用了这么久的docker,对docker的实现原理挺感兴趣的,在对Linux下docker的实现原理了解之后,我没有用过Windows下的docker,更加好奇Windows下的docker是如何实现的(它并不开源),问了问owefsad师傅,说是可能用到了hyperV,那么可能类似Vmware吗?不知道啊。
另外说一下,其实这篇文章大部分都是cv的,算是一个知识整合加上个人的理解,我每看的一篇文章,都放在了最后的,所以也可以看到个公众号的作者是《互联网所有大佬们》
1、什么是Linux NameSpace
Linux Namespace是Linux提供的一种内核级别环境隔离的方法。从Unix开始,有一个chroot命令,
chroot
change root directory (更改 root 目录)。在 linux 系统中,系统默认的目录结构都是以 `/`,即是以根 (root) 开始的。而在使用 chroot 之后,系统的目录结构将以指定的位置作为 `/` 位置。
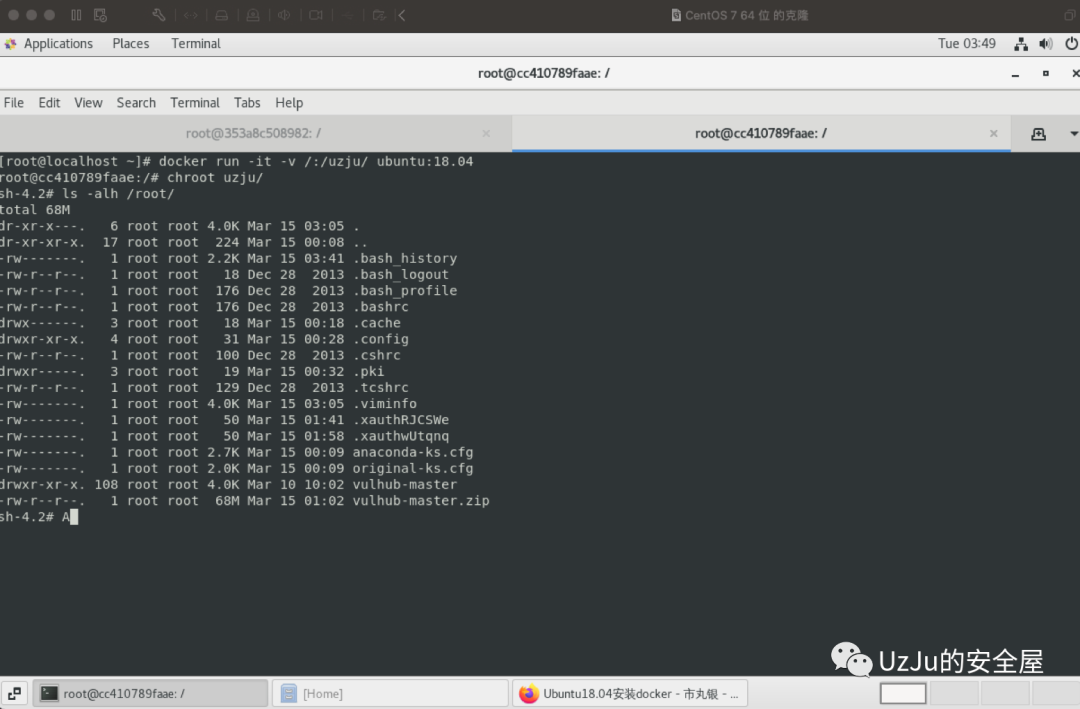
也就是说,原先我们的root目录在/,那么我们在tmp目录使用chroot后,那么我们的/目录就在tmp/下,在docker中有一种逃逸方式,在docker启动的时候,挂在宿主机的根目录,假设,启动时,把宿主机的根目录挂载在了docker中的/UzJu/目录
docker run -it -v /:/uzju/ ubuntu:18.04
那么此时,我们进入到docker中,使用chroot,将根目录切换至/UzJu/目录下
chroot /uzju/
此时我们就可以使用crontab等多种方式获取宿主机权限
那么chroot提供的就是一种简单的隔离环境,chroot内部的内容无法访问外部的,Linux NameSpace在这个基础上,又提供了对以下内容的隔离机制
UTS
IPC
mount
PID
network
User
Mount namespaces | CLONE_NEWNS | Linux内核2.4.19 |
UTS namespaces | CLONE_NEWUTS | Linux内核2.6.19 |
I | CLONE_NEWIPC | Linux内核2.6.19 |
PID namespaces | CLONE_NEWPID | Linux内核2.6.24 |
Network namespaces | CLONE_NEWNET | Linux内核2.6.24->2.6.29 |
User namespaces | CLONE_NEWUSER | Linux内核2.6.23 |
在Linux文档中我们可以看到,目前,Linux 实现了六种不同类型的命名空间。每个命名空间的目的是将特定的全局系统资源包装在一个抽象中,使命名空间内的进程看起来拥有自己的全局资源隔离实例。命名空间的总体目标之一是支持容器的实现,容器是一种用于轻量级虚拟化(以及其他目的)的工具,它为一组进程提供了它们是系统上唯一进程的错觉。
UTS NameSpaces
用来隔离两个系统标识符,nodename和domainname,由uname()调用返回,名称是使用sethostname()和setdomainname()系统调用设置的,在容器的上下文中,UTS NameSpace允许每个容器拥有自己的主机名和NIS域名。
ps: UTS这个名称源自传递给uname()系统调用的结构名称:struct utsname,该结构的名称又源于Unxi分时系统
HostName
1、什么是HostName主机名
无论在局域网还是INTERNET上,每台主机都有一个IP地址,是为了区分此台主机和彼台主机,也就是说IP地址就是主机的门牌号。但IP地址不方便记忆,所以又有了域名。域名只是在公网(INtERNET)中存在(以实验为目的的局域网域网实验性除外),每个域名都对应一个IP地址,但一个IP地址可有对应多个域名。域名类型 linuxsir.org 这样的;
主机名是用于什么的呢?在一个局域网中,每台机器都有一个主机名,用于主机与主机之间的便于区分,就可以为每台机器设置主机名,以便于以容易记忆的方法来相互访问。比如我们在局域网中可以为根据每台机器的功用来为其命名。
2、HostName和Domain的区别
主机名就机器本身的名字,域名是用来解析到IP的。但值得一说的是在局域网中,主机名也是可以解析到IP上的;
NIX(Network Information System)
NIS 是一个基于远程过程调用 (RPC) 的客户端/服务器系统,它允许 NIS 域中的一组机器共享一组通用的配置文件。这允许系统管理员仅使用最少的配置数据设置 NIS 客户端系统,并从单个位置添加、删除或修改配置数据。
https://docs.freebsd.org/en/books/handbook/network-servers/#network-nis
GoLang的实现
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
// fork出新的进程。并执行sh命令
cmd := exec.Command("sh")
// 设置Cloneflags。clone新的UTS命名空间
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS, // 注释这一行前后,对比一下UTS的隔离情况
}
// 输入输出
cmd.Stdin = os.Stdin
cmd.Stderr = os.Stderr
cmd.Stdout = os.Stdout
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}
虽然程序内和程序外的HostName没有区别,都是uzju,但是我们可以通过查看/proc来进行判断
Tips:/proc
Linux内核提供了一种通过 proc 文件系统,在运行时访问内核内部数据结构、改变内核设置的机制。proc 文件系统是一个伪文件系统,它只存在内存当中,而不占用外存空间。它以文件系统的方式为访问系统内核数据的操作提供接口。
/proc下有三个重要的目录
net
scsi
sys
其中sys目录是可写的,可以通过他来访问或者修改内核参数,而net和scsi则依赖于内核配置,例如,如果系统不支持scsi,那么scsi目录就不会存在
ls -alh /proc
ls alh /proc/9811/
# 查看当前进程ID
echo $$
在宿主机中查看9815的父进程
px aux -H
那么他的父进程就是9811,子进程就是9815
可以看到两个进程之间的uts ID并不相同,实现了UTS NameSpaces的隔离
Tips: /proc/$PID/ns/uts目录,启示版本是Linux3.0,表示的是进程的UTS NameSpace
下面表格是其他的文件名已经含义
文件名称 | 起始版本 | 描述 |
/proc/[pid]/ns/cgroup | Linux 4.6 | 进程的 cgroup namespace |
/proc/[pid]/ns/ipc | Linux 3.0 | 进程的 IPC namespace |
/proc/[pid]/ns/mnt | Linux 3.8 | 进程的 mount namespace |
/proc/[pid]/ns/net | Linux 3.0 | 进程的 network namespace |
/proc/[pid]/ns/pid | Linux 3.8 | 进程的 PID namespace在进程的整个生命周期里是不变的 |
/proc/[pid]/ns/pid_for_children | Linux 4.12 | 进程创建子进程的 PID namespace这个文件与 /proc/[pid]/ns/pid 不一定一致。 |
/proc/[pid]/ns/time | Linux 5.6 | 进程的 time namespace |
/proc/[pid]/ns/time_for_children | Linux 5.6 | 进程创建子进程的 time namespace |
/proc/[pid]/ns/user | Linux 3.8 | 进程的 user namespace |
/proc/[pid]/ns/uts | Linux 3.0 | 进程的 UTS namespace |
IPC NameSpaces
用于隔离某些进程之间的通信,sysvipc对象和POSIX消息队列,这些IPC机制的共同特征是IPC对象由文件系统路径名以外的机制标识,每个IPC NameSpaces都有一组自己的 sys vipc标识符和自己的POSIX消息队列文件系统。
sysvipc
sysvipc是UNIX系统上官方使用的三种进程间的通信机制的名称,分别为:消息队列,信号量,共享内存。
https://man7.org/linux/man-pages/man7/svipc.7.html
POSIX
POSIX消息队列允许进程以如下形式交换数据消息,不同于sysvipc提供的API消息队列(msgget(2),msgsnd(2),msgrcv(2)等,但是也提供类似的功能
https://man7.org/linux/man-pages/man7/mq_overview.7.html
Tips:
1、msgget(2) 获取 Sys v 消息队列标识符
#include <sys/msg.h>
int msgget(key_t key , int msgflg );
https://man7.org/linux/man-pages/man2/msgget.2.html
2、msgsnd(2) 获取sys v 消息队列操作
#include <sys/msg.h>
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
https://man7.org/linux/man-pages/man2/msgsnd.2.html
3、msgrcv sys v消息队列操作
#include <sys/msg.h>
int msgsnd(int msqid , const void * msgp , size_t msgsz , int msgflg );
ssize_t msgrcv(int msqid , void * msgp , size_t msgsz , long msgtyp , int msgflg);
https://man7.org/linux/man-pages/man2/msgrcv.2.html
在Go代码实现之前,需要了解进程间的通信IPC(Inter-Process Communication)
这里的解释来自于企鹅大佬的公众号文章,我在这只是把一些精简的复制过来了,完整的可点击链接https://mp.weixin.qq.com/s/WgZaS5w5IXa3IBGRsPKtbQ
其中,最初 Unix IPC 包括:管道、FIFO、信号;
System V IPC 包括:System V 消息队列、System V 信号灯、System V 共享内存区;
Posix IPC 包括:Posix 消息队列、Posix 信号灯、Posix 共享内存区。
简单说明一下,现有大部分 Unix 和流行版本都是遵循 POSIX 标准的,而 Linux 从一开始就遵循 POSIX 标准。
进程间的七大通信方式
signal
信号(Signal)的本质
信号是进程间通信机制中唯一的异步通信机制,可以看作是异步通知,通知接收信号的进程有哪些发生事情了
信号(Signal)的来源
信号事件的发生有两个来源:
进程对信号(Signal)响应的三种方式
1、忽略信号,不作任何处理,不过其中有两个不能忽略的:SIGKILL和SIGSTOP
2、捕捉信号,定义信号处理函数,当信号发生时,执行相应的处理函数
3、执行缺省操作,Linux对每种信号都规定了默认操作
信号(Signal)发送的主要函数
kill()
raise()
siguqeue()
alarm()
setitimer()
abort()
信号(Signal)的处理
如果进程要处理某一信号,那么就要在进程中安装该信号。
安装信号主要用来确定信号值及进程针对该信号值的动作之间的映射关系,即进程将要处理哪个信号;该信号被传递给进程时,将执行何种操作。
file
在Linux中,每打开一个文件,就会产生一个文件控制块,而文件控制块与文件描述符是一一对应的,因此可以通过文件描述符的操作进而对文件进行操作。
文件描述符的分配原则:
使用的API:read()和write()
通过pause()等待对方发起一个信号,已确认可以开始执行下一次读写操作;pause() 只要接受到任何的信号,立马就可以往下执行
通过kill()方法向对方发出明确的信号:可以开始下一步执行(读,写)
缺点
文件通信没有访问规则
访问速度慢
pipe
管道(Pipe)及有名管道(named pipe)
(1)管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道;
(2)只能用于父子进程或者兄弟进程之间(具有亲缘关系的进程);
(3)单独构成一种独立的文件系统:管道对于管道两端的进程而言,就是一个文件,但它不是普通的文件,它不属于某种文件系统,而是自立门户,单独构成一种文件系统,并且只存在与内存中。
(4)数据的读出和写入:一个进程向管道中写的内容被管道另一端的进程读出。写入的内容每次都添加在管道缓冲区的末尾,并且每次都是从缓冲区的头部读出数据。
shm
共享内存(shm)概念
使得多个进程可以访问同一块内存空间,
进程对于共享内存的操作与管理主要是:
(1)申请创建一个共享内存区域(操作系统内核是不可能主动为进程创建共享内存),操作系统内核得到申请然后创建。
(2)申请使用一个已存在的共享内存区域。
(3)申请释放共享内存区域(操作系统内核也是不可能主动释放共享内存区域),操作系统内核得到申请然后释放。
共享内存允许两个或多个进程共享一给定的存储区,因为数据不需要来回复制,所以是最快的一种进程间通信机制。
sem
信号量(semaphore)的概念
主要作为进程间以及同一进程不同线程之间的同步手段。
存在的问题
进程在访问共享资源的时候存在冲突的问题,必须有一种强制手段说明这些共享资源的访问规则。
sem
表示的是一种共享资源的个数,对共享资源的访问规则。
访问规则
(1)用一种数量单位去标识某一种共享资源的个数。
(2)当有进程需要访问对应的共享资源的时候,则需要先查看申请,根据当前资源对应的可用数量进行申请。
(3)资源的管理者(也就是操作系统内核)就使用当前的资源个数减去要申请的资源的个数。如果结果 >=0 表示有可用资源,允许该进程的继续访问;否则表示资源不可用,通知进程(暂停或立即返回)。
(4)资源数量的变化就表示资源的占用和释放。占用:使得可用资源减少;释放:使得可用资源增加。
msg
消息队列(message)的概念
消息队列就是一个消息的链表。可以把消息看作一个记录,具有特定的格式以及特定的优先级。
对消息队列有写权限的进程可以向中按照一定的规则添加新消息;对消息队列有读权限的进程则可以从消息队列中读走消息。
socket
套接字(socket)
一个套接口可以看作是进程间通信的端点(endpoint),每个套接口的名字都是唯一的(唯一的含义是不言而喻的),其他进程可以发现、连接并且与之通信。
IPC常用命令
# 查看
ipcs
# 创建
ipcmk
# 删除
ipcrm
Go的实现
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
// fork出新的进程。并执行sh命令
cmd := exec.Command("sh")
// 设置Cloneflags。clone新的IPC命名空间
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWIPC,
}
// 输入输出
cmd.Stdin = os.Stdin
cmd.Stderr = os.Stderr
cmd.Stdout = os.Stdout
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}
在go build 后运行程序,查看ipcs
新建一个消息队列
会宿主机中无法看到创建的消息队列
PID NameSpaces
用于隔离进程ID号,换句话说,不同的PID NameSces中的进程可以有一模一样的PID,PID命名空间的主要好处之一就是容器可以在主机之间迁移,同时为容器内的进程保持相同的进程PID,PID NameSpaces 还允许每个容器又用自己的init(PID 1),也就是Linux中最大的父进程,管理各种系统初始化任务并在他们终止前kill掉其他的子进程。
当我们创建一个新的PID NameSpace的时候,第一个进程的PID会被赋值为1,进程退出时,内核就会kill NameSpace内的其他进程
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
// fork出新的进程。并执行sh命令
cmd := exec.Command("sh")
// 设置Cloneflags。clone新的PID命名空间
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWPID, // 注释这一行前后,对比一下PID的隔离情况
}
// 输入输出
cmd.Stdin = os.Stdin
cmd.Stderr = os.Stderr
cmd.Stdout = os.Stdout
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}
在go build 后我们输出当前进程的PID可以发现为1。
NetWork NameSpaces
提供与网络相关的系统资源隔离,因此每个NetWork NameSpaces都有自己的网络设备,IP地址,IP路由表,/proc/net目录,端口号等
那么从网络的角度来看,NetWork NameSpaces使每个容器都可以拥有自己的(虚拟)网络设备和绑定到每个命名空间端口号空间的应用程序,主机系统中合适的路由规则可以将网络数据包定向到与特定容器相关的网络设备,例如:可以在同一个主机系统上拥有多个容器化的Web服务器,每个服务器都绑定到每个容器的NetWork NameSpaces中的80端口
Go的实现
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
// fork出新的进程。并执行sh命令
cmd := exec.Command("sh")
// 设置Cloneflags。clone新的network命名空间
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWNET,
}
// 输入输出
cmd.Stdin = os.Stdin
cmd.Stderr = os.Stderr
cmd.Stdout = os.Stdout
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}
可以看到隔离之后,只有一个link/loopback本地回环
User NameSpaces
用于隔离用户和组ID号的空间,换句话说:进程的用户和组ID在User NameSpaces内部和外部可以不同,这里最有意思的是:一个进程可以在User NameSpaces之外拥有一个普通的非特权用户ID,同时在命名空间内拥有一个用户ID为0,这意味着该进程对User NameSpaces内的操作具有完全的root权限,但对命名空间外的操作没有特权
从Linux 3.8开始,非特权进程可以创建User NameSpaces,这给应用程序开启了许多有意思的可能性:由于原本非特权进程可以在User NameSpaces内拥有root权限,因此非特权应用程序现在可以访问以前仅限于根路径,Eric Biederman 为使User NameSpaces实现安全和正确付出了很多努力。然而,这项工作带来的变化是微妙而广泛的。因此,User NameSpaces可能会出现一些尚待发现和修复的未知安全问题。
ps: 这里我理解的意思是,一个普通权限的用户,可以创建一个User NameSpaces,在这个User NameSpaces外面,它只是一个普通权限的用户,但是在User NameSpaces中拥有绝对的root权限
Go的实现
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
// fork出新的进程。并执行sh命令
cmd := exec.Command("sh")
// 设置Cloneflags。clone新的user命名空间
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUSER,
UidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: 0,
Size: 1,
},
},
GidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: 0,
Size: 1,
},
},
}
// 输入输出
cmd.Stdin = os.Stdin
cmd.Stderr = os.Stderr
cmd.Stdout = os.Stdout
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}
上面的代码中有一个GidMappings和UidMappings
从这个结构体的解释中我们可以发现,一个是用来映射用户ID的,一个是用来映射用户组的
可以运行后查看用户的隔离性
Mount namespaces
隔离一组进程看到的文件系统挂载点集。因此,不同挂载命名空间中的进程可以具有文件系统层次结构的不同视图。随着挂载命名空间的添加,mount() 和umount() 系统调用停止在系统上所有进程可见的全局挂载点集上运行,而是执行仅影响与调用进程关联的挂载命名空间的操作。
简单来说:挂载命名空间的一种用法是创建类似于chroot的环境,但是,与使用chroot()相比,挂载命名空间更加的灵活,并且安全,挂载命令空间的其他更复杂的用途也是有可能的,例如:允许安装在一个命名空间中的光盘设备自动出现在其他的命名空间
ps: Mount namespaces 是第一个进入Linux内核的namespace,首次出现在Linux 2.4.19版本。它们隔离了每个进程可以看到的挂载点列表,或者换句话说,每个Mount namespace都有它们自己的挂载点列表,意味着在不同namespace中的进程都可以看到且控制不同的目录层次结构(目录树)。
什么是rootfs
rootfs(root filesystem)是分层文件树的顶端,包含对系统运行至关重要的文件和目录,包括设备目录和用于启动系统的程序,rootfs还包含了许多挂载点,其他文件系统可以通过这些挂载点连接到rootfs的文件数中,rootfs通常由linux 发行版提供,一个典型的rootfs内容如下
ps: rootfs包含了一般系统上的常见目录结构,类似于/dev, /proc, /bin等等以及一些基本的文件和命令。
系统启动时,初始化进程会将rootfs挂载到/目录,之后再挂载其他的文件系统到其子目录中,这期间所有的mount系统调用都会被记录到初始化的mount table中,宿友进程都有一张独立的mount table,记录在/proc/$PID/mounts中,但一般情况下,系统中的所有进程都会被使用初始化进程的mount table
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
// fork出新的进程。并执行sh命令
cmd := exec.Command("sh")
// 设置Cloneflags。clone新的Mount命名空间
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWNS,
}
// 输入输出
cmd.Stdin = os.Stdin
cmd.Stderr = os.Stderr
cmd.Stdout = os.Stdout
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}
创建一个tmp/uzju的目录
我们回到原来宿主机的终端可以发现并没有uzju.txt的文件
什么是bootfs
包含了bootloader和linux内核。用户是不能对这层作任何修改的。在内核启动之后,bootfs实际上会unmount掉。
2、为什么要使用Linux NameSpace隔离进程
个人理解
1、如果我们在一台服务器上启动多个服务,那么他们之前互相可以看到互相的进程,文件等,可能会造成相互的影响,同时他们也都可以访问宿主机的文件,那么隔离进程能让一台主机,部署多个服务,并且互相不冲突,并且在同一台服务器可以有很高的扩展性与多样性
2、既然在一台机器上部署了多个服务,那么如果其中有一个Web网站被入侵,容器之间没有隔离,或与宿主机之间没有隔离,就会导致一个被入侵,全部服务都被入侵的情况
3、服务器的弹性扩展,如果一个服务就需要一台服务器的话,那么如果有1000个,10000个怎么办,而且就算真的开10000个服务器,那么服务器上的资源性能肯定会过剩,导致高服务扛不住,低服务性能跑不满的情况,当然这个说法也不确定,因为现在毕竟服务器有弹性伸缩,算是各有各的好处吧
举个例子
其中有一个PID为1的/sbin/init进程
和一个PID为2的kthreadd进程
这两个进程由上帝进程idle创建
上帝进程idle
1.简单的说idle是一个进程, 贴切一点说是系统创建的第一个进程(idle进程由系统自动创建, 运行在内核态 ),其pid号为 0。其前身是系统创建的第一个进程,也是唯一一个没有通过fork()产生的进程, 完成加载系统后,演变为进程调度、交换, idle进程最终调用了cpu_idle()函数。
2.主处理器上的idle由原始进程(pid=0)演变而来。从处理器上的idle由init进程fork得到,可是它们的pid都为0。
3.Idle进程为最低优先级。且不參与调度。仅仅是在执行队列为空的时候才被调度。
4.Idle循环等待need_resched置位。默认使用hlt节能。
PID为1的/sbin/init的进程主要负责执行内核的一部分初始化工作和系统配置,也会创建一些类似 getty 的注册进程
PID为2的负责管理和调度其他的内核进程。
我们在宿主机中可以看到很多的进程,但是我们现在启动一个docker看看
当前的Docker 容器成功将容器内的进程与宿主机器中的进程隔离,此时我们回到宿主机,使用ps -ef | grep docker 可以看到
Linux Clone
https://man7.org/linux/man-pages/man2/clone.2.html
Linux进程必须具备的四大要素
1、 程序代码不一定是进程专有,可以与其它进程共用。
2、系统堆栈空间,这是进程专用的
3、在内核中维护相应的进程控制块。只有这样,该进程才能成为内核调度的基本单位,接受调度。并且,该结构也记录了进程所占用的各项资源。
4、有独立的存储空间,表明进程拥有专有的用户空间。
以上四条,缺一不可。如果缺少第四条,那么就称其为“线程”。如果完全没有用户空间,称其为“内核线程”;如果是共享用户空间,则称其为“用户线程”。
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg);
fn是函数指针,我们知道进程的4要素,这个就是指向程序的指针,就是所谓的“剧本", child_stack明显是为子进程分配系统堆栈空间(在linux下系统堆栈空间是2页面,就是8K的内存,其中在这块内存中,低地址上放入了值,这个值就是进程控制块task_struct的值),flags就是标志用来描述你需要从父进程继承那些资源, arg就是传给子进程的参数)。下面是flags可以取的值:
1、CLONE_PARENT 创建的子进程的父进程是调用者的父进程,新进程与创建它的进程成了“兄弟”而不是“父子”
2、CLONE_FS 子进程与父进程共享相同的文件系统,包括root、当前目录、umask
3、CLONE_FILES 子进程与父进程共享相同的文件描述符(file descriptor)表
4、CLONE_NEWNS 在新的namespace启动子进程,namespace描述了进程的文件hierarchy
5、CLONE_SIGHAND 子进程与父进程共享相同的信号处理(signal handler)表
6、CLONE_PTRACE 若父进程被trace,子进程也被trace
7、CLONE_VFORK 父进程被挂起,直至子进程释放虚拟内存资源
8、CLONE_VM 子进程与父进程运行于相同的内存空间
9、CLONE_PID 子进程在创建时PID与父进程一致
10、CLONE_THREAD Linux 2.4中增加以支持POSIX线程标准,子进程与父进程共享相同的线程群
3、Go实现NameSpaces
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
switch os.Args[1] {
case "run":
run()
default:
panic("pass me an argument please")
}
}
func run() {
fmt.Printf("Running %v\n", os.Args[2:])
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.Env = []string{"PS1=-[container]- # "}
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
if err := cmd.Run(); err != nil {
fmt.Printf("Error running the %s command - %s\n", os.Args[1], err)
os.Exit(1)
}
}
上述代码,我们需要编译,环境在Ubuntu21.10中,Go的版本为1.8
go build main.go
ps: 执行./main的时候,必须要是root权限
不过此时进程之类的都还没有隔离,还是可以操作宿主机的资源,进程,磁盘等
此时已经创建了一个UTS NameSpace,那么来仔细看一下上面这段代码。
首先是第一部分
导入了四个模块,分别fmt,os,os/exec,syscall,其中最重要的就是syscall
在main函数中,使用Switch来判断接收的控制台第一个参数是不是run,如果不是则显示pass me an argument please,那么我们的传参就应该是./main run
我们来到run()函数,定了cmd的标准输入输出错误等,并且还定义了Env,主要是为了在执行程序的时候区分NameSPace等信息
最重要的就是下面这段代码
NameSpace Api
共有3个系统调用组成命名空间API
1、Clone(2)
创建一个新的进程,如果调用的时候传进去了一个或者多个标志参数,那么这些命名参数就是给创建的子进程的
2、Setns(2)
允许调用进程加入新的一个存在的命名空间
3、unshare(2)
unshare(2)系统调用将调用进程移动到一个新的NameSpace,如果在创建的时候,指定了一个或者多个CLONE_NEW*熬制,那么首先会为每个标志创建新的NameSpace,并且调用进程会成为这些NameSpace的成员
调用clone()的时候,可以传递多个CLONE*标志,这里传递了一个CLONE_NEWUTS,那么还有其他的例如:CLONE_NEWNS, CLONE_NEWIPC, CLONE_NEWPID, CLONE_NEWNET, CLONE_NEWUSER和CLONE_NEWCGROUP
1、什么是Linux Cgroup
虽然NameSpace解决了环境隔离上的问题,但是并没有解决主机上资源的隔离,虽然可以通过NameSpace把单个容器关到一个特定的环境中,但是单个容器对其中的进程使用的CPU,内存,磁盘等这些计算资源其实都是可以操作的,所以对进程进行资源上的限制或者控制,这就Linux Cgroup的作用
Linux CGroup全称Linux Control Group, 是Linux内核的一个功能,用来限制,控制与分离一个进程组群的资源(如CPU、内存、磁盘输入输出等)。这个项目最早是由Google的工程师在2006年发起(主要是Paul Menage和Rohit Seth),最早的名称为进程容器(process containers)。在2007年时,因为在Linux内核中,容器(container)这个名词太过广泛,为避免混乱,被重命名为cgroup,并且被合并到2.6.24版的内核中去。
Linux Cgroup主要提供以下功能
1、Resource limitation:限制资源的使用
例如:内存使用上限以及文件系统的缓存限制
2、Prioritization:优先级控制
例如:CPU利用和磁盘的IO吞吐
3、Accounting 一些审计和一些统计
4、Control
挂起进程,恢复执行进程
Cgroup主要限制的资源
CPU
内存
网络
磁盘I/O
2、Cgourp子系统
cgroups 的全称是control groups,cgroups为每种可以控制的资源定义了一个子系统。典型的子系统介绍如下:
cpu 子系统,主要限制进程的 cpu 使用率。
cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。
cpuset 子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
memory 子系统,可以限制进程的 memory 使用量。
blkio 子系统,可以限制进程的块设备 io。
devices 子系统,可以控制进程能够访问某些设备。
net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
freezer 子系统,可以挂起或者恢复 cgroups 中的进程。
ns 子系统,可以使不同 cgroups 下面的进程使用不同的 namespace。
2、Cgroup在什么时候创建
Linux 内核通过一个叫做 cgroupfs的伪文件系统来提供管理 cgroup 的接口,我们可以通过 lscgroup命令来列出系统中已有的 cgroup,该命令实际上遍历了/sys/fs/cgroup/目录中的文件:
lscgroup | tee cgroup.a
ps: 如果没有lscgroup的话,需要使用sudo apt install cgroup-tools
lssubsys -m
3、Cgroup如何限制资源
举个例子
如果安装docker之后,在每个子系统下都会有一个docker的目录
其中的4355等都是docker容器,启动这个容器时,Docker 会为这个容器创建一个与容器标识符相同的 CGroup,在当前的主机上 CGroup 就会有以下的层级关系:
每一个 CGroup 下面都有一个 tasks 文件,其中存储着属于当前控制组的所有进程的 pid,作为负责 cpu 的子系统,cpu.cfs_quota_us 文件中的内容能够对 CPU 的使用作出限制,如果当前文件的内容为 50000,那么当前控制组中的全部进程的 CPU 占用率不能超过 50%。
[email protected]:/sys/fs/cgroup/cpu,cpuacct/docker# docker run -itd --cpu-quota=50000 alpine:latest
42e834d55ff2287aceb0d80bdf8a47a417f732e71fdb2419301c09ac6154e05d
[email protected]:/sys/fs/cgroup/cpu,cpuacct/docker# cd 42e834d55ff2287aceb0d80bdf8a47a417f732e71fdb2419301c09ac6154e05d
[email protected]:/sys/fs/cgroup/cpu,cpuacct/docker/42e834d55ff2287aceb0d80bdf8a47a417f732e71fdb2419301c09ac6154e05d# ls -alh
total 0
drwxr-xr-x 2 root root 0 Mar 31 17:53 .
drwxr-xr-x 13 root root 0 Mar 31 17:53 ..
-rw-r--r-- 1 root root 0 Mar 31 17:53 cgroup.clone_children
-rw-r--r-- 1 root root 0 Mar 31 17:53 cgroup.procs
-r--r--r-- 1 root root 0 Mar 31 17:53 cpuacct.stat
-rw-r--r-- 1 root root 0 Mar 31 17:53 cpuacct.usage
-r--r--r-- 1 root root 0 Mar 31 17:53 cpuacct.usage_all
-r--r--r-- 1 root root 0 Mar 31 17:53 cpuacct.usage_percpu
-r--r--r-- 1 root root 0 Mar 31 17:53 cpuacct.usage_percpu_sys
-r--r--r-- 1 root root 0 Mar 31 17:53 cpuacct.usage_percpu_user
-r--r--r-- 1 root root 0 Mar 31 17:53 cpuacct.usage_sys
-r--r--r-- 1 root root 0 Mar 31 17:53 cpuacct.usage_user
-rw-r--r-- 1 root root 0 Mar 31 17:53 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 Mar 31 17:53 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 Mar 31 17:53 cpu.shares
-r--r--r-- 1 root root 0 Mar 31 17:53 cpu.stat
-rw-r--r-- 1 root root 0 Mar 31 17:53 notify_on_release
-rw-r--r-- 1 root root 0 Mar 31 17:53 tasks
[email protected]:/sys/fs/cgroup/cpu,cpuacct/docker/42e834d55ff2287aceb0d80bdf8a47a417f732e71fdb2419301c09ac6154e05d# cat cpu.cfs_quota_us
50000
[email protected]:/sys/fs/cgroup/cpu,cpuacct/docker/42e834d55ff2287aceb0d80bdf8a47a417f732e71fdb2419301c09ac6154e05d#
4、Cgroup支持的文件种类
文件名 | R/W | 用途 |
Release_agent | RW | 删除分组时执行的命令,这个文件只存在于根分组 |
Notify_on_release | RW | 设置是否执行 release_agent。为 1 时执行 |
Tasks | RW | 属于分组的线程 TID 列表 |
Cgroup.procs | R | 属于分组的进程 PID 列表。仅包括多线程进程的线程 leader 的 TID,这点与 tasks 不同 |
Cgroup.event_control | RW | 监视状态变化和分组删除事件的配置文件 |
docker的实现原理
其实docker就是一个linux下的进程,通过Linux NameSpaces对不同的容器进行隔离,为了保证宿主机与容器资源上的隔离,与资源占用的比例,所有使用Cgroup对进程进行资源上的限制或者控制
docker的实现原理(互联网)
1、docker就是一个linux系统的进程, 它通过 Linux 的 namespaces 对不同的容器实现了资源隔离,然后上面再跑一rootfs文件系统当容器使用的时候为了单个容器不榨干系统资源,所以就使用cgroup来做控制。
Linux NameSpace和Cgroup解决了什么?
Linux 的NameSpace和Cgroup分别解决了不同资源隔离的问题,前者解决了进程、网络以及文件系统的隔离,后者实现了 CPU、内存等资源的隔离。
https://lwn.net/Articles/531114/
https://www.toptal.com/linux/separation-anxiety-isolating-your-system-with-linux-namespaces
https://linux.cn/article-3068-1.html
https://coolshell.cn/articles/17010.html
https://coolshell.cn/articles/17029.html
https://coolshell.cn/articles/17049.html
https://lwn.net/Articles/531114/
https://www.cnblogs.com/chenglee/p/10435616.html
https://www.cnblogs.com/charlieroro/p/14280738.html
https://blog.csdn.net/u013272948/article/details/69218319
https://segmentfault.com/a/1190000006917884
https://www.cnblogs.com/sparkdev/p/8296063.html
https://www.cnblogs.com/snake-hand/p/3161450.html
https://man7.org/linux/man-pages/man2/clone.2.html
*
https://jameshfisher.com/2018/03/31/dev-stdout-stdin/
https://bingbig.github.io/topics/container/linux_namespaces.html
*https://www.slideshare.net/jpetazzo/docker-and-go-why-did-we-decide-to-write-docker-in-go
https://blog.csdn.net/qq_27068845/article/details/90666317
https://medium.com/@teddyking/namespaces-in-go-basics-e3f0fc1ff69a
https://ref.gotd.dev/src/syscall/exec_linux.go.html#line-50
https://pkg.go.dev/syscall#SysProcAttr
https://www.jianshu.com/p/4a1f712185c4
https://jimmysong.io/blog/docker-source-code-analysis-code-structure/
https://www.cnblogs.com/axian1001/p/6239173.html
https://moelove.info/2021/12/13/%E6%90%9E%E6%87%82%E5%AE%B9%E5%99%A8%E6%8A%80%E6%9C%AF%E7%9A%84%E5%9F%BA%E7%9F%B3-namespace-%E4%B8%8B/#procpidns-%E7%9B%AE%E5%BD%95
https://www.cnblogs.com/shihuvini/p/7899189.html
https://lwn.net/Articles/689856/
https://www.waynerv.com/posts/container-fundamentals-filesystem-isolation-and-sharing/
https://colobu.com/2017/06/19/advanced-command-execution-in-Go-with-os-exec/
https://www.cnblogs.com/plxx/p/5129245.html
https://tech.meituan.com/2015/03/31/cgroups.html
好文推荐
欢迎关注 系统安全运维
如有侵权请联系:admin#unsafe.sh