadCache的一样,这些缓存都被放在CentralFreeList中,当ThreadCache中的某个Size Class刻度下的缓存小对象不够用,就会向CentralCache对应的Size Class刻度的CentralFreeList获取,同样的如果ThreadCache有多余的缓存对象也会退还给响应的CentralFreeList,流程和关系如图26所示。图 26 TCMalloc中CentralCache
CentralCache与PageHeap的角色关系与ThreadCache与CentralCache的角色关系相似,当CentralCache出现Span不足时,会从PageHeap申请Span,以及将不再使用的Span退还给PageHeap。5.5 PageHeap
PageHeap是提供CentralCache的内存来源。PageHead与CentralCache不同的是CentralCache是与ThreadCache布局一模一样的缓存,主要是起到针对ThreadCache的一层二级缓存作用,且只支持小对象内存分配。而PageHeap则是针对CentralCache的三级缓存。弥补对于中对象内存和大对象内存的分配,PageHeap也是直接和操作系统虚拟内存衔接的一层缓存,当找不到ThreadCache、CentralCache、PageHeap都找不到合适的Span,PageHeap则会调用操作系统内存申请系统调用函数来从虚拟内存的堆区中取出内存填充到PageHeap当中,具体的结构如图27所示。图 27 TCMalloc中PageHeap
PageHeap内部的Span管理,采用两种不同的方式,对于128个Page以内的Span申请,每个Page刻度都会用一个链表形式的缓存来存储。对于128个Page以上内存申请,PageHeap是以有序集合(C++标准库STL中的Std::Set容器)来存放。5.6 TCMalloc的小对象分配
上述已经将TCMalloc的几种基础结构介绍了,接下来总结一下TCMalloc针对小对象、中对象和大对象的分配流程。小对象分配流程如图28所示。图 28 TCMalloc小对象分配流程
小对象为占用内存小于等于256KB的内存,参考图中的流程,下面将介绍详细流程步骤: (1)Thread用户线程应用逻辑申请内存,当前Thread访问对应的ThreadCache获取内存,此过程不需要加锁。 (2)ThreadCache的得到申请内存的SizeClass(一般向上取整,大于等于申请的内存大小),通过SizeClass索引去请求自身对应的FreeList。 (4)如果FreeList非空,则表示目前有对应内存空间供Thread使用,得到FreeList第一个空闲Span返回给Thread用户逻辑,流程结束。 (5)如果FreeList为空,则表示目前没有对应SizeClass的空闲Span可使用,请求CentralCache并告知CentralCache具体的SizeClass。 (6)CentralCache收到请求后,加锁访问CentralFreeList,根据SizeClass进行索引找到对应的CentralFreeList。 (7)判断得到的CentralFreeList是否为非空。 (8)如果CentralFreeList非空,则表示目前有空闲的Span可使用。返回多个Span,将这些Span(除了第一个Span)放置ThreadCache的FreeList中,并且将第一个Span返回给Thread用户逻辑,流程结束。 (9)如果CentralFreeList为空,则表示目前没有可用是Span可使用,向PageHeap申请对应大小的Span。 (10)PageHeap得到CentralCache的申请,加锁请求对应的Page刻度的Span链表。 (11)PageHeap将得到的Span根据本次流程请求的SizeClass大小为刻度进行拆分,分成N份SizeClass大小的Span返回给CentralCache,如果有多余的Span则放回PageHeap对应Page的Span链表中。 (12)CentralCache得到对应的N个Span,添加至CentralFreeList中,跳转至第(8)步。 综上是TCMalloc一次申请小对象的全部详细流程,接下来分析中对象的分配流程。5.7 TCMalloc的中对象分配
中对象为大于256KB且小于等于1MB的内存。对于中对象申请分配的流程TCMalloc与处理小对象分配有一定的区别。对于中对象分配,Thread不再按照小对象的流程路径向ThreadCache获取,而是直接从PageHeap获取,具体的流程如图29所示。图 29 TCMalloc中对象分配流程
PageHeap将128个Page以内大小的Span定义为小Span,将128个Page以上大小的Span定义为大Span。由于一个Page为8KB,那么128个Page即为1MB,所以对于中对象的申请,PageHeap均是按照小Span的申请流程,具体如下: (1)Thread用户逻辑层提交内存申请处理,如果本次申请内存超过256KB但不超过1MB则属于中对象申请。TCMalloc将直接向PageHeap发起申请Span请求。 (2)PageHeap接收到申请后需要判断本次申请是否属于小Span(128个Page以内),如果是,则走小Span,即中对象申请流程,如果不是,则进入大对象申请流程,下一节介绍。 (3)PageHeap根据申请的Span在小Span的链表中向上取整,得到最适应的第K个Page刻度的Span链表。 (4)得到第K个Page链表刻度后,将K作为起始点,向下遍历找到第一个非空链表,直至128个Page刻度位置,找到则停止,将停止处的非空Span链表作为提供此次返回的内存Span,将链表中的第一个Span取出。如果找不到非空链表,则当错本次申请为大Span申请,则进入大对象申请流程。 (5)假设本次获取到的Span由N个Page组成。PageHeap将N个Page的Span拆分成两个Span,其中一个为K个Page组成的Span,作为本次内存申请的返回,给到Thread,另一个为N-K个Page组成的Span,重新插入到N-K个Page对应的Span链表中。5.8 TCMalloc的大对象分配
对于超过128个Page(即1MB)的内存分配则为大对象分配流程。大对象分配与中对象分配情况类似,Thread绕过ThreadCache和CentralCache,直接向PageHeap获取。详细的分配流程如图30所示。图 30 TCMalloc大对象分配流程
进入大对象分配流程除了申请的Span大于128个Page之外,对于中对象分配如果找不到非空链表也会进入大对象分配流程,大对象分配的具体流程如下: (1)Thread用户逻辑层提交内存申请处理,如果本次申请内存超过1MB则属于大对象申请。TCMalloc将直接向PageHeap发起申请Span 。(2)PageHeap接收到申请后需要判断本次申请是否属于小Span(128个Page以内),如果是,则走小Span中对象申请流程(上一节已介绍),如果不是,则进入大对象申请流程。(3)PageHeap根据Span的大小按照Page单元进行除法运算,向上取整,得到最接近Span的且大于Span的Page倍数K,此时的K应该是大于128。如果是从中对象流程分过来的(中对象申请流程可能没有非空链表提供Span),则K值应该小于128。(4)搜索Large Span Set集合,找到不小于K个Page的最小Span(N个Page)。如果没有找到合适的Span,则说明PageHeap已经无法满足需求,则向操作系统虚拟内存的堆空间申请一堆内存,将申请到的内存安置在PageHeap的内存结构中,重新执行(3)步骤。(5)将从Large Span Set集合得到的N个Page组成的Span拆分成两个Span,K个Page的Span直接返回给Thread用户逻辑,N-K个Span退还给PageHeap。其中如果N-K大于128则退还到Large Span Set集合中,如果N-K小于128,则退还到Page链表中。 本章节将介绍Golang的内存管理模型,看本章节之前强烈建议读者将上述章节均阅读理解完成,更有助于理解Golang的内存管理机制。
Golang内存管理模型的逻辑层次全景图,如图31所示。
图 31 Golang内存管理模块关系
Golang内存管理模型与TCMalloc的设计极其相似。基本轮廓和概念也几乎相同,只是一些规则和流程存在差异,接下来分析一下Golang内存管理模型的基本层级模块组成概念。 Golang内存管理中依然保留TCMalloc中的Page、Span、Size Class等概念。
1.Page
与TCMalloc的Page一致。Golang内存管理模型延续了TCMalloc的概念,一个Page的大小依然是8KB。Page表示Golang内存管理与虚拟内存交互内存的最小单元。操作系统虚拟内存对于Golang来说,依然是划分成等分的N个Page组成的一块大内存公共池,如图3.21所示。2.mSpan
与TCMalloc中的Span一致。mSpan概念依然延续TCMalloc中的Span概念,在Golang中将Span的名称改为mSpan,依然表示一组连续的Page。3.Size Class相关
Golang内存管理针对Size Class对衡量内存的的概念又更加详细了很多,这里面介绍一些基础的有关内存大小的名词及算法。(1)Object Size,是只协程应用逻辑一次向Golang内存申请的对象Object大小。Object是Golang内存管理模块针对内存管理更加细化的内存管理单元。一个Span在初始化时会被分成多个Object。比如Object Size是8B(8字节)大小的Object,所属的Span大小是8KB(8192字节),那么这个Span就会被平均分割成1024(8192/8=1024)个Object。逻辑层向Golang内存模型取内存,实则是分配一个Object出去。为了更好的让读者理解,这里假设了几个数据来标识Object Size 和Span的关系,如图32所示。图 32 Object Size与Span的关系
上图中的Num Of Object表示当前Span中一共存在多少个Object。 注意 Page是Golang内存管理与操作系统交互衡量内存容量的基本单元,Golang内存管理内部本身用来给对象存储内存的基本单元是Object。(2)Size Class,Golang内存管理中的Size Class与TCMalloc所表示的设计含义是一致的,都表示一块内存的所属规格或者刻度。Golang内存管理中的Size Class是针对Object Size来划分内存的。也是划分Object大小的级别。比如Object Size在1Byte~8Byte之间的Object属于Size Class 1级别,Object Size 在8B~16Byte之间的属于Size Class 2级别。(3)Span Class,这个是Golang内存管理额外定义的规格属性,是针对Span来进行划分的,是Span大小的级别。一个Size Class会对应两个Span Class,其中一个Span为存放需要GC扫描的对象(包含指针的对象),另一个Span为存放不需要GC扫描的对象(不包含指针的对象),具体Span Class与Size Class的逻辑结构关系如图33所示。图 33 Span Class与Size Class的逻辑结构关系
其中Size Class和Span Class的对应关系计算方式可以参考Golang源代码,如下://usr/local/go/src/runtime/mheap.go
type spanClass uint8
//……(省略部分代码)
func makeSpanClass(sizeclass uint8, noscan bool) spanClass {return spanClass(sizeclass<<1) | spanClass(bool2int(noscan))}
//……(省略部分代码)
这里makeSpanClass()函数为通过Size Class来得到对应的Span Class,其中第二个形参noscan表示当前对象是否需要GC扫描,不难看出来Span Class 和Size Class的对应关系公式如表5所示。表5 TCMalloc的内存分离| 对象 | Size Class 与 Span Class对应公式 |
| 需要GC扫描 | Span Class = Size Class * 2 + 0 |
| 不需要GC扫描 | Span Class = Size Class * 2 + 1 |
如果再具体一些,则通过Golang的源码可以看到,Golang给内存池中固定划分了66[7]个Size Class,这里面列举了详细的Size Class和Object大小、存放Object数量,以及每个Size Class对应的Span内存大小关系,代码如下://usr/local/go/src/runtime/sizeclasses.go
package runtime
// 标题Title解释:// [class]: Size Class// [bytes/obj]: Object Size,一次对外提供内存Object的大小// [bytes/span]: 当前Object所对应Span的内存大小// [objects]: 当前Span一共有多少个Object// [tail wastre]: 为当前Span平均分层N份Object,会有多少内存浪费// [max waste]: 当前Size Class最大可能浪费的空间所占百分比
// class bytes/obj bytes/span objects tail waste max waste// 1 8 8192 1024 0 87.50%// 2 16 8192 512 0 43.75%// 3 32 8192 256 0 46.88%// 4 48 8192 170 32 31.52%// 5 64 8192 128 0 23.44%// 6 80 8192 102 32 19.07%// 7 96 8192 85 32 15.95%// 8 112 8192 73 16 13.56%// 9 128 8192 64 0 11.72%// 10 144 8192 56 128 11.82%// 11 160 8192 51 32 9.73%// 12 176 8192 46 96 9.59%// 13 192 8192 42 128 9.25%// 14 208 8192 39 80 8.12%// 15 224 8192 36 128 8.15%// 16 240 8192 34 32 6.62%// 17 256 8192 32 0 5.86%// 18 288 8192 28 128 12.16%// 19 320 8192 25 192 11.80%// 20 352 8192 23 96 9.88%// 21 384 8192 21 128 9.51%// 22 416 8192 19 288 10.71%// 23 448 8192 18 128 8.37%// 24 480 8192 17 32 6.82%// 25 512 8192 16 0 6.05%// 26 576 8192 14 128 12.33%// 27 640 8192 12 512 15.48%// 28 704 8192 11 448 13.93%// 29 768 8192 10 512 13.94%// 30 896 8192 9 128 15.52%// 31 1024 8192 8 0 12.40%// 32 1152 8192 7 128 12.41%// 33 1280 8192 6 512 15.55%// 34 1408 16384 11 896 14.00%// 35 1536 8192 5 512 14.00%// 36 1792 16384 9 256 15.57%// 37 2048 8192 4 0 12.45%// 38 2304 16384 7 256 12.46%// 39 2688 8192 3 128 15.59%// 40 3072 24576 8 0 12.47%// 41 3200 16384 5 384 6.22%// 42 3456 24576 7 384 8.83%// 43 4096 8192 2 0 15.60%// 44 4864 24576 5 256 16.65%// 45 5376 16384 3 256 10.92%// 46 6144 24576 4 0 12.48%// 47 6528 32768 5 128 6.23%// 48 6784 40960 6 256 4.36%// 49 6912 49152 7 768 3.37%// 50 8192 8192 1 0 15.61%// 51 9472 57344 6 512 14.28%// 52 9728 49152 5 512 3.64%// 53 10240 40960 4 0 4.99%// 54 10880 32768 3 128 6.24%// 55 12288 24576 2 0 11.45%// 56 13568 40960 3 256 9.99%// 57 14336 57344 4 0 5.35%// 58 16384 16384 1 0 12.49%// 59 18432 73728 4 0 11.11%// 60 19072 57344 3 128 3.57%// 61 20480 40960 2 0 6.87%// 62 21760 65536 3 256 6.25%// 63 24576 24576 1 0 11.45%// 64 27264 81920 3 128 10.00%// 65 28672 57344 2 0 4.91%// 66 32768 32768 1 0 12.50%
下面分别解释一下每一列的含义:
(1)Class列为Size Class规格级别。(2)bytes/obj列为Object Size,即一次对外提供内存Object的大小(单位为Byte),可能有一定的浪费,比如业务逻辑层需要2B的数据,实则会定位到Size Class为1,返回一个Object即8B的内存空间。(3)bytes/span列为当前Object所对应Span的内存大小(单位为Byte)。(4)objects列为当前Span一共有多少个Object,该字段是通过bytes/span和bytes/obj相除计算而来。(5)tail waste列为当前Span平均分层N份Object,会有多少内存浪费,这个值是通过bytes/span对bytes/obj求余得出,即span%obj。(6)max waste列当前Size Class最大可能浪费的空间所占百分比。这里面最大的情况就是一个Object保存的实际数据刚好是上一级Size Class的Object大小加上1B。当前Size Class的Object所保存的真实数据对象都是这一种情况,这些全部空间的浪费再加上最后的tail waste就是max waste最大浪费的内存百分比,具体如图34所示。[7] 参考Golang 1.14版本,其中还有扩展到128个size class的对应关系,本书不详细介绍,具体细节参考Golang源码/usr/local/go/src/runtime/sizeclasses.go文件。
图 34 Max Waste最大浪费空间计算公式
图中以Size Class 为7的Span为例,通过源代码 runtime/sizeclasses.go的详细Size Class数据可以得知具体Span细节如下:// class bytes/obj bytes/span objects tail waste max waste
// … …// 6 80 8192 102 32 19.07%// 7 96 8192 85 32 15.95%// … …
从图3.34可以看出,Size Class为7的Span如果每个Object均超过Size Class为7中的Object一个字节。那么就会导致Size Class为7的Span出现最大空间浪费情况。综上可以得出计算最大浪费空间比例的算法公式如下:(本级Object Size – (上级Object Size + 1)*本级Object数量) / 本级Span Size
从概念来讲MCache与TCMalloc的ThreadCache十分相似,访问mcache依然不需要加锁而是直接访问,且MCache中依然保存各种大小的Span。虽然MCache与ThreadCache概念相似,二者还是存在一定的区别的,MCache是与Golang协程调度模型GPM中的P所绑定,而不是和线程绑定。因为Golang调度的GPM模型,真正可运行的线程M的数量与P的数量一致,即GOMAXPROCS个,所以MCache与P进行绑定更能节省内存空间使用,可以保证每个G使用MCache时不需要加锁就可以获取到内存。而TCMalloc中的ThreadCache虽则Thread的增多,ThreadCache的数量也就相对成正比增多,二者绑定关系的区别如图35所示。图 35 ThreadCache与mcache的绑定关系区别
如果将图35的mcache展开,来看mcache的内部构造,则具体的结构形式如图36所示。图 36 MCache内部构造
协程逻辑层从mcache上获取内存是不需要加锁的,因为一个P只有一个M在其上运行,不可能出现竞争,由于没有锁限制,mcache则其到了加速内存分配。 MCache中每个Span Class都会对应一个MSpan,不同Span Class的MSpan的总体长度不同,参考runtime/sizeclasses.go的标准规定划分。比如对于Span Class为4的MSpan来说,存放内存大小为1Page,即8KB。每个对外提供的Object大小为16B,共存放512个Object。其他Span Class的存放方式类似。当其中某个Span Class的MSpan已经没有可提供的Object时,MCache则会向MCentral申请一个对应的MSpan。 在图3.36中应该会发现,对于Span Class为0和1的,也就是对应Size Class为0的规格刻度内存,mcache实际上是没有分配任何内存的。因为Golang内存管理对内存为0的数据申请做了特殊处理,如果申请的数据大小为0将直接返回一个固定内存地址,不会走Golang内存管理的正常逻辑,相关Golang源代码如下://usr/local/go/src/runtime/malloc.go
// Al Allocate an object of size bytes. // Sm Small objects are allocated from the per-P cache's free lists. // La Large objects (> 32 kB) are allocated straight from the heap. func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer { // ……(省略部分代码)
if size == 0 {return unsafe.Pointer(&zerobase)}
//……(省略部分代码)}
上述代码可以看见,如果申请的size为0,则直接return一个固定地址zerobase。下面来测试一下有关0空间申请的情况,在Golang中如[0]int、 struct{}所需要大小均是0,这也是为什么很多开发者在通过Channel做同步时,发送一个struct{}数据,因为不会申请任何内存,能够适当节省一部分内存空间,测试代码如下://第一篇/chapter3/MyGolang/zeroBase.gopackage main
import ( "fmt")
func main() { var ( //0内存对象 a struct{} b [0]int
//100个0内存struct{} c [100]struct{}
//100个0内存struct{},make申请形式 d = make([]struct{}, 100) )
fmt.Printf("%p\n", &a) fmt.Printf("%p\n", &b) fmt.Printf("%p\n", &c[50]) //取任意元素 fmt.Printf("%p\n", &(d[50])) //取任意元素}
$ go run zeroBase.go 0x11aac780x11aac780x11aac780x11aac78
从结果可以看出,全部的0内存对象分配,返回的都是一个固定的地址。 MCentral与TCMalloc中的Central概念依然相似。向MCentral申请Span是同样是需要加锁的。当MCache中某个Size Class对应的Span被一次次Object被上层取走后,如果出现当前Size Class的Span空缺情况,MCache则会向MCentral申请对应的Span。Goroutine、MCache、MCentral、MHeap互相交换的内存单位是不同,具体如图37所示。
图 37 Golang内存管理各层级内存交换单位
其中协程逻辑层与MCache的内存交换单位是Object,MCache与MCentral的内存交换单位是Span,而MCentral与MHeap的内存交换单位是Page。 MCentral与TCMalloc中的Central不同的是MCentral针对每个Span Class级别有两个Span链表,而TCMalloc中的Central只有一个。MCentral的内部构造如图38所示。图 38 MCentral的内部构造
MCentral与MCCache不同的是,每个级别保存的不是一个Span,而是一个Span List链表。与TCMalloc中的Central不同的是,MCentral每个级别都保存了两个Span List。注意 图38中MCentral是表示一层抽象的概念,实际上每个Span Class对应的内存数据结构是一个mcentral,即在MCentral这层数据管理中,实际上有Span Class个mcentral小内存管理单元。 表示还有可用空间的Span链表。链表中的所有Span都至少有1个空闲的Object空间。如果MCentral上游MCache退还Span,会将退还的Span加入到NonEmpty Span List链表中。 表示没有可用空间的Span链表。该链表上的Span都不确定否还有有空闲的Object空间。如果MCentral提供给一个Span给到上游MCache,那么被提供的Span就会加入到Empty List链表中。注意 在Golang 1.16版本之后,MCentral中的NonEmpty Span List 和 Empty Span List均由链表管理改成集合管理,分别对应Partial Span Set 和 Full Span Set。虽然存储的数据结构有变化,但是基本的作用和职责没有区别。 下面是MCentral层级中其中一个Size Class级别的MCentral的定义Golang源代码(V1.14版本)://usr/local/go/src/runtime/mcentral.go , Go V1.14
// Central list of free objects of a given size.// go:notinheaptype mcentral struct { lock mutex //申请MCentral内存分配时需要加的锁
spanclass spanClass //当前哪个Size Class级别的
// list of spans with a free object, ie a nonempty free list // 还有可用空间的Span 链表 nonempty mSpanList
// list of spans with no free objects (or cached in an mcache) // 没有可用空间的Span链表,或者当前链表里的Span已经交给mcache empty mSpanList
// nmalloc is the cumulative count of objects allocated from // this mcentral, assuming all spans in mcaches are // fully-allocated. Written atomically, read under STW. // nmalloc是从该mcentral分配的对象的累积计数 // 假设mcaches中的所有跨度都已完全分配。 // 以原子方式书写,在STW下阅读。 nmalloc uint64}
在GolangV1.16及之后版本(截止本书编写最新时间)的相关MCentral结构代码如下://usr/local/go/src/runtime/mcentral.go , Go V1.16+
//…
type mcentral struct { // mcentral对应的spanClass spanclass spanClass
partial [2]spanSet // 维护全部空闲的Span集合 full [2]spanSet // 维护存在非空闲的Span集合}
//…
新版本的改进是将List变成了两个Set集合,Partial集合与NonEmpty Span List责任类似,Full集合与Empty Span List责任类似。可以看见Partial和Full都是一个[2]spanSet类型,也就每个Partial和Full都各有两个spanSet集合,这是为了给GC垃圾回收来使用的,其中一个集合是已扫描的,另一个集合是未扫描的。 Golang内存管理的MHeap依然是继承TCMalloc的PageHeap设计。MHeap的上游是MCentral,MCentral中的Span不够时会向MHeap申请。MHeap的下游是操作系统,MHeap的内存不够时会向操作系统的虚拟内存空间申请。访问MHeap获取内存依然是需要加锁的。 MHeap是对内存块的管理对象,是通过Page为内存单元进行管理。那么用来详细管理每一系列Page的结构称之为一个HeapArena,它们的逻辑层级关系如图39所示。图 39 MHeap内部逻辑层级构造
一个HeapArena占用内存64MB[8],其中里面的内存的是一个一个的mspan,当然最小单元依然是Page,图中没有表示出mspan,因为多个连续的page就是一个mspan。所有的HeapArena组成的集合是一个Arenas,也就是MHeap针对堆内存的管理。MHeap是Golang进程全局唯一的所以访问依然加锁。图中又出现了MCentral,因为MCentral本也属于MHeap中的一部分。只不过会优先从MCentral获取内存,如果没有MCentral会从Arenas中的某个HeapArena获取Page。 如果再详细剖析MHeap里面相关的数据结构和指针依赖关系,可以参考图40,这里不做过多解释,如果更像详细理解MHeap建议研读源代码/usr/local/go/src/runtime/mheap.go文件。图 40 MHeap数据结构引用依赖
MHeap中HeapArena占用了绝大部分的空间,其中每个HeapArean包含一个bitmap,其作用是用于标记当前这个HeapArena的内存使用情况。其主要是服务于GC垃圾回收模块,bitmap共有两种标记,一个是标记对应地址中是否存在对象,一个是标记此对象是否被GC模块标记过,所以当前HeapArena中的所有Page均会被bitmap所标记。 ArenaHint为寻址HeapArena的结构,其有三个成员: (1)addr,为指向的对应HeapArena首地址。 (2)down,为当前的HeapArena是否可以扩容。 (3)next,指向下一个HeapArena所对应的ArenaHint首地址。从图3.40中可以看出,MCentral实际上就是隶属于MHeap的一部分,从数据结构来看,每个Span Class对应一个MCentral,而之前在分析Golang内存管理中的逻辑分层中,是将这些MCentral集合统一归类为MCentral层。 在之前章节的表3-4中可以得到TCMalloc将对象分为了小对象、中对象、和大对象,而Golang内存管理将对象的分类进行了更细的一些划分,具体的划分区别对比如表6所示。
表6 Golang内存与TCMalloc内存的分类对比| TCMalloc | Golang |
| 小对象 | Tiny对象 |
| 中对象 | 小对象 |
| 大对象 | 大对象 |
针对Tiny微小对象的分配,实际上Golang做了比较特殊的处理,之前在介绍MCache的时候并没有提及有关Tiny的存储和分配问题,MCache中不仅保存着各个Span Class级别的内存块空间,还有一个比较特殊的Tiny存储空间,如图41所示。
图 41 MCache中的Tiny空间
Tiny空间是从Size Class = 2(对应Span Class = 4 或5)中获取一个16B的Object,作为Tiny对象的分配空间。对于Golang内存管理为什么需要一个Tiny这样的16B空间,原因是因为如果协程逻辑层申请的内存空间小于等于8B,那么根据正常的Size Class匹配会匹配到Size Class = 1(对应Span Class = 2或3),所以像 int32、 byte、 bool 以及小字符串等经常使用的Tiny微小对象,也都会使用从Size Class = 1申请的这8B的空间。但是类似bool或者1个字节的byte,也都会各自独享这8B的空间,进而导致有一定的内存空间浪费,如图42所示。图 42 如果微小对象不存在Tiny空间中
可以看出来这样当大量的使用微小对象可能会对Size Class = 1的Span造成大量的浪费。所以Golang内存管理决定尽量不使用Size Class = 1的Span,而是将申请的Object小于16B的申请统一归类为Tiny对象申请。具体的申请流程如图43所示。图 43 MCache中Tiny微小对象分配流程
MCache中对于Tiny微小对象的申请流程如下: (1)P向MCache申请微小对象如一个Bool变量。如果申请的Object在Tiny对象的大小范围则进入Tiny对象申请流程,否则进入小对象或大对象申请流程。 (2)判断申请的Tiny对象是否包含指针,如果包含则进入小对象申请流程(不会放在Tiny缓冲区,因为需要GC走扫描等流程)。 (3)如果Tiny空间的16B没有多余的存储容量,则从Size Class = 2(即Span Class = 4或5)的Span中获取一个16B的Object放置Tiny缓冲区。(4)将1B的Bool类型放置在16B的Tiny空间中,已字节对齐的方式。 Tiny对象的申请也是达不到内存利用率100%的,就上述图43为例,当前Tiny缓冲16B的内存利用率为,而如果不用Tiny微小对象的方式来存储,那么内存的布局将如图44所示。图 44 不用Tiny缓冲存储情况
可以算出利用率为。Golang内存管理通过Tiny对象的处理,可以平均节省20%左右的内存。 上节已经介绍了分配在1B至16B的Tiny对象的分配流程,那么对于对象在16B至32B的内存分配,Golang会采用小对象的分配流程。
分配小对象的标准流程是按照Span Class规格匹配的。在之前介绍MCache的内部构造已经介绍了,MCache一共有67份Size Class其中Size Class 为0的做了特殊的处理直接返回一个固定的地址。Span Class为Size Class的二倍,也就是从0至133共134个Span Class。当协程逻辑层P主动申请一个小对象的时候,Golang内存管理的内存申请流程如图45所示。图 45 Golang小对象内存分配流程
(1)首先协程逻辑层P向Golang内存管理申请一个对象所需的内存空间。(2)MCache在接收到请求后,会根据对象所需的内存空间计算出具体的大小Size。(3)判断Size是否小于16B,如果小于16B则进入Tiny微对象申请流程,否则进入小对象申请流程。(4)根据Size匹配对应的Size Class内存规格,再根据Size Class和该对象是否包含指针,来定位是从noscan Span Class 还是 scan Span Class获取空间,没有指针则锁定noscan。(5)在定位的Span Class中的Span取出一个Object返回给协程逻辑层P,P得到内存空间,流程结束。(6)如果定位的Span Class中的Span所有的内存块Object都被占用,则MCache会向MCentral申请一个Span。(7)MCentral收到内存申请后,优先从相对应的Span Class中的NonEmpty Span List(或Partial Set,Golang V1.16+)里取出Span(多个Object组成),NonEmpty Span List没有则从Empty List(或 Full Set Golang V1.16+)中取,返回给MCache。(8)MCache得到MCentral返回的Span,补充到对应的Span Class中,之后再次执行第(5)步流程。(9)如果Empty Span List(或Full Set)中没有符合条件的Span,则MCentral会向MHeap申请内存。(10)MHeap收到内存请求从其中一个HeapArena从取出一部分Pages返回给MCentral,当MHeap没有足够的内存时,MHeap会向操作系统申请内存,将申请的内存也保存到HeapArena中的mspan中。MCentral将从MHeap获取的由Pages组成的Span添加到对应的Span Class链表或集合中,作为新的补充,之后再次执行第(7)步。(11)最后协程业务逻辑层得到该对象申请到的内存,流程结束。 小对象是在MCache中分配的,而大对象是直接从MHeap中分配。对于不满足MCache分配范围的对象,均是按照大对象分配流程处理。
大对象分配流程是协程逻辑层直接向MHeap申请对象所需要的适当Pages,从而绕过从MCaceh到MCentral的繁琐申请内存流程,大对象的内存分配流程相对比较简单,具体的流程如图46所示。图 46 Golang大对象内存分配流程
(1)协程逻辑层申请大对象所需的内存空间,如果超过32KB,则直接绕过MCache和MCentral直接向MHeap申请。(2)MHeap根据对象所需的空间计算得到需要多少个Page。(3)MHeap向Arenas中的HeapArena申请相对应的Pages。(4)如果Arenas中没有HeapA可提供合适的Pages内存,则向操作系统的虚拟内存申请,且填充至Arenas中。 本章从操作系统的虚拟内存申请到Golang内存模型进行的理论的推进和逐层剖析。通过本章的内存,可以了解到无论是操作系统虚拟内存管理,还是C++的TCMalloc、Golang内存模型,均有一个共同特点,就是分层的缓存机制。针对不同的内存场景采用不同的独特解决方式,提高局部性逻辑和细微粒度内存的复用率。这也是程序设计的至高理念。
推荐阅读
我为大家整理了一份从入门到进阶的Go学习资料礼包,包含学习建议:入门看什么,进阶看什么。关注公众号 「polarisxu」,回复 ebook 获取;还可以回复「进群」,和数万 Gopher 交流学习。![]()